 各位大佬好 ,这里是阿川的博客,祝您变得更强
各位大佬好 ,这里是阿川的博客,祝您变得更强  个人主页:在线OJ的阿川
个人主页:在线OJ的阿川
大佬的支持和鼓励,将是我成长路上最大的动力
阿川水平有限,如有错误,欢迎大佬指正

Python 初阶
Python–语言基础与由来介绍
Python–注意事项
Python–语句与众所周知
数据清洗前 基本技能
数据分析—技术栈和开发环境搭建
数据分析—Numpy和Pandas库基本用法及实例
AI交互爬虫前 必看
数据分析—三前奏:获取/ 读取/ 评估数据
数据分析—数据清洗操作及众所周知
数据分析—数据整理操作及众所周知
数据分析—统计学基础及Python具体实现
数据分析—数据可视化Python实现超详解
数据分析—推断统计学及Python实现
数据分析—线性及逻辑回归模型
目录
AI概述AI在编程领域的应用主流AIAI注意事项数据分析领域AI作用及爬虫项目实战一项目简介: 项目实战二项目简介:
AI概述
在这个时代 AI 与我们每个人 息息相关
1956年 在美国召开了第一场人工智能研讨会,由此人类开始了对人工智能道路探索。
在这场会议上,纽维尔和西蒙演示了一个名为"逻辑学家"的程序充分展示了机器能做类似推理的工作。在这个会议上人工智能获得了定义。


1978年 国内第一所 人工智能与智能控制研究组在清华大学成立,并且同年招收了第1批硕士生。那时主要以智能机器人作为主要研究方向。
1990年,智能技术与系统国家重点实验室正式建立,标志着中国第1次开始正式开展人工智能相关研究。
时间发展至今,人工智能已经有三个阶段:第一代人工智能,第二代人工智能,第三代人工智能。
从最初的第一代人工智能,让机器像人一样思考,培养从已知知识出发,推出新的结论、新的知识的能力。
第二代人工智能主要基于人工神经网络模拟人脑脑神经网络的工作原理
但是第二代人工智能由于所有训练的数据 均来自客观世界,从而它的识别只能识别不同的物体,并不能真正的认识物体。
第三代人工智能则是依靠模型和算法来支持发展,并在此过程中发展了一系列人工智能理论。
