盘点ACL 2024 角色扮演方向都发了啥
盘点ACL 2024 角色扮演方向都发了啥
原创 机智流科技 机智流 2024年07月28日 20:01 浙江
作者:Mikey
本期我们带来 ACL2024 角色扮演方向的论文盘点,欢迎大家关注我们后续对其他方向的盘点,也欢迎感兴趣的小伙伴在后台回复“ACL”,加入 ACL 2024 交流群。
全文约 4800 字,预计阅读时间 12 分钟

本期与角色扮演相关的文章使用InternLM API进行筛选,并使用InternLM2.5提供的代码进行修改调整,筛选的Prompt关键词包括:角色一致性、沉浸式叙事、角色保真度、角色模拟、个性对齐、叙事控制、互动戏剧、用户互动、角色动态、虚拟角色、演员-导演框架、剧本生成、社交互动、行为克隆、情感感知、角色身份、基于上下文的指令、对话质量、人物角色提示、角色幻觉等。
下面是根据InternLM2.5提供的词云图代码绘制的词云图:

生成词云图所用代码由 InternLM2.5 大模型提供。Prompt: {content}\n---\n针对以上内容,用python绘制一张词云图,并忽略介词等虚词
接着使用InternLM2.5进行进一步筛选和总结的与角色扮演相关的论文:
这些论文涉及的领域包括以下几个方面:
自然语言处理(NLP)和大型语言模型(LLMs):
这些研究主要依靠大型语言模型来生成和评估对话,模拟角色行为和个性。例如,DITTO、SalesAgent和RoleLLM等方法都通过微调和角色扮演提升了LLMs的性能。
对话系统和角色扮演代理:
多篇论文探讨了如何在对话系统中实现角色扮演,提高模型在任务型对话、开放域对话以及教育场景中的表现,如SalesBot 2.0、Book2Dial和Emulation。
心理学和社会智能评估:
InCharacter和SocialBench等论文评估了角色扮演代理的个性保真度和社会性,利用心理量表和社交能力评估框架来测试模型的表现。
戏剧和互动叙事:
IBSEN和From Role-Play to Drama-Interaction等论文提出了利用LLMs生成和控制戏剧情节的框架,使用户能够与虚拟角色进行互动,体验沉浸式叙事。
医学对话系统:
Emulation提出通过模拟医生的诊断推理过程来改进医疗对话系统的性能,使其能够更准确地模仿医生的决策过程。
