前言
在日常的开发工作中,我们总会遇到 Spark 应用运行失败、或是执行效率未达预期的情况。对于这样的问题,想找到根本原因,可以通过 Spark UI 提供的"体检报告"中的一些信息来获取最直接、最直观的线索,本篇就是介绍如何解读Spark UI “体检报告”,和用他定位分析问题。
一、Web UI 页面介绍
打开 Spark UI,首先映入眼帘的是默认的 Jobs 页面。Jobs 页面记录着应用中涉及的 Actions 动作,以及与数据读取、移动有关的动作。
其中,每一个 Action 都对应着一个 Job,而每一个 Job 都对应着一个作业。
可以看到,导航条最左侧是 Spark Logo 以及版本号,后面则依次罗列着 6 个一级入口。每个入口的功能与作用如下的表格介绍
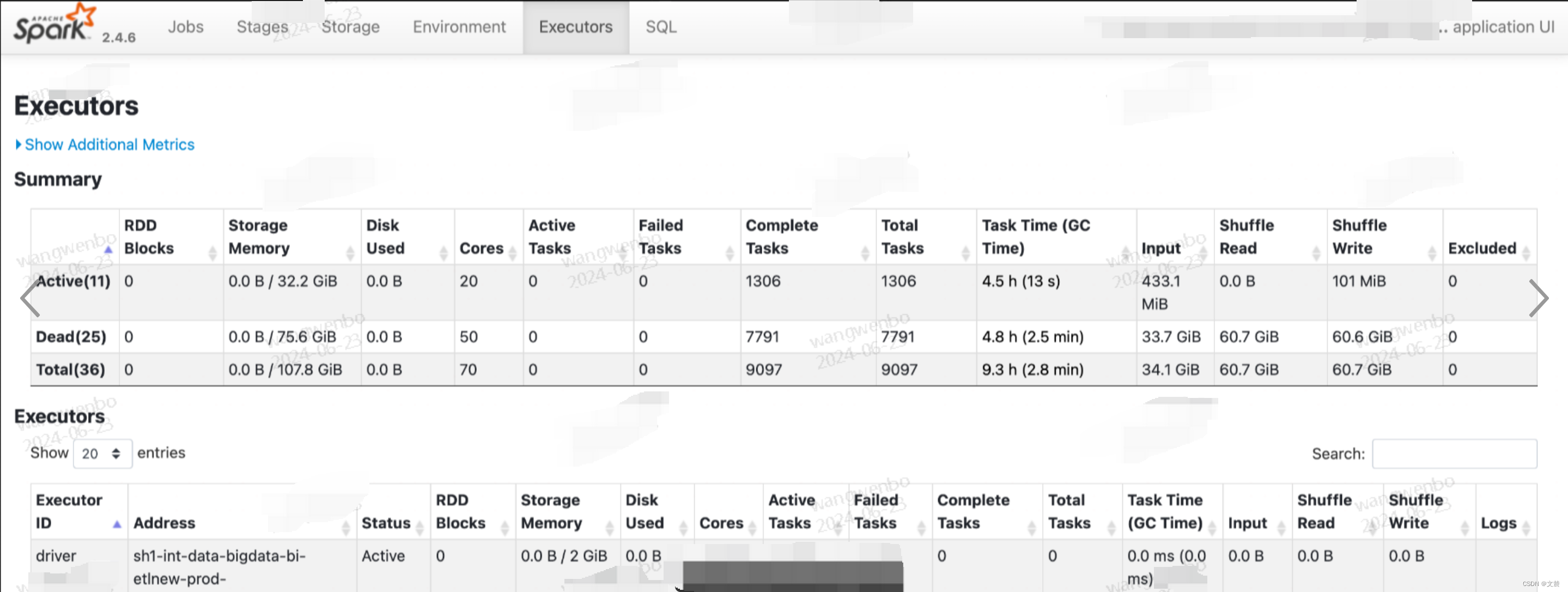
1.1 Executors页(一级入口)
Executors Tab 的主要内容如下,主要包含“Summary”和“Executors”两部分。这两部分所记录的度量指标是一致的,其中“Executors”以更细的粒度记录着每一个 Executor 的详情
,而第一部分“Summary”是下面所有 Executors 度量指标的简单加和。
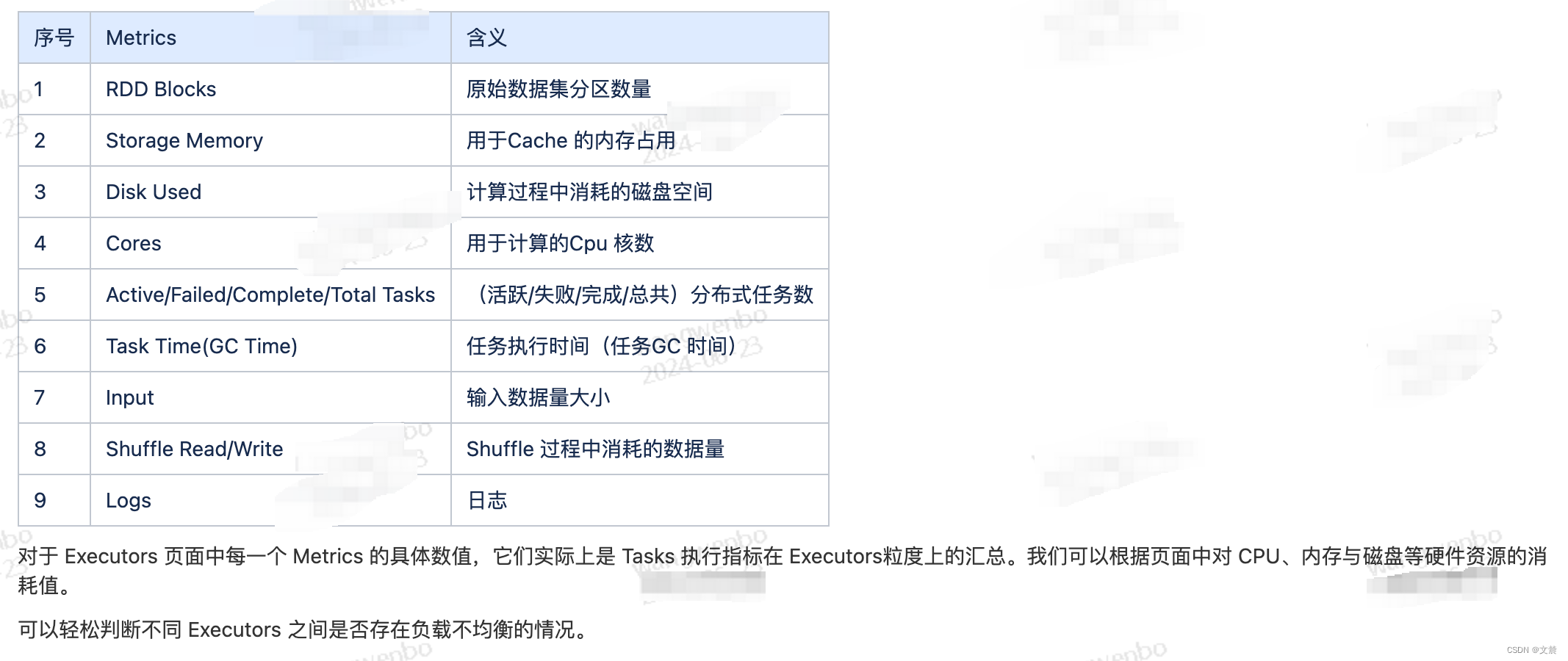
1.1.1 Metrics 指标介绍
1.2 Environment页(一级入口)