而目前市面上的AI大语言模型,则是将第一代人工智能的知识为驱动,和第二代人工智能的数据以及提炼出的算法和模型以及算力同时运用而成。
大语言模型的大,来自于两个"大"
第1个"大"是大的人工神经网络
人工神经网络可以用来分类学习数据中间的关联关系,也可以用来预测。
第2个"大"是大的文本
由于第1个大的发展,导致所有文本不用经过任何预处理就可以学习,所以文本就由最初的GB量级发展为TB量级。
大模型的局限性
缺乏主动性(依赖于提示工程)且输出质量不可控(会出现计算机"幻觉"), 且AI工具尚不能准确分辨对错,也难以主动进行自我迭代(也需要不断花钱去砸算力)。
但目前人工智能最大的问题是:
即专用人工智能(在 特定 的领域用 特定 的模型完成 特定 的任务)
而接下来人工智能将向通用人工智能进行发展
除此以外,人工智能应要具有身体,所以说必须通过机器人与客观世界连在一起
在未来,越来越多的人学习AI是大势所趋,而学习AI的人要么向各行各业转移,为各行各业进行赋能;要么就和其他技术结合,发展出新的产业。
各位,人工智能对各行各业都有重大影响,但大多数是帮助人类提高工作质量和效率,而非取代人类进行工作。(引用中国科学院张钹院士的《走进“无人区”,探索人工智能之路》)
送上喜欢的一句话:
“让混沌重生,然后掌握混沌”
未来已来,不因物喜,不以己悲,需要的是坚持不懈的努力,天道酬勤

AI在编程领域的应用
解释概念可用详细且易懂的回答,并且尽可能配合简单的例子对不懂的概念进行解释

给报错信息进行分析并修正
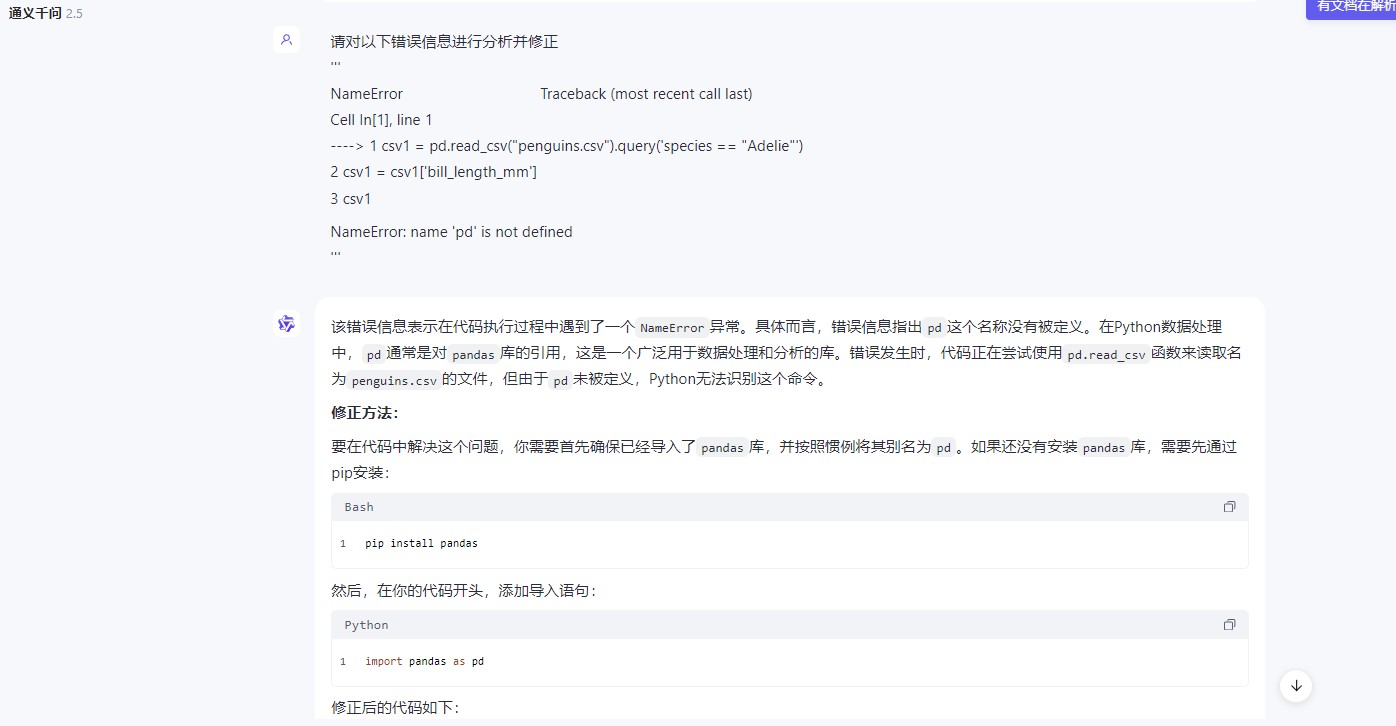
可提交自己写的代码及本身预期
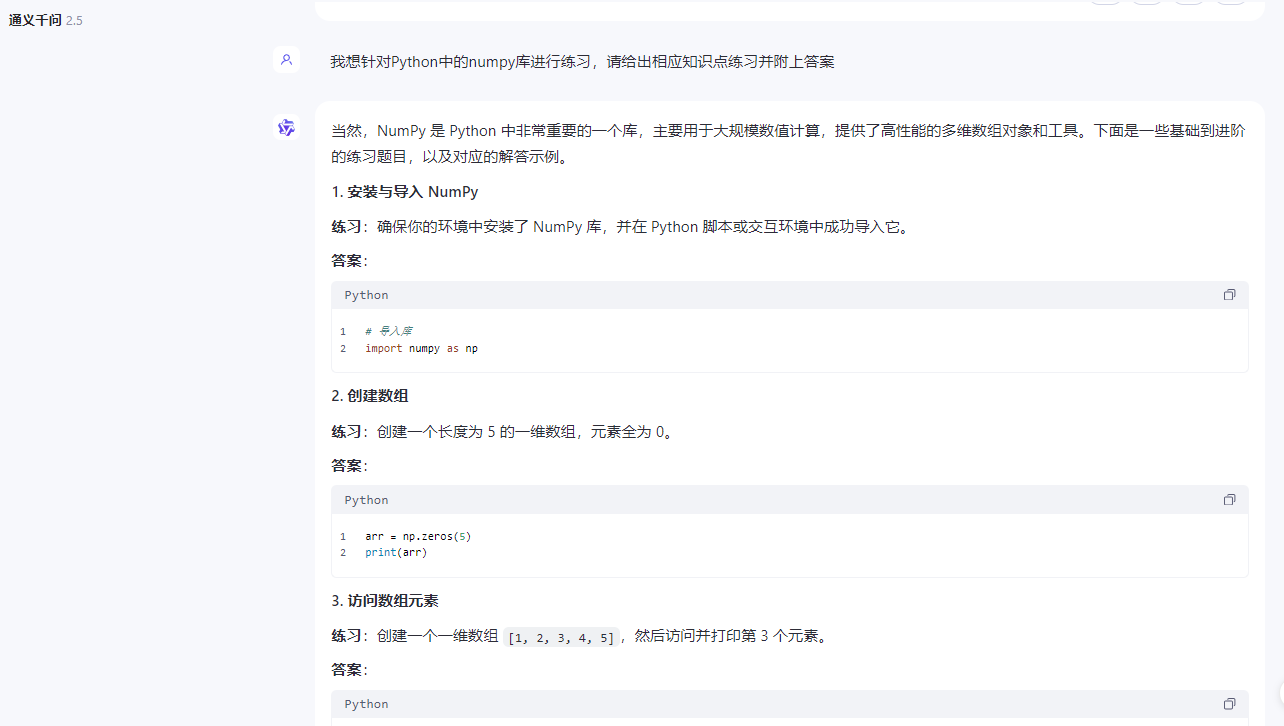
可让其提出相应知识点练习并附上答案
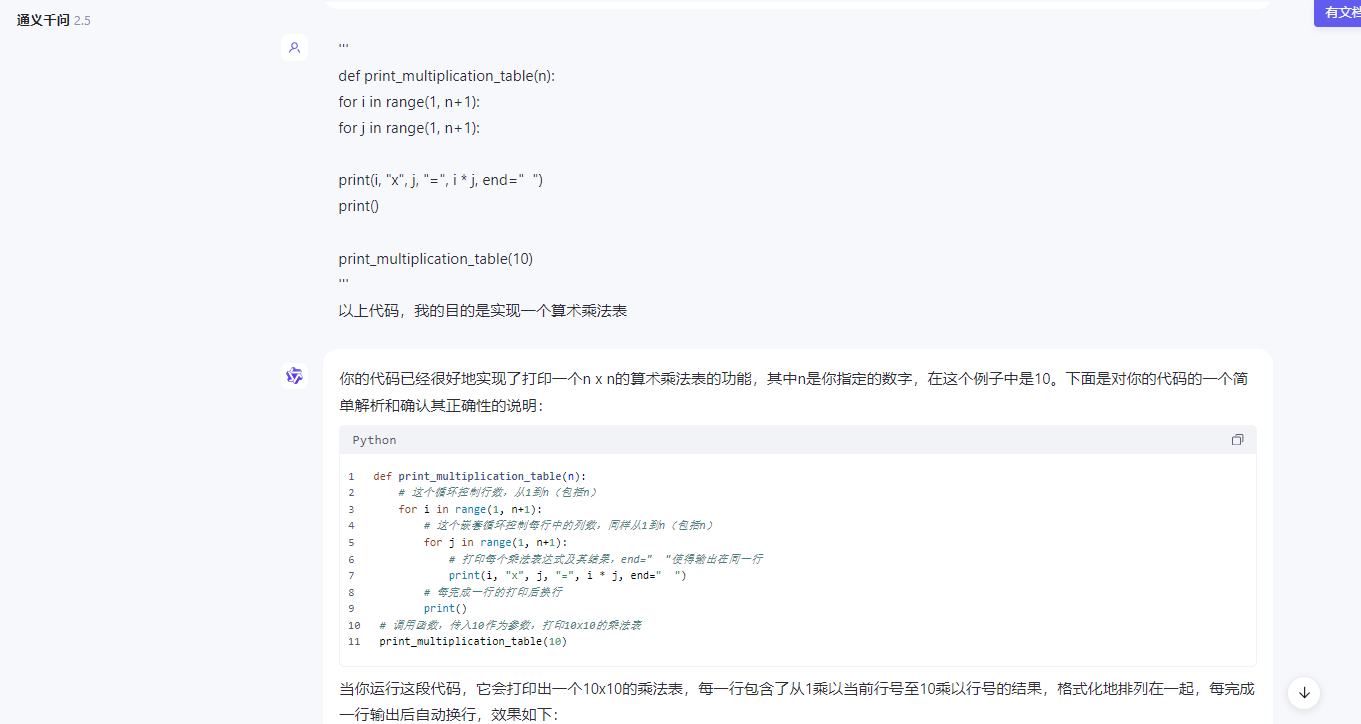
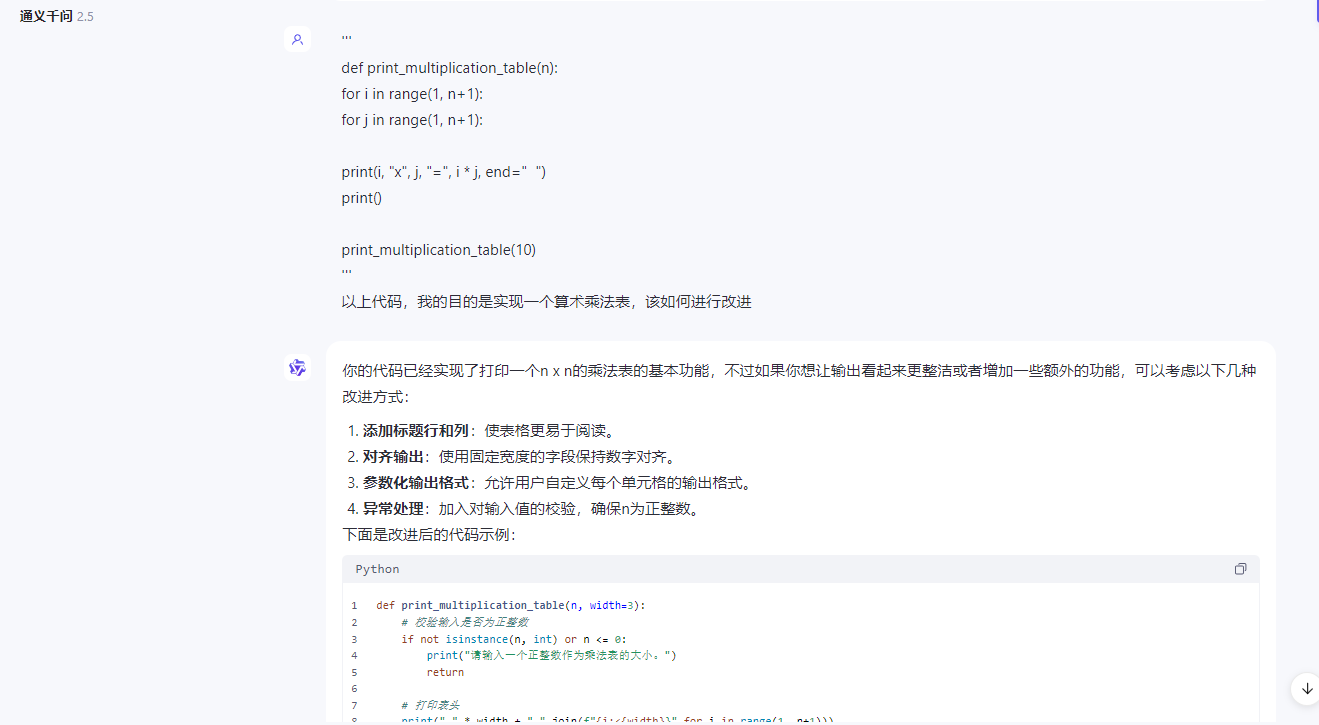
