随着人工智能技术的迅猛发展,AI大模型已经成为全球科技竞争的焦点、未来产业的关键赛道以及经济发展的新动力,展现出巨大的发展潜力和广阔的应用前景。目前,AI大模型的应用落地引发行业关注。技术的持续进步促使AI大模型的应用逐步从云端向终端设备延伸,同时,从通用模型向针对特定行业的定制化解决方案转变,其商业潜力和对行业的影响不断增强。此外,国内外企业在大模型领域的竞争日趋激烈,伴随着性能的显著提升和应用场景的持续拓展,AI技术正在经历快速的发展,同时推动着产业的深层次变革。
本文将深入探讨AI大模型的相关话题,分析当前行业的现状以及我国AI大模型面临的挑战。同时,我们将简要概述AI大模型产业链的结构。随后,我们将详细分析AI大模型的应用场景,探讨企业如何将业务与AI技术相结合,以及AI大模型在实际应用中的落地途径。最后,我们将分析国内外公司在AI大模型领域的基本情况。根据以上内容展望未来发展趋势。希望通过这些内容,能够帮助大家更深入地理解AI大模型。
01
行业概述
1、AI大模型定义
AI大模型是指在机器学习和深度学习领域中,采用大规模参数(至少在一亿个以上)的神经网络模型,AI大模型在训练过程中需要使用大量的算力和高质量的数据资源。
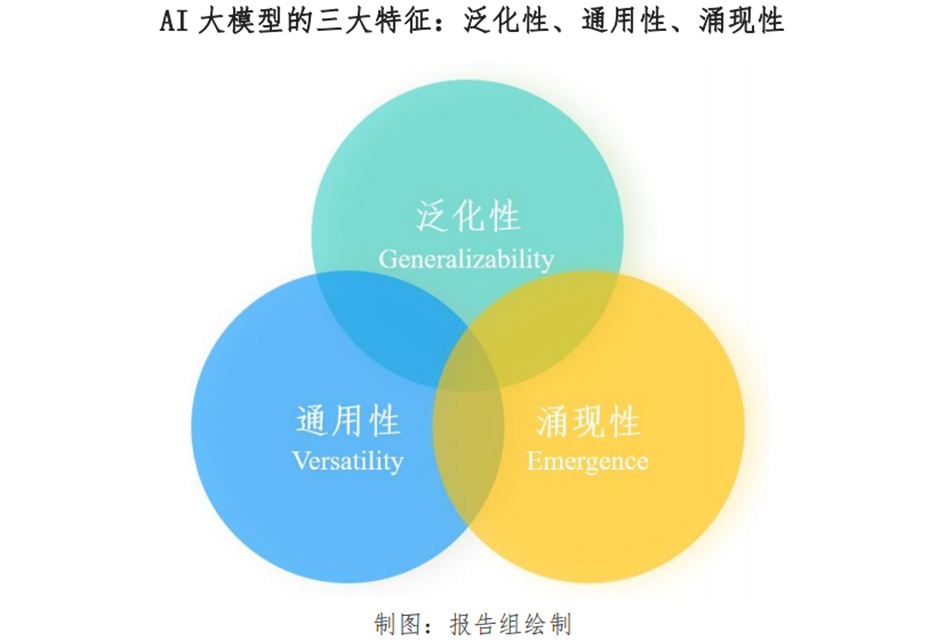
2、AI大模型主要特征
AI大模型具有泛化性(知识迁移到新领域)、通用性(不局限于特定领域)以及涌现性(产生预料之外的新能力)特征。以ChatGPT为代表的AI大模型因其具有巨量参数和深度网络结构,能学习并理解更多的特征和模式,从而在处理复杂任务时展现强大的自然语言理解、意图识别、推理、内容生成等能力,同时具有通用问题求解能力,被视作通往通用人工智能的重要路径。
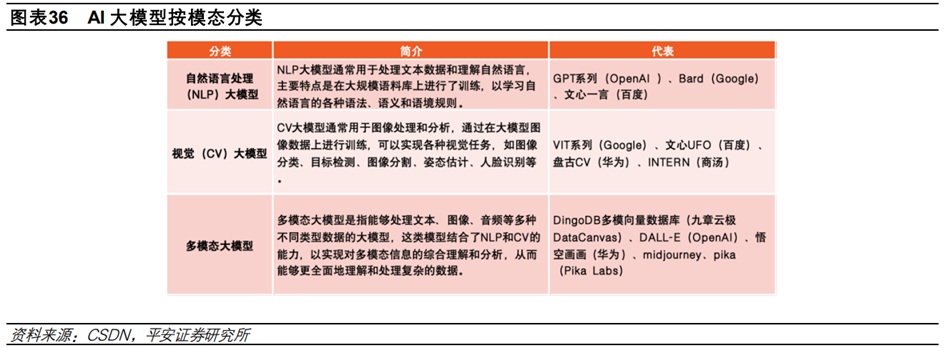
3、AI大模型分类
按模态划分,大模型可分为自然语言处理(NLP)大模型,视觉(CV)大模型、多模态大模型等。
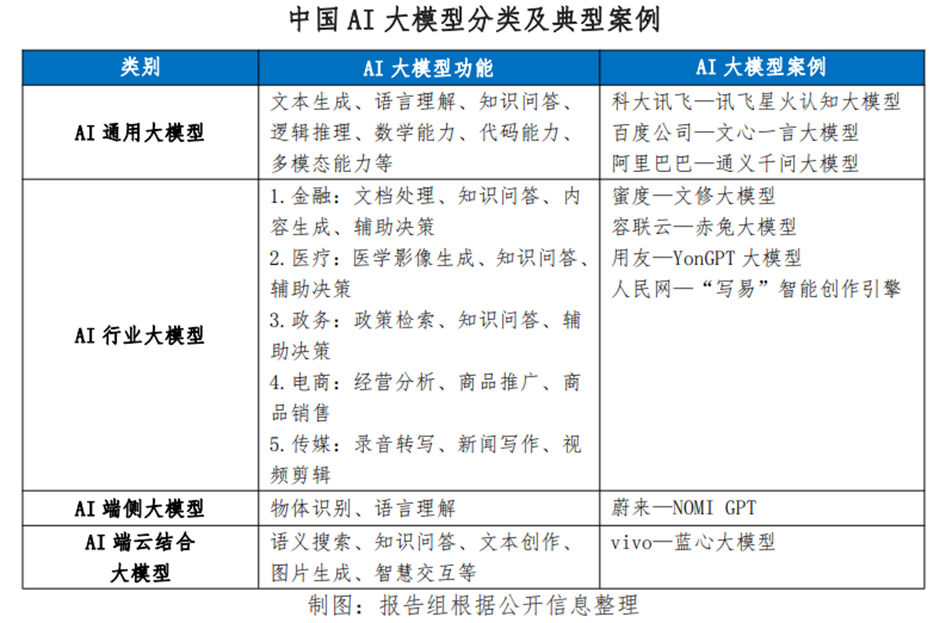
**按照部署方式划分,AI大模型主要分为云侧大模型和端侧大模型两类。**云侧大模型由于部署在云端,其拥有更大的参数规模、更多的算力资源以及海量的数据存储需求等特点;端侧大模型通常部署在手机、PC等终端上,具有参数规模小、本地化运行、隐私保护强等特点。
具体而言,**云侧大模型分为通用大模型和行业大模型;端侧大模型主要有手机大模型、PC大模型。**从云侧大模型来看,通用大模型具有适用性广泛的特征,其训练数据涵盖多个领域,能够处理各种类型的任务,普适性较强。行业大模型具有专业性强的特点,针对特定行业(如金融、医疗、政务等)的需求进行模型训练,因而对特定领域具有更深的业务理解和场景应用能力。从端侧大模型来看,手机和PC大模型由于直接部署在设备终端,让用户体验到更加个性化和便捷的智能体验。
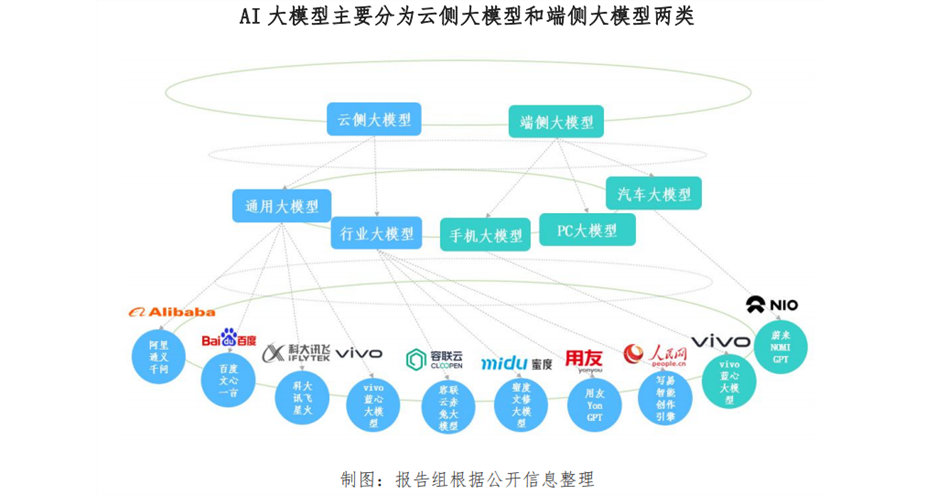
当前AI大模型的应用路线日渐清晰,大致途径为“基础大模型→行业大模型→终端应用”。
4、AI大模型行业应用价值
AI大模型能够提升要素效率及数据要素地位。
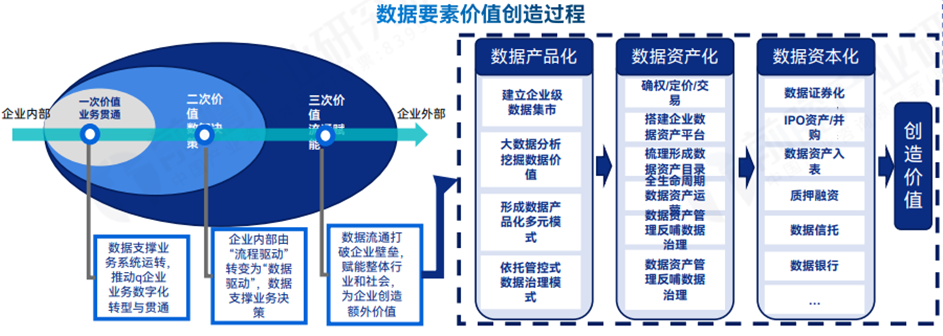
**目前数据已成为新生产要素。**数字经济是继农业经济、工业经济之后的现阶段主要经济形态,数据要素已成为数字经济时代下的新型生产要素。2019年十九届四中全会,数字要素首次被增列为生产要素,数据要素地位得到确立。我国成为首个将数据列为生产要素的国家。
数据从企业内部到外部的流通过程中可以创造三次价值:1、数据支撑业务贯通;2、数据推动企业数智决策;3、数据资源流通交易赋能社会创造额外价值。

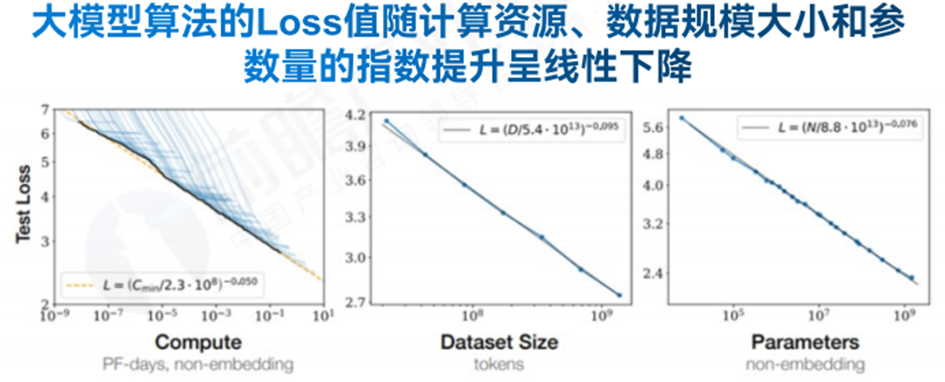
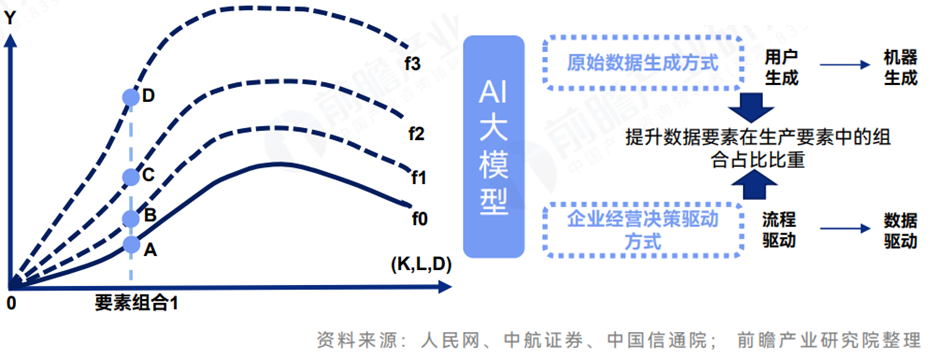
**AI大模型技术进步提升生产要素使用效率。**基于生产函数模型,AI大模型的技术进步对生产函数的影响如图所示,且当前的大模型技术进步对经济增长的影响仍成发散态势,即AB<BC<CD。AI大模型的应用从改变数据要素的生成方式和企业经营决策驱动方式两大维度提升了数据要素在生产要素组合中的占比地位。
5、大模型发展以Transformer为技术基座
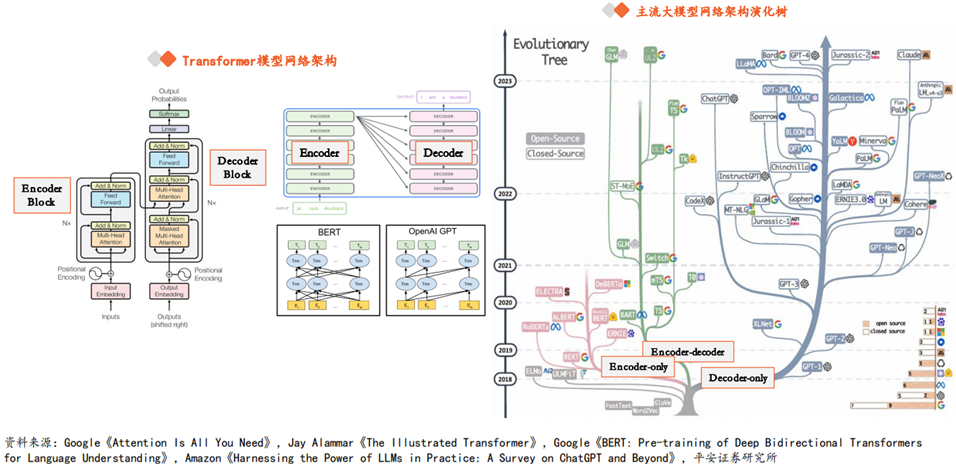
当前主流大模型普遍是基于Transformer模型进行设计的。Transformer模型在Google团队2017年论文《Attention Is All You Need》中被首次提出,Transformer的核心优势在于具有独特的自注意力(Self-attention)机制,能够直接建模任意距离的词元之间的交互关系,解决了循环神经网络(RNN)、卷积神经网络(CNN)等传统神经网络存在的长序列依赖问题。
相较于RNN,Transformer具有两个显著的优势。1)处理长序列数据:RNN受限于循环结构,难以处理长序列数据。Self-attention机制能够同时处理序列中的所有位置,捕捉全局依赖关系,从而更准确地理解、表示文本含义。2)实现并行化计算:RNN作为时序结构,需要依次处理序列中的每个元素,计算速度受到较大限制,而Transformer则可以一次性处理整个序列,大大提高了计算效率。

Transformer由两类组件构成:Encoder(编码器)和Decoder(解码器)。通常,Encoder结构擅长从文本中提取信息以执行分类、回归等任务,而Decoder结构则专用于生成文本。