Environment 页面记录的是各种各样的环境变量与配置项信息,如下图所示:
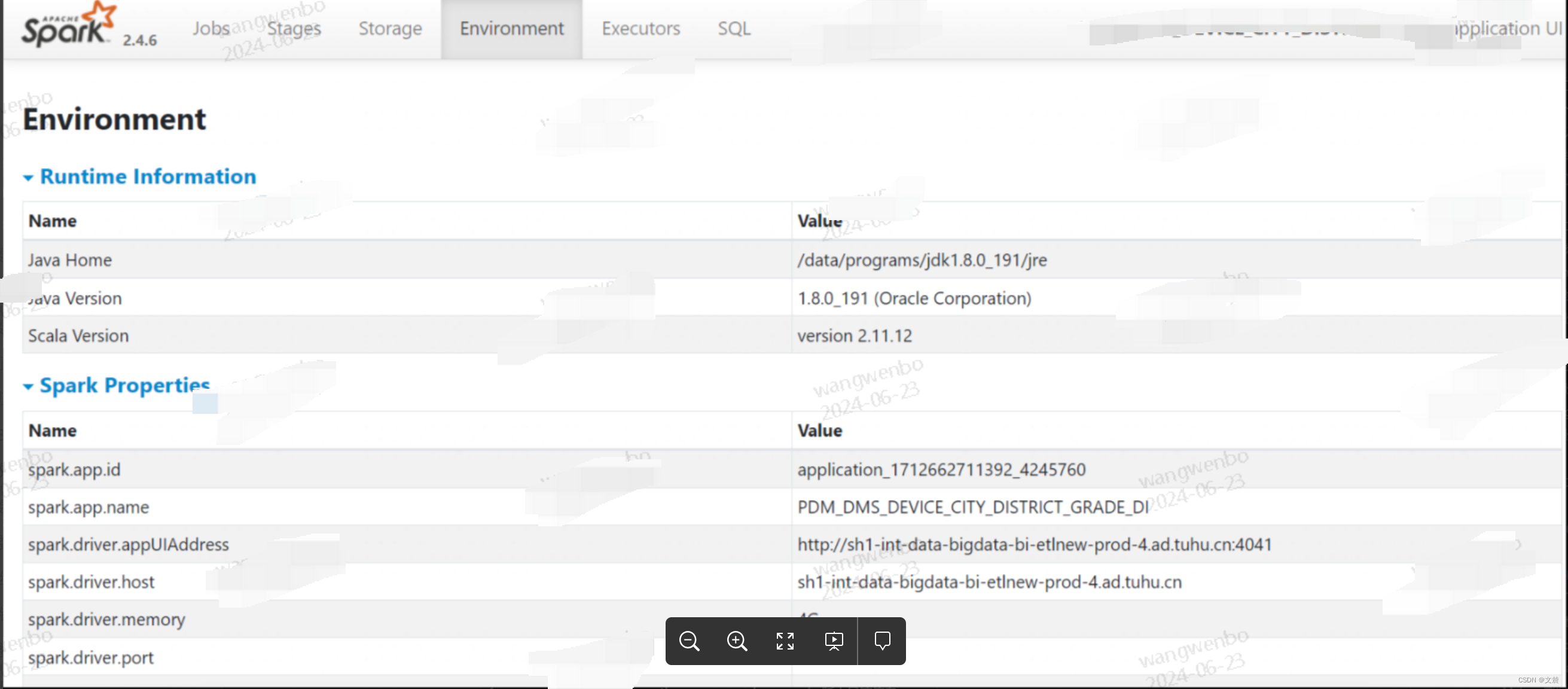
1.2.1 Metrics 指标介绍
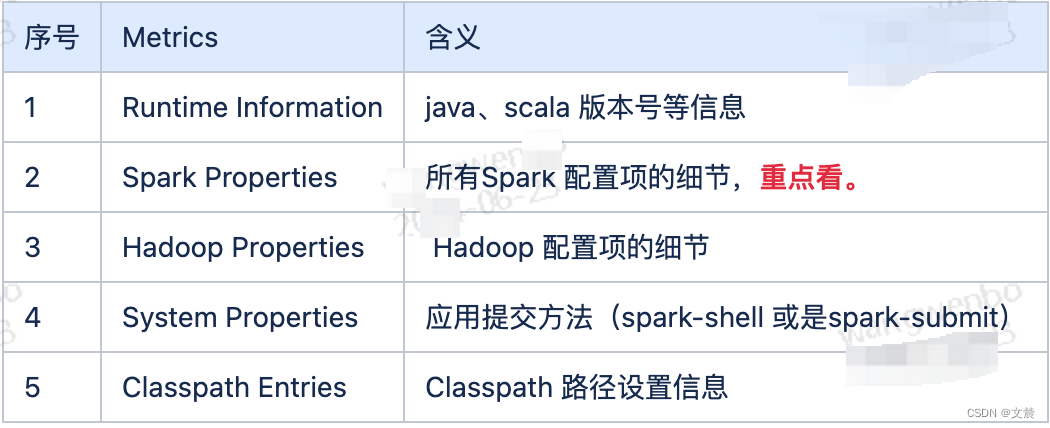
其中Spark Properties 是重点,其中记录着所有在运行时生效的 Spark 配置项设置。
通过 Spark Properties,我们可以确认运行时的设置,与我们预期的设置是否一致,从而排除因配置项设置错误而导致的稳定性或是性能问题。
1.3 Storage页 (一级入口)
Storage 详情页,记录着每一个分布式缓存(RDD Cache、DataFrame Cache)的细节,包括缓存级别、已缓存的分区数、缓存比例、内存大小与磁盘大小。但下图为空,原因没有使用或者未对使用的RDD或DataFrame使用persist()或cache()操作

1.4 SQL页 (一级入口)
当我们的应用包含 DataFrame、Dataset 或是 SQL 的时候,Spark UI 的 SQL 页面,就会展示相应的内容,(所以hive on spark 不会有这个页面)如下图所示:
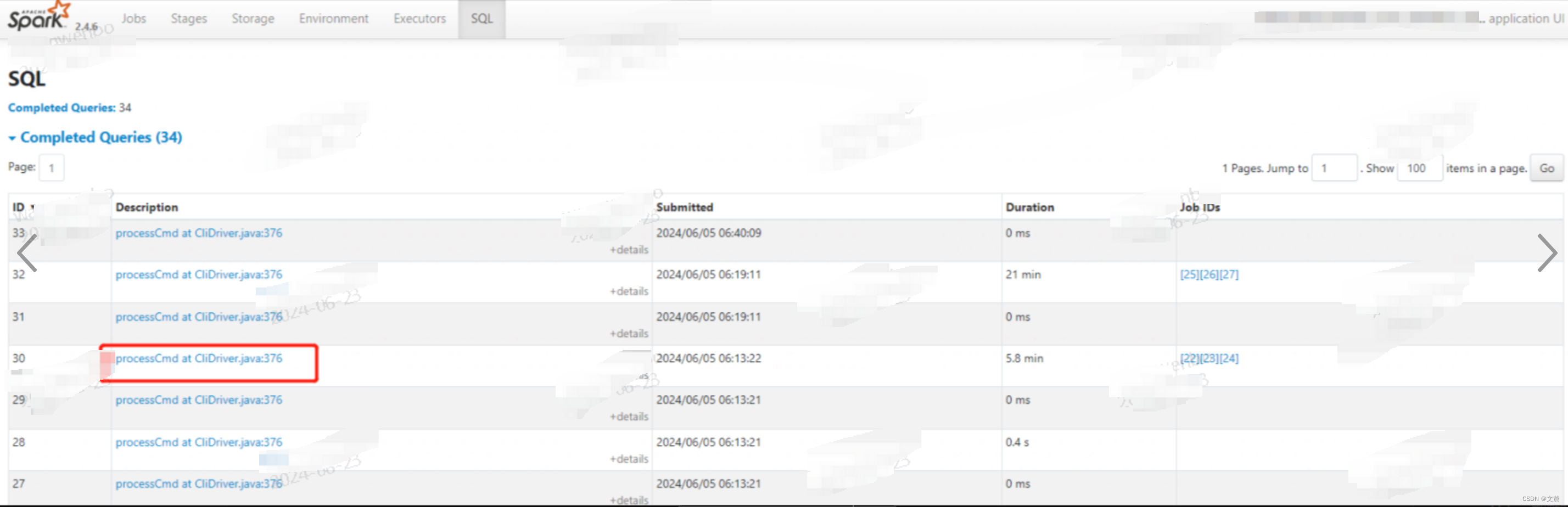
在这里以 Actions 为单位,记录着每个 Action 对应的 Spark SQL 执行计划。我们需要点击“Description”列中的超链接,才能进入到二级页面,去了解每个执行计划的详细信息。