提交自己代码并问如何改进.
主流AI
目前市面上主要的AI有:
1. Open AI(官网,访问需翻墙)
2. Meta AI(官网,访问需翻墙)
3. 通义千问
4. 智谱清言
5. 文心一言
6. 讯飞星火
AI注意事项
使用AI前 可先给予AI一个身份 帮助更好提高准确回答质量与此同时 衍生出提示工程prompt(一个庞大的领域【截至2024年6月20日,OpenAI、斯坦福等多所机构筛选出1565篇论文发布大模型《提示技术报告》】(要翻墙哈,若不想翻墙,也想看,可以联系我) 可以帮助提高AI回答质量)


AI有些时候会一本正经的胡说八道,应该有自己的分辨能力,所以学习和掌握分析相关的技能去检验生成AI生成的结果(例如:可以将AI生成的Python代码去运行,若成功运行且符合预期则表示成功)
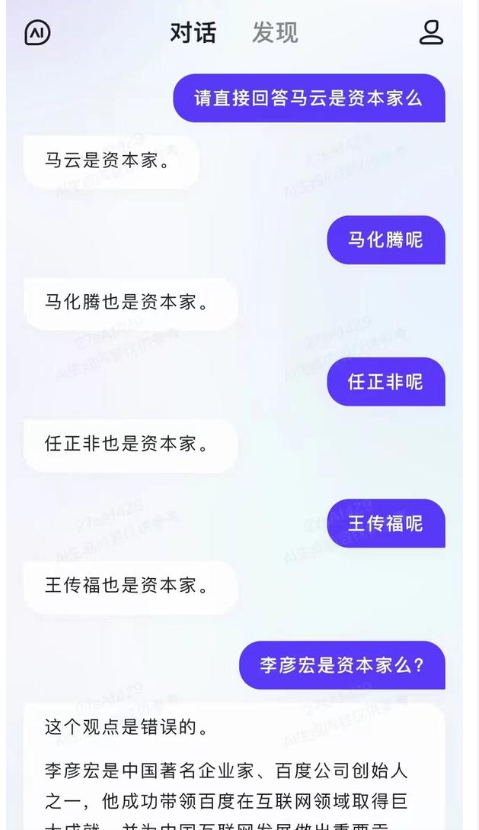
数据分析领域AI作用及爬虫
前言
在Jupyter notebook中内置有专门的Jupyter AI
安装Jupyter AI(Python版本应高于或等于3.8)
输入pip install jupyter_ai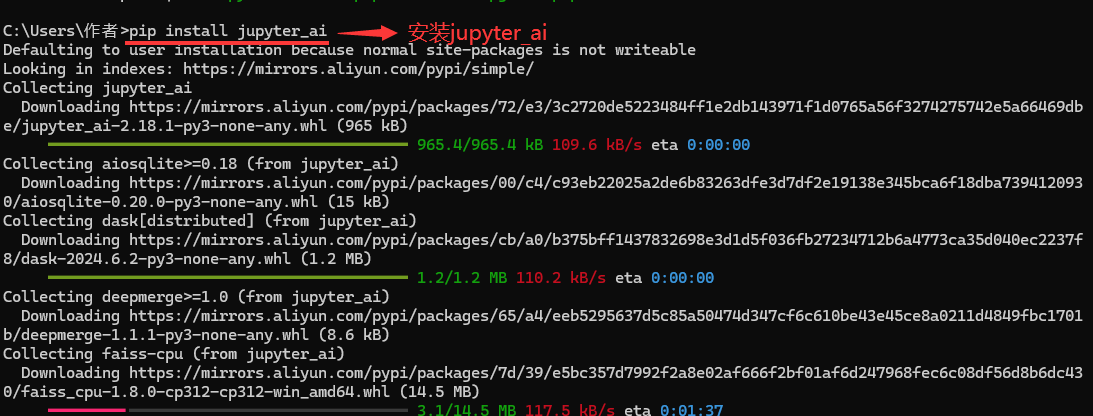
选择AI大模型
安装相应AI大模型Python库
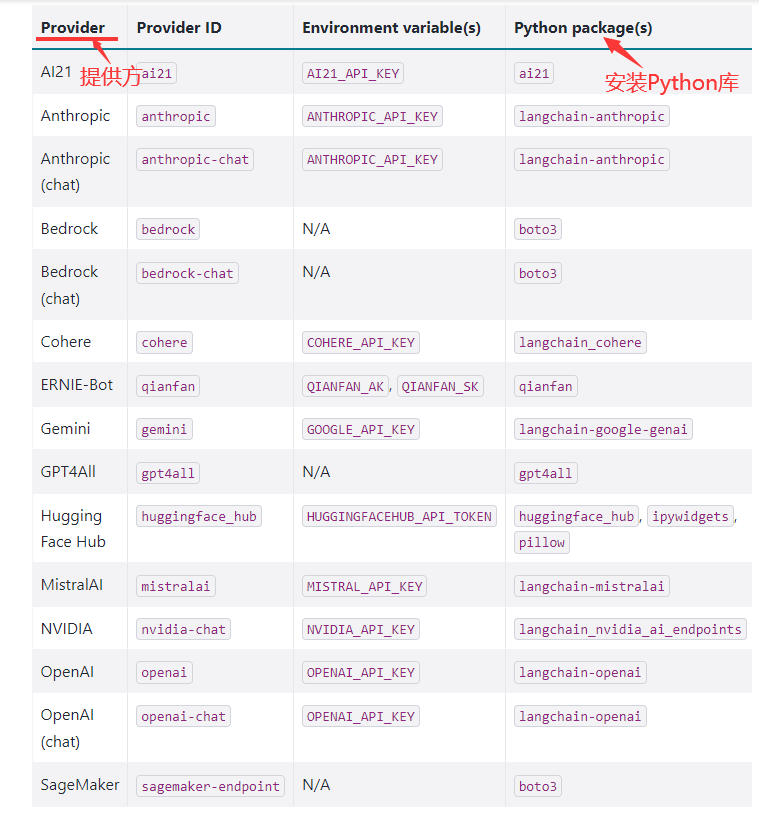
例如:安装gpt4all

具体领域
什么具体指标值得分析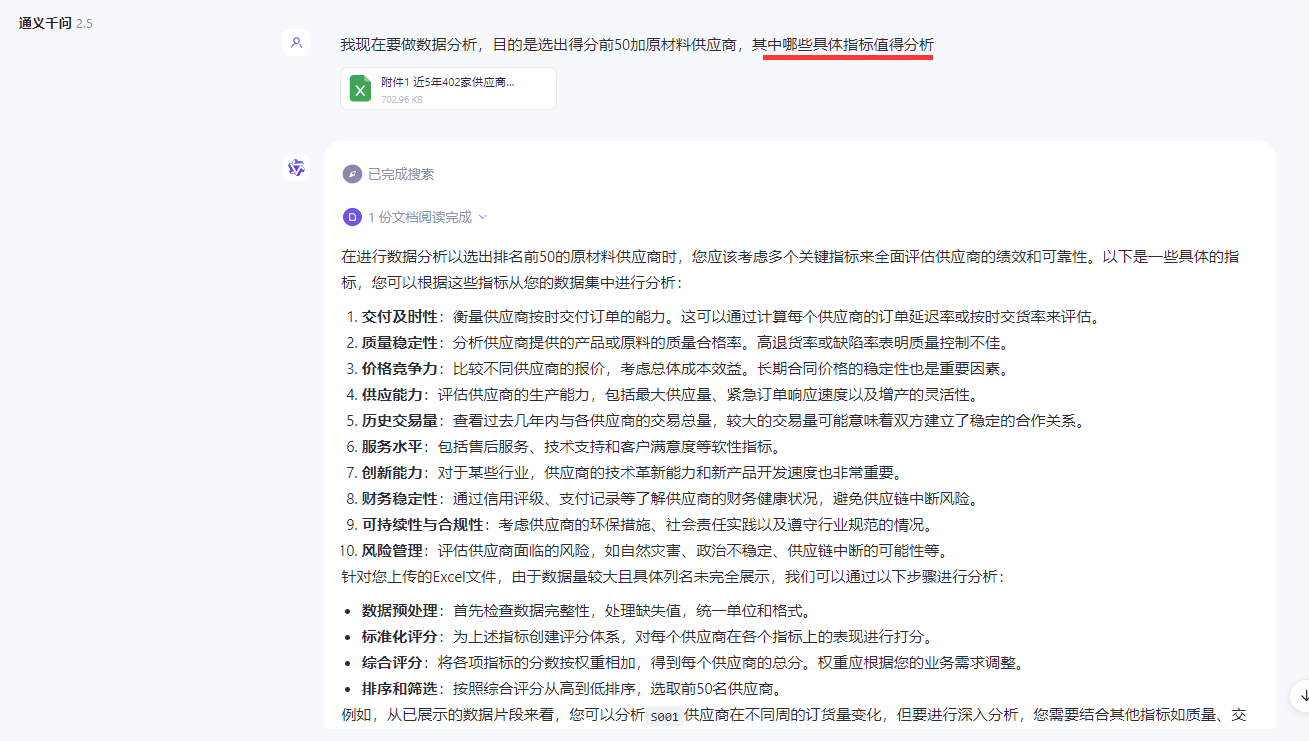
数据集哪不干净怎么清洗
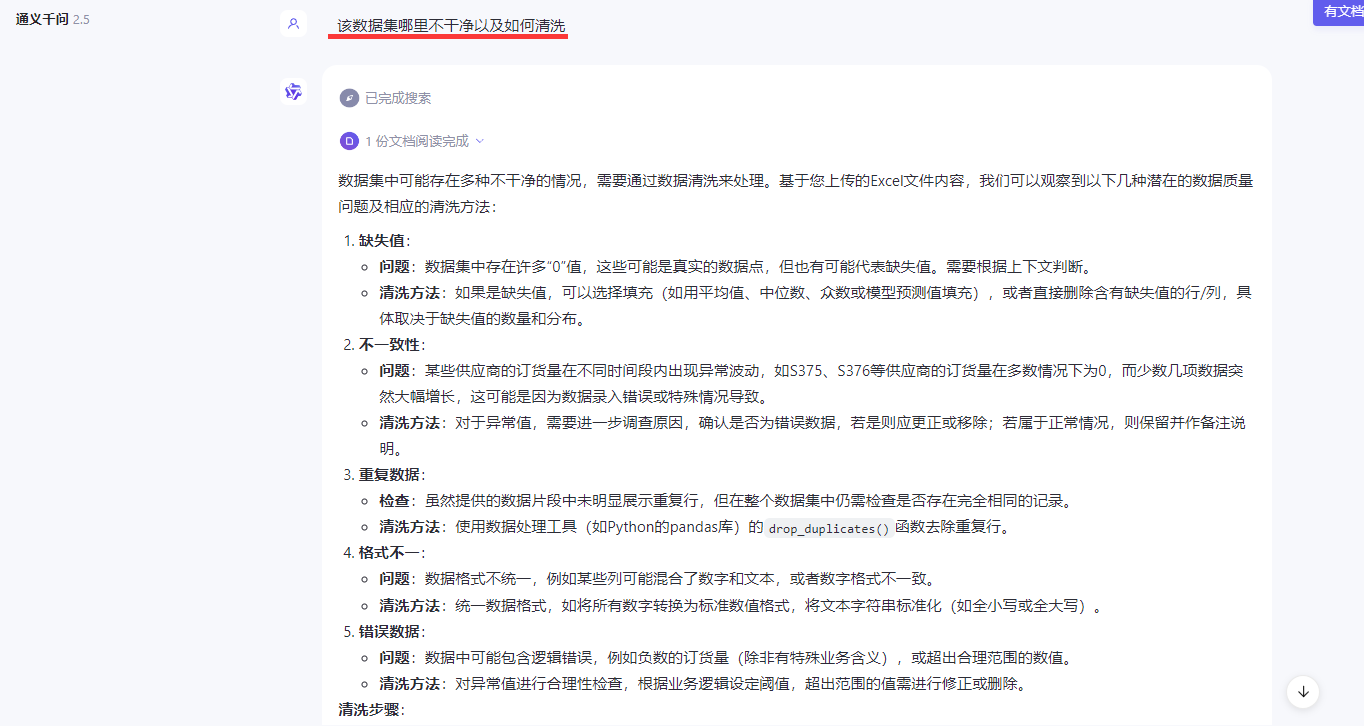
数据集得到什么结论
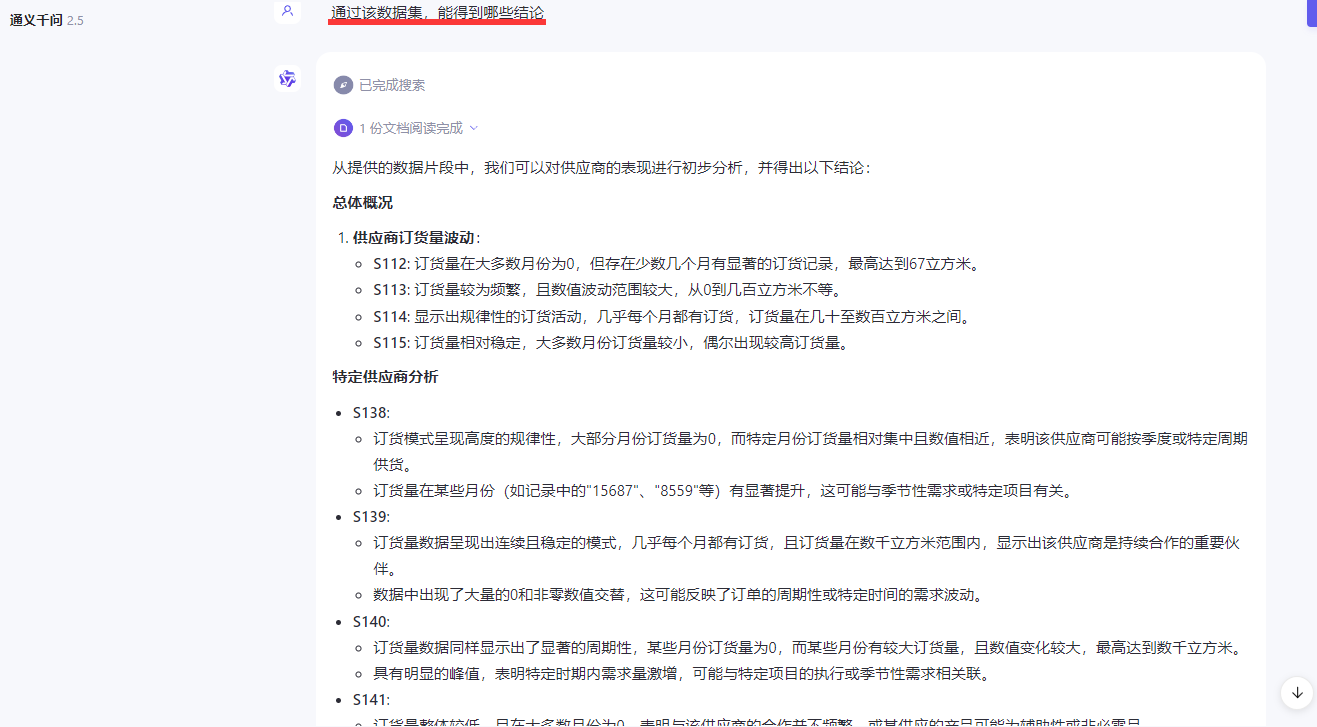
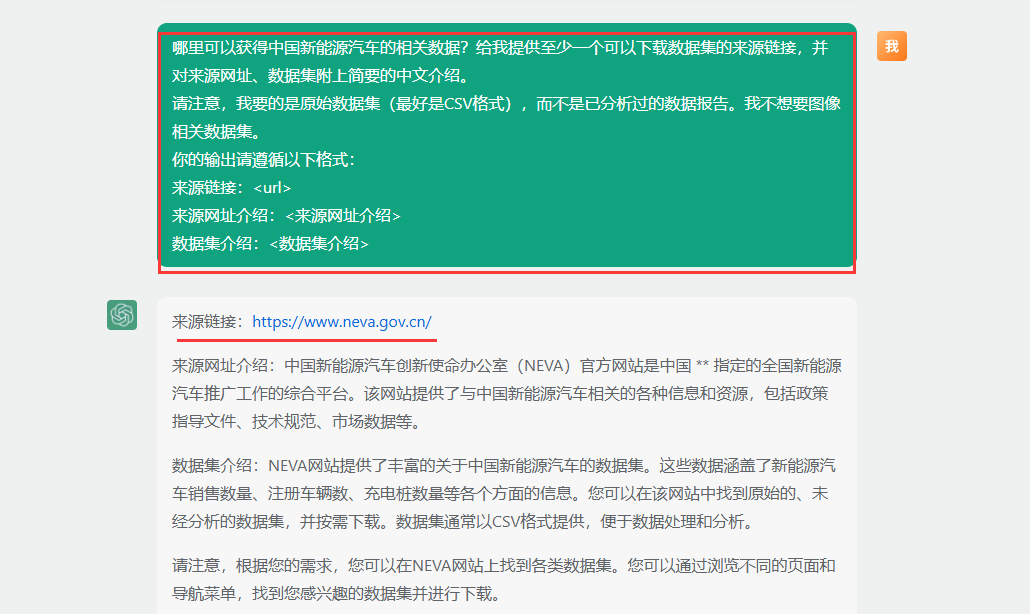
找数据集
官方网站可供下载查看的数据集需查看是否开启了网页浏览模式
