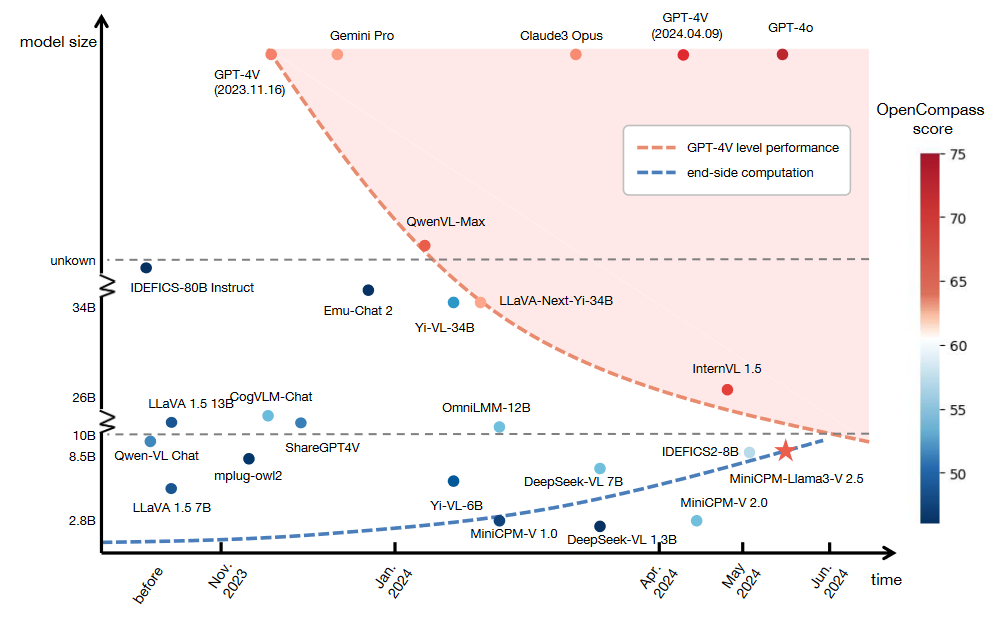
MiniCPM-V | 端侧GPT4V level的多模态大模型
论文标题:MiniCPM-V: A GPT-4V Level MLLM on Your Phone
论文模型版本:MiniCPM-Llama3-V 2.5
论文地址:https://arxiv.org/abs/2408.01800
论文github:https://github.com/OpenBMB/MiniCPM-V
MiniCPM-V-2.6已经开源,经过测试效果确实很好,但是论文还没有出来,因此先看看v2.5
一、模型结构
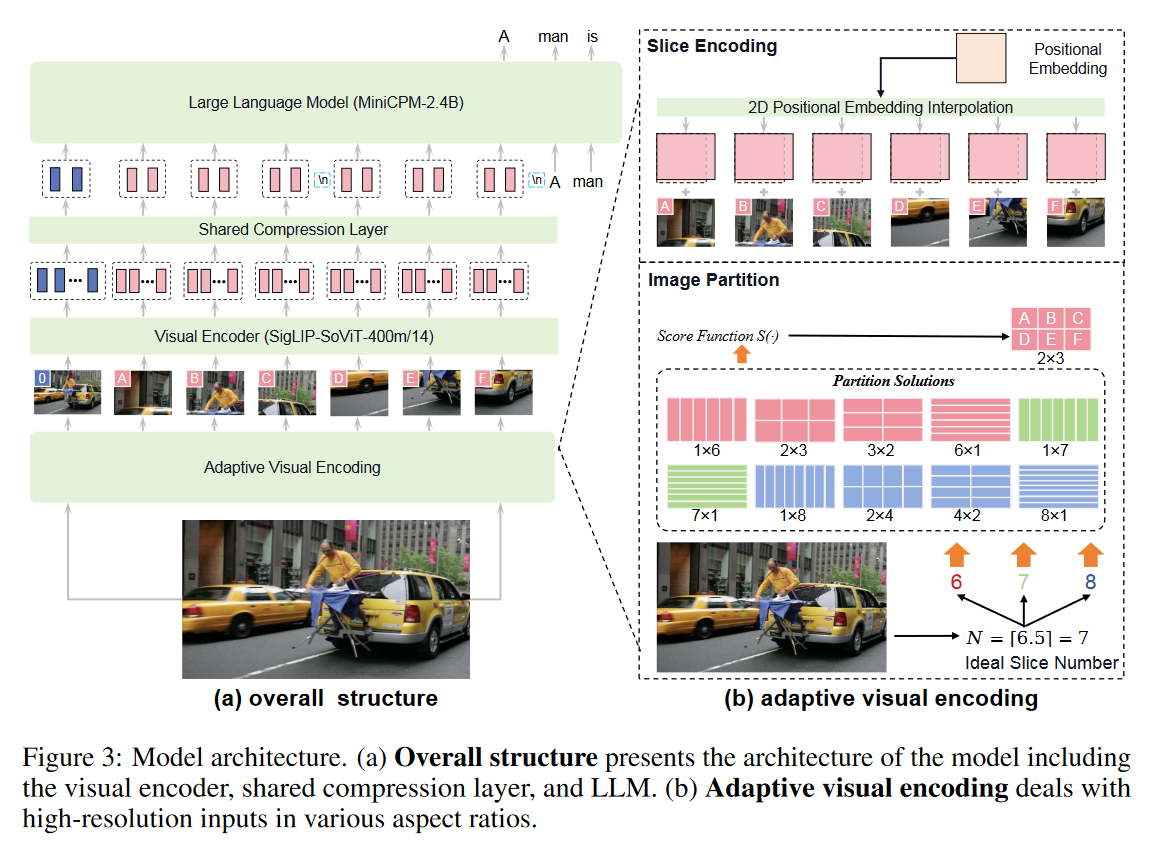
视觉编码器(SigLIP SoViT-400m/14)+ compression layer + LLM(MiniCPM-2.4B)
1、Adaptive Visual Encoding
良好的视觉编码策略应该既尊重输入的原始纵横比,又保留足够的视觉细节(高分辨率),又要图像编码中的视觉标记数量应该适中,
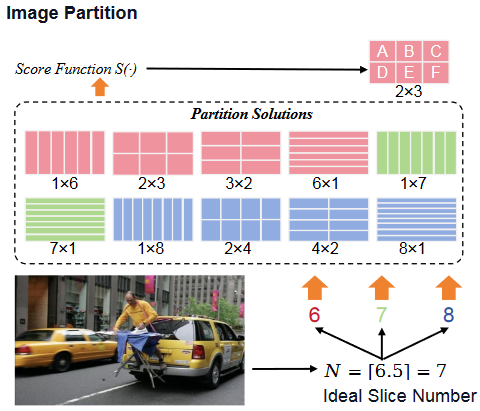
Image Partition. 根据图像计算理想的切片数量,最佳切片数量:
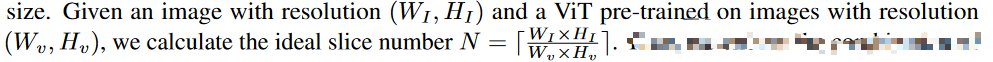
假设最佳切片数量为N,行切m,列切n,一共m*n=N,使用分数评估S:

有个问题就是N为素数,(m,n)是(1,N)或者(N,1),因此额外引入集合,即N-1和N+1的情况。在实际情况中,N<10, 即可支持13441344的像素(448,448)@ (3,3)。