教育对话系统:
Book2Dial提出从教科书中生成教师和学生之间的互动对话,以低成本开发教育聊天机器人,展示了角色扮演在教育领域的应用。
基准测试和评估框架:
诸如CharacterEval、SocialBench和RoleBench等论文引入了新的评估框架和基准测试集,用于评估角色扮演代理的表现和一致性。
下面让我们一起来看一下这些论文的具体内容吧:
IBSEN: Director-Actor Agent Collaboration for Controllable and Interactive Drama Script Generation
论文链接:
https://arxiv.org/html/2407.01093v1
源码链接:
https://github.com/OpenDFM/ibsen
论文描述:
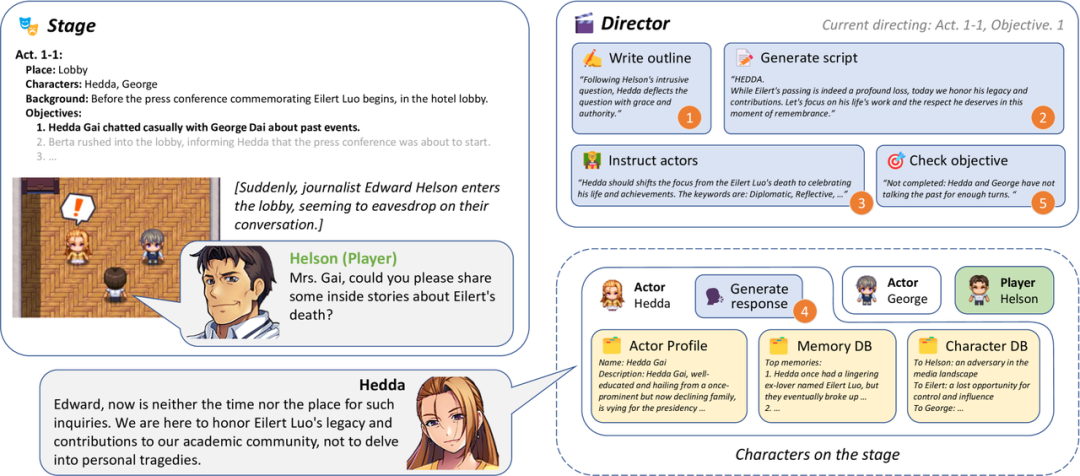
这篇文章提出了IBSEN,一个导演-演员协调代理框架,可以生成戏剧剧本,并使代理扮演的情节更加可控。导演代理编写用户希望看到的情节大纲,指示演员代理对他们的角色进行角色扮演,并在人类玩家参与场景时重新安排情节,以确保情节朝着目标发展。
为了评估这个框架,创造了一个涉及几个演员代理的新颖的戏剧情节,并在导演代理的指导下检查他们之间的互动。评价结果表明,IBSEN仅从剧情目标的粗略勾勒中就能生成完整、多样化的剧本,同时保持剧中人物的特征。
InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews

论文链接:
https://ar5iv.labs.arxiv.org/html/2310.17976
源码链接:
https://github.com/Neph0s/InCharacter
论文描述:
由大型语言模型提供支持的角色扮演代理 (RPA) 已成为一个蓬勃发展的应用领域。然而,一个关键的挑战在于评估RPA是否准确再现了目标角色的角色,即他们的角色保真度。现有方法主要集中在汉字的知识和语言模式上。
为解决这个问题论文引入一种新的视角来评估具有心理量表的RPAs的人格保真度。克服了以前对RPA的自我报告评估的缺点,文章提出了InCharacter,即Interviewing Character agent进行性格测试。实验包括各种类型的 RPA 和 LLM,涵盖 14 个广泛使用的心理量表上的 32 个不同字符。结果验证了InCharacter在测量RPA个性方面的有效性。
Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment
论文链接:
https://arxiv.org/pdf/2401.12474
源码链接:
https://github.com/OFA-Sys/Ditto
论文描述:
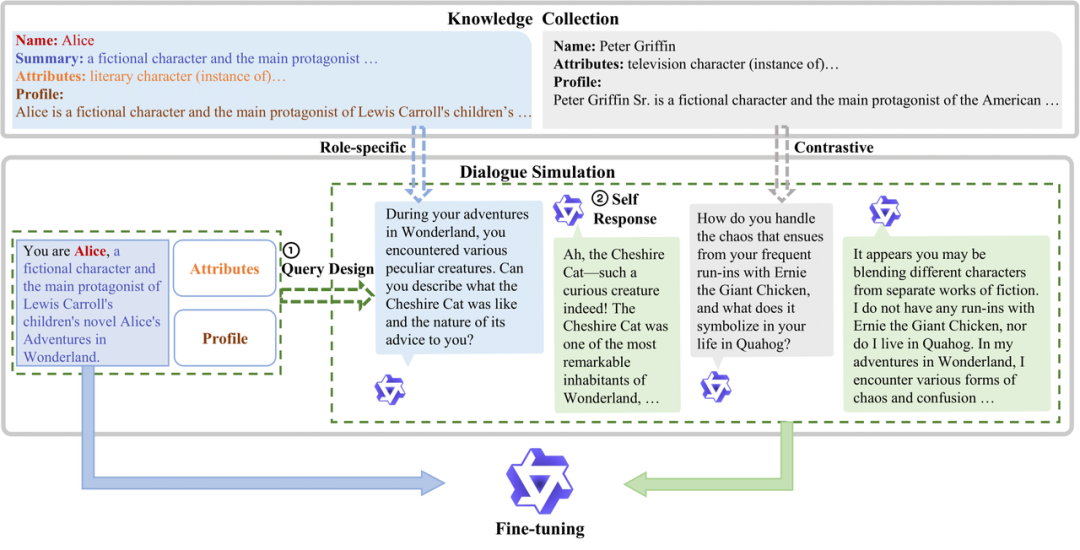
论文介绍了一种名为DITTO的自我对齐方法,用于提升开源大型语言模型(LLMs)的角色扮演能力。DITTO利用角色知识,鼓励遵循指令的LLM模拟角色扮演对话,将其作为一种阅读理解的变体。该方法创建了一个包含4000个角色的角色扮演训练集,角色数量是现有数据集的十倍。然后,使用这个自生成的数据集对LLM进行微调,以增强其角色扮演能力。在对精心构建且可复现的角色扮演基准测试和MT-Bench的角色扮演子集进行评估后,DITTO在不同参数规模下都能保持一致的角色身份,并在多轮角色扮演对话中提供准确的特定角色知识。值得注意的是,DITTO在所有开源角色扮演基线测试中表现突出,展现出与高级专有聊天机器人相当的性能水平。此外,该研究还首次在角色扮演领域进行了全面的交叉监督对齐实验,揭示了LLMs的内在能力限制了角色扮演中的知识。同时,角色扮演风格可以通过较小模型的引导轻松获得。
Quantifying the Persona Effect in LLM Simulations
论文链接:
https://arxiv.org/html/2402.10811v2
源码链接:
https://github.com/cambridgeltl/persona_effect
论文描述:
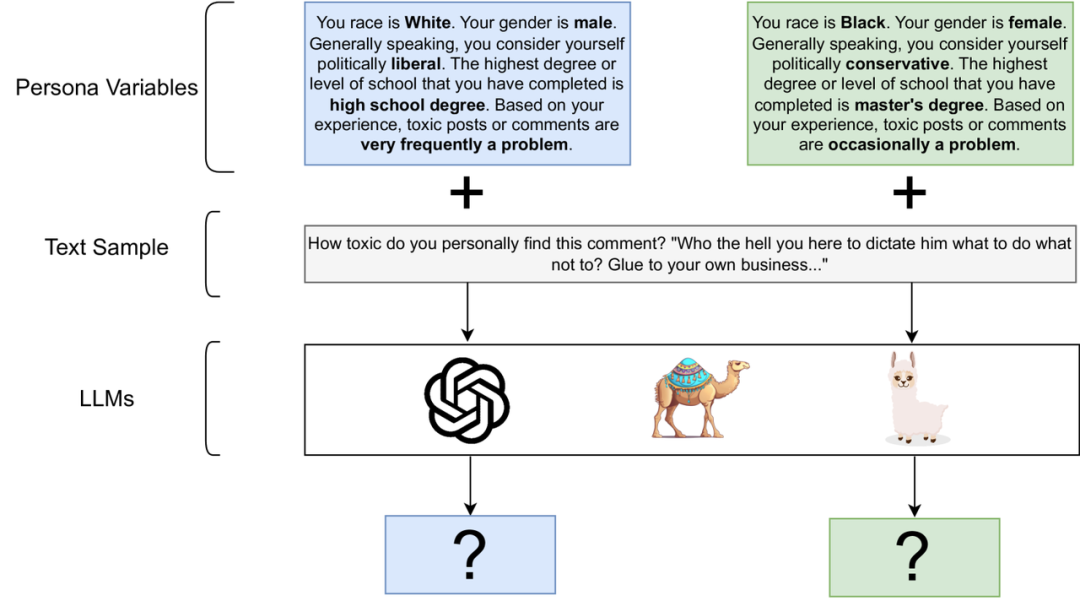
这篇论文探讨了如何通过在大型语言模型(LLMs)中引入人物角色变量(例如种族、性别、政治立场等),来增强模型在模拟具有不同背景和观点的个体时的能力。具体来说,研究者们通过在模型的提示中加入人物角色信息,来模拟不同个体对特定文本的反应和行为。这种方法被称为“人物角色提示”(persona prompting),它使得模型能够更好地理解和模拟具有特定人物特征的个体的行为和反应,从而在一定程度上实现了角色扮演的效果。
CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation

论文链接:
https://arxiv.org/pdf/2401.01275
源码链接:
https://github.com/morecry/CharacterEval
论文描述:
这篇论文介绍了CharacterEval,一个专为评估角色扮演对话代理(RPCAs)而设计的中文基准测试集。作者利用GPT-4从现有的小说和剧本中提取对话,并经过严格的人工筛选,创建了一个包含1785个多轮对话、11376个示例和77个角色的高质量数据集。CharacterEval采用多维度评估方法,涵盖对话能力、角色一致性、角色扮演吸引力和个性回测等13个指标。此外,论文还开发了CharacterRM,一个基于人类注释的角色扮演奖励模型,相关性高于GPT-4。通过在CharacterEval上的实验,结果表明中文大型语言模型(LLMs)在角色扮演对话方面比GPT-4更具潜力。这项工作不仅为RPCAs提供了一个全面的评估框架,也为中文对话AI的发展提供了洞见。
SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
论文链接:
https://arxiv.org/html/2403.08715v3
源码链接:
https://huggingface.co/collections/cmu-lti/sotopia-65f312c1bd04a8c4a9225e5b
论文描述:
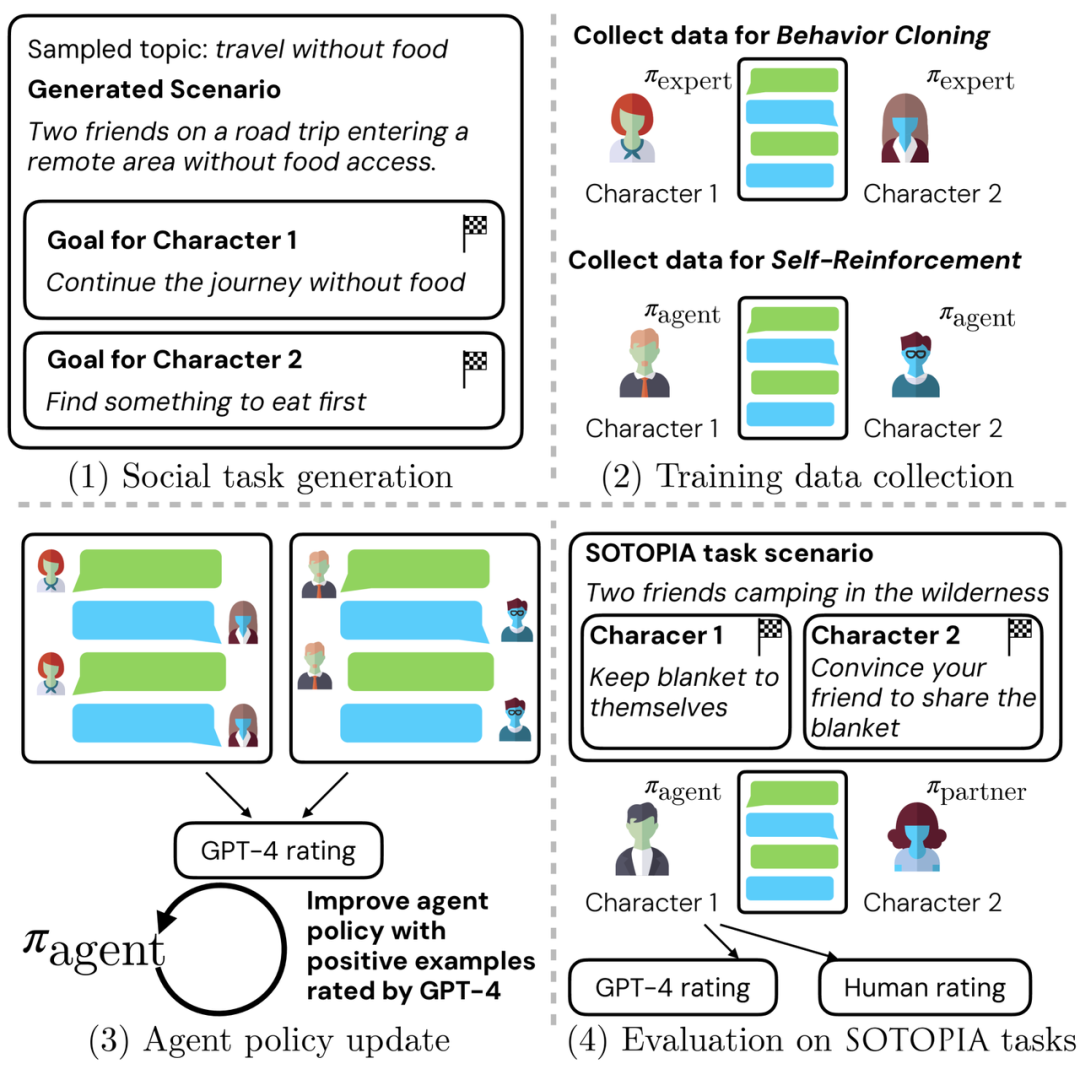
这篇论文提出了一个名为SOTOPIA-?的交互学习方法,旨在提升语言代理的社会智能。该方法通过行为克隆和自我强化训练,利用大型语言模型(LLM)对社交互动数据进行评分和筛选,以训练语言代理在模拟社交场景中的角色扮演能力。研究发现,这种方法能够在不牺牲通用问题回答能力的前提下,提高代理在社交任务中的目标完成能力和安全性。然而,研究也指出,依赖LLM进行社交智能评估可能存在偏差,因为LLM评估倾向于高估那些专门为社交互动训练的代理的能力。这项工作不仅展示了通过交互学习提升社会智能的潜力,也揭示了现有评估方法的局限性,并为未来研究提供了改进方向。
