
【编者按】本文探讨了大语言模型(LLM)在软件编程中的应用及其局限性。虽然 LLM 在根据自然语言描述生成代码方面展现出了显著的进步,但在逻辑推理尤其是演绎推理上的不足限制了其在编程任务中的表现。文章回顾了多项研究,指出 LLM 在生成代码时面临诸如 API 使用不当、边界条件处理失误等问题。鉴于此,作者提出了探索一种新的中间语言——语言模型特定语言(LMSL)的想法,这种语言既便于 LLM 生成,又易于人类理解和监督。LMSL 的目标是通过减少复杂性来提高 LLM 生成代码的可靠性,并且能够方便地转换为现有的编程语言。
作者 | 卢威
责编 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)

我们在研究大语言模型(LLM)在软件编程领域的应用问题时有一个基础的问题需要思考:如何定位 LLM?
LLM 根据自然语言描述的要求生成简单的编程语言代码的能力是传统程序合成(Program Synthesis)道路上一次跨越式的提高,惊艳了众人。但随着使用越来越多,它不能像以往的“低/零代码”方案或高级语言编译器那样可靠的工作的问题也暴露出来(见图 1),修复 LLM 生成的代码给程序员带来更大的工作负担。
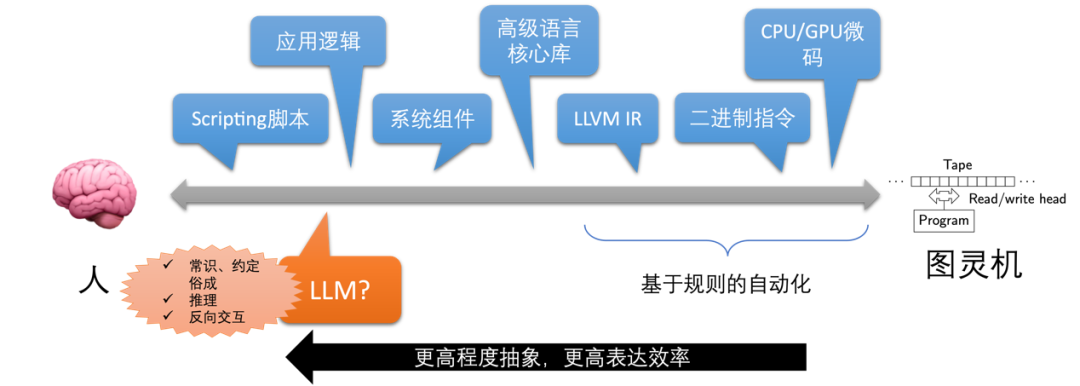
图 1 演变过程
思考 LLM 的定位问题自然要基于它的能力问题。LLM 不同于以往的单一任务模型,训练它的数据涵盖非常广的领域,它表现出的能力也千变万化。与软件编程密切相关的逻辑推理能力方面学术界仍存在激烈的争论:模型究竟有像人类一样的逻辑推理能力,还是模式匹配到记忆过的相似推理结果而已?比如《推理还是背诵?通过反事实任务探索语言模型的能力和局限性》(见下方论文)。

论文链接:https://arxiv.org/abs/2307.02477
我们在六月份的《如果语言≠思维,大语言模型怎么办?》一文中也讨论了一个重要的研究发现。在此方向上最近的重要成果应属 “Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs”(见下方论文)。