Slice Encoding,图片切片,每个切片大小不一定符合视觉编码器的输入,比如可能切成448,视觉编码器的输入可能是336,因此将切片resize到尽可能匹配视觉编码器的输入(尽量保持长宽比,但是不一定就是规定的模型输入size)。然后通过对位置嵌入进行插值适应切片的大小,即将VIt的1D position embedding,还原成2D,然后进行插值,使得position embedding符合slice的size:
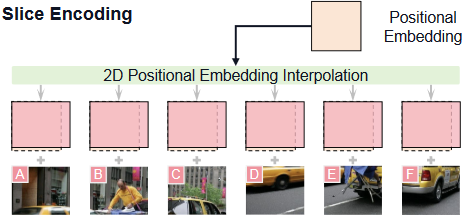
Token Compression,每个切片都编码为1024个tokens,10个切片就是10K个视觉token,采用压缩模块,由cross-attention和queries组成。在实际中,每个切片被压缩到96 token(MiniCPM-Llama3-V 2.5),
Spatial Schema,使用<slice></slice>包裹切片,\n区分切片的每行
二、训练
1、Training
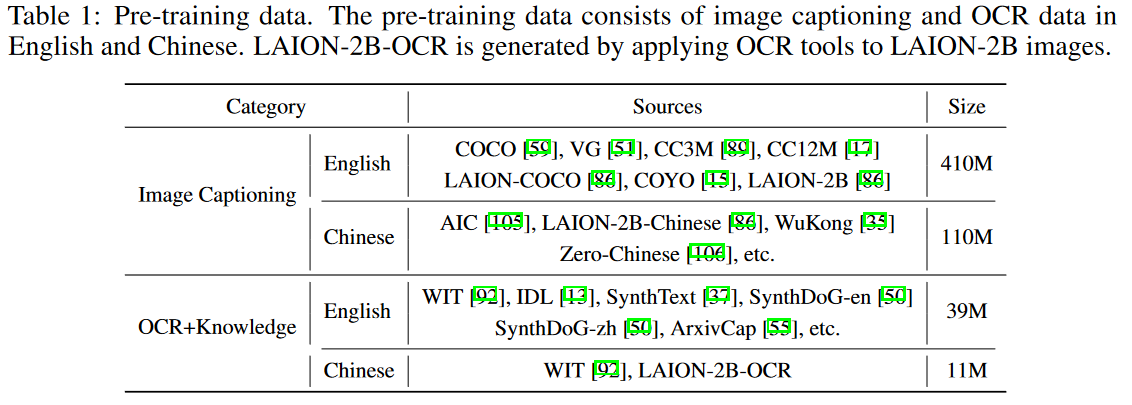
三个阶段。第一阶段,仅仅训练压缩层,图像输入为224,训练数据为下面筛出200M:
第二阶段,训练视觉编码器,图像为448*448,从上表中重新选200M Image caption数据训练。
第三阶段,训练压缩层和视觉编码器,使用上面提到的Adaptive Visual Encoding策略,适应任意像素图像长宽比。此外,引入OCR数据提升模型效果。
Caption Rewriting:网络图像文本对可能会遇到caption数据的质量问题,包括不流畅的内容、语法错误和重复的单词。为了解决问题,引入了用于低质量字幕重写的辅助模型。重写模型将原始标题作为输入,并要求将其转换为问答对。此过程的答案将被采用作为更新的caption。在实践中,我们利用 GPT-4 来标注少量种子样本,然后将其用于微调 LLM 以进行重写任务。