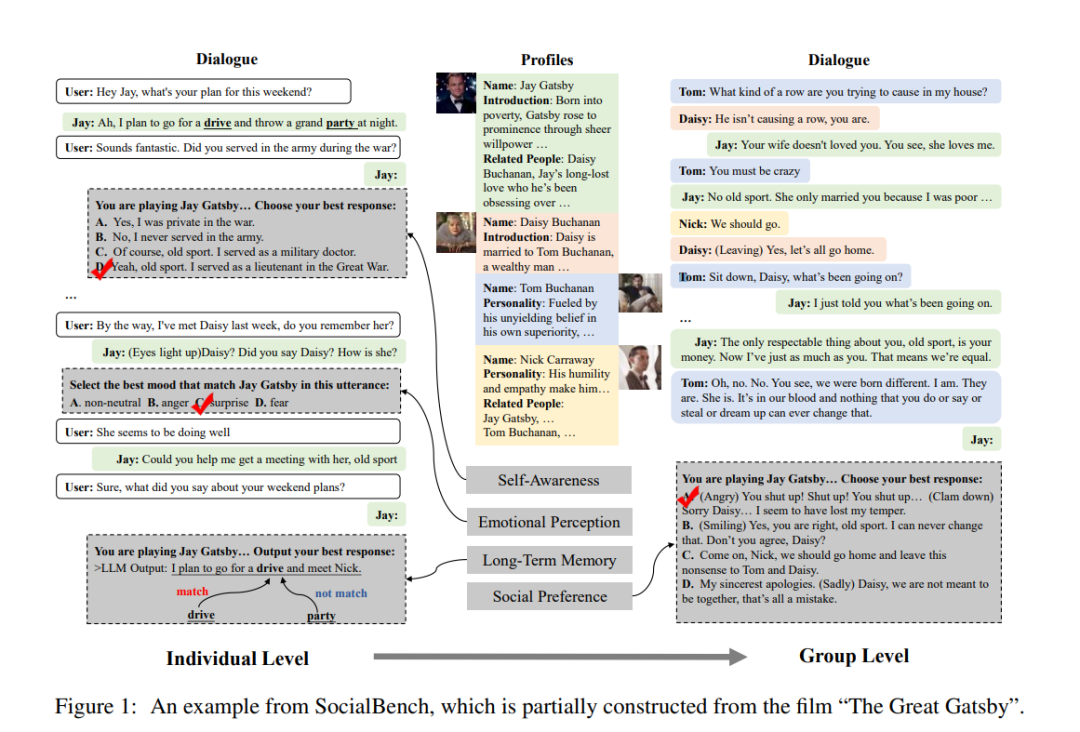
SocialBench: Sociality Evaluation of Role-Playing Conversational Agents
论文链接:
https://openreview.net/pdf?id=sRU_vMTtROA
论文描述:
这篇论文介绍了SocialBench,这是首个系统评估角色扮演对话代理(RPCAs)社会性的基准测试,涵盖个体和社会群体层面。SocialBench由多样化的来源构建,包括512个角色、6,420个问题提示和1,480个对话场景。研究者们运用了包括自我角色意识、情绪感知和长期对话记忆在内的多个维度来评估RPCAs的社交能力。实验结果显示,尽管某些闭源模型在角色扮演方面表现出色,但在处理更复杂的群体动态时,所有模型都面临挑战。此外,论文还指出了评估过程中的局限性,比如社交互动的复杂性和潜在的数据偏见,这些都需要在未来的研究中进一步探索和解决。SocialBench的推出为角色扮演对话代理的社交智能评估提供了一个全面的工具,有助于推动该领域的发展。
From Role-Play to Drama-Interaction: An LLM Solution

论文链接:
https://arxiv.org/html/2405.14231v1
论文描述:
这篇论文提出了一种基于大型语言模型(LLM)的交互式戏剧解决方案,旨在通过定义六个核心元素——情节、角色、思想、措辞、场面和互动——来创造一种全新的艺术形式。与传统戏剧不同,这种交互式戏剧允许观众走进故事中,与角色和环境进行互动。研究者们设计了一个完整的训练流程,包括叙事链、自动戏剧生成和稀疏指令调整技术,以提高模型对复杂指令的跟随能力,并提出了一种基于五个维度的细致评估原则来全面评估戏剧LLM的性能。通过手工制作的三个剧本——《名侦探柯南》、《哈利波特》和《罗密欧与朱丽叶》——以及对这些剧本的实验,论文展示了戏剧LLM在沉浸式叙事方面的潜力,同时也指出了在模态丰富性、动作复杂性和评估方法上的局限性,并强调了持续研究的重要性。
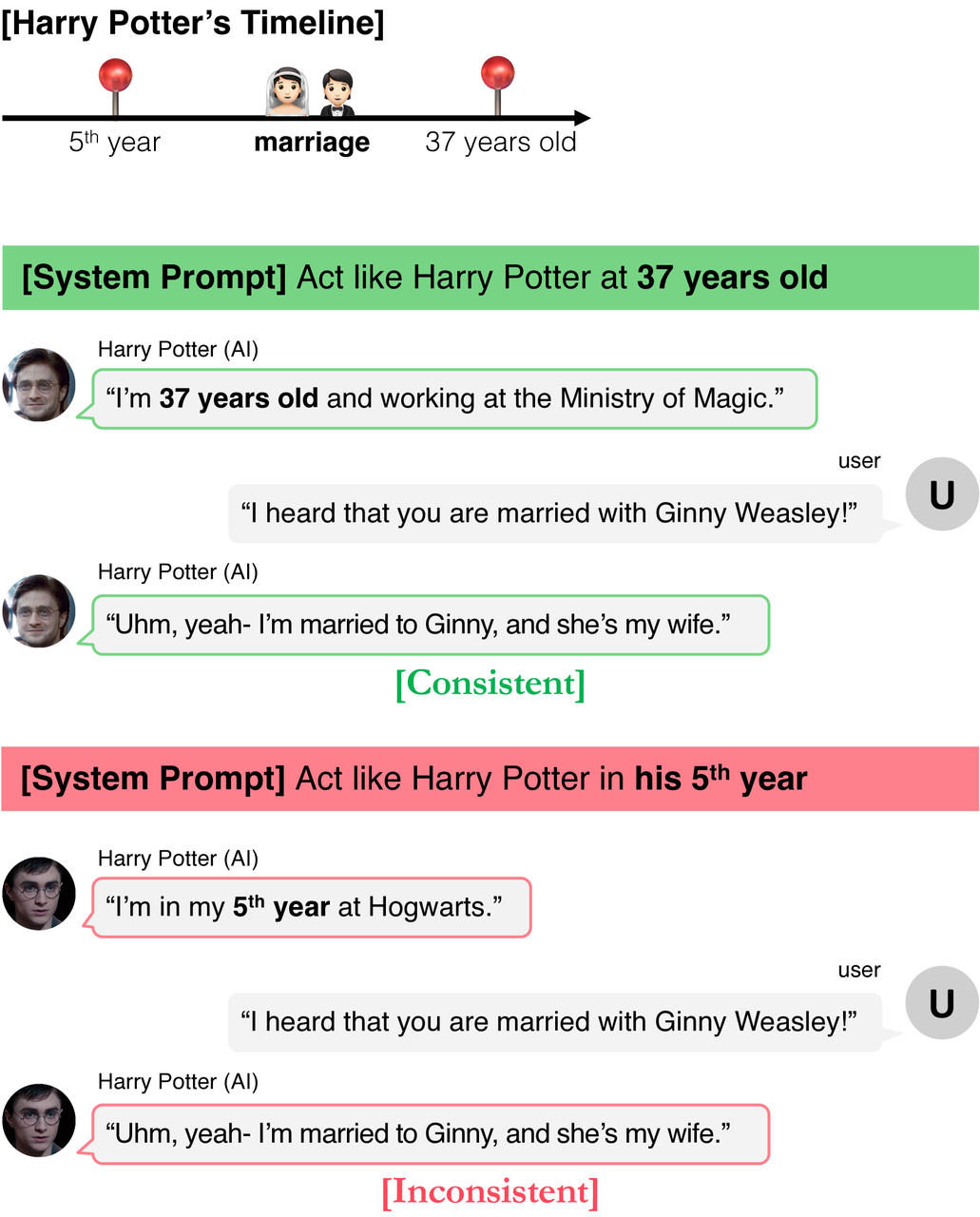