论文链接:https://arxiv.org/abs/2408.00114
其发现是:在演绎(Deductive reasoning)、归纳(Inductive reasoning)和溯因(Abductive reasoning)三种逻辑推理的主要形式中,LLM 表现出很强的归纳推理能力,但往往缺乏演绎推理能力,特别是在涉及“反事实”推理的任务中(见图 2)。
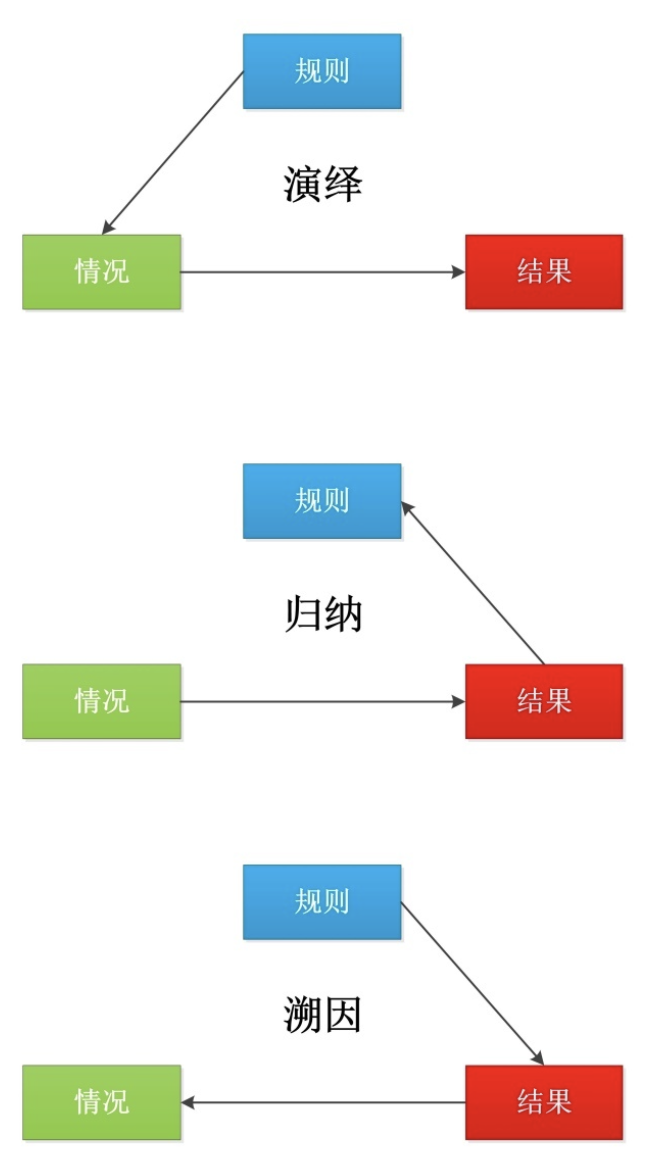
图 2 逻辑推理的主要形式
显然,演绎推理才是在软件编程任务中最常见,并且能保证因果关系的类型,而语言模型并不擅长。
LLM 实际在代码生成任务上的表现也是一大研究方向。除了不断刷新评测(HumanEval 等)分数新高外,我们也特别关注一个研究方向:什么编程任务 LLM 处理得不好?庞大的任务不论是人还是 LLM 都显然处理不好,但可以采用分而治之的策略来转化为比较小和简单的任务,Agent(智能体)技术在这方面也帮助 LLM 取得了很大的改善,先排除在本次关注的范围之外。
非功能性要求,比如性能、安全、可维护性等方面,LLM 表现也不能令人满意(见下方论文),但为简化问题也暂时先不讨论。

论文链接:https://arxiv.org/abs/2401.15963
“What’s Wrong with Your Code Generated by Large Language Models? An Extensive Study” “Can ChatGPT replace StackOverflow? A Study on Robustness and Reliability of Large Language Model Code Generation” “Where Do Large Language Models Fail When Generating Code?” “No need to lift a finger anymore? Assessing the quality of code generation by ChatGPT” 等论文是我们关注的一系列研究,接下来会单独撰写一篇文章,汇总、分类和分析 LLM 生成代码的各种失败案例。简单来说,从小的代码生成专用模型到最大的通用模型如 GPT-4,存在一些普遍性的发生概率不低的问题,比如 API 使用、边界条件、数值关系和操作顺序、分支条件、概念实现、输入输出格式等。
事实上,现在的软件编程语言就只有社会整体劳动力中极少数受过专业和长期训练的人——程序员——能真正掌握运用,而且运用的效率和可靠性也是随个体有巨大差异的。除了继续训练更强大的模型使其达到资深程序员的水平,另一个思路也呼之欲出:
“计算机科学中的所有问题都可以通过增加一个间接层来解决。”(All problems in computer science can be solved by another level of indirection.)
——David Wheeler (1927-2004)
探索一种介于自然语言和现有软件编程语言之间的中间形态,使其更适合 LLM 生成,也便于人类理解和监督。
这两年各种形式的探索包括 “Self-planning Code Generation with Large Language Models”,先让模型生成一个自然语言文字形式的计划,再结合原始意图和计划生成代码(见图 3)。缺点是,文字计划难以通过程序手段来自动进行形式验证,第二步也仍然完全依靠模型的能力来转化到编程语言代码。


图 3 结合原始意图和计划生成代码
论文链接:https://arxiv.org/abs/2303.06689
“Low-code LLM: Graphical User Interface over Large Language Models” 则是先让模型生成一个流程图(见图 4),解决以上方案的形式验证问题。