1.4.1 SQL 详情页(二级入口)
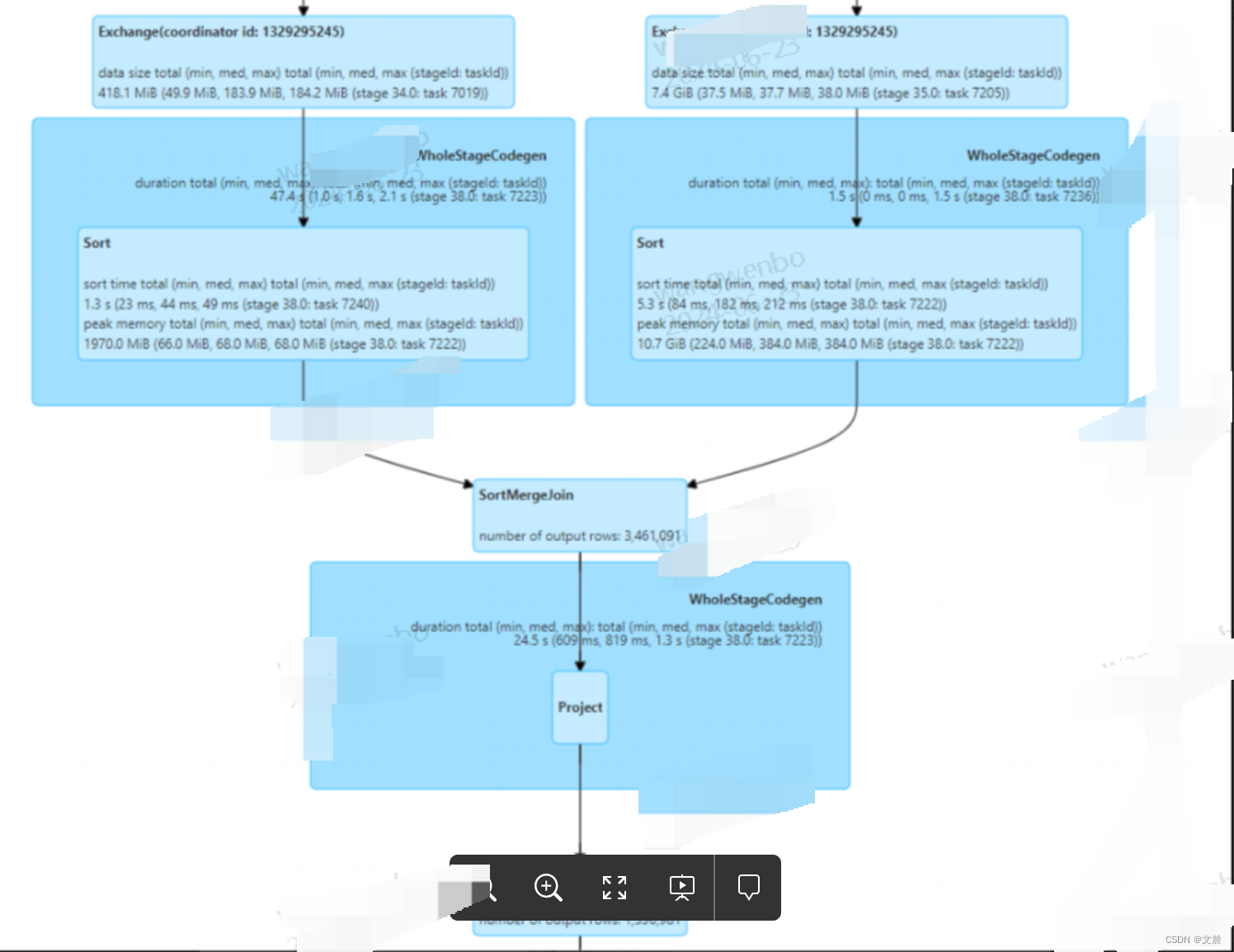
其中Exchange代表的是 Shuffle 操作,Sort是排序,Aggregate表示的是(局部与全局的)数据聚合。下面详细介绍
1.4.1.1 Metrics 指标介绍
1.4.1.1.1 Exchange
如图两个 Exchange的详细的metrics 指标信息如下:(为了展示的指标更全,下本分别是spark 3.x和2.x 的版本的展示信息。表格中是竟可能的详细的罗列一些信息)
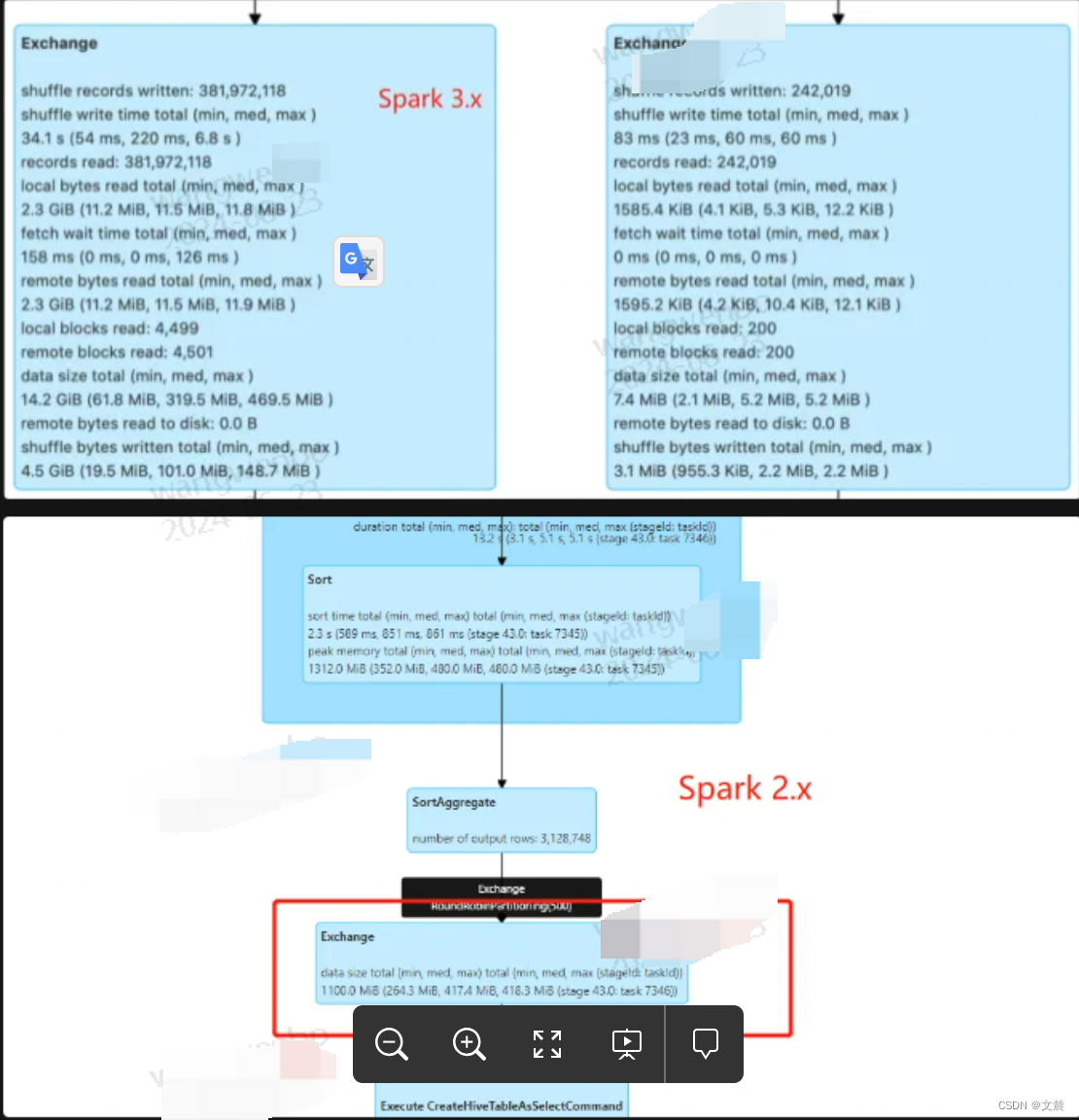
Metrics 整理如下:

Metrics 案例分析:
根据上图一,我们观察到过滤之后的辅表数据大小不足 10MB(7.4MB),这时我们首先会想到,对于这样的大表 Join 小表,Spark SQL 选择了 SortMergeJoin 策略是不合理的。
基于这样的判断,我们完全可以让 Spark SQL 选择 BroadcastHashJoin 策略来提供更好的执行性能。至于调优的具体方法,要么用强制广播,要么利用 3.x 版本提供的 AQE 特性。
1.4.1.1.2 Sort
相比 Exchange,Sort 的度量指标没那么多,如图(为了展示的指标更全,下本分别是spark 3.x和2.x 的版本的展示信息。表格中是竟可能的详细的罗列一些信息)