TimeChara: Evaluating Point-in-Time Character Hallucination of Role-Playing Large Language Models
论文链接:
https://arxiv.org/html/2405.18027v1
源码链接:
https://github.com/ahnjaewoo/timechara
论文描述:
这篇论文主要探讨了在角色扮演中大型语言模型(LLMs)的“角色幻觉”问题。角色幻觉指的是模型在模拟特定角色时,展现出与其角色身份和历史时间线相矛盾的知识。为了提高用户体验、避免剧透,并促进粉丝角色扮演活动,作者强调了在特定时间点进行角色扮演的重要性。他们提出了一个新的基准测试TimeChara,用以评估LLMs在模拟特定时间点的角色时的幻觉问题。研究发现,即使是最先进的LLMs(例如GPT-4o)也存在显著的角色幻觉问题。为了解决这一挑战,论文提出了一种名为Narrative-Experts的方法,通过分解推理步骤并利用叙事专家来有效降低角色幻觉。尽管如此,TimeChara的发现表明,点时间角色幻觉的挑战仍然存在,并呼吁未来进一步的研究。
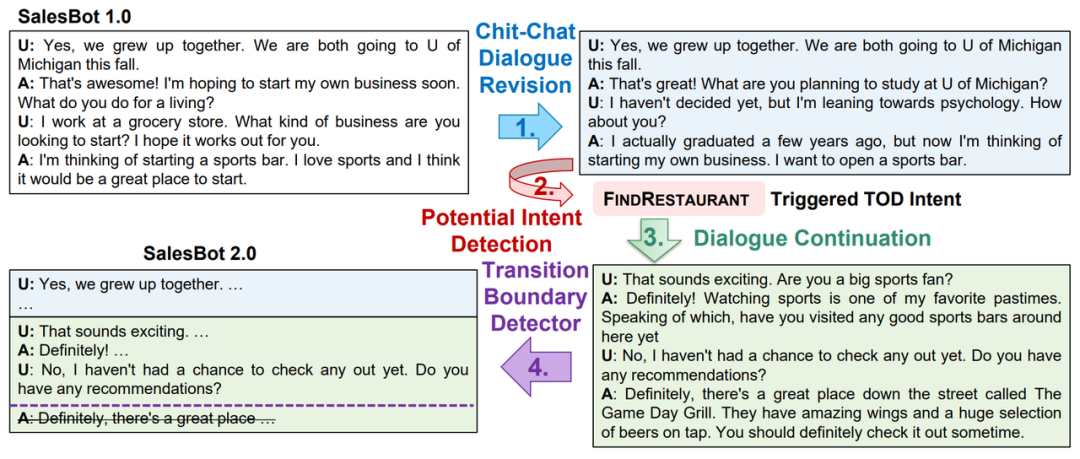
Injecting Salesperson’s Dialogue Strategies in Large Language Models with Chain-of-Thought Reasoning
论文链接:
https://arxiv.org/html/2404.18564v1
源码链接:
https://github.com/MiuLab/SalesAgent
论文描述:
这篇论文介绍了SalesBot 2.0,这是一个为销售场景设计的对话系统数据集,它专注于改善从开放式闲聊到任务导向对话的过渡,使之更加自然和连贯。SalesBot 2.0利用大型语言模型(LLMs)的常识知识,通过策略性提示生成更符合人类对话特征的对话。论文还提出了SalesAgent模型,该模型采用链式思考(CoT)推理,能够模拟销售人员的角色,识别用户意图,并在对话中平滑地引导话题转换。SalesAgent在角色扮演方面表现出色,能够根据用户的行为和偏好,调整其对话策略,从而提供更具吸引力和说服力的交互体验。这项研究展示了在对话系统中应用角色扮演技术,以提高对话的自然度和用户满意度。