实际上,两类组件可以独立使用,当前主流大模型中,诞生了以BERT为代表的Encoder-only架构、以T5为代表的Encoder-decoder架构、以GPT为代表的Decoder-only架构的大规模预训练语言模型。
6、大模型商业模式
**大模型收费模式可以总结为API、订阅、广告、定制化四种。**首先,大模型最常见的商业模式基本遵循软件行业的SaaS(Software as a Service),通用大模型通常会采取API模式,根据tokens/调用次数/产出内容量等计价,大模型形成AI产品后,可以采用订阅制,按月/季/年向用户收取使用费。同时,AI产品若具备一定程度的流量价值,能够吸引商家投放广告,从而收取广告费。此外,服务内容可以不限于大模型本身,针对付费能力强的企业客户,部分厂商会提供软硬件一体的定制化解决方案,称之为MaaS(Model as a Service)。
**从AI产品商业化程度来看,B端变现模式更加清晰,C端大多数产品仍然以免费为主。**根据量子位智库,面向B端的AI产品从通用场景到垂直赛道分布较均匀,收入模式以会员订阅和按需付费为主,商业模式较为清晰,虽然(纯B端)市场占比只有31%,但80%以上的产品均能实现营收。C端AI产品以智能助手以及图像生成类的生产力工具为主,虽然用户量大(纯C端占比50%以上),但近50%的产品当前仍未有明确的收入模式,以免费为主。
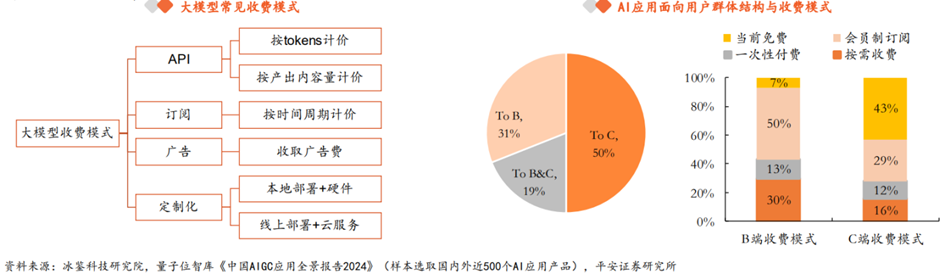
**纵观海内外的大模型厂商,OpenAI确立了最为经典的大模型商业模式,主要包括ChatGPT订阅、API调用、战略合作三种营收方式。**1)ChatGPT订阅:OpenAI向C端提供生产力解放工具ChatGPT,并以付费订阅模式变现,针对ChatGPT Plus会员收取每月20美元的订阅费。2)API调用:而对于模型使用灵活性要求更高的用户,提供API服务,基于模型的调用量(tokens)或者产出内容量(如图片张数、时长)收费。3)战略合作:此外,公司与微软建立了密切合作关系,ToC,OpenAI模型能力嵌入微软的生成式AI工具,如GitHub、Office、Bing等;ToB,微软Azure是OpenAI的独家云服务提供商,Azure全球版企业客户可以在平台上直接调用OpenAI模型。OpenAI绝大多数收入来自前两项,ChatGPT订阅和API调用。
02
行业现状
1、国内外企业争先发布AI大模型,AI大模型性能持续快速提升
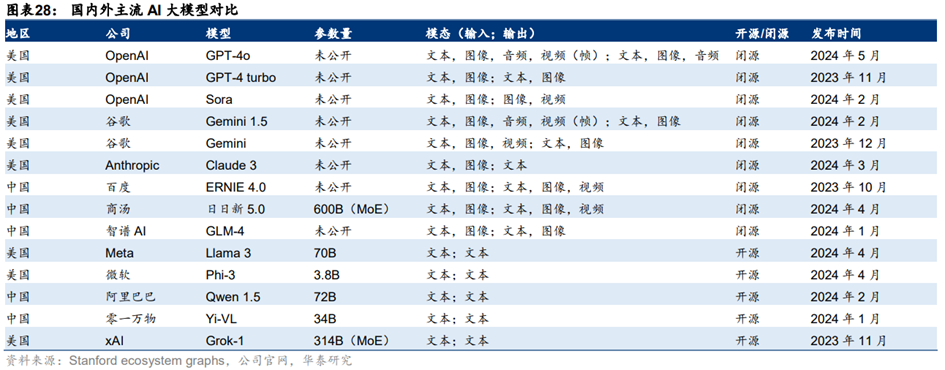
**全球大模型竞争中,OpenAI、Anthropic、谷歌三大厂商为第一梯队,**OpenAI先发推出GPT-4,在2023年基本稳定在行业龙头地位,而Anthropic凭借Claude、谷歌凭借Gemini后发,可以看到,2024年以来,三家大模型能力呈现互相追赶态势。目前,OpenAI、微软、谷歌、百度、阿里、字节跳动、讯飞等国内外企业争先发布自己的大模型。大模型的能力最初仅限于文字问答,此后逐渐引入图像理解、文生图能力,并通过GPTStore拓展功能,形成了AI Agent雏形,近期GPT-4o则实现了具备情感的互动。大模型的能力提升推动应用迅速向具备记忆、推理、规划、执行等能力的AI Agent演进。
**AI大模型性能持续快速提升。**以衡量LLM的常用评测标准MMLU为例,2021年底全球最先进大模型的MMLU5-shot得分刚达到60%,2022年底超过70%,而2023年底已提升至超过85%。以OpenAI为例,2020年7月推出的GPT-3得分43.9%,2022年11月推出的GPT-3.5提升至70.0%,2023年3月和2024年5月推出的GPT-4、GPT-4o分别提升至86.4%和87.2%。谷歌目前性能最佳的大模型Gemini 1.5 Pro得分达到85.9%。开源模型性能不容小觑,2024年4月推出的Llama370B得分已经达到82.0%。
2、开、闭源共存以满足不同应用开发需求
**双线竞争下,闭源模型和开源模型齐头并进。**与软件开发和分发类似,基于代码开发的AI大模型也面临着闭源或开源模型源代码和训练数据的选择。
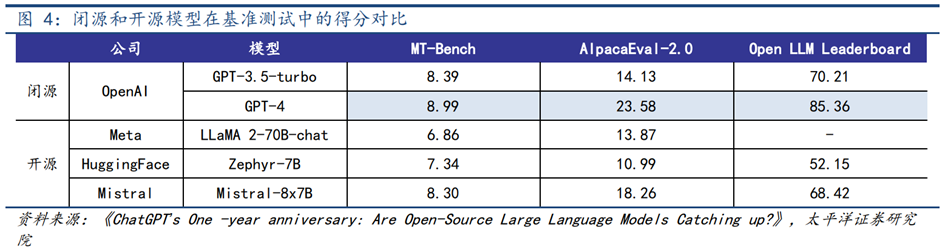
闭源模型**:能力优于开源,是模型基础能力上限持续突破的主阵地。**2023年3月,OpenAI发布最新大模型GPT-4,其不仅具备对图文输入生成应答文字等多模态能力,还在上下文窗口容量、推理能力等方面实现突破,GPT-4由此成为了最强大模型。随后,谷歌发布Gemini 1.0及更新后的Gemini 1.5 Pro,把上下文窗口容量再次提升。进入2024年,Anthropic发布最新大模型Claude3,其在模型理解能力(MMLU)、推理能力(GPQA)等再次实现突破,得分超过GPT-4和Gemini 1.0 Ultra,成为目前能力最强的大模型。出于商业竞争、安全等因素的考量,这些模型仍均为闭源模型。对比它们与开源模型在基准测试中的得分,闭源模型表现明显更为突出。头部大模型公司正凭借科研实力、人才、算力资源等优势,成为推动模型基础能力持续实现突破的主要力量。
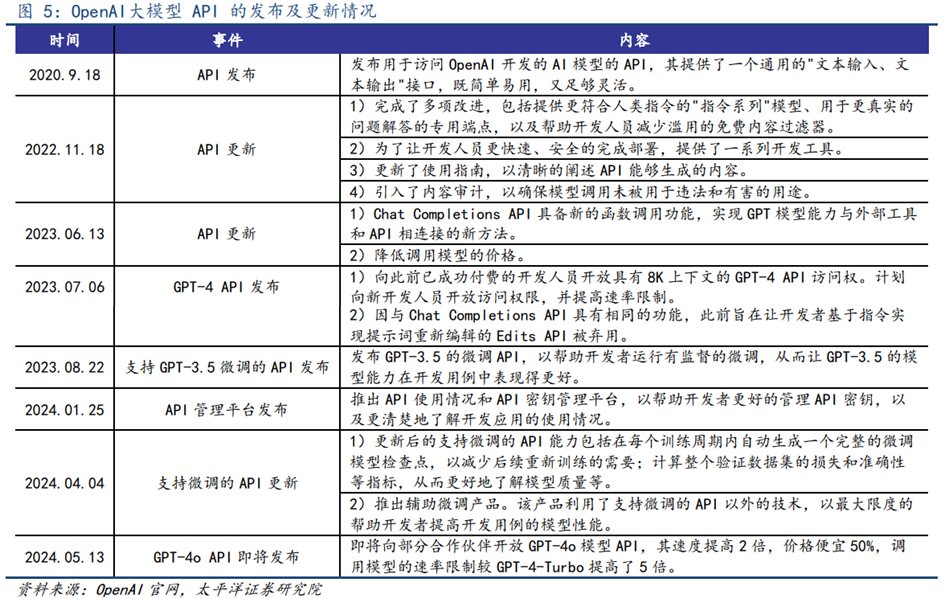
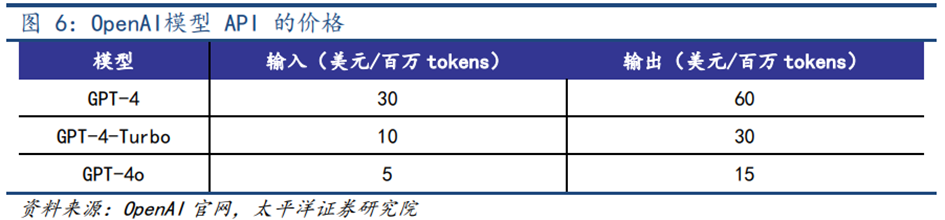