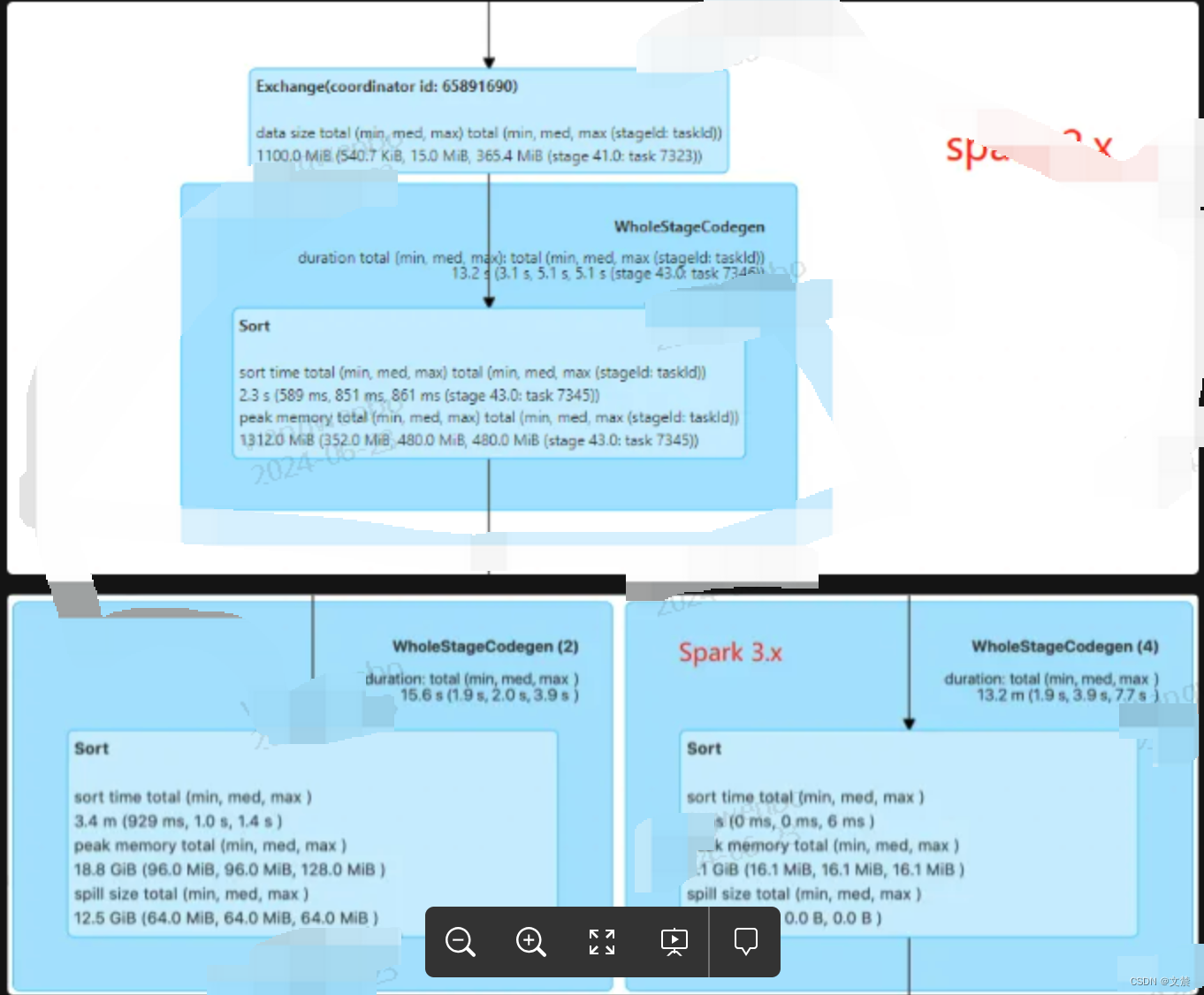
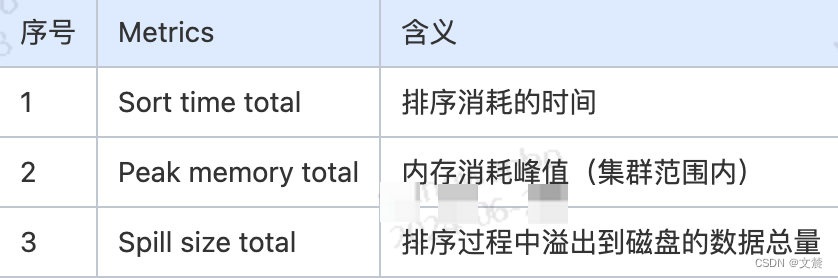
Metrics 整理如下:
Metrics 案例分析:
“Peak memory total”和“Spill size total”这两个数值,可以指导我们更有针对性地去设置 spark.executor.memory、spark.memory.fraction、spark.memory.storageFraction。
日比如。结合第二张图 18.8GB 的峰值消耗,以及 12.5GB 的磁盘溢出这两条信息,我们可以去思考,当前 Executor Memory 是否足够?如果不够那么我们可以去=通过调整上面的 3 个参数,来加速 Sort 的执行性能。
1.4.1.1.3 Aggregate
与 Sort 类似,衡量 Aggregate 的度量指标,主要记录的也是操作的内存消耗

Metrics 案例分析:
对于 Aggregate 操作,Spark UI 也记录着磁盘溢出与峰值消耗,即 Spill size 和 Peak memory total。这两个数值也为内存的调整提供了依据,
以图二为例,0溢出与 2GB 的峰值消耗,证明当前 Executor Memory 设置,对于 Aggregate 计算来说是绰绰有余。
1.5 Jobs 页(一级入口)