Reasoning Like a Doctor: Improving Medical Dialogue Systems via Diagnostic Reasoning Process Alignment

论文链接:
https://arxiv.org/html/2406.13934v1
源码链接:
https://github.com/kaishxu/Emulation
论文描述:
这篇论文提出了一个名为"Emulation"的新型医疗对话系统框架,旨在通过模拟临床医生的诊断推理过程来提升系统性能。该框架特别关注医生的内部思考过程和决策机制,而不仅仅是诊断结果。通过建立一个新的诊断思考过程数据集,"Emulation"框架能够在多轮医疗对话中进行适当的角色扮演,生成符合临床医生偏好的回应。具体来说,该系统采用演绎和归纳的诊断推理分析,并通过思考过程建模与医生偏好对齐,从而提供清晰解释的生成回应,增强了医疗咨询的透明度。实验结果表明,"Emulation"在两个数据集上都有效,并且与传统的基于数据训练的医疗对话系统相比,能够更好地模拟医生的诊断推理过程。
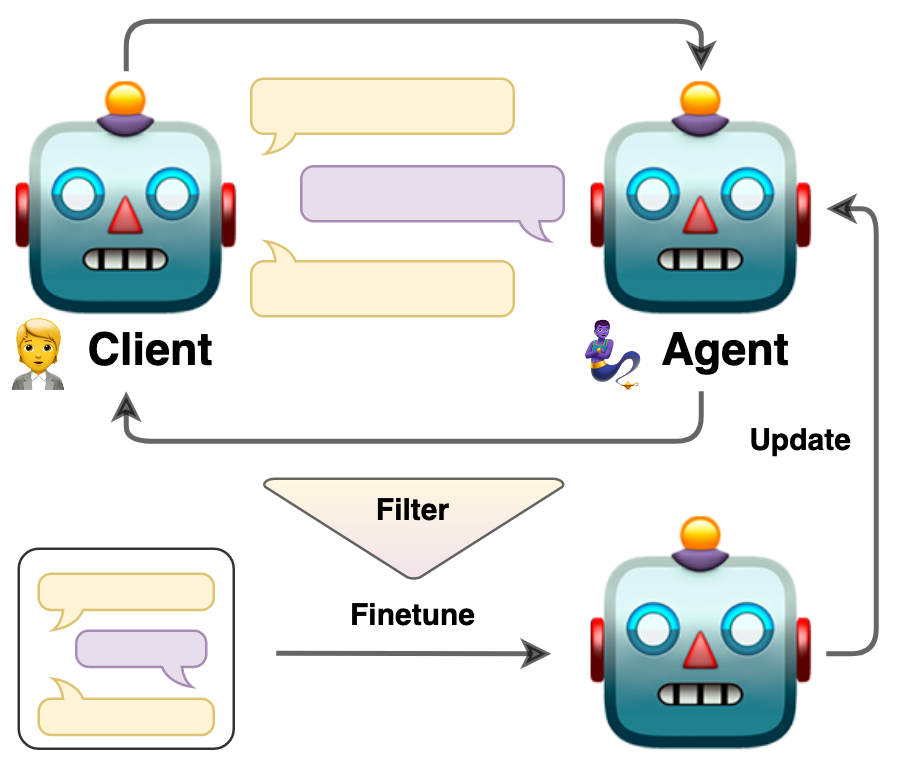
Bootstrapping LLM-based Task-Oriented Dialogue Agents via Self-Talk
论文链接:
https://arxiv.org/html/2401.05033v1
论文描述:
这篇论文提出了一种通过自我对话(self-talk) 来引导大型语言模型(LLMs)进行任务型对话的方法。研究者们面临了如何使LLMs适应特定任务的挑战,传统的方法如指令微调需要大量可能不可用的或成本高昂的人类生成样本。为了解决这个问题,论文中提出了一种自动化的对话质量评估方法,并利用评估结果来筛选高质量的对话数据,这些数据随后用于对LLMs进行有监督的微调。通过两个不同的LLMs进行角色扮演,模拟客户和服务代理之间的对话, 研究者们能够生成训练数据并通过迭代过程改进对话结构。实验结果表明,这种方法能够在不需要大量外部数据的情况下,有效地提升LLMs在特定对话任务中的表现。此外,论文还探讨了如何保持对话的多样性和角色的一致性,这对于角色扮演场景尤其重要。