**基于闭源模型****的应用通过API实现,同时API能力提升、价格下降。**基于闭源模型的应用开发通过连接闭源模型API的形式实现。API接口允许用户将模型功能集成到自己的应用程序或服务中,实现数据的输入输出和模型功能的调用。随着模型不断更新迭代,模型API的能力也正持续进化。以OpenAI为例,其大模型API已完成多次更新,并支持微调功能,逐步为用户提供能力更强、更易用的API服务。其中,最新的GPT-4o API实现速度提高2倍,价格便宜50%,调用模型的速率限制较GPT-4-Turbo提高5倍。价格方面,GPT API价格呈现随模型能力提升而下降的趋势,最新的GPT-4o API输入和输出百万tokens的价格分别为5、15美元,仅为GPT-4 API的16.7%和25%。
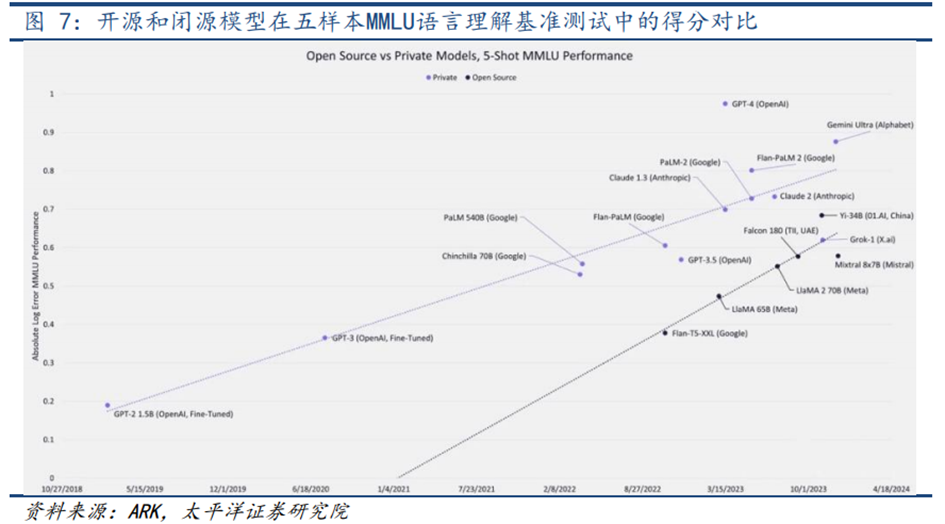
**开源模型:与闭源模型差距缩小,基于开源模型的应用通过fine-tuning实现。**类比于互联网时代开源操作系统Linux和安卓在大量开发人员贡献代码、报告错误等社区共建中实现发展,人工智能时代开源模型也正在社区群策群力、共同开发的支持下,实现模型能力的逐步提升。根据ARK基金统计的开源和闭源模型在五样本MMLU语言理解基准测试中的得分对比,开源模型与闭源模型的测试得分差距正不断缩小。在应用开发层面,以LLaMA为例,通过继续预训练和指令微调的方式,应用开发者能利用自有数据对开源模型进行微调,从而获得与应用更匹配的底层大模型。
当前海外市场中,OpenAI和谷歌闭源模型领先,Meta凭借开源模型Llama系列模型独树一帜;国内市场中,百度、月之暗面等坚持闭源模型,阿里、商汤、智谱、百川、零一万物等互联网大厂或初创公司开源与闭源兼具。
3、政策驱动中国AI大模型产业发展
近年来,我国始终高度重视人工智能发展机遇和顶层设计,发布多项人工智能支持政策,国务院于2017年发布《新一代人工智能发展规划》。科技部等六部门也于2022年印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》对规划进行落实。2024年《政府工作报告》中提出开展“人工智能+”行动。伴随人工智能领域中大模型技术的快速发展,我国各地方政府出台相关支持政策,加快大模型产业的持续发展。当前,北京、深圳、杭州、成都、福建、安徽、上海、广东等地均发布了关于AI大模型的相关政策。具体来看,北京着力推动大模型相关技术创新,构建高效协同的大模型技术产业生态;上海强调打造具备国际竞争力的大模型;深圳重点支持打造基于国内外芯片和算法的开源通用大模型,支持重点企业持续研发和迭代商用通用大模型;安徽从资源方面着手吸引大模型企业入驻;成都着力推动大模型相关技术创新,重点研发和迭代CV大模型、NLP大模型、多模态大模型等领域大模型以及医疗、金融、商务、交通等行业大模型;杭州支持头部企业开展多模态通用大模型关键技术攻关、中小企业深耕垂直领域做精专用模型。

4、国内模型百花齐放,互联网大厂、初创公司、科技企业均有代表性模型产品
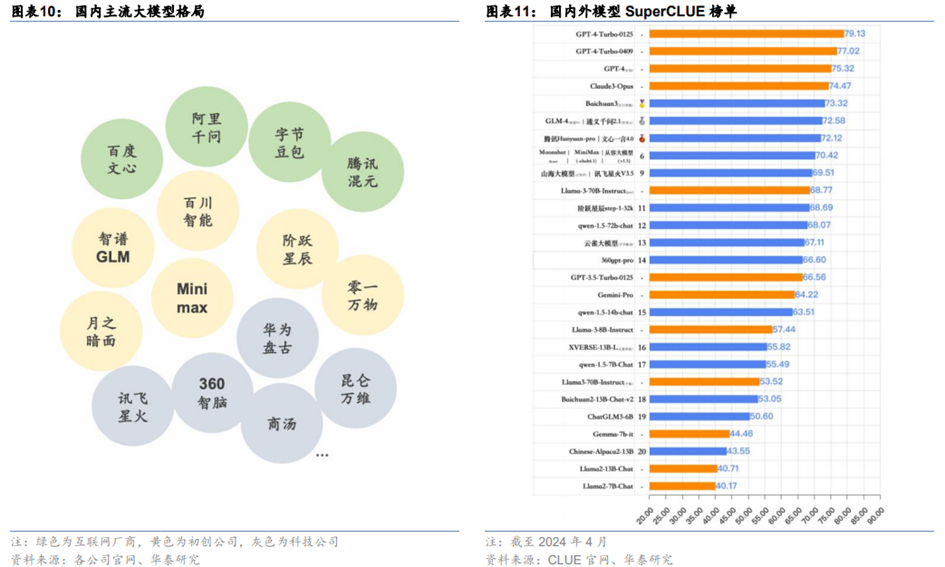
国内模型技术辨识度不高,据SuperCLUE测评结果榜单,头部的国内模型在得分上相差并不显著。在国内主流的模型中,互联网厂商和科技企业在大模型上起步较早,如百度在GPT-4发布的后一天即23年3月15日发布文心一言,23年3月29日360智脑1.0发布,23年4月通义千问上线,23年5月6日讯飞星火1.0发布。进入24年,初创公司的大模型产品得到了更广泛的关注,例如24年3月月之暗面更新Kimi智能助手200万字的上下文支持能力,直接引发了百度、360等厂商对长上下文的适配。同月阶跃星辰STEP模型发布,其STEP2宣称为万亿参数MoE模型,直接对标GPT-4的参数(一般认为是1.8T参数的MoE),在大多数国内模型以千亿参数为主的环境下,将参数量率先提升到万亿级别。4月,MiniMax也发布了万亿参数MoE架构的abab6.5。
5、国内AI大模型产业市场规模
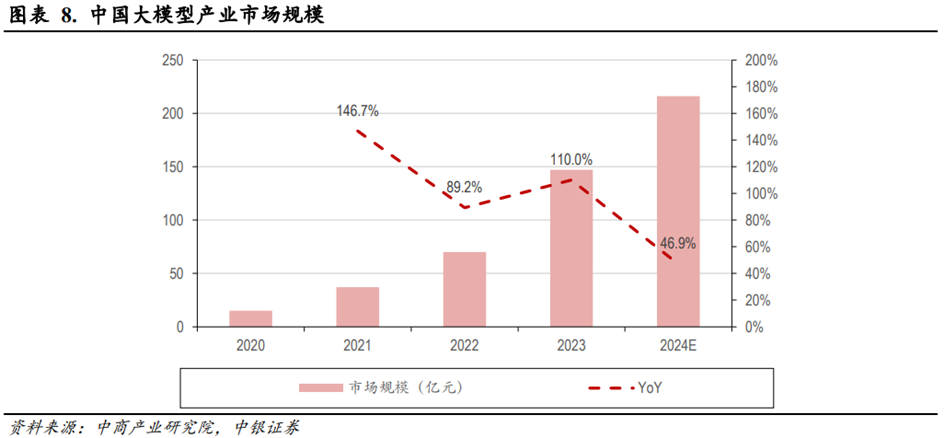
根据中商产业研究院的数据,2020年到2023年,大模型产业的市场规模从15亿元快速增长到147亿元,年复合增速约114%,其中2023年元年同比增速为110%。
6、国内通用AI大模型用户规模快速增长
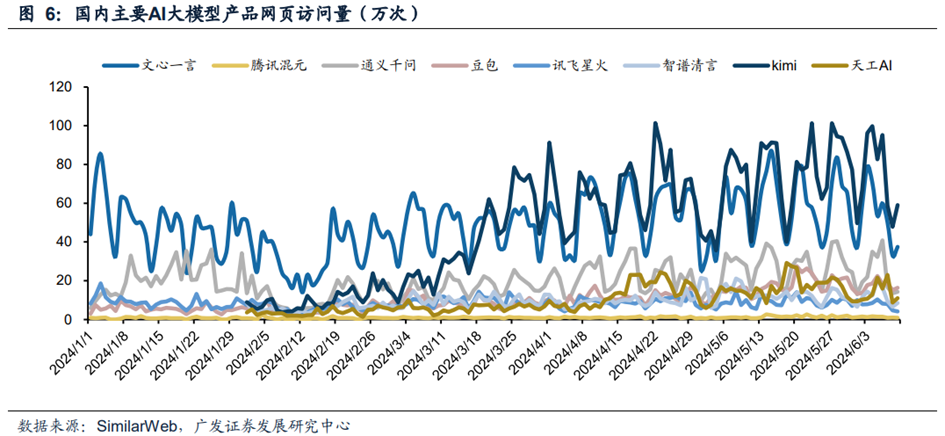
国内AI大模型随着功能性能不断提升,下游客户使用意愿有所提升,相应的用户规模快速增长。从月度活跃数据来看,部分国内AI大模型的月活用户规模由2023年的十万级别快速提升到2024年的百万级别。2024年,字节跳动开发的豆包大模型和百度开发的文心一言的月活用户规模都超过1000万人。从每日访问量数据来看,Kimi和文心一言的网页访问量已经稳定在十万次级别,其中Kimi网页的访问量自年初以来有较大幅度增长。
03
国内AI大模型行业应用痛点及解决方案
1、AI大模型行业应用痛点
(1)算力、数据不足
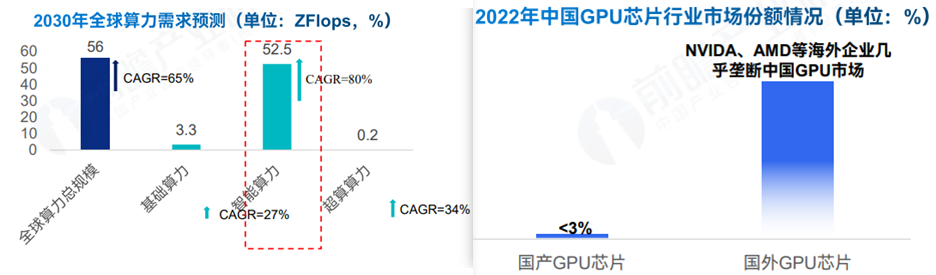
**大模型算力需求巨大:**根据预测,随着大模型的不断开发和应用,全球的算力消耗将呈现指数级增长,2030年智能算力需求为52.5ZFlops,是全球算力最主要的需求增长动力。
**国产服务器供给不足,进口面临卡脖子:**在供给方面,算力供给的核心取决于GPU芯片,然而由于发展基础差异,我国GPU芯片市场长期被海外企业垄断,并且受中美贸易摩擦影响,近年来也面临着限制进口的卡脖子问题。
**大模型对数据要求高:**需求方面来看,大模型的训练对数据的需求特征主要体现数据体量足够庞大和数据质量足够优秀,其中数据质量有表现在准确性和连贯性等方面。此外,当前随着多模态大模型的不断应用发展,大模型对数据的需求特征也呈现多模态化的特点。
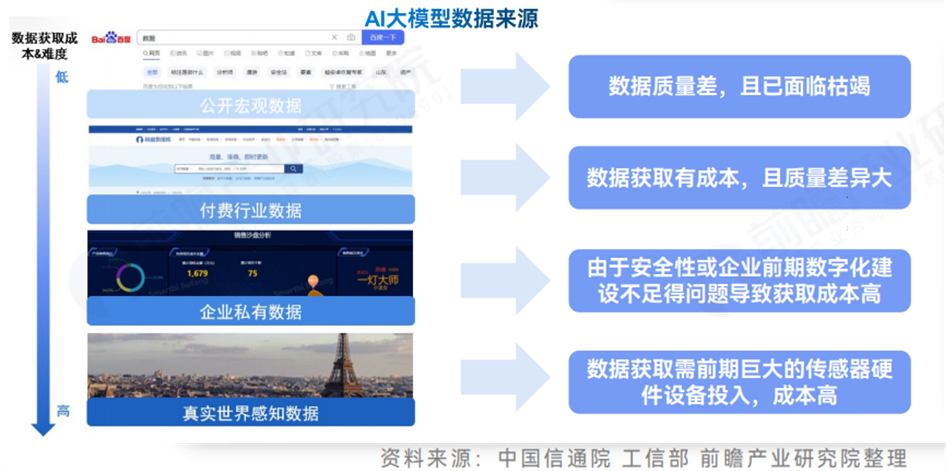