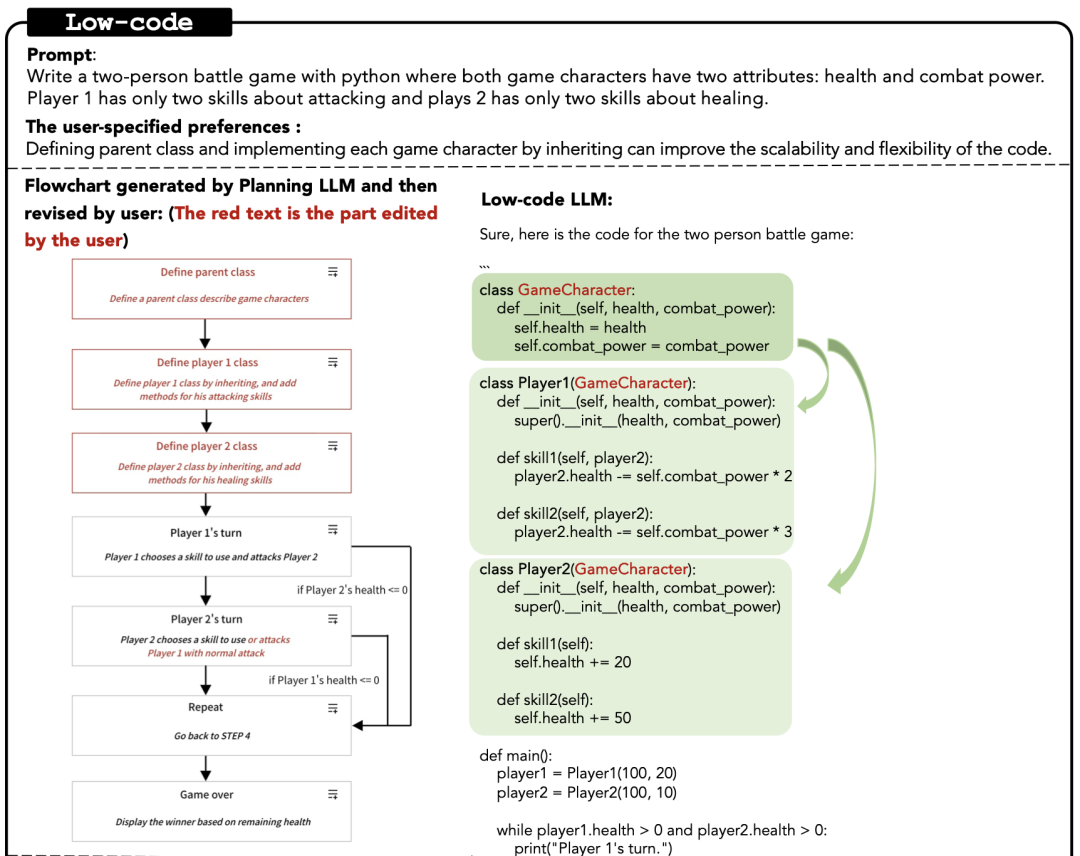
图 4 流程图
论文链接:https://arxiv.org/abs/2304.08103
如果流程图像 ComfyUI 或“低/零代码”方案一样可以直接运行,文字计划方案的另一个问题也得到解决。挑战在于,让模型生成这样的流程图(见图 5)也不是那么容易和可靠的。
图 5 类 ComfyUI 流程图
“Natural Language Commanding via Program Synthesis” 设计了一个 Office 领域特定语言 Office Domain Specific Language (ODSL),综合了以上方案的优点,并且根据自然语言意图使用 GPT-3.5 生成 ODSL(见图 6)即可达到 96.06 ± 2.69% 成功率。其基础语法基于大模型最“熟悉”的 Python,使用 Few-shot ICL 来“教会”模型特定的 API,这个模式似乎是最接近实用的。


