参考论文:https://arxiv.org/abs/2403.10249
在传统游戏中,NPC(非玩家角色)的行为往往是预先设定好的,缺乏灵活性和变化性。然而,基于大模型的NPC可以利用其强大的推理和学习能力,实时生成对话和行为,使其看起来更加真实和多样化。

随着大模型技术不断进步,它们在游戏中的应用变得越来越广泛和深远。从简单的角色对话到复杂的游戏策略,这些模型正在逐步改变我们对游戏的理解和体验。本文将从技术层面深入探讨大模型如何应用到游戏中。
人类是如何玩游戏的?
在思考如何让大模型玩游戏之前,让我们先来想一想人类是如何玩游戏的。
在游戏的过程中,人类大脑首先将感官信息转化为对游戏世界的感知表征,接着利用这些表征构建关于游戏环境的知识,并基于这些知识做出推理,最后通过行动来实现游戏中的操作。这一系列步骤可以概括为感知、推理和行动的循环过程。
下面我们以经典的游戏《塞尔达传说:旷野之息》为例,看看这个过程是如何展开的。
感知:解析游戏世界
在《旷野之息》中,玩家首先需要通过视觉、听觉等感官信息来感知周围的游戏环境。例如,玩家注意到敌人的位置、道具的分布,以及环境中的天气变化。这些信息会被大脑处理,转化为对游戏世界的理解。早期的游戏可能只要求玩家理解文本指令,而如今,游戏已经发展到需要玩家同时处理多模态信息,比如理解风向对箭矢轨迹的影响,或是辨别不同敌人的攻击模式。

推理:制定最佳策略
推理的过程涉及多个步骤,包括记忆、学习、推理、反思和决策。例如,玩家需要记住之前遇到的敌人行为模式,学习如何有效地避开攻击或寻找弱点。推理则帮助玩家在面对复杂情况时做出最佳决策,比如在敌人围攻时,玩家可能会评估使用炸弹、剑攻击还是躲避的最佳时机。而这些推理往往不是单线的,而是多跳推理——玩家需要同时考虑敌人的位置、自己的生命值、环境因素等多个变量,才能制定出最佳的战斗策略。

行动:执行与反馈循环
在推理之后,玩家会根据自己的判断采取行动,比如决定用剑击打敌人、在悬崖边使用滑翔伞逃脱,或者在寒冷的山峰穿上御寒衣物。在《旷野之息》中,行动的反馈直接影响玩家的下一步决策,比如敌人的反击、天气变化或是玩家体力的消耗,都需要玩家及时调整策略。