**数据供给面临枯竭:**在供给方面,当前训练AI大模型的数据来源则主要有四种。当前绝大部分AI大模型企业主要采用公开数据或付费的行业数据库,这些数据一方面质量参差不齐,另一方面当前也逐渐面临数据枯竭的问题;而大模型企业想要获得更质量的数据则只能选择企业私有数据或真实世界感知数据,但都面临着数据获取难度大或者成本高的问题。
(2)人才缺失与法规风险
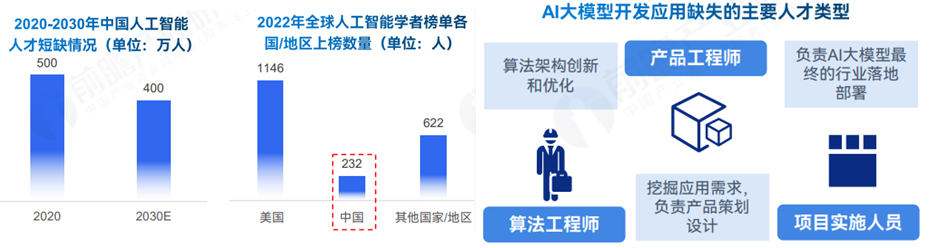
我国在AI大模型面临人才短缺问题,无论是人才数量还是质量都与发达国家有明显差距。当前我国人工智能人才缺口已超过500万,供需比例失衡,且预计到2030年这一缺口将超过400万。同时,顶尖算法人才不足,全球最具影响力学者榜单中美国学者数量是中国学者的五倍。这些问题对大模型研发及整个人工智能行业的快速发展构成了挑战。
**当前AI大模型存在:1)数据安全和隐私问题:**大模型的训练和应用需要处理大量数据,其中可能包含敏感或个人信息。现有的数据保护法律法规可能难以完全覆盖大模型相关的数据使用场景,特别是在跨境数据传输、数据匿名化处理等方面,存在法律空白或不足。**2)监管与技术创新矛盾:**当前我国大模型主要实施备案制度,以规范和监管大模型的开发和使用。然而,技术的快速迭代和复杂性使得备案审批过程可能变得缓慢和繁琐,影响到大模型的研发和市场应用速度。**3)责任归属和伦理问题:**当前大模型已逐步逼近图灵测试的极限,且部分企业已将大模型技术应用于复活逝者等敏感行业,造成社会争议。未来随着AI大模型技术的突破,相关矛盾将进一步突出和加剧。**4)知识产权(IP)问题:**大模型的开发涉及大量代码、算法、数据集等知识产权。此外,如何处理由AI生成的内容的版权,也成为一个挑战。
(3)市场认知不准及行业know-how不足
在企业调研访谈中发现市场对AI大模型行业应用的认知不准确也是当前AI大模型行业应用推进过程中企业面临的主要痛点,这种认知不准确则分为两类极端:1)认知严重不足:部分群体或企业并不认可AI大模型的能力,故选择不采购相应服务;2)认知预期过高:客户对AI大模型能力有较高预期,采购应用后发现无法达成预期失望;
从目前来看,由于AI大模型的火爆,认知预期过高的群体甚至可能超过认知不足的群体,从而对AI大模型的实际应用落地造成巨大的阻碍。
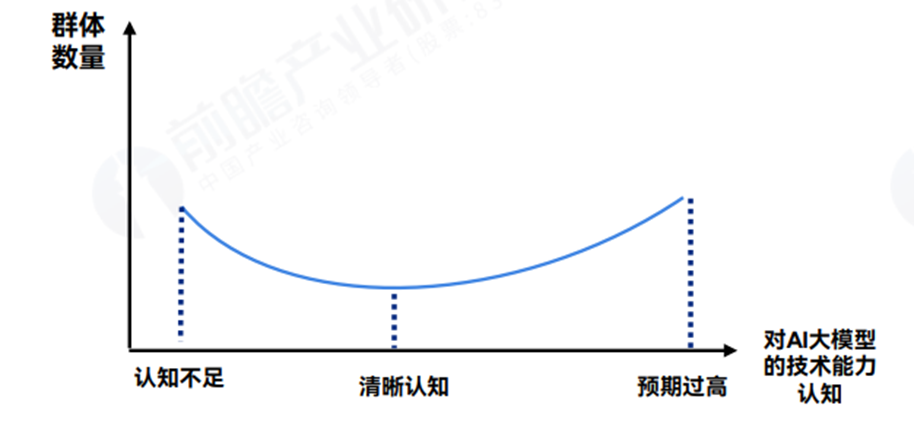
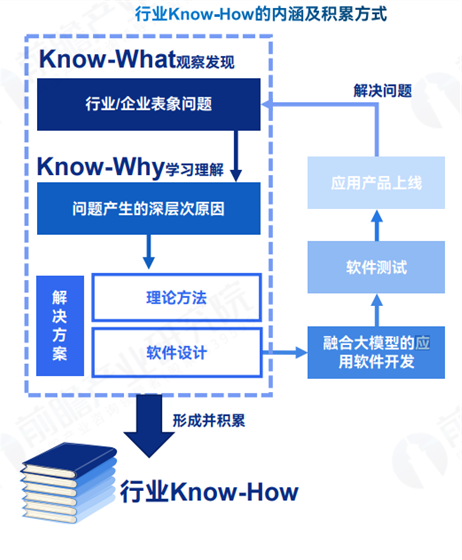
对于AI大模型的行业应用,除了AI大模型本身的能力提升,最重要的便在于如何实现应用落地,并且真正有用。应用程序算法本身难度并不大,不同企业的应用产品之间的差异点在于软件内核体现出的企业对行业know-how的积累和深度,这需要长时间和丰富的实践案例的积累。
2、AI大模型行业应用痛点解决方案
**为了应对算力不足的问题,**可以采取以下几种方式:首先,租用算力是一种主流且灵活性高的解决方案,其成本相对较低;其次,合作建设算力中心也是一个有效的策略,可以自主或与硬件厂商共建,满足特定算力需求,例如科大讯飞与华为的合作;最后,优化算法,关注应用场景,减少对算力的需求,也是一个可行的方法。
**面对数据缺乏的问题,**可以采取多种策略。如:购买数据是当前企业获取非公开数据的主要途径;其次,与企业合作也是一种获取数据的有效方式;最后,布局现实传感,获取真实数据,可以为企业提供更全面的数据支持。
为了应对人才缺失的挑战,可以采取与高校合作,如科大讯飞联合成渝多所高校,共同推进AI专业人才的培养;其次,举办开发者大赛,如百度、华为通过悬赏的方式举办大赛,吸引高技术人才。
**为了应对法规风险,产权风险,数据安全风险以及伦理及合规风险,**可以采取以下措施:增加隐性数字水印以应对产权风险;建立安全风控机制及保护措施以应对数据安全风险;在方向选择或数据筛选过程中直接过滤不合规信息以应对伦理及合规风险。通过这些策略,可以有效地降低各种风险,确保企业的合规性和安全性。
为了解决市场认知不准确的问题,应积极推进市场化应用的落地,并塑造企业案例,以提高市场对企业的准确理解和认知。
针对行业know-how不足的问题,可以通过与头部企业合作来积累know-how,聘请行业专家,与第三方行业咨询公司合作,以及构建行业生态合作体系,以促进know-how的获取和应用。
04
产业链分析
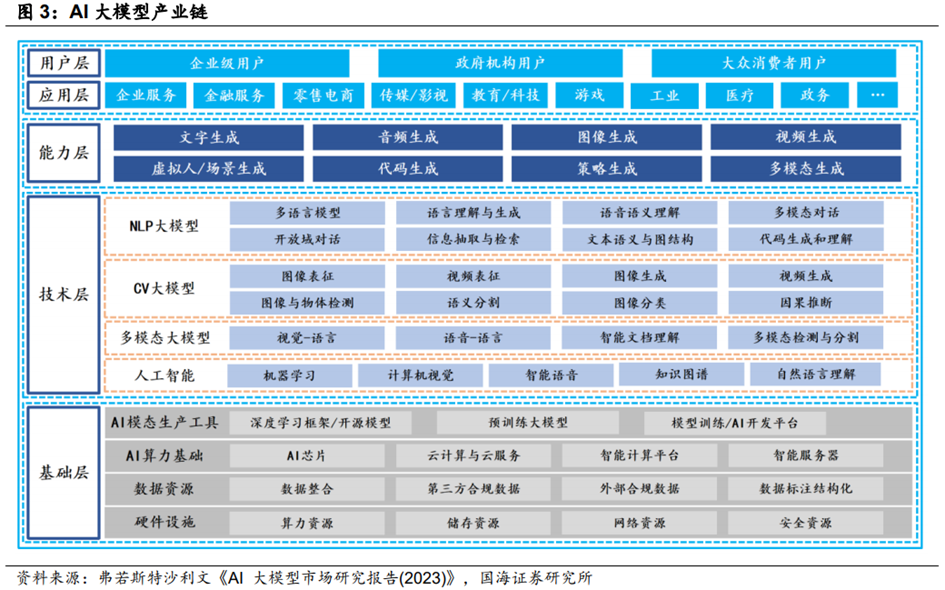
大模型的技术架构可分为基础层、技术层、能力层、应用层和终端层五个层次:
**基础层:涉及硬件基础设施和数据、算力、算法模型三大核心要素。**随着AI大模型规模的不断扩大,对计算资源的需求也在增加。因此,高性能的硬件设备、海量场景数据、强大的算力基础和升级迭代的算法模型成为了支持AI大模型发展的关键。深度学习模型的不断升级和迭代,增强了AI算法的学习能力;同时,开源模式将使AI大模型成为海量应用、网络和服务的基础。
**技术层:AI大模型的技术层主要涉及模型构建。**目前,Transformer架构在AI大模型领域占据主导地位,如BERT、GPT系列等。AI大模型包括NLP大模型、CV大模型、多模态大模型等。这些模型采用预训练和微调的策略,先在大量无标注数据上学习语言或图像的基本表示,然后针对特定任务进行微调。
**能力层、应用层及用户层:在基础层和技术层的支持下,AI大模型拥有了文字、音频、图像、视频、代码、策略、多模态生成能力等,**具体应用于金融、电商、传媒、教育、游戏、医疗、工业、政务等多个领域,为企业级用户、政府机构用户、大众消费者用户提供产品和服务。
1、基础层:AI高性能芯片不断升级,AI大模型产业生态体系将不断完善