Jobs 页面也是以 Actions 为粒度,记录着每个 Action 对应作业的执行情况。具体作业详情,可以通过“Description”页面提供的二级入口链接。
1.6 Stages(一级入口)
Stages 页面,更多地是一种预览,要想查看每一个 Stage 的详情,同样需要从“Description”进入 Stage 详情页(二级页面)
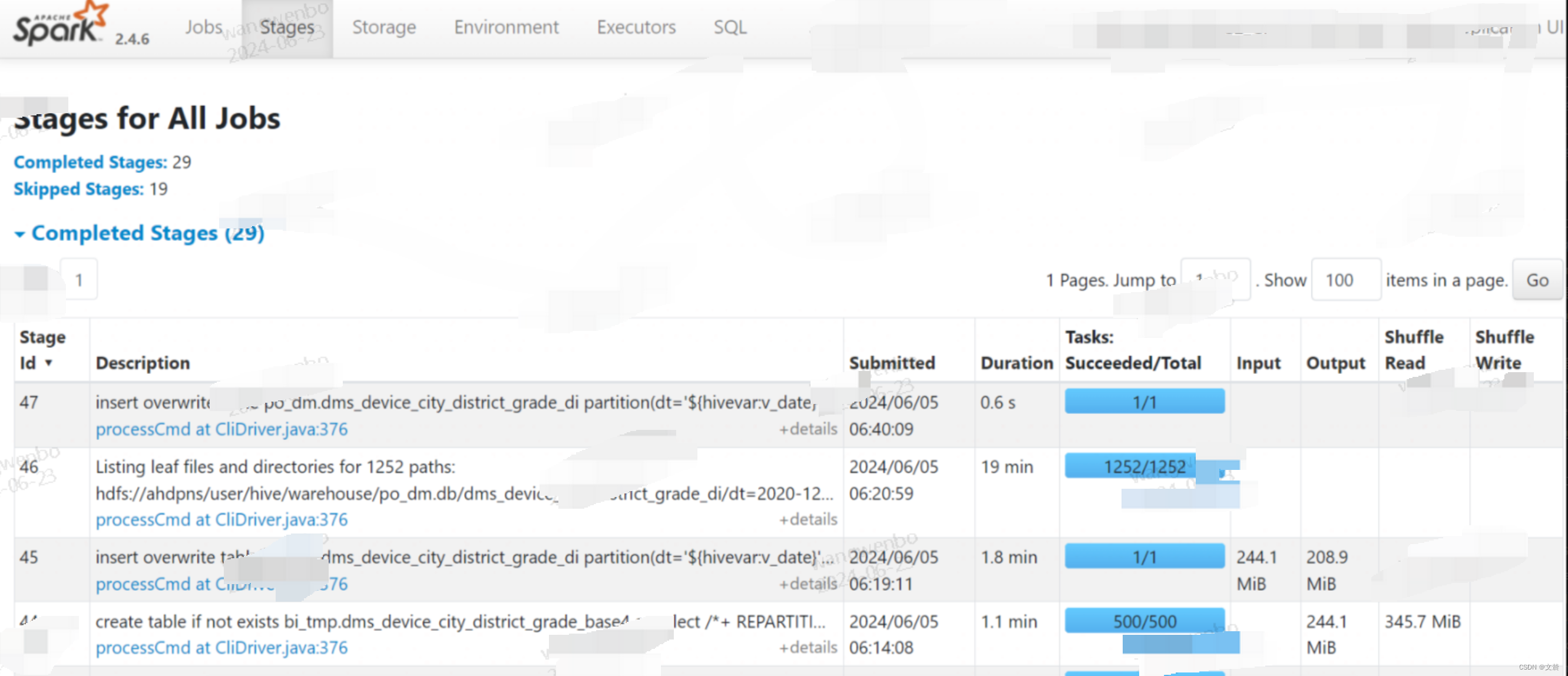
1.6.1 Stages 详情页(二级入口)
除了从Job 的二级页跳转进来,另一种就是这里了。可以看到它主要包含 3 大类信息,分别是 Stage DAG、Event Timeline 与 Task Metrics。
如图:
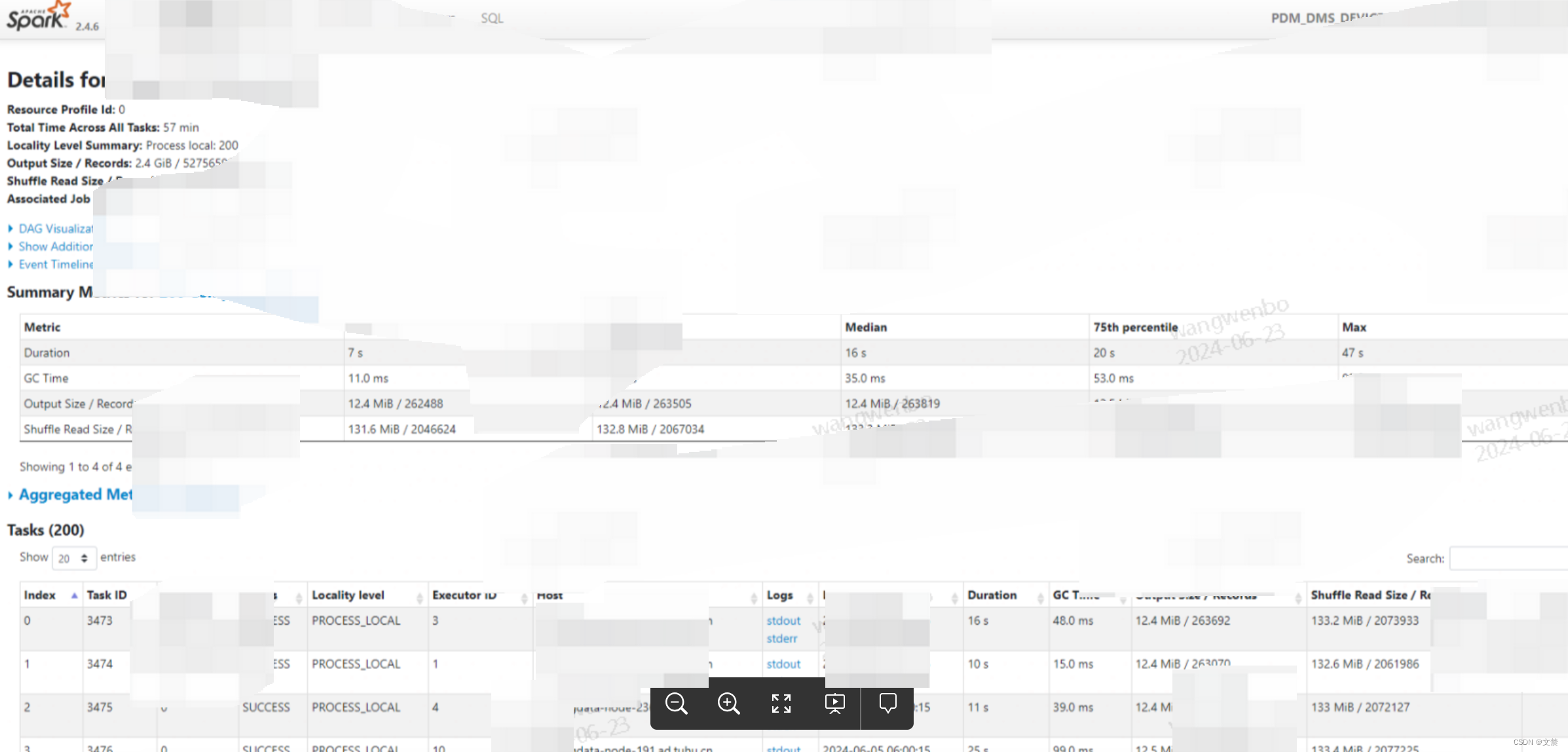
下面我们沿着“Stage DAG -> Event Timeline -> Task Metrics”的顺序,依次讲讲这些页面所包含的内容。
1.6.1.1 Stage DAG
点开蓝色的“DAG Visualization”按钮,我们就能获取到当前 Stage 的 DAG,如下图所示
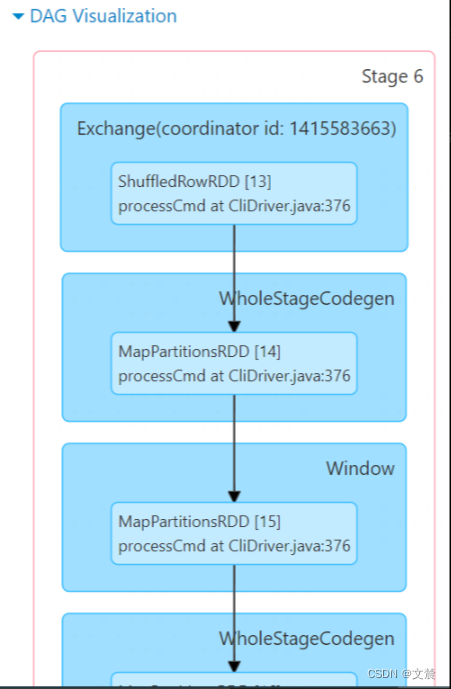
这里Stage DAG 只是 SQL 页面完整 DAG 的一个子集,而SQL 页面的 DAG却是针对的是作业(Job)。所以我们可以不看这里,优先去看SQL 的DAG 。
1.6.1.2 Event Timeline