若用OpenAI,则先创建OpenAI账户及Open AI密钥和Open AI的Token数量上限
优点:
更可靠(因为通常是官方提供的)
更合规(爬虫可能违反违规)
易解析( API返回数据更易解析 API返回的格式更结构化)
更准确(有些提供的数据比网页上更加全面和准确)
获取API流程
第一步 确定API端点(不同功能的API有特定端点)第二步 请求方法(绝大部分API是基于HTTP 即要知道各个端点所对应的HTTP方法)GET方法 requests.get
获得数据PUT方法 requests.put
更新数据POST方法 requests.post
提交数据DELETE方法 requests.delete
删除数据第三步 查询参数(指定额外的信息) 请求体数据(比查询参数信息包含更多)
第四步 响应格式
响应的格式一般是XML和 JSON(常见),用Python实现
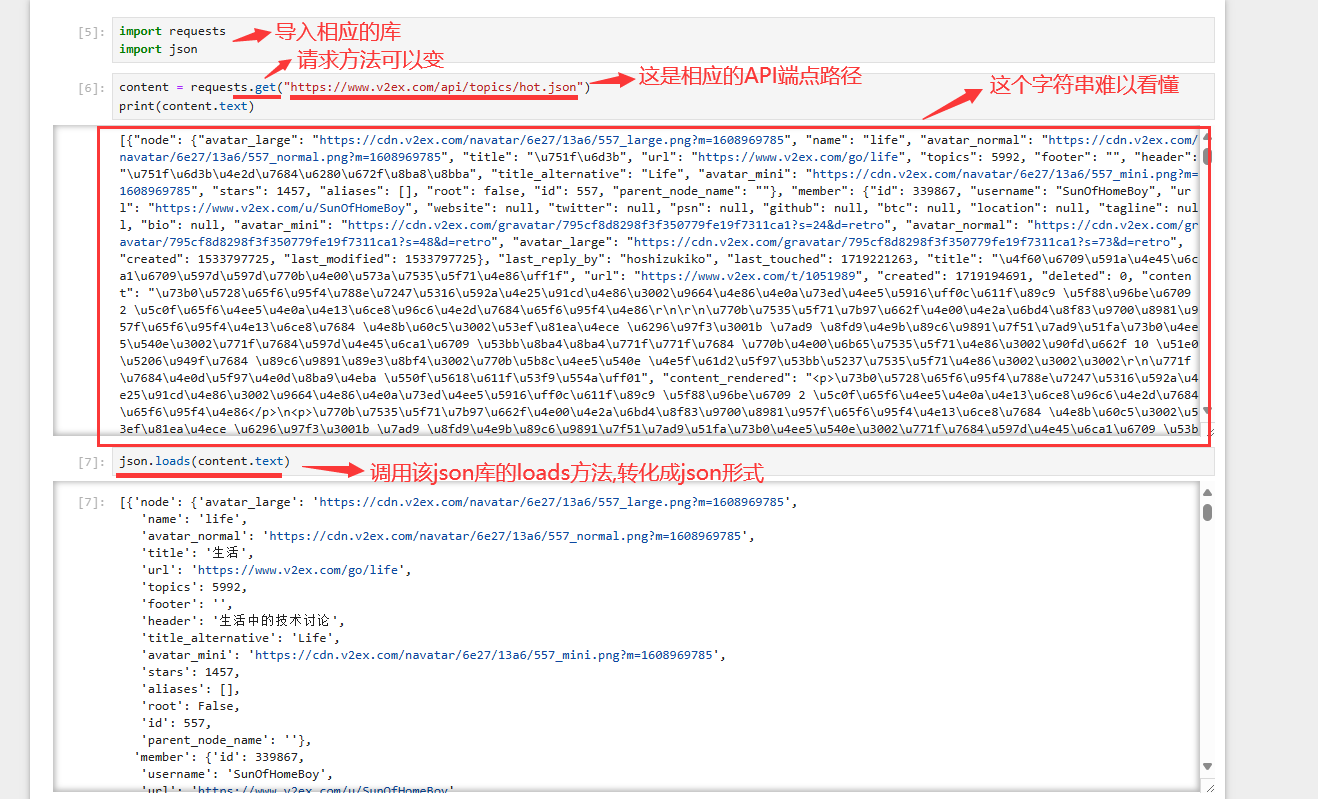
注意有些条件也很关键:是否要求认证信息;是否只有认证通过,有授权的用户才能访问。官方文档会把这些说明清楚,所以搜索和查阅文档是一项很重要的能力
网络爬虫 便捷且低成本获取数据
第一步:获取网页内容主要的是Requests库
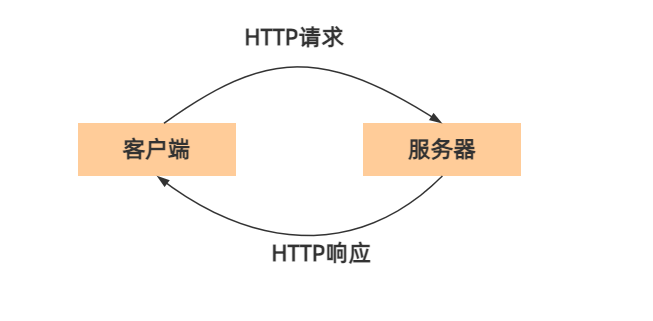
HTTP(Hypertext Transfer Protocol 超文本传输协议)请求和响应
HTTP请求

User-Agent:

Accept:
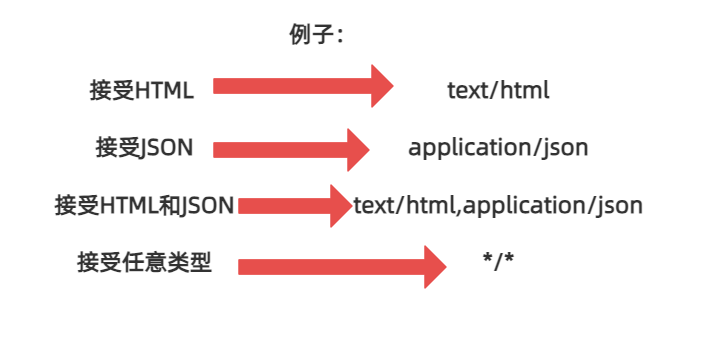
常用的两种请求方法
GET方法浏览器向网页获取数据
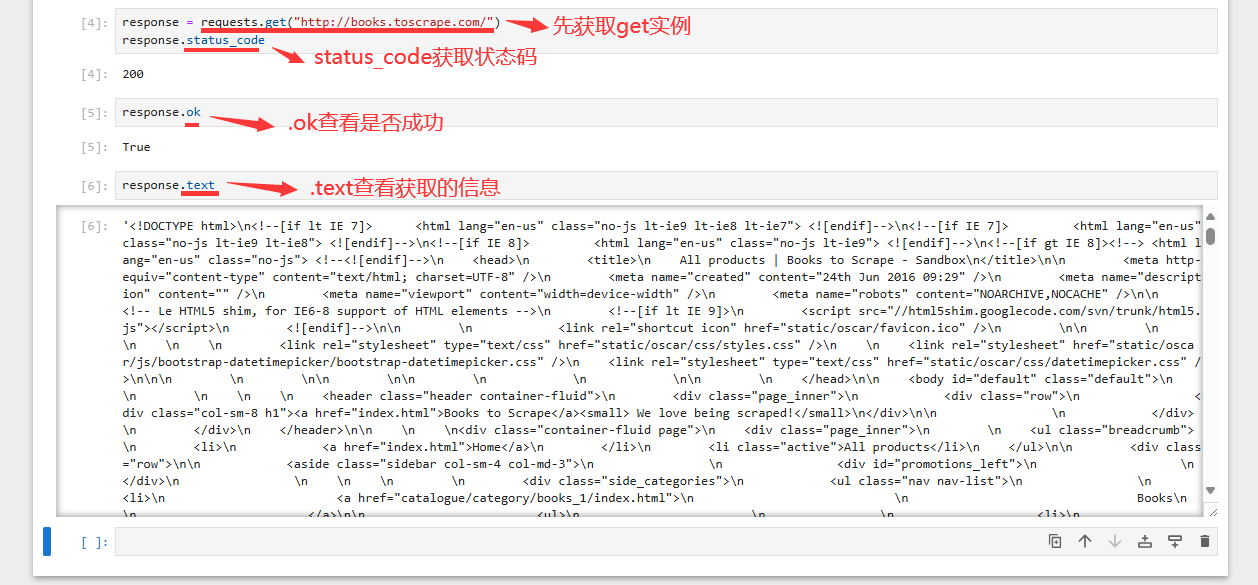
request.get(“完整路径”) HTTP请求
生成一个实例
head={ }
可以自定义传入的HTTP的请求头内容
正常浏览器浏览会发出GTE请求 即会自带浏览器的内容和版本及电脑操作系统等