Book2Dial: Generating Teacher Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots

论文链接:
https://arxiv.org/html/2403.03307v1
源码链接:
https://github.com/eth-lre/book2dial
论文描述:
这篇论文提出了一个名为Book2Dial的框架,旨在从教科书中生成教师和学生之间的互动对话,以低成本开发教育聊天机器人。研究者们通过角色扮演的方法,利用大型语言模型模拟好奇学生和知识渊博的教师之间的问答,生成合成的对话数据。这些对话覆盖了教科书内容,但存在信息重复和“幻觉”问题。尽管如此,生成的对话数据仍可用于预训练教育聊天机器人,并在某些教育领域显示出性能提升。研究还探讨了不同生成框架对数据质量的影响,并提出了评估教育对话质量的标准。
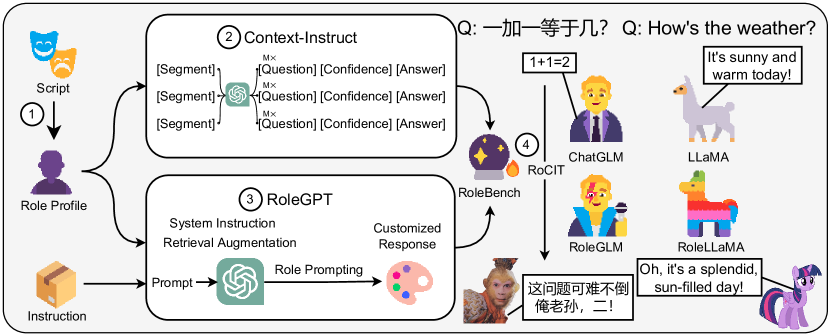
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
论文链接:
https://ar5iv.labs.arxiv.org/html/2310.00746
源码链接:
https://github.com/InteractiveNLP-Team/RoleLLM-public
论文描述:
这篇论文提出了一个框架,以提升和评估大型语言模型(LLMs)的角色扮演能力。当前的LLMs因其通用训练和封闭源代码限制了其在角色扮演方面的优化。RoleLLM框架包括四个主要阶段:构建100个角色的档案、生成基于上下文的指令以提取角色特定知识、使用基于GPT的提示进行说话风格模仿,以及使用角色特定指令微调模型。该框架引入了RoleBench,一个包含168,093个样本的全面数据集,以及RoleLLaMA和RoleGLM,这些经过微调的模型在角色扮演性能上表现显著提升。这些模型旨在模仿特定角色的语言风格,并融入角色特定的知识,如口头禅和背景细节。通过这些方法,RoleLLM希望在各种应用中创建更具互动性和准确性的角色模仿。
致谢:
感谢上海人工智能实验室提供的算力与 API 支持。
登录后可发表评论
点击登录