Data Packing:不同数据源的样本通常具有不同的长度。批次间样本长度的巨大差异将导致内存使用效率低下以及OOM错误的风险。将多个样本打包成一个固定长度的序列。通过截断序列中的最后一个样本,确保序列长度的一致性,从而促进更一致的内存消耗和计算效率。同时修改position ids and attention masks以避免不同样本之间的干扰。在实验中,在预训练阶段带来2~3倍的加速。
2、Supervised Fine-tuning
训练所有模型参数。

第 1 部分侧重于增强模型的基本识别能力,而第 2 部分则旨在增强模型生成详细响应和遵循人类指令的能力。具体来说,第 1 部分数据由传统的 QA/字幕数据集组成,响应长度相对较短,这有助于增强模型的基本识别能力。相比之下,第 2 部分包含的数据集具有文本或多模式环境中的长响应和复杂交互。
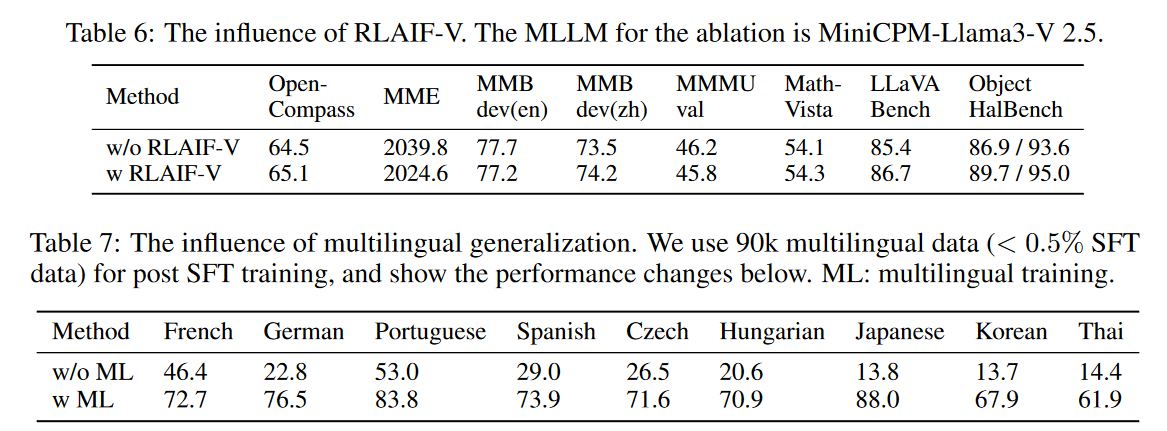
3、RLAIF-V
从开源模型中获取可扩展的高质量反馈以进行直接偏好优化(DPO)。

第一步:“Response Generation.”
第二步:“Feedback Collection.”
第三步:“Direct Preference Optimization.” ,通过DPO方法进行偏好学习。 DPO 算法需要对偏好对进行训练,其中一个样本 yw 优于另一个样本 yl。为了组成偏好数据集,从每个响应集中随机采样对 Y = {y1, y2, · · · , yn},并根据它们的相对分数确定 (yw, yl)。最后,构建了一个由 3K 个独特图像中的 6K 个偏好对组成的偏好数据集,用于偏好学习。
三、端侧部署
“Quantization:4-bit quantization strategy” +“Memory Usage Optimization.” +“Compilation Optimization.” + “Configuration Optimization.” + “NPU Acceleration.”