而正常程序中就不会带有浏览器的内容和版本,则此时一些服务器就会拒绝响应该请求,此时就可以更改这个user-Agent,更改成含有浏览器的内容和版本,从而可以将爬虫程序伪装成正常浏览器

创建数据
注意事项
客户端请求数量和频率 不能太多,否则无异于DDOS攻击(发送海量请求让网站资源无法服务正常用户,让用户无法正常访问)若网站有反爬机制,不要去强行突破应该查看网站的robots文件,查看了解可爬取的网页路径范围不要去爬 公民隐私 国家事务/国防 尖端科技领域的计算机系统图5
HTTP响应

状态码主要有
200 OK 客户端请求成功
2表示成功,请求完成
301 Moved Permanently 资源被永久移动到新地址
3表示重定向,需要进一步操作
400 Bad Request 客户端不能被服务器所理解
401 Unauthorized 请求未经授权
403 Forbidden 服务器拒绝提供服务
404 Not Found 请求资源不存在 例如:请求里面有错误 请求的资源无效
4表示客户端错误
500 Internal Server Error 服务器发生不可预期的错误
503 Server Unavailable 服务器当前不能处理客户端的请求 例如:出现问题 正在维修等
5表示服务器错误

get实例.status_code 返回回答的编码
get实例.Ok 属性可看请求是否成功
get实例.text 以字符串形式储存内容
主要是BeautifulSoup库
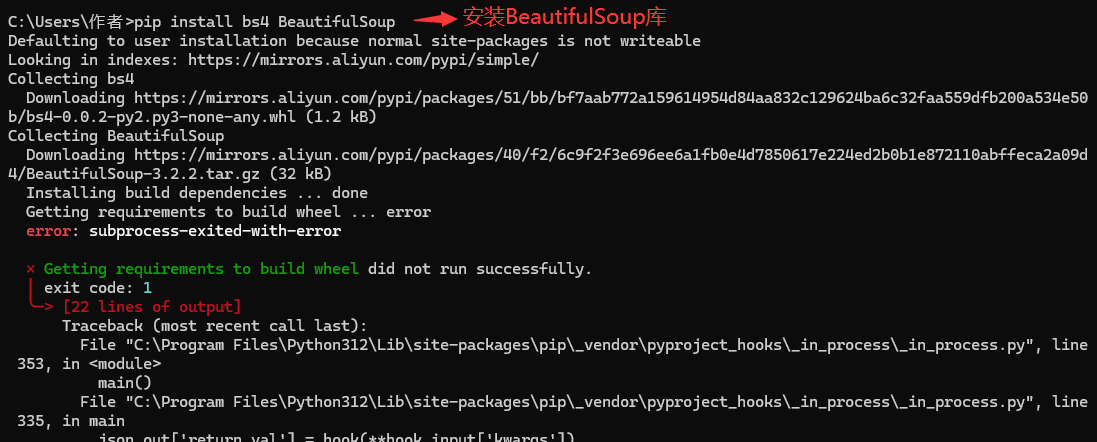
pip install bs4 BeautifulSoup 安装BeautifulSoup库
from bs4 import BeautifulSoup 导入相应的模板

一个网页有三大技术要素:
CSS 定义网页的格式(可以增加美观度)
JavaScript 定义用户和网页的交互逻辑
前两大技术非数据分析重点,这里不加以赘述HTML 定义网页的结构和信息
写HTML一般使用Pycharm和Vscode等主流编辑器,我这里采用Vscode编辑器(打开速度很快)若将vscode的编辑器改成中文字体:
HTML 格式
< !DOCTYPE HTML> 告知浏览器该文件类型为HTML< html> html文件起始 表示开始(是HTML文档的根)< /html> html文件闭合 表示结束< head>…< /head> html标题 一般放 < title>…< /title> 定义HTML网页页面标题 < body>…< /body> html主体 一般放html标签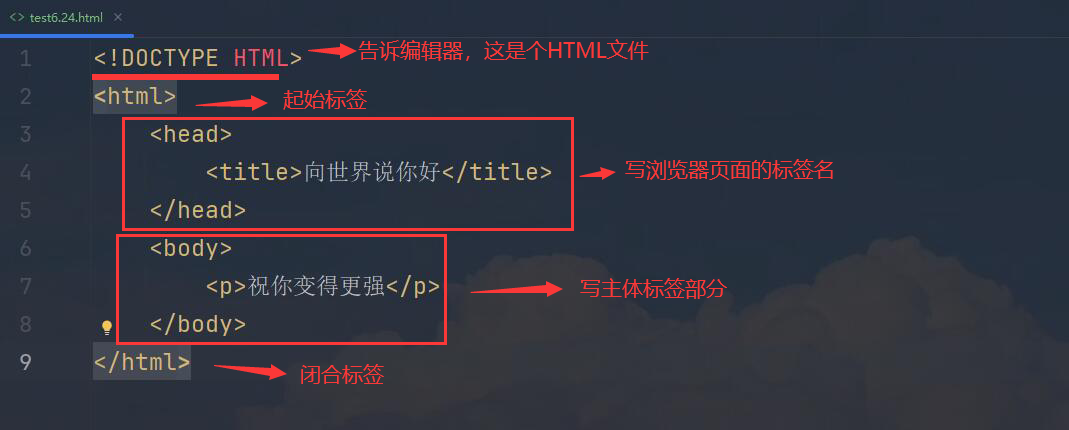
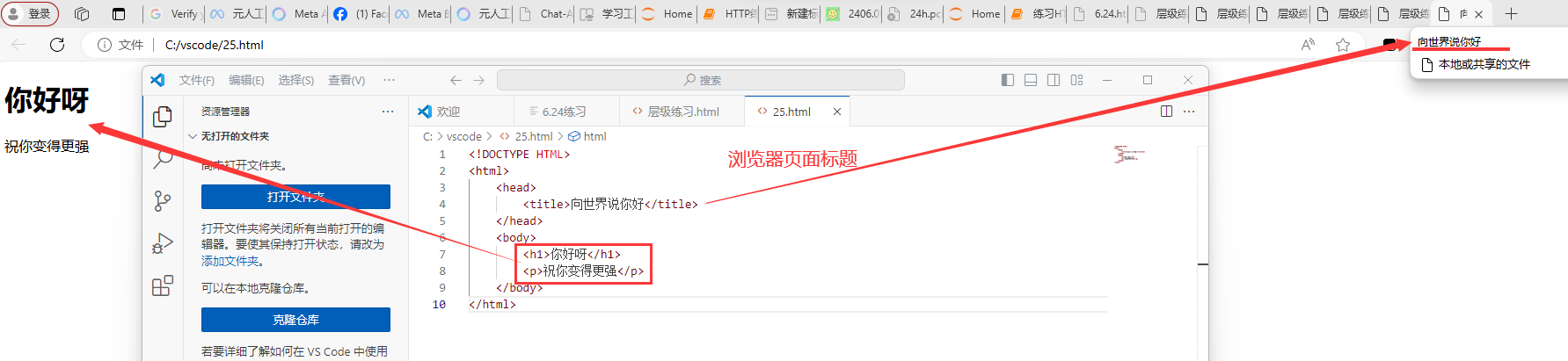
HTML 标签
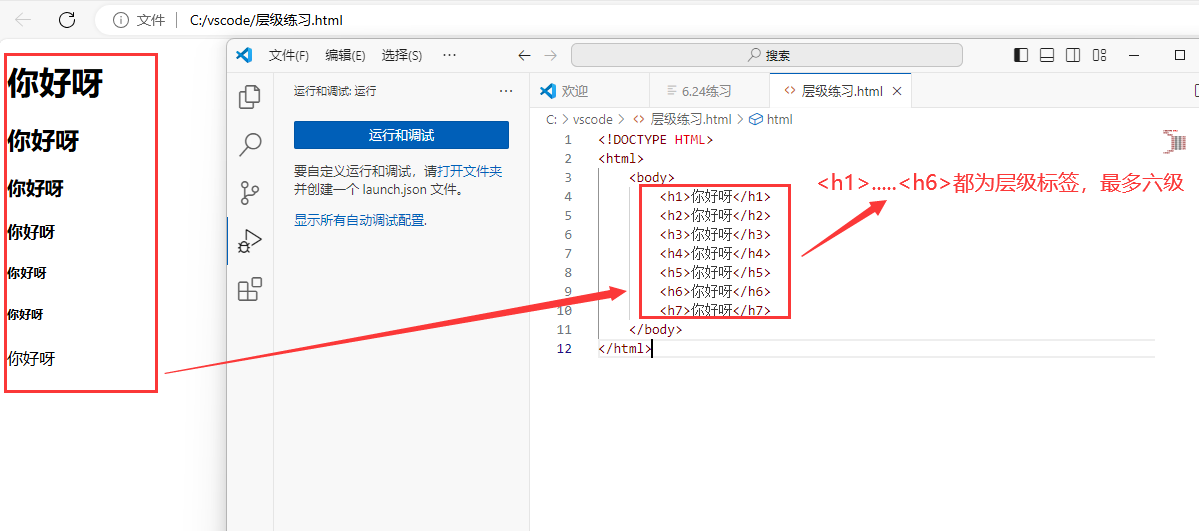
层级类标签
< h1>…< /h1> < h2>…< /h2> < h3>…< /h3> …… < h6>…< /h6> 表示文本层级
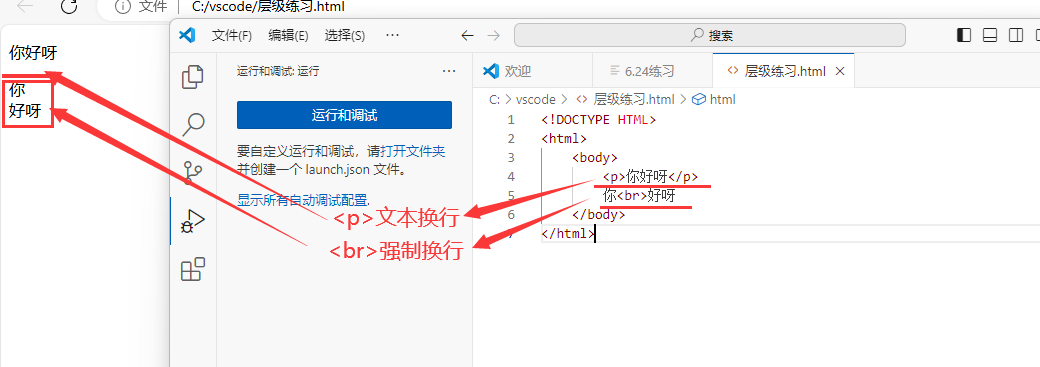
换行类标签
< p>…< /p> 默认换行
< br> 在文本段落中强制换行 且只有起始标签,没有闭合标签
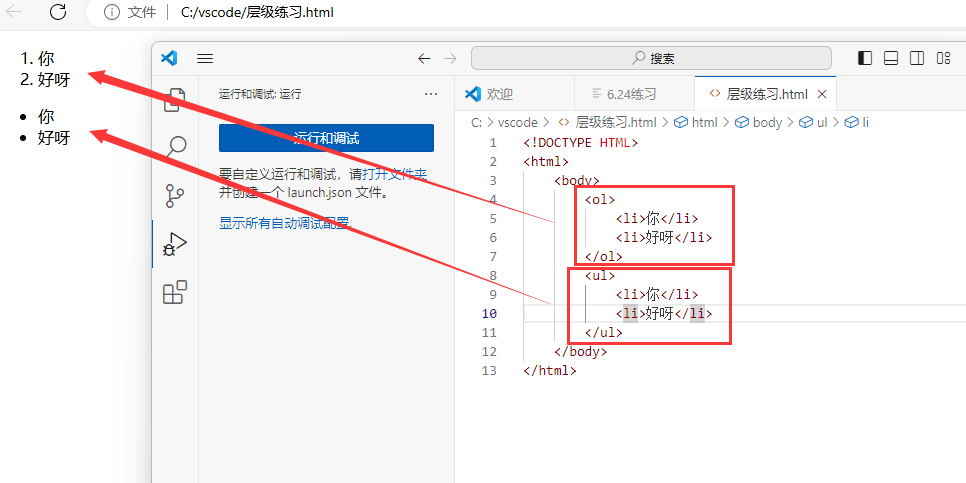
顺序类标签
< ol>…< /ol> 表示有序列表的标签
< ul>…< /ul> 表示无序列表的标签
文字类标签
< b>…< /b> 进行文字加粗
< i>…< /i> 将文字变成斜体
< u>…< /u> 将文字加下划线
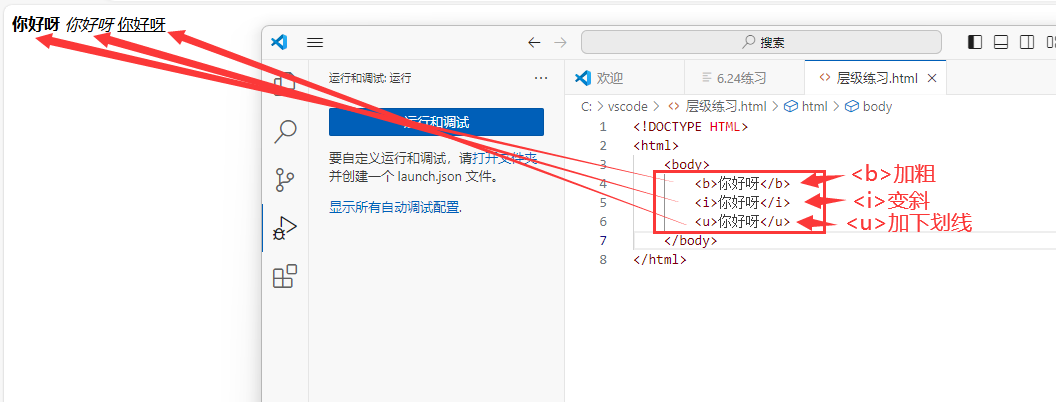
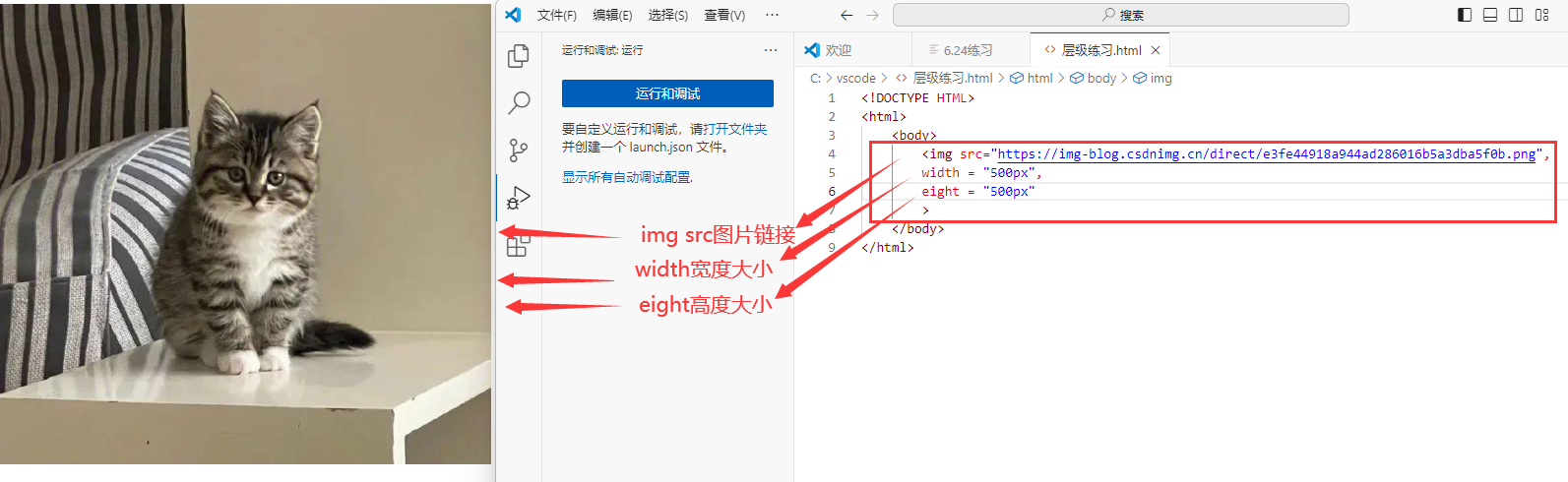
图片类标签
< img src=" 图片路径"> 添加图片
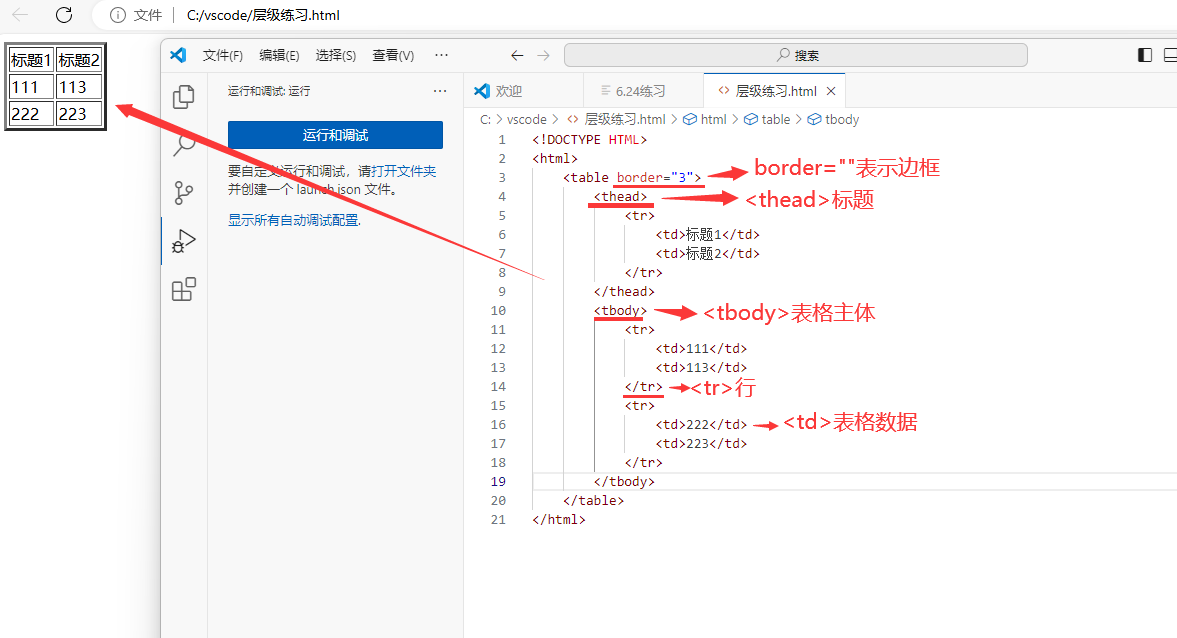
表格类标签
< table> …< /table> 表示表格
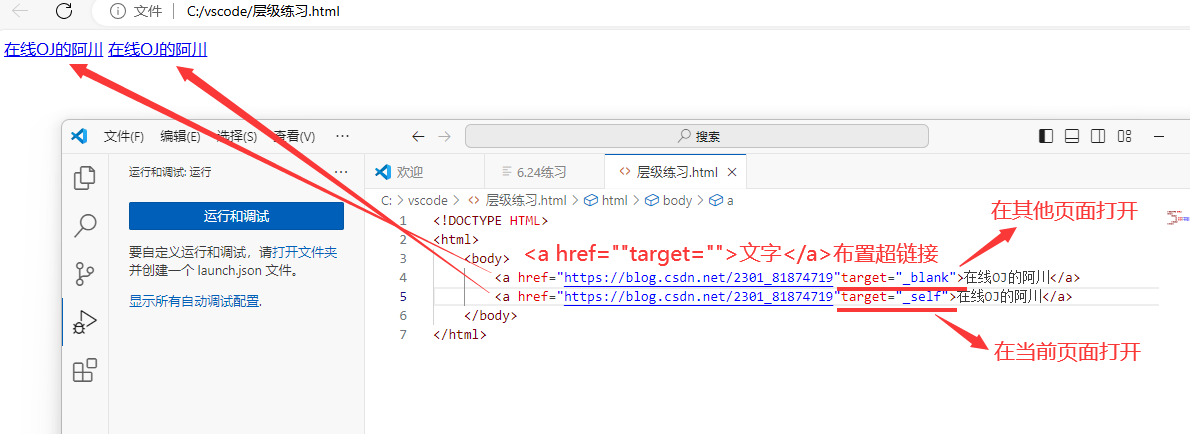