图 6 使用 GPT-3.5 生成 ODSL 的提示词
论文链接:https://arxiv.org/abs/2306.03460
从最开始人类直接用自然语言表达意图,LLM 直接处理执行(模式 0),或 LLM 直接生成编程代码(模式 1),到各类探索,模式可以做如下分类(见图 7)。
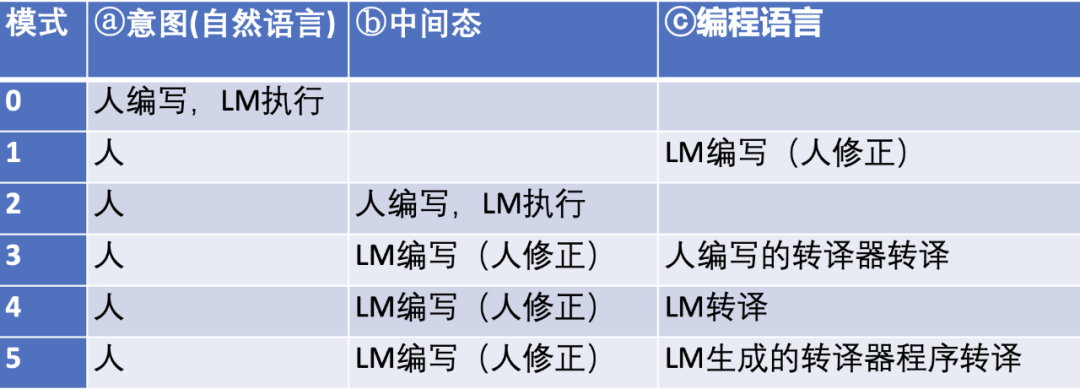
图 7 分类表格
我们认为模式 3 和 5 最值得进一步探索。这个中间态的形式可能是有程序可处理的语法约束的文字形式(也容易转化为图形表达),以下暂时称之为语言模型特定语言 LMSL。
LMSL 最终转译为现有的软件编程语言代码来实际运行。出于不完全相同的目的,业界也有不少新语言的尝试,能够部分解决以上提到的问题,例如 APPL 等(见图 8)。

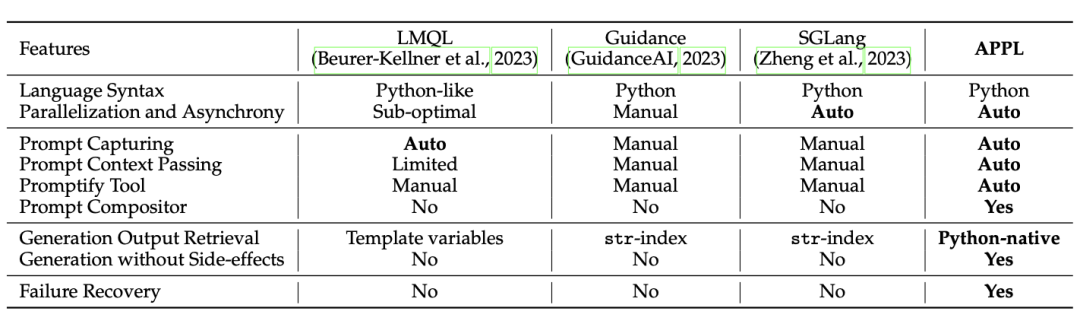
图 8 APPL 的方案优势
论文链接:https://arxiv.org/abs/2406.13161
华为的仓颉 Agent DSL(见图 9)也可以视为一个方案,它似乎实现了提示词自动优化的模式,这方面是比较领先的。但外界还缺乏资料进一步了解。

图 9 仓颉 Agent DSL
参考链接:https://developer.huawei.com/consumer/cn/doc/cangjie-guides-V5/cj-wp-intelligence-V5
我们对于 LMSL 提出以下要求和目标:
控制复杂度,提高 LLM 可靠性;
易于程序验证,可自动修正;
单个程序简单,引用方式简单;
自然语言(不确定性处理)的演绎推理部分能用确定性代码替换或覆盖;
易于人类理解和修正;
易于转译为现有编程语言,重用软件生态;
易于实现面向目标的编程方式和程序自动优化(涉及 Automatic Prompt Engineer 即 APE 这个研究方向,我们将另文讨论);
LMSL 的设计探索工作具体这样展开:
1. 根据以上阐述的 LLM 生成代码的各种失败案例分析,设计 LMSL 以避免容易失败的语言特性和要求。通过两种方式优化设计:
a) 基于以上研究的数据集,使用 LLM 生成 LMSL 代码进行评测。
b) 人类手写一些 LMSL 代码,用 LLM 生成自然语言意图,再测试 LLM 根据意图生成 LMSL 的情况。
2. 对于容易通过 LLM 自行修复的错误类型,训练一个模型或开发一个 Agent 进行自动修复。
3. 存在一些非常难用 LLM 自行修复的错误,可以收集数据,训练一个分类模型判断判断此类自然语言意图,从开始就提醒用户,或及早引入其他工具。
我们会继续发文介绍探索的过程,也欢迎广大读者留言交流和参与我们的探索。