在大模型场景下,AI高性能芯片主要用于大模型的训练环节,芯片性能的强弱直接影响大模型的性能和表现。在全球AI高性能芯片市场中,英伟达的芯片产品采用最前沿半导体工艺和创新GPU架构保持行业的领先地位。目前,英伟达的A100芯片在主流AI大模型训练中占据重要市场份额,H100虽性能强劲但难以获取。AI高性能芯片未来将不断迭代升级,持续推动大模型性能和能力的提升。在国内,AI高性能芯片近年来发展速度加快。其中,华为昇腾主要包括310和910两款主力芯片,其中昇腾910采用了7nm工艺,最高可提供256TFLOPS的FP16计算能力,其能效比在行业中处于领先水平。寒武纪是中国具有代表性的另一本土AI芯片厂商,公司先后推出了思元290和思元370芯片及相应的云端智能加速卡系列产品、训练整机。未来,随着全球AI高性能芯片不断迭代升级,也将持续推动大模型性能和能力的提升。
2、能力层、应用层及用户层:企业AI+与+AI的战略选择
**随着大模型能力的不断增强,AI的作用不断深化,生成式AI新的应用不断被解锁。**通过对AI在搜索、电商零售、办公、金融法律、影视游戏,医药、教育、汽车等行业应用前景的分析,能够认为,AI应用的落地节奏或与行业数字化程度成正比,能够看到AI大模型在互联网(搜索+广告营销)、办公、金融等领域率先迎来“iPhone时刻”。
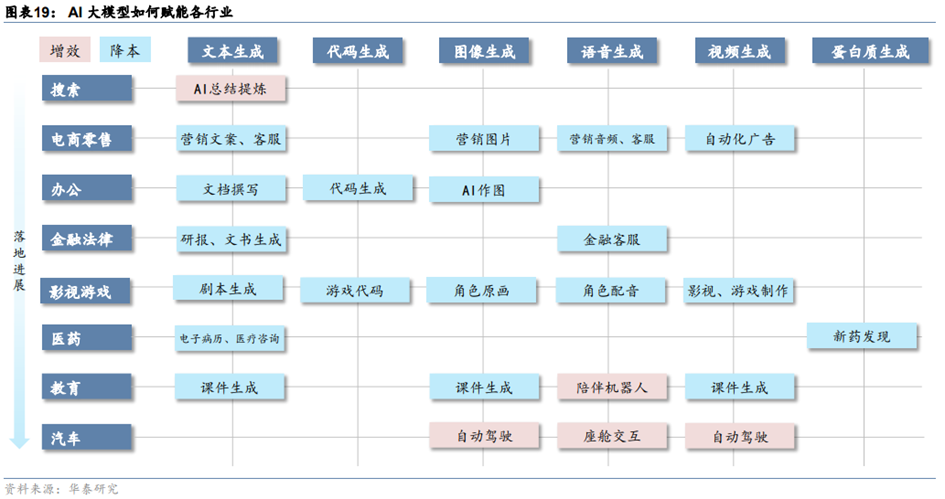
“AI+”是以AI技术为核心,重构现有业务;“+AI”是以现有业务为核心,借助AI降本增效,是改进而非重建。从结果来看,“AI+”企业在智慧城市等特定领域获得商业成功,但互联网(例如谷歌、百度的搜索,头条的推荐,阿里的广告)、金融等行业通过已有业务+AI提升了效率。
在当前大模型主导的创新周期中,大模型的应用模式仍然是许多企业关注的焦点。企业需要决定是选择“AI+”(以AI技术为核心,重构现有业务)还是“+AI”(以现有业务为核心,借助AI降本增效)?对于大模型应用模式的选择可以从两个方面考虑:
**首先,要考虑AI在企业全业务流程价值链中所占比例。**如果AI在该赛道全业务流程价值链中所占比例很小,比如只有10%,则更容易从“+AI”切入。因为要从“AI+”切入,企业需要先将剩下的90%业务补足,而在产业链深耕多年的竞争对手很可能已经补足了这90%。相比之下,如果AI占据全业务价值链的较大比例,“AI+”将有更大的发展空间。例如,在电商领域,可能更适合从“+AI”切入。因为即使没有AI技术,商家仍然可以通过提供更优质的产品和服务来取胜。这是因为AI在电商全业务价值链中所占比例较低,而用户、渠道和产品等因素更为关键。大模型在电商领域更多地用于降低成本和增加效率,例如自动生成营销文案、图像快速检索和智能语音客服等。
**其次,要考虑企业业务中AI是否具备护城河。**如果AI在业务中没有护城河或者门槛很低,选择“+AI”更适合持续发展。因为一旦传统企业认识到AI的价值,也开始采用“+AI”策略,其他企业很容易赶上来。在这种情况下,创业公司选择“AI+”可能难以生存。相反,如果AI在业务中形成了较高的护城河,“AI+”也许会产生创业机会。即使AI只占全产业链的一小部分,比如30%,但这30%却具有非常高的门槛。后来进入市场的传统企业即使在其余70%上取得优势,也难以突破这30%的高门槛。因此,提前入局并占据了30%份额的企业仍能持续经营,这也是“AI+”模式的机会所在。
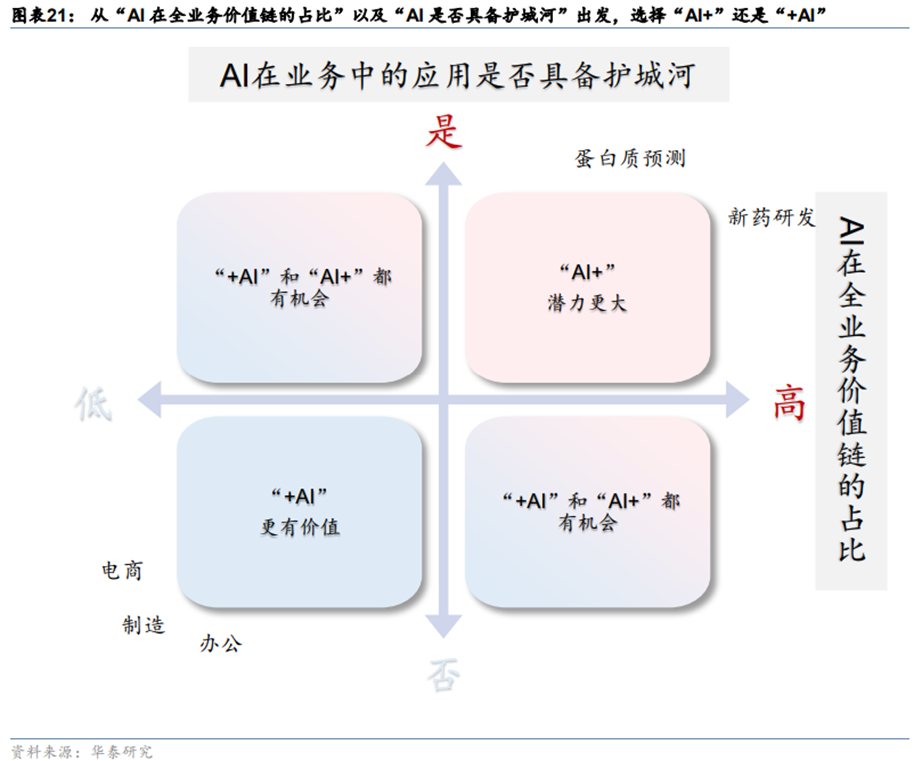
综上,本轮“+AI”和“AI+”都可能获得可观的价值,“+AI”赋能众多传统业务,比如电商的阿里和京东、办公软件的微软和金山办公等,因为有自身发展需求、具备商业价值的海量数据。“AI+”更可能重塑行业,例如在数据更私密、算法壁垒更高、定制化程度较高的自动驾驶等关键领域。
05
AI大模型应用落地方式
从2022年11月OpenAI发布ChatGPT以来,科技巨头积极推出各类应用来吸引客户。目前比较主流的应用包括:1)聊天机器人:具备语言问答、文本生成、图像理解与生成等功能,代表性产品包括ChatGPT、谷歌Gemini、字节豆包、百度文心一言等。2)编程工具:具备自动代码生成、代码分析与错误检测、实时编程建议等功能,代表性产品包括Github Copilot、谷歌Alpha Code2等。3)生产力工具:通常提供文档理解、文字生成、图片生成、数据分析与处理等功能,代表性产品包括微软Copilot、谷歌Gemini for Workspace、金山办公WPS AI。
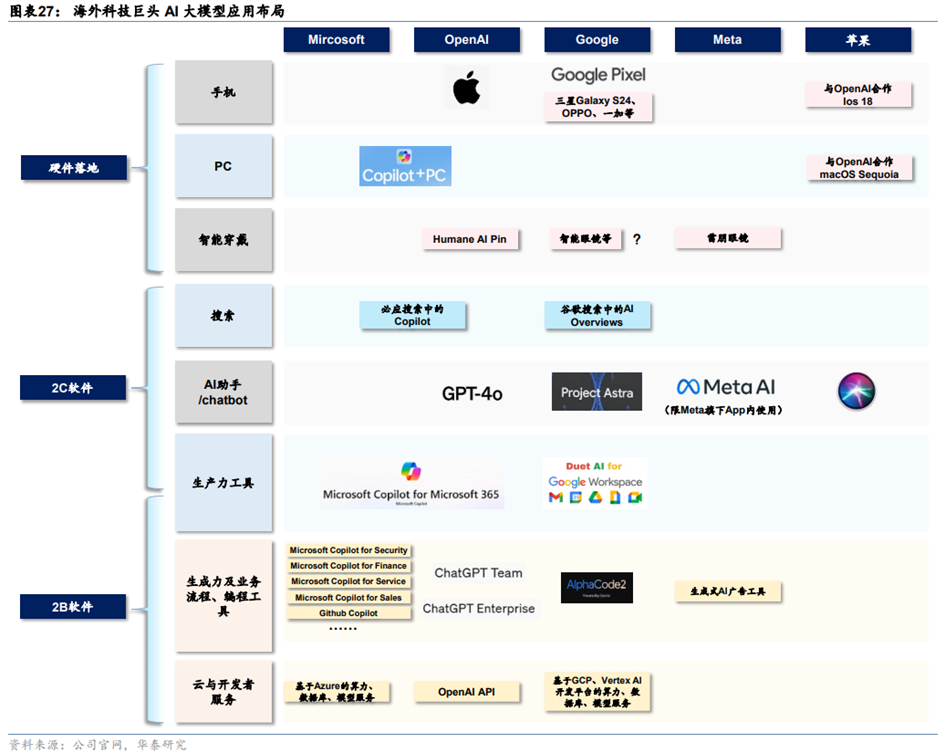
1、从Chatbot到AI Agent,个人助理重塑手机应用生态