四、实验
模型配置:


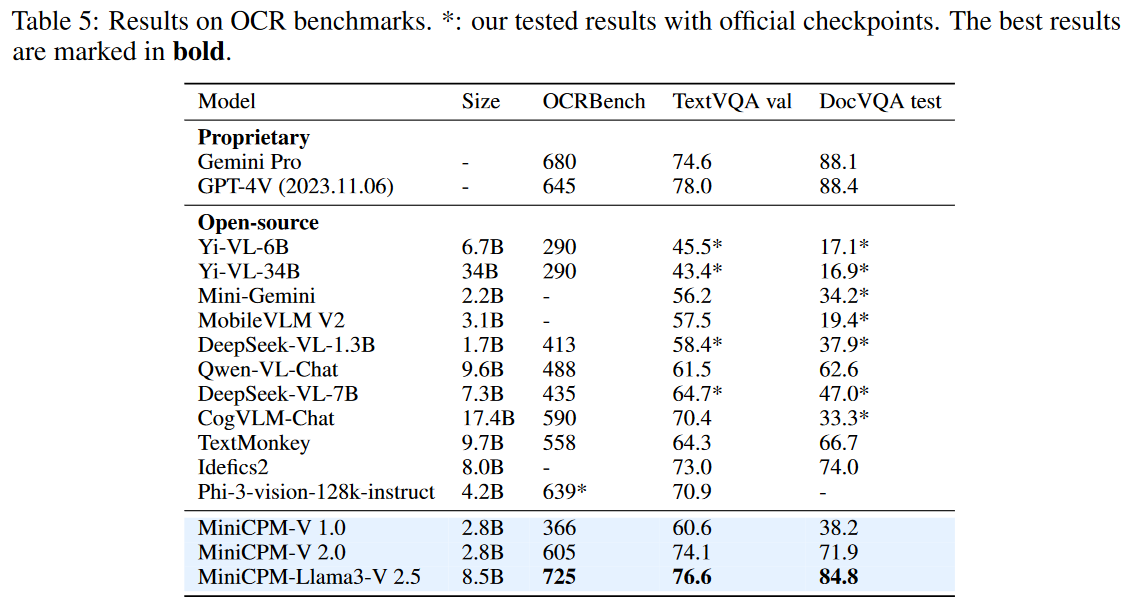
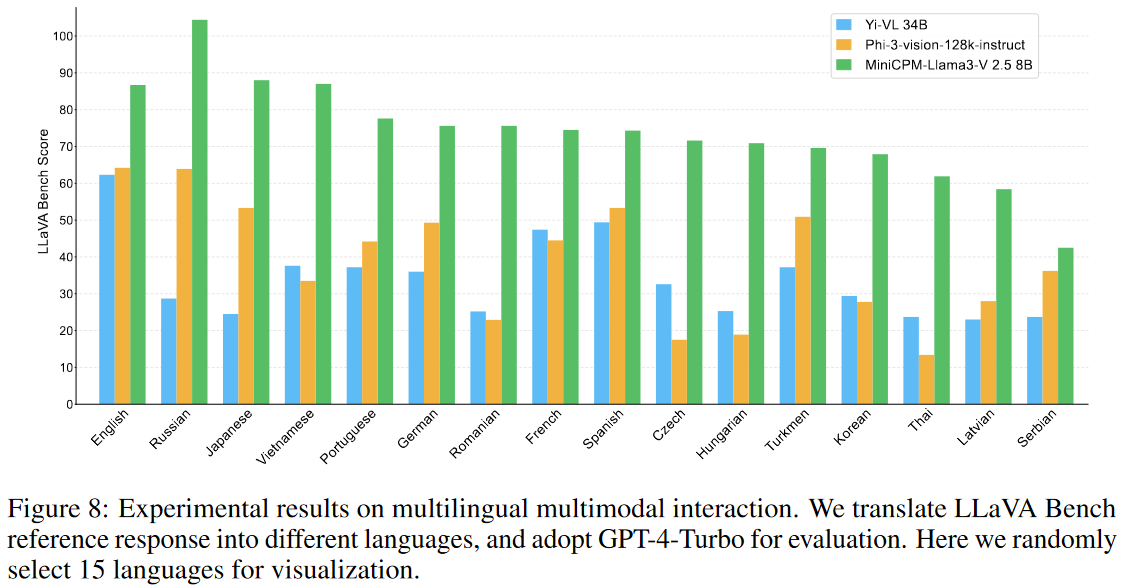
我们重点关注数据构建、模型结构、训练策略、模型结果,因此忽略端侧部署内容。
登录后可发表评论
点击登录