Event Timeline,记录着分布式任务调度与执行的过程中,不同计算环节主要的时间花销。图中的每一个条带,都代表着一个分布式任务,条带由不同的颜色构成。其中不同颜色的矩形,代表不同环节的计算时间。
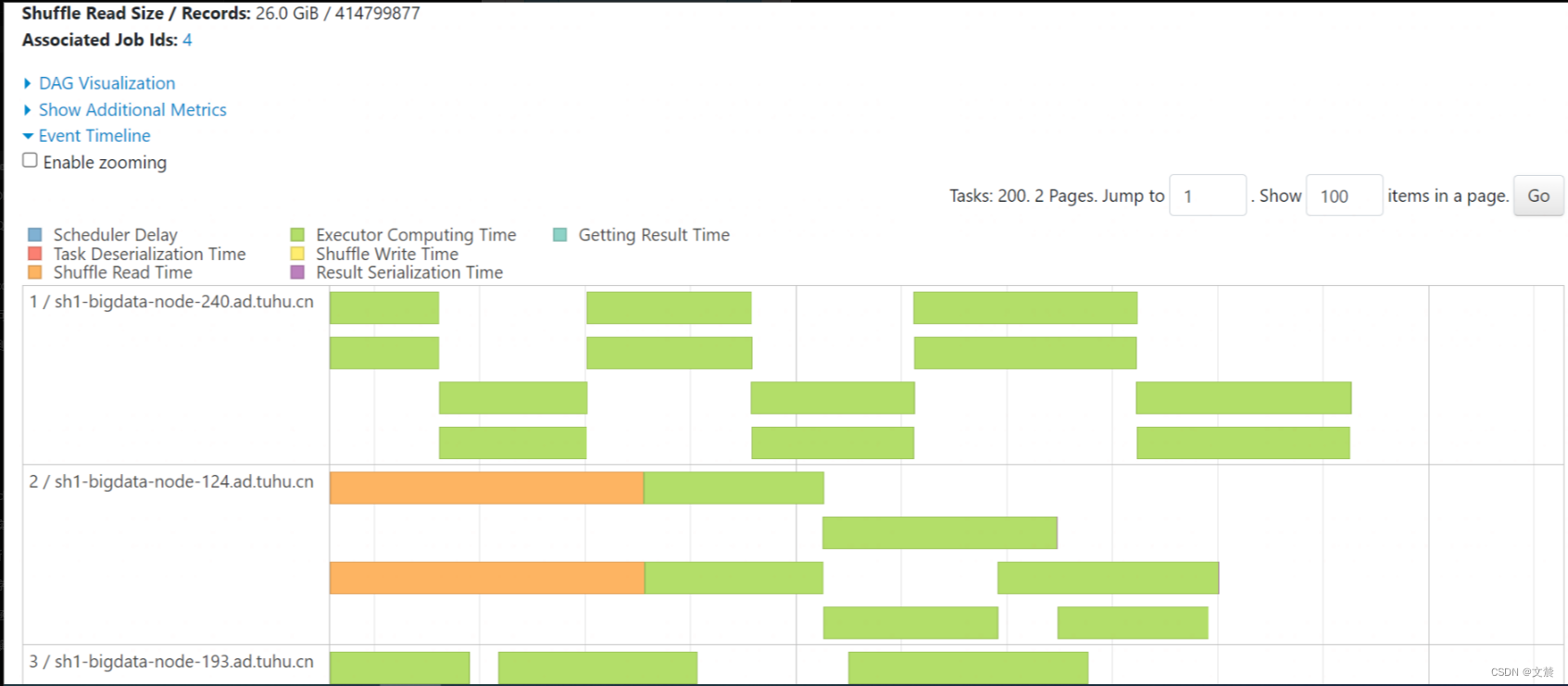
Metrics 整理如下:

Metrics 案例分析:
理想情况下,条带的大部分应该都是绿色的(如图中所示),也就是任务的时间消耗,大部分都是执行时间。不过,实际情况并不总是如此。
比如:
有些时候,蓝色的部分占比较多,或是橙色的部分占比较大。在这些情况下,我们就可以结合 Event Timeline,来判断作业是否存在调度开销过大、或是 Shuffle 负载过重的问题,从而有针对性地对不同环节做调优。
比方说,如果条带中深蓝的部分(Scheduler Delay)很多,那就说明任务的调度开销很重。这个时候,我们就需要参考“三足鼎立”的调优技巧,去相应地调整 CPU、内存与并行度,从而减低任务的调度开销。
再比如:
如果条带中黄色(Shuffle Write Time)与橙色(Shuffle Read Time)的面积较大,就说明任务的 Shuffle 负载很重,这个时候,我们就需要考虑,有没有可能通过利用 Broadcast Join 来消除 Shuffle,从而缓解任务的 Shuffle 负担。
1.6.1.3 Task Metrics