**AI大模型的能力进步推动Chatbot在C端广泛“出圈”。**Chatbot(聊天机器人)通过自动化方式来处理和回复用户输入,可以模拟人类对话,通过文字或语音与用户进行实时交互。2010年代,随着NLP等技术的发展,Chatbot已经在客服、营销、企业信息服务等领域得到了广泛应用。然而,由于语言理解及生成能力有限,Chatbot的落地范围局限在B端特定服务型场景,并未诞生具有广泛影响力的C端产品。2022年12月,ChatGPT在文本生成、代码生成与修改、多轮对话等领域展现了大幅超越过去AI问答系统的能力,标志着Chatbot行业进入AI大模型时代。此后,Chatbot作为C端用户体验大模型门槛最低的产品,成为大模型厂商的“标配”,谷歌Bard、百度文心一言、阿里通义千问等产品在2023年纷纷推出。
**在文字对话功能之外,Chatbot功能随着AI大模型能力的发展而迅速丰富。**过去一年,各大模型厂商的Chatbot产品普遍新增了图像理解、文生图功能,并且新增应用插件商店以拓展Chatbot功能。以ChatGPT为例,2023年9月,OpenAI将DALL-E3整合到ChatGPT中,从而支持文生图功能。2024年1月,OpenAI正式上线应用商店GPTStore,当时用户已经创建超过300万个GPTs,主要的GPTs涵盖图像生成、写作、科研、编程/软件开发、教育、生产力工具和生活七大类别。GPTStore取代了此前的插件商店(2024年3月关闭),用户不仅可以在平台上分享自己创建的GPTs,还可以从其他人那里获取各种GPTs,形成丰富的GPTs生态系统。GPTStore定制版本可以针对特定任务或行业进行优化,允许用户与外部数据(如数据库和电子邮件)进行简洁的交互。2024年5月,随着OpenAI更新GPT-4o模型,ChatGPT能够识别用户语音的感情,并输出语音,实现如同与真人对话一般的沉浸式体验。
**Chatbot逐渐向AI Agent演进。**AI Agent是指大模型赋能的,具备规划、记忆、工具、行动能力的智能体。Chatbot的演进方向是智能化和自动化程度逐渐提升,需要人类参与的程度逐渐下降,逐渐过渡到人与AI协作的Copilot,最终形态是AI Agent,Agent只需要人类的起始指令和结果的反馈,具有自主记忆、推理、规划和执行的全自动能力,执行任务的过程中并不需要人的介入。
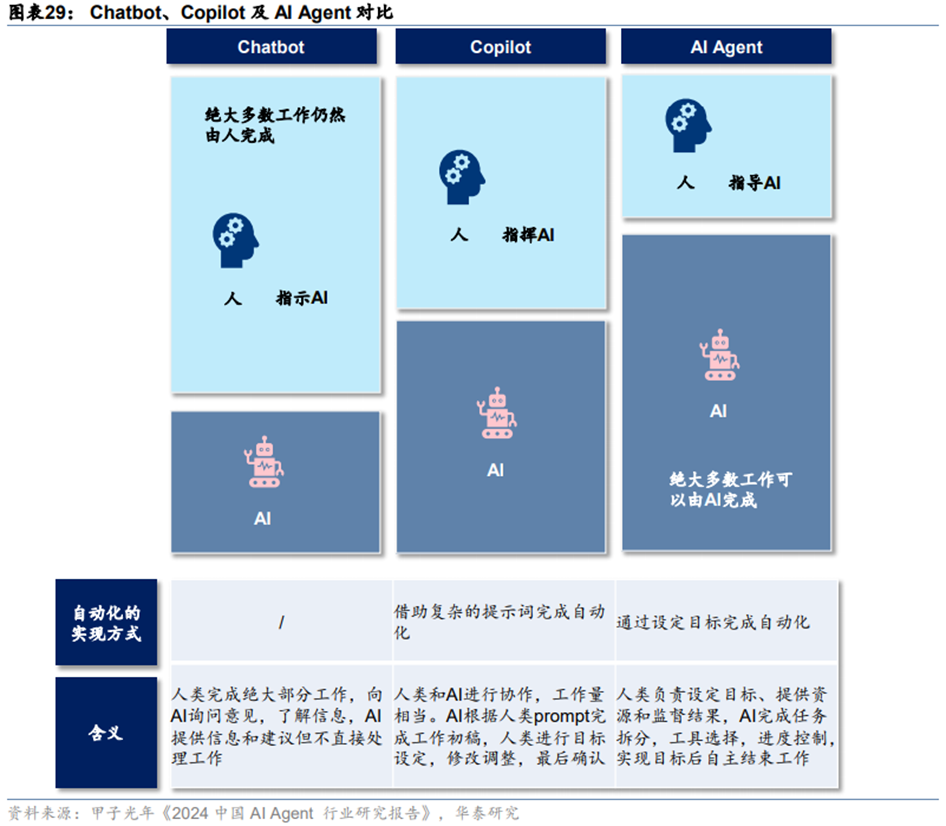
**从Chatbot向AI Agent的演进过程中,手机应用生态或将发生改变。**手机或是向AI Agent演进率先落地的硬件载体,发挥AI个人助理的作用。AI个人助理可以记住生活和工作中的各种信息,如下周的晚餐计划或工作会议的内容,并自动整理和索引这些信息;可以帮助用户完成例如安排约会、预订旅行、点餐、播放音乐、回答问题等各种任务。落地过程中,手机应用生态或将从目前以应用商店+APP的模式转变为AgentStore+Agent的模式,手机厂商可能都会发布自己的AgentStore。
(1)AI手机:AI大模型驱动软硬件升级
手机已经成为AI大模型在C端落地的重要设备。去年底至今,随着三星Galaxy S24、Google Pixel 8等重要产品上市,及苹果WWDC推出Apple Intelligence,手机AI的功能逐渐清晰。目前语音助手、修图、写作助手等功能成为主流。
以三星今年1月发布的GalaxyS24为例,该机型搭载自研大模型Samsung Gauss,具备实时翻译/圈选搜图/生成式编辑/笔记助手等功能。软件方面,基于OneUI6.1系统,强化虚拟助手Bixby,为用户提供丰富多样的应用服务。据Techweb,Google有望在10月推出Pixel9系列,预计将搭载基于最新Gemini模型的AI助手,执行复杂的多模态任务。芯片方面,下半年将发布的骁龙8Gen4较上一代产品有望进一步支持AI应用。

2024年6月举行的苹果WWDC2024大会推出全新个人化智能系统Apple Intelligence,由苹果端侧大模型、云端大模型、ChatGPT共同组成,算力足够下依赖终端,复杂场景则使用私密云计算或ChatGPT,能够1)增强Siri理解能力,配备多轮对话、总结信息、屏幕内容感知、应用智能交互等能力,2)提供邮件智能回复、通知整理,备忘录和通话录音/撰写/摘要等功能,3)支持图像生成/智能修图等功能,4)ChatGPT 4o将融入siri和writingtools,作为云端备选模型。Apple Intelligence核心能力包括文生文、文生图、跨App交互与个人情境理解,并需要以OpenAI ChatGPT4o作为云端备选模型,配备上了目前已有的大部分AI功能。苹果通过Siri,把AI当作手机不同App之间联系的工具,而不是像此前三星和谷歌的AI应用更侧重于让AI去完成单一特定任务。苹果让Siri在未来成为应用分发入口和流量入口,以超过13亿台用户基数生态去提供好的产品解决方案。
IDC认为,新一代AI智能手机需拥有至少30TOPS性能的NPU,能够在手机上运行LLMs,符合标准的SoC包括Apple A17 Pro、Media Tek Dimensity 9300、Qualcomm Snapdragon8 Gen 3等。此类手机在2023年下半年开始进入市场。
**硬件方面,**1)SoC:AI引擎升级、NPU算力提升,SoC进一步升级确定性强;2)存储:手机RAM升级至24GB LPDDR5X,相较当前主流的8GB LPDDR4X,成本提升300%;3)电源:电池/电源管理芯片升级,但弹性相对较小;4)光学:AI推动屏下摄像头应用取得突破。软件方面,新一代AI智能手机在系统架构和应用方面更加注重个性化、场景化服务需求。
**软件方面,与功能机和前代智能机相比,新一代AI智能手机更加注重场景化服务能力。**前代智能机在功能机的基础上增加了手机OS和内嵌语音助手,并针对用户不同需求推出独立APP进行响应。新一代AI手机在大模型和原生化服务组件库的基础上,提供用户可定义的智能体开发平台和专属智能体,实现AI文本/AI图像/Al语音/Al视频等功能,满足用户健康管理/生活服务/角色扮演/高效办公/游戏助手等场景化需求。
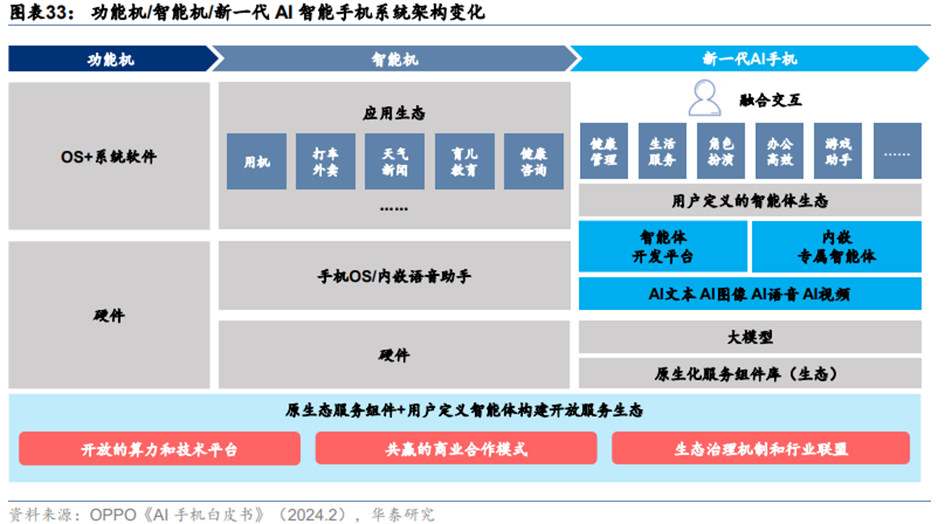