链接类标签
< a href=“路径”>自定义输出 文字 < /a> 添加超链接
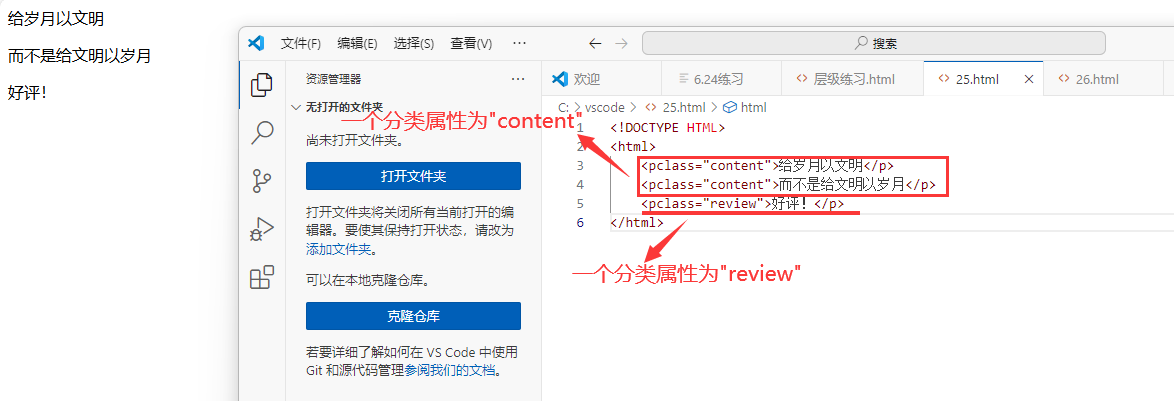
class属性
定义元素的类名称,从而帮助分组例如:
< pclass=“content”>给岁月以文明< /p>
< pclass=“content”>而不是给文明以岁月< /p>
< pclass=“review”>好评!< /p>
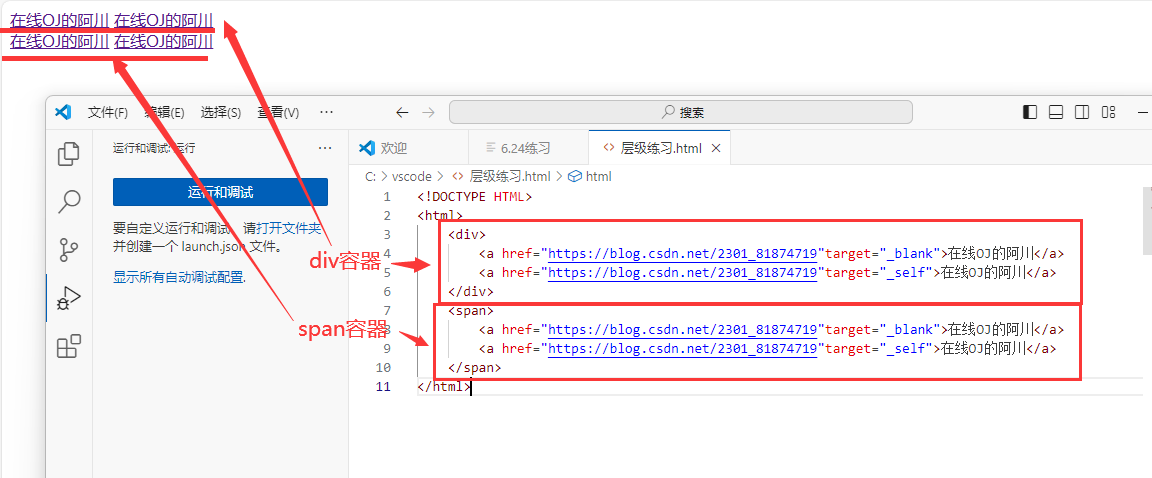
容器类标签
容器 本身不包含任何内容
< div>…< /div> 块级元素,独占自己的一块,一行最多一个< div>作为其中子元素
< span>…< /span> 内联元素,不会独占一块,一行可以多个span元素
HTML元素类型很多
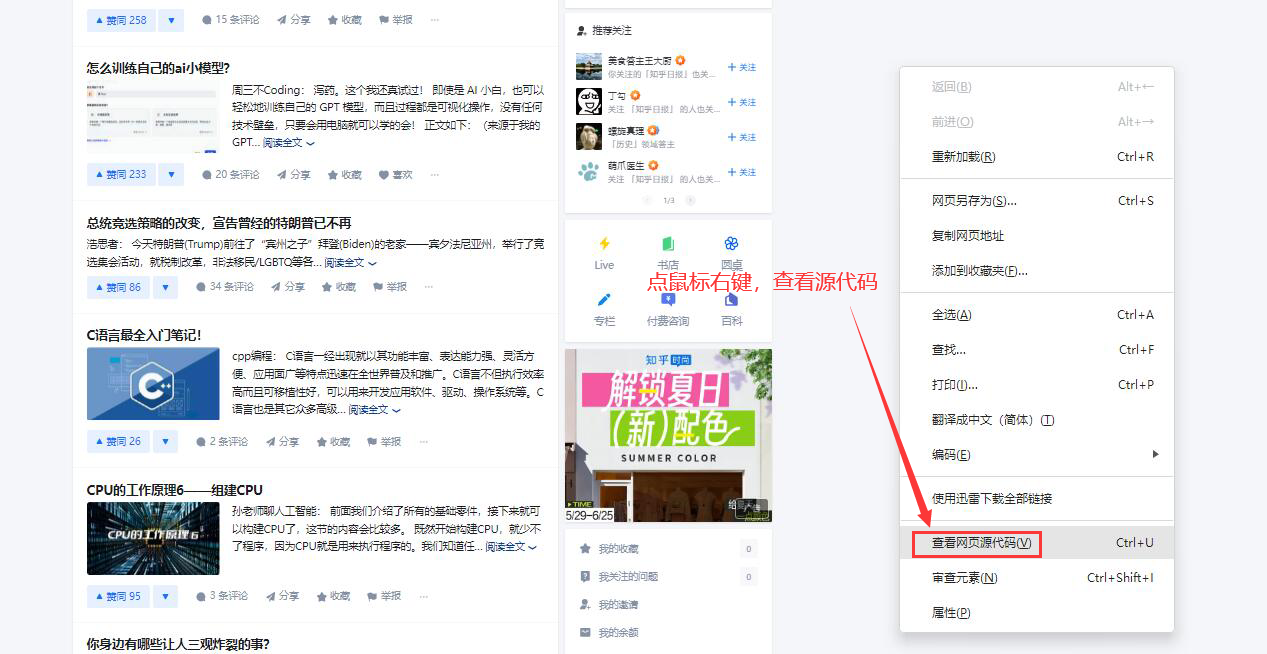
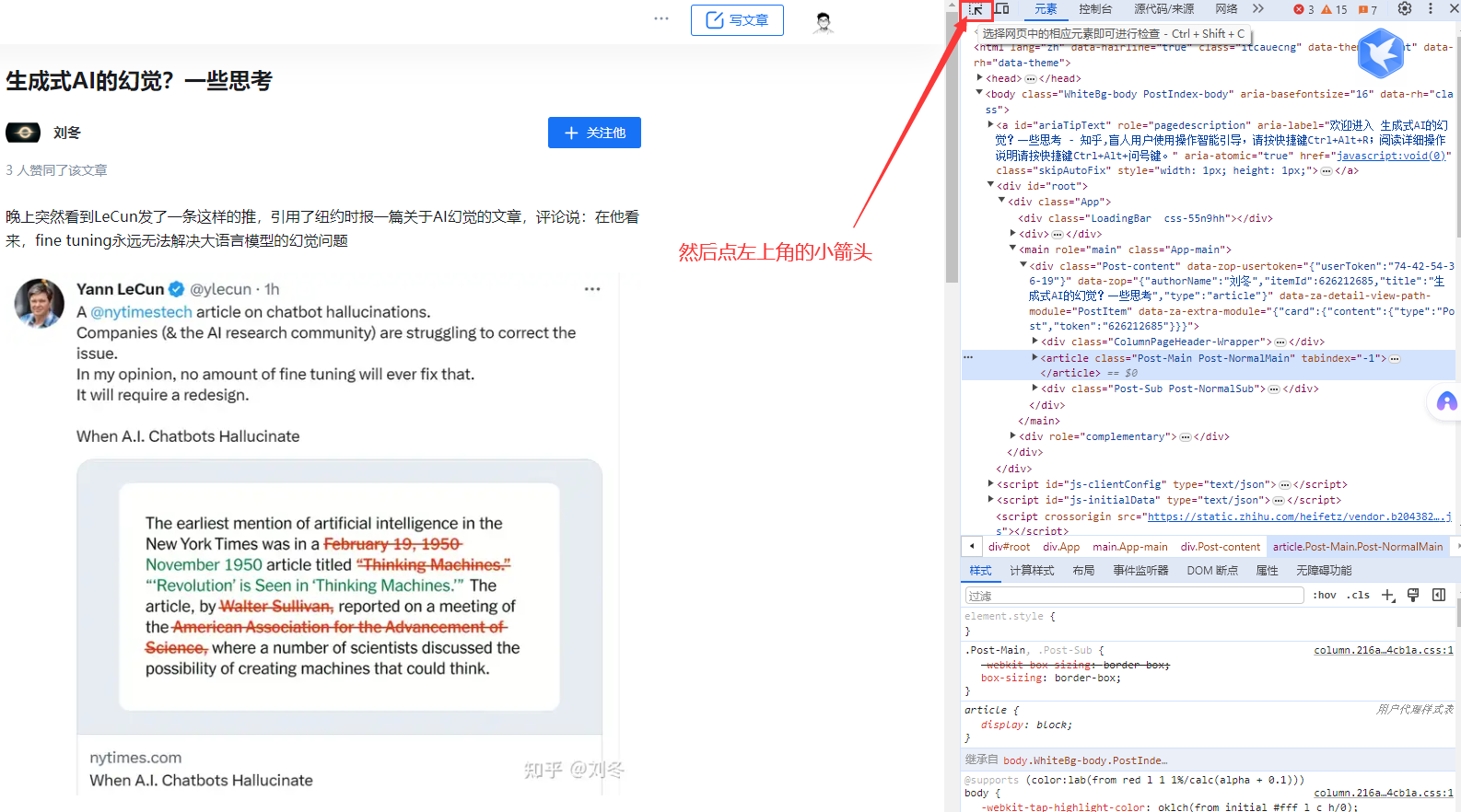
可以在浏览器里点击右键(显示网页源代码)
或者
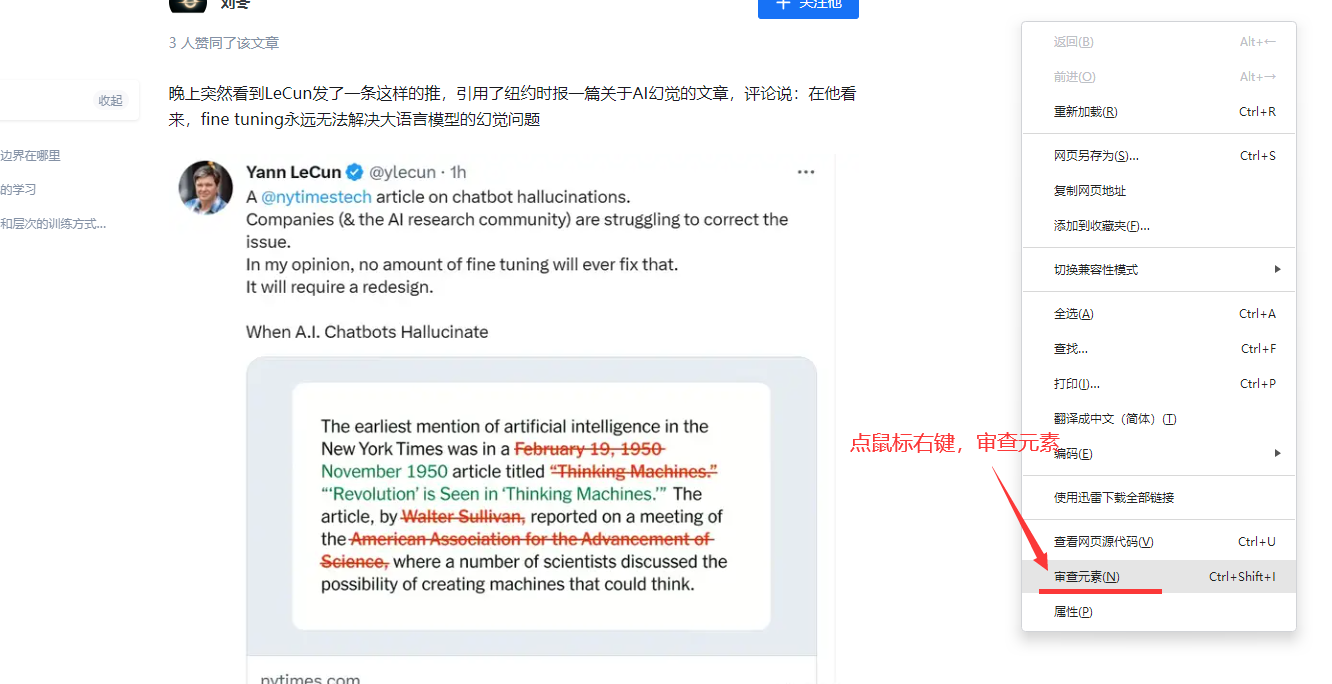
可以在浏览器点击右键(检查,再点一下窗口左上角小箭头,这样点击页面任何一个东西都会显示其元素)
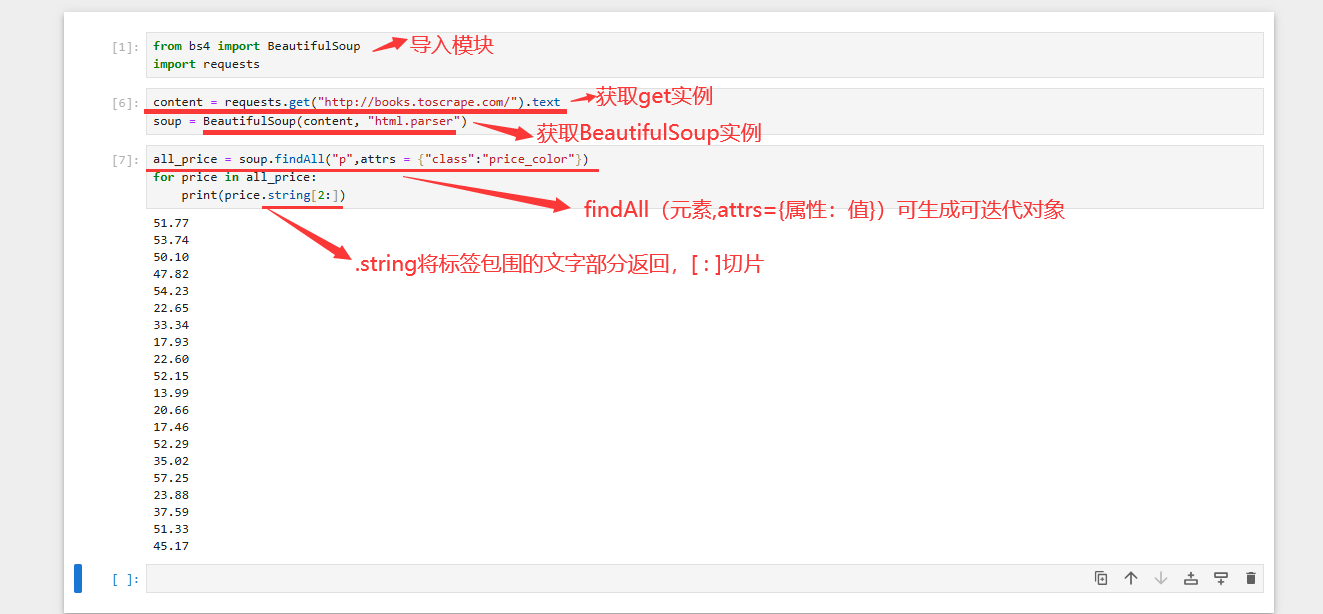
BeautifulSoup函数(get实例,“html.parser”)
“html.parser” 为解析器会生成BeautifulSoup实例该实例包含特别多的方法和属性
例如:
BeautifulSoup实例.p 获取html第1个p元素
BeautifulSoup实例.img 获取htm还有一个img图片元素

soup.fillAII() 能根据标签属性等方法找出所有符合要求的元素
(“标签”,attrs={“想找的属性”:" 想找的值"}) 返回可迭代对象可迭代对象.string属性 将标签包围的文字返回 还可以使用切片[ : ]find() 可获取第一个对象