AI大模型如何玩游戏?
在理解了人类如何玩游戏之后,我们来探讨一下AI大模型是如何玩游戏的。AI大模型的游戏过程同样可以抽象为agent智能体的迭代过程:感知、推理和行动。
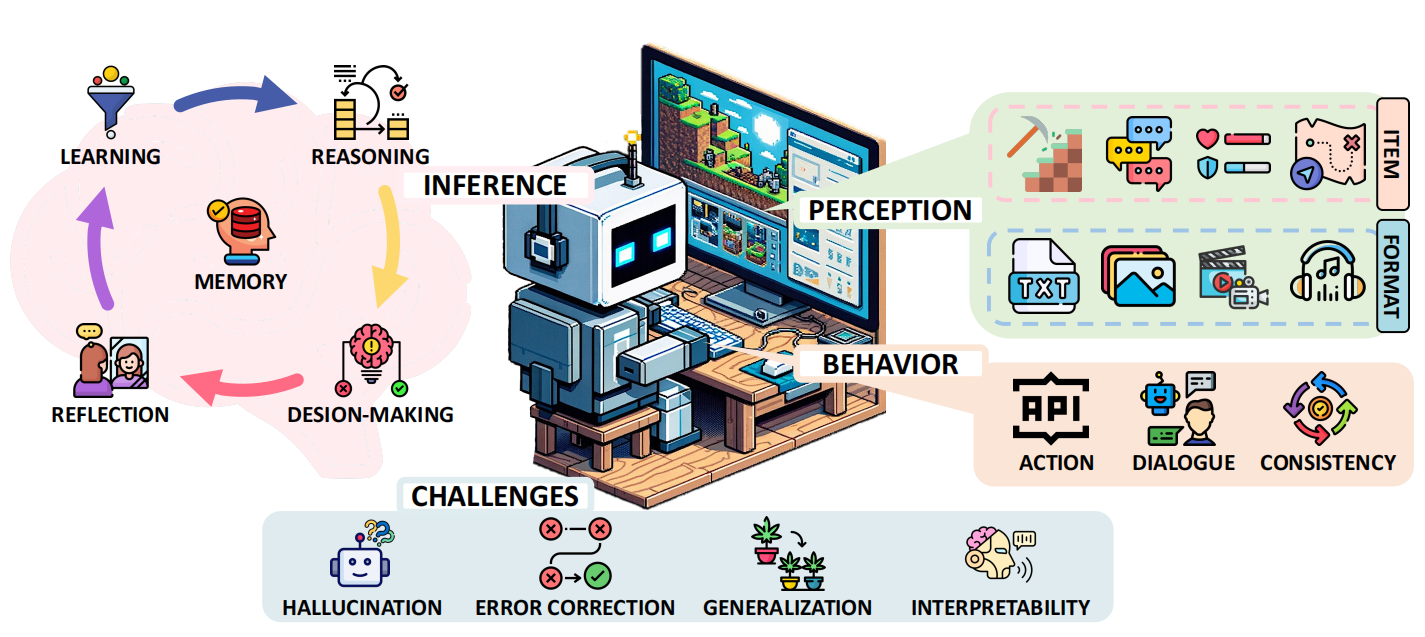
多模态感知:游戏世界更为沉浸
多模态感知是游戏大模型理解和互动的核心能力之一,它通过整合不同类型的信息(如视觉、语义和音频)来构建更具沉浸感的游戏体验。
语义感知语义感知主要涉及对游戏文本元素的理解,如自然语言指令和对话。玩家通过解读这些文本信息来了解游戏中的环境、角色和事件,从而做出相应的决策。
语义感知可以进一步细分为以下几类:
简单文本输入:包括用户的简单描述、游戏状态和角色对话。结构化或角色输入:涉及角色属性、故事背景及技能信息。环境和上下文输入:指详细的游戏描述及任务指令,这些信息帮助玩家理解当前场景。多模态输入:整合视觉、听觉和文本数据来做出更复杂的决策,并实现丰富的互动。 视觉感知视觉感知是大模型处理游戏中图像信息的能力。然而,仅依赖将视觉数据转化为文本可能会导致重要信息的丢失,从而影响大模型NPC在游戏中的表现。
为了提升视觉感知能力,使用多模态大语言模型(MLLMs)是一种有效的方法。MLLMs能够整合视觉与其他感官数据,提升大模型NPC对游戏世界的理解和决策能力。
复杂推理与决策:NPC变得更“聪明”
在AI大模型游戏中,NPC的智能化体现在其复杂的推理与决策能力上。为了实现这一点,大模型模型需要具备知识存储和检索、进行推理和做出决策的综合能力。
为了正确地表示学习到的知识或过去事件,并在推理中使用这些信息,一个NPC需要有效地操作这些"记忆”。这就要求对游戏大模型设计一种高质量的记忆机制,使NPC能够有效存储和检索记忆。
例如,如果一个模型被用于模拟护士NPC的角色,大模型应了解包含医疗常识、病人交流的指南,以及诊断和治疗的标准流程。这使得模型能够在模拟或实际情境中更加有效和适应性地行动。
然而,这些知识可能不总是与特定的游戏场景等应用情境完全一致。因此,当前的研究旨在通过以下方式增强语言模型的常识性理解:
通过指令微调将结构化的知识嵌入。使用SOP将常识集成到特定的角色和任务中。使用RAG(检索增强生成)。将详细的角色资料通过prompt输入大模型中。使用知识图谱用于描述实体之间的关系。 进行推理和做出决策大模型NPC的学习推理过程包括解释和整合各种来源的信息,以适应新的游戏场景。学习可以是显式的,通过特定数据集进行微调;也可以是隐式的,通过利用现有知识适应新情况。结合反馈和强化学习,大模型NPC能够通过环境交互优化行为,从而更好地适应游戏世界。
在复杂的游戏环境中,大模型NPC需要做出多层次的决策,这通常包括多跳推理和长期规划。多跳推理要求大模型NPC在做出决策前考虑多层信息和依赖关系,例如预测对手的动作并评估各种行动的潜在结果。长期规划则涉及设定长期目标,并通过一系列策略行动来实现这些目标。
持续行动与反思:NPC越来越“人类”
在游戏中,大模型NPC不仅需要做出即时的反应,还要能够持续行动和反思,以应对复杂的游戏环境,NPC的行为变得更加智能和人性化。

在游戏中,NPC的行动空间可以分为三种类型:
基于文本互动:NPC通过文本与玩家或环境进行互动,解释和响应玩家的输入。使用API互动:通过API,NPC能够获取或发送信息,控制游戏中的各种元素。通过IO操作直接控制:例如使用键盘、鼠标等设备,直接影响游戏中的行为和操作。 反思反思是指NPC评估和调整自身行为的能力。通过利用外部反馈和不断优化计划,NPC能够在游戏过程中不断改进。特别是在多智能体系统中,NPC需要与其他角色协作,重新评估和调整其决策,以更好地适应游戏环境。
通过持续行动与反思,NPC变得越来越接近人类,使游戏体验更为真实和动态。
大模型游戏未来展望
随着生成式AI和大模型的快速崛起,我们离NPC与游戏世界深度互动的梦想越来越近。《失控玩家》中,NPC逐渐觉醒,拥有了自主意识和情感的设定,为我们描绘了一个充满可能性的未来。虽然目前的技术还存在许多需要改进的地方,但通过引入能够理解和响应玩家的AI大模型,游戏世界将不再是单纯的虚拟场景,而是一个有感知、有情感的交互空间。

展望未来,AI大模型或许会彻底改变游戏产业的格局。它不仅为游戏创造带来了全新的可能性,还可能重新定义游戏与玩家之间的关系。在不久的将来,我们可能会看到一个更加智能化、更加人性化的游戏世界,在这个世界里,玩家不再是孤独的冒险者,而是与“有灵魂”的NPC共同编织梦境的创作者。