据IDC,全球AI手机2024年出货量有望同比增长233%至1.7亿台。中国AI手机所占份额自2024年以后会迅速增长,预计2024年中国市场AI手机出货量为0.4亿台,2027年将达到1.5亿台,且AI手机渗透率有望在2027年超过50%。能够认为,AI手机以其智能化、个性化的特点,有望吸引更多用户进行换机升级,从而引领新一轮的换机潮。
(2)AR/VR:AI大模型交互能力,看好智能眼镜等轻量级AR发展机遇
**AI大模型有望提升AR/VR交互能力,加速其进入主流市场。**据IDC,2023年,AR/VR产品全球出货量675万台,同比-23%。随着苹果VisionPro发布,AR/VR/MR出货量在2024年有望温和复苏。AI大模型的出现驱动语音助手、物体识别和生活助理等功能赋能AR/VR设备,提升了用户与虚拟环境的互动质量,据VR陀螺(2024/6/5),Meta雷朋智能眼镜出货量已超百万副,AI大模型的出现有望加速AR/VR技术进入主流市场的步伐。
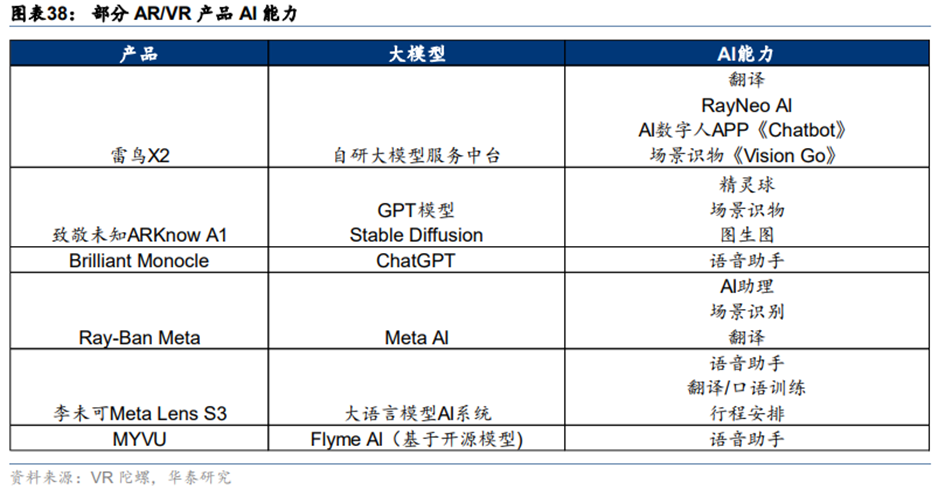
**语音助手、物体识别、生活助理等AI功能已在AR/VR产品中广泛出现。**语音助手功能让AR眼镜能够通过上下文语义理解与用户进行更自然的交流,如李未可MetaLensS3通过大型语言模型AI系统提供闲聊和建议。物体识别技术使AR眼镜能够识别现实世界中的物体,例如Meta雷朋智能眼镜引入建筑识别和菜单翻译功能。此外,生活助理功能与用户的社交生活深度绑定,提供聊天回复、邮件整理、购物建议等个性化服务。这些AI功能的融合不仅提升了用户体验,还预示着AR/VR产品将更加智能化,为用户提供更便捷和个性化的服务。随着技术的不断进步,预计未来AR/VR设备将实现更复杂的多模态AI应用,进一步增强其作为下一代计算平台的潜力。
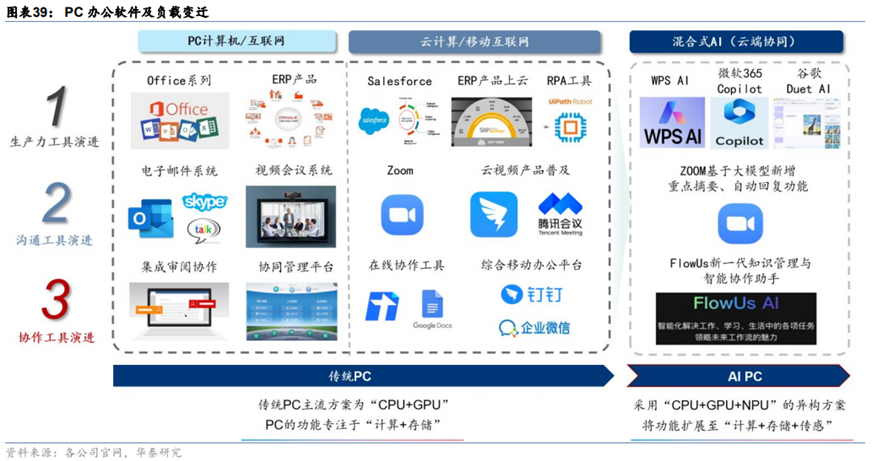
2、生产力工具的AI化推动新一轮PC换机周期
**生产力工具、沟通工具及协作工具经历了PC时代、移动互联网时代的演进,正在进入AI时代。**微软、谷歌与金山办公等公司以AI大模型对原有的生产力工具应用进行升级,通常提供文档理解、文字生成、图片生成、数据分析与处理等等功能,提升用户生产力。
(1)办公:微软、谷歌引领产品矩阵全面AI化
**微软是全球生产力工具的领导企业,围绕企业业务与管理流程,已经形成了布局完整的产品矩阵,目前正主导生产力工具的AI化。**微软的产品矩阵覆盖企业办公、客户关系管理、资源管理、员工管理、低代码开发等业务环节,微软已经围绕这些业务环节,推出相应的Copilot产品,对原有产品进行AI大模型赋能。从Copilot时点来看,微软首先在主力产品Office套件上线Copilot,然后逐步在企业业务与管理流程的Dynamics套件、开发相关的PowerPlatform条件、员工管理的Viva套件上线Copilot。Copilot正以“通用助手”为切入点,重塑微软生产力工具矩阵,向数据协同、功能联动的方向发展。目前办公场景Office、企业业务流程场景Dynamics下的Copilot已明确单品收费标准。微软的Copilot产品分为和家庭两大场景。
**工作场景方面:**1)面向企业办公场景推出Copilot for Microsoft 365,根据微软FY3Q24(对应日历季度1Q24)业绩会,近60%的财富100强企业正在使用。2)面向企业流程中的财务、销售和客服场景,分别推出Copilot for Finance/Sales/Service;3)面向云运营和管理场景,推出Copilot for Azure;4)面向IT安全场景,推出Copilot for Security;5)此外,微软推出Copilot Studio支持用户自定义Copilot,根据1Q24业绩会,已有3万名用户使用。
**家庭应用方面:**1)面向C端用户办公场景推出Copilot Pro;2)面向Win11和部分Win10推出Copilot for Windows,支持通过任务栏上或键盘上的Copilot按钮进行快速访问;3)在Bing搜索、Edge浏览器推出Copilot。
**谷歌将****Gemini大模型内置在其2B云端办公套件Workspace中。**谷歌将Gemini for Workspace的功能定义为:1)写作,例如生成项目计划、提案、简报等、以及优化文本;2)整理,例如通过简单描述创建项目跟踪表格;3)创建图像;4)联系,例如在视频通话中创建自定义背景,提高声音和视频质量;5)无代码创建应用。
**金山办公WPS已陆续在主要产品上线WPS AI服务。**WPSAI已经覆盖文字、演示、PDF、表格、智能文档、智能表格、智能表单等产品,涵盖了金山办公的主要产品。此外,金山办公发布了WPSAI企业版,推出AIHub(智能基座)、AIDocs(智能文档库)、CopilotPro(企业智慧助理)三大功能。
(2)编程:AI协助编程开发,提高开发效率与质量