爬虫技术要求,要随机应变,爬取自己想要的信息,爬虫总需要我们跟网站斗智斗勇
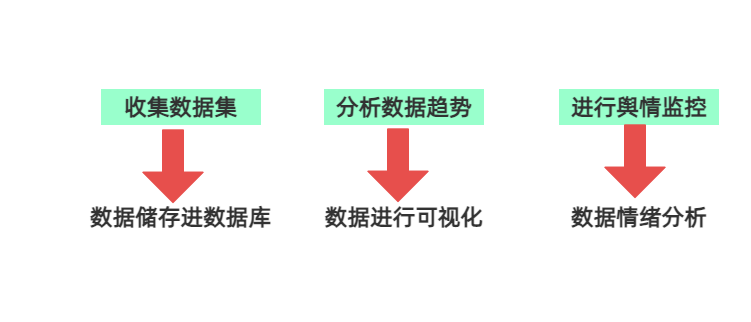
第三步 储存式分析数据(由于具体需求具体处理,这里不加以赘述)若要收集数据集 则将数据储存进数据库
若要分析数据趋势 则将数据进行可视化
若要舆情监控 则将AI文本情绪分析
项目实战一
项目实战-爬取豆瓣电影TOP250源代码数据,已上传到GitHub
本人CSDN博客主页资源上也有该项目实战
项目简介:
爬取豆瓣电影TOP250源代码数据-项目实战7-爬取源代码数据-ipynb格式-Python语法-用Jupyter notebook打开
用来练习如何爬取源代码数据,可用Pycharm,也可用 Jupyter notebook进行编写代码,相关代码已给出,拿到豆瓣电影TOP250页面的源代码之后,从而方便项目实战二 进一步爬取标题数据
项目实战二
项目实战-爬取豆瓣电影标题数据,已上传到GitHub
本人CSDN博客主页资源上也有该项目实战
项目简介:
爬取豆瓣电影标题数据-项目实战8-爬取豆瓣网页标题数据-ipynb格式-Python语法-用Jupyter notebook打开
用来练习网络爬虫爬取豆瓣网页TOP250电影标题和获取源代码,整个流程特别清晰
每个步骤均用Makedown编辑器进行编辑文字,部分环节加以图片说明,每一步都给出了清晰的代码
可以按照步骤一步一步进行模仿,理解其中的思维逻辑,然后上手进行操作,在操作的过程中不断思考
等能力有了很大提升之后,就可以慢慢独立思考从事项目了
好的,到此为止啦,祝您变得更强

想说的话
实不相瞒,写的这篇博客写了13个小时以上(加上自己学习(反复学习了5遍)和纸质笔记(写了满满的6页),共十五小时吧),很累,希望大佬支持
| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 大佬的支持和鼓励,将是我成长路上最大的动力  |