是这个二级页面里最重要的地方,分位两项,其中“Tasks” 项目以 Task 为粒度,记录着每一个分布式任务的执行细节。而“Summary Metrics”则是对于所有 Tasks 执行细节的统计汇总。
1.6.1.3.1 Summary Metrics
首先,我们点开“Show Additional Metrics”按钮,勾选“Select All”,让所有的度量指标都生效,如下图所示。这么做的目的,在于获取最详尽的 Task 执行信息
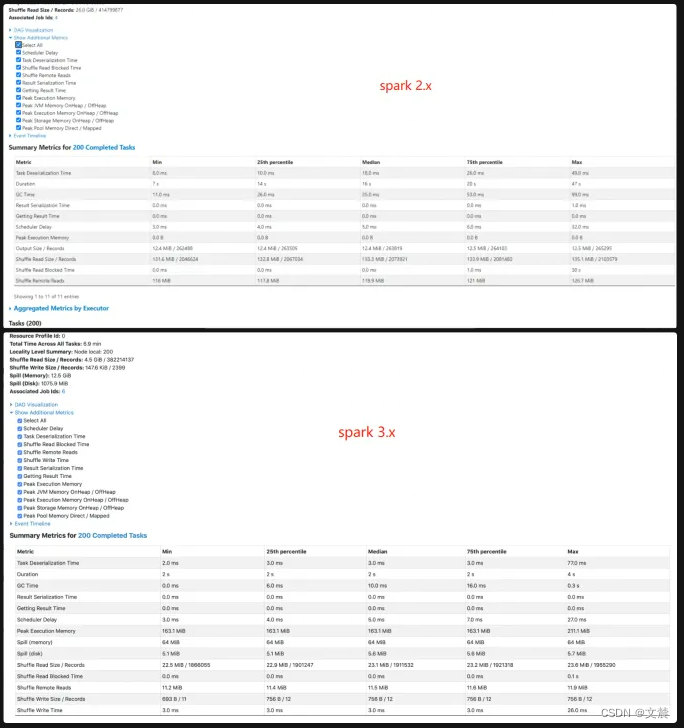
下面详细的介绍下各种Metrics 。其中Task Deserialization Time、Result Serialization Time、Getting Result Time、Scheduler Delay 与刚刚表格中的含义相同,不再赘述,这里我们仅整理新出现的 Task Metric
Metrics 整理如下:

Metrics 案例分析:
对于这些详尽的 Task Metrics,我们可以非常清晰地量化任务的负载分布。根据不同 Metrics 的统计分布信息去判定当前作业的不同任务之间,是相对均衡,还是存在严重的倾斜。
如果判定计算负载存在倾斜,根据不同倾斜的场景我们就可以选择不用的方式去处理。
注意:如何估算数据在内存中大小这一问题。 可以借助这里的 Spill(Memory)除以 Spill(Disk),得到“数据膨胀系数”的近似值,记为 Explosion ratio。
有了 Explosion ratio,对于一份存储在磁盘中的数据,我们就可以估算它在内存中的存储大小,从而准确地把握数据的内存消耗。1.6.1.3.2 Tasks
Tasks 的不少指标,与 Summary 是高度重合的,如下图所示。唯一的区别,就是这些指标是针对每一个 Task 进行度量的。而上面的Summary 是Executor。
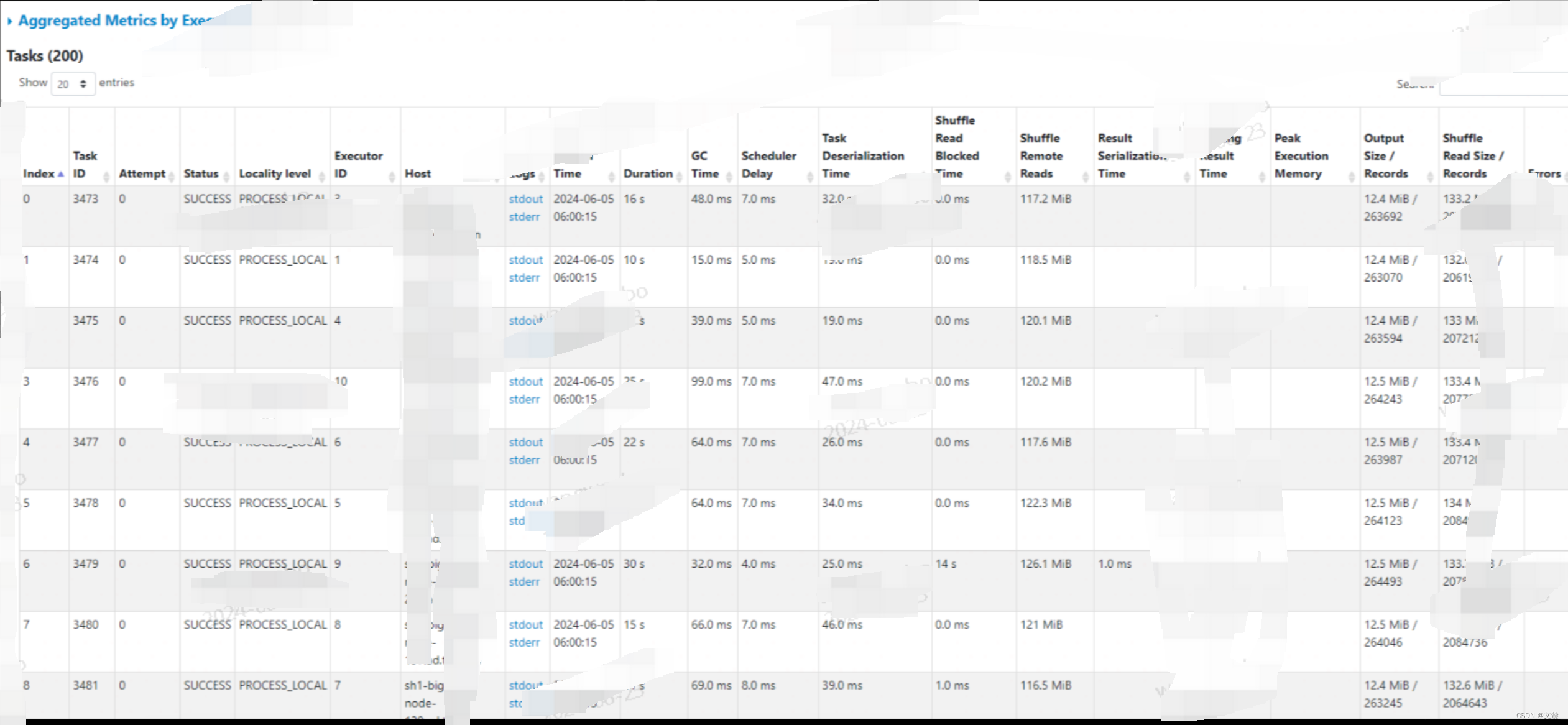
Metrics 整理如下:
Metrics 案例分析:
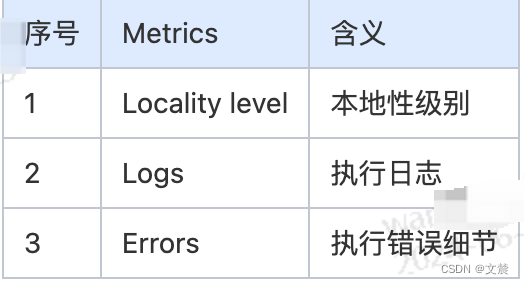
是 Locality level,也就是本地性级别。在调度系统中,每个 Task 都有自己的本地性倾向。结合本地性倾向,调度系统会把 Tasks 调度到合适的 Executors 或是计算节点,尽可能保证“数据不动、代码动”。
Logs 与 Errors 属于 Spark UI 的三级入口,它们是 Tasks 的执行日志,详细记录了 Tasks 在执行过程中的运行时状态与报错信息,使用他们可以讯速地定位问题。
1.7 页面总结
Executors、Environment、Storage 是详情页,开发者可以通过这 3 个页面,迅速地了解集群整体的计算负载、运行环境,以及数据集缓存的详细情况;
而 SQL、Jobs、Stages,更多地是一种罗列式的展示,想要了解其中的细节,还需要进入到二级入口。里面 涉及的 Metrics 纷繁而又复杂,需要去结合日常的开发,去多多摸索与体会。