**AI编程工具在功能上具有高度相似性,主要包括自动代码生成、代码分析与错误检测、实时编程建议。**AI工具的应用极大地提高了开发效率,自动完成编写样板代码、设置环境和调试等重复性任务,使得开发者能腾出时间进行创造性开发;实时语法与错误检查功能有助于提升代码质量,减少代码调试时间,加快开发过程。
Copilot具备强大的网络搜索和推理决策能力,能回答开发过程中的问题。比如通过自然语言描述需求,Copilot可以自动生成代码,并提供部署建议。据微软FY3Q24(对应日历季度1Q24)业绩会,GitHub Copilot付费用户数已达到180万,环比增速35%以上,收入同比增长超过45%。2024年5月微软Build大会进一步升级GitHub Copilot,包括1)更新Extensions,提升开发者的效率。开发者在编写代码之外花费了75%的时间用于追踪工作流和撰写文档。Extensions将所有流程整合在一起,可从Neovim、JetBrains IDE、VisualStudio和Visual Studio Code等多种编辑器实时工作,减少上下文切换,开发者只需专注于核心代码。2)推出Copilot Workspace,提高团队使用GitHub管理项目的效率,提供清晰的代码变动可视化界面,增强项目掌控感。3)推出Copilot connectors,便于开发者用第三方数据和应用定制Copilot,提升开发效率。例如,开发者可以用西班牙语语音要求Copilot用Java编写代码,或询问Azure资源的可用性。

(3)PC:AIPC24年下半年渗透率有望持续提升
**AIPC=边缘算力+内置大模型。**目前AIPC定义众多,芯片厂商、PC品牌厂商、第三方机构均各自有自己的定义。广义来说,处理器具有NPU提供的边缘算力能力,以及具有内置大模型,就可以称之为一款AIPC。以联想4/18推出的AIPC系列产品看,目前AIPC主流功能可以分为8类,PPT智能创作、文生图、文档总结、智能问答、AI识图、会议纪要、智会分身、设备调优,预计24年底全新一代AIPC随着处理器升级而推出后,全球AIPC渗透率有望更快提升。
**IDC预计全球PC出货总量稳定增长,AIPC渗透率持续提升,2027年或达60%。**根据IDC数据,2023年全球PC出货量约2.5亿台,AI-capable PC出货量0.25亿台,市占率约为10%;2024年全球PC出货量2.75亿台,AI-capable PC市占率约19%;预计到2027年,全球PC出货量为2.93亿台,届时AI-capable PC市占率有望达到60%。
AIPC下NPU与独立GPU方案或将长期共存。同时,AIPC推动存储规格升级,DRAM最低16GB、LPDDR占比或逐渐提高。
**硬件级的安全芯片确保隐私安全。**根据联想和IDC联合发布的《AIPC产业(中国)白皮书》,AIPC需要设备级的个人数据和隐私安全保护,除了个性化本地知识库提供本地化的个人数据安全域以及本地闭环完成隐私问题的推理之外,还可能引入硬件级的安全芯片在硬件层面确保只有经过授权的程序和操作才能读取、处理隐私数据。此外联想等厂商也同样在自研AI芯片(如联想拯救者Y7000P、Y9000P、Y9000X、Y9000K四款新品笔记本搭载的搭联想自研AI芯片——LA系列芯片),实现智能的整机功耗分配。

3、AI大模型推动具身智能技术加速迭代
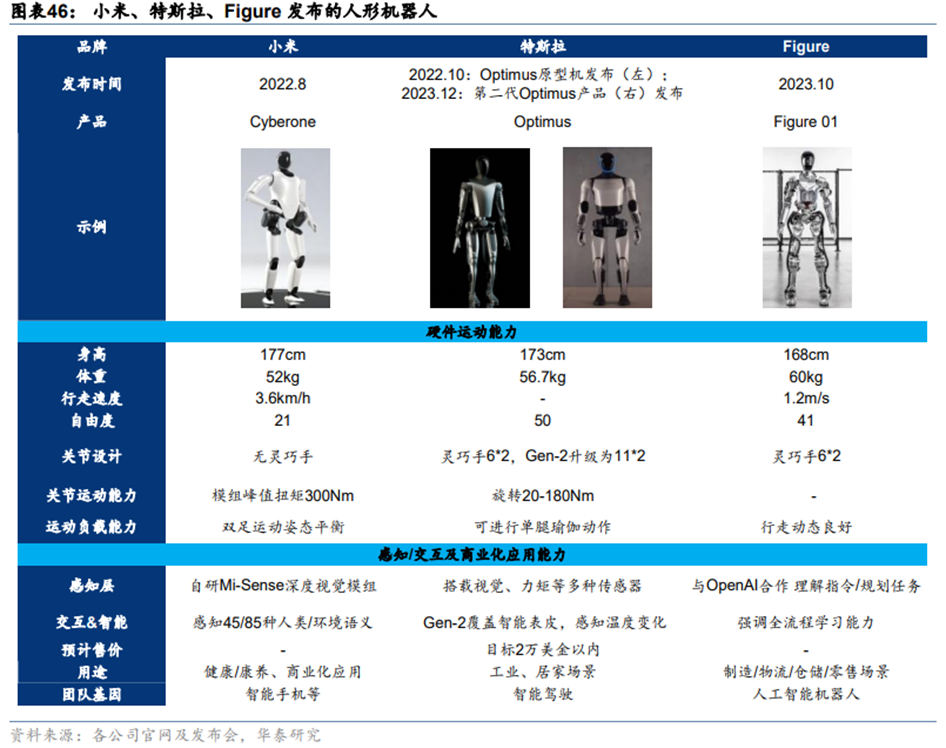
具身智能**(Embodied AI)属于人工智能领域的分支,典型应用为自动驾驶和机器人。**具身智能是泛指具有物理身体可以与外界环境进行自主交互的AI智能载体。类似于人的自主性,即通过五官(感知)、大脑(规划决策)、小脑(运动控制)完成一系列的行为,具身智能的行动一般也基于:(1)感知并理解与物理世界交互获得的信息、(2)实现自主推理决策、(3)采取相应行动进行交互。目前典型的具有较大落地场景的具身智能应用包括自动驾驶和机器人,最具代表性产品如特斯拉的FSD自动驾驶系统和Optimus人形机器人等。
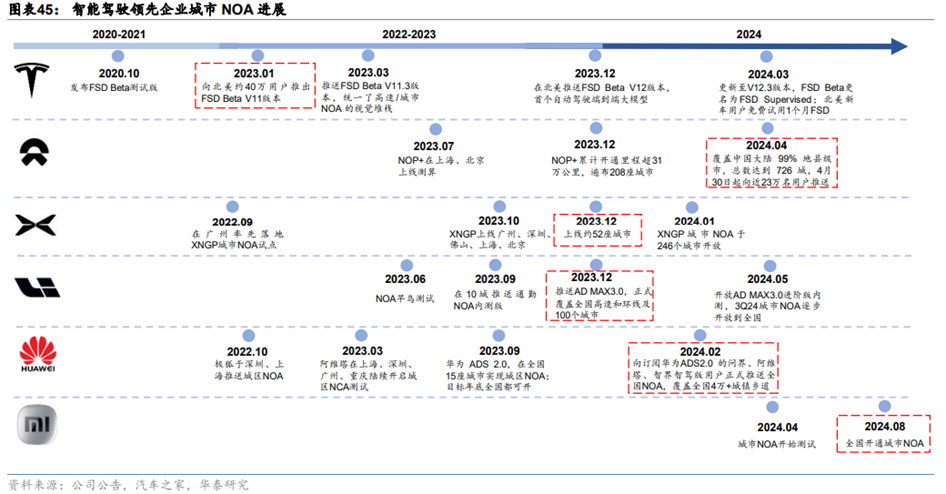
**过去一年,AI大模型助力具身智能的感知、决策等技术进展。从自动驾驶来看:受益于AI大模型发展,感知和决策层快速迭代。(1)感知层:过去传统的自动驾驶感知技术主要系“2D直视图+CNN”,核心是识别周遭的障碍物是什么及其大小和速度,效率和精度低。特斯拉2022年10月公布的Occupancy Network大模型(基于BEV+Transformer的延申),通过计算物体的空间体积占用来构建具有空间、时序的4D“实时地图”,获得更加连续、稳定的感知结果。有利于解决障碍物无法识别从而消失问题;同时地图以自车为中心坐标系构建,更好的统一了感知和预测的框架。(2)决策层:过去的决策算法基于一条条事先设定的rule-based的规则,在不同场景下触发行为准则,因此难以解决长尾瓶颈问题。特斯拉决策算法采用交互搜索模型,机器可以自主预测周围环境个体的交互轨迹,并对每一种交互带来的风险进行评估,最终分步决定采取何种策略,让车辆实现更快、更灵活、更拟人的决策行为。(3)控制层:**由于汽车的自由度较低,自动驾驶的控制算法主要依据决策模型输出指令,控制线控底盘等部件进行转向、刹车,从而操控汽车驾驶。目前特斯拉FSDV12全面转向端到端架构(一个大模型实现从感知到控制),开始推进商业落地,代码仅2000多行,全面摒弃V11版本超过30万行由工程师编写C++代码。
**从人形机器人来看:技术难度远高于自动驾驶,运动控制算法或是关键之一。(1)感知层:人形机器人的外部感知(获取外部环境信息)主要包括视/听/触觉,内部感知(获取自身状态信息)主要是对身体的状态和姿态控制。特斯拉FSD的视觉感知Occupancy Network,可以复用在机器人上,有利于加速机器人多模态感知的发展。(2)决策层:LLM/VLM/VLA等通用大模型的不断发展和扩大运用,有望帮助提升机器人的语义和视觉理解能力、问题和任务拆解和推理能力。(3)控制层:**机器人,特别是人形机器人的自由度较高,让灵巧手/机械臂完成一系列复杂的任务以及控制直立行走/跑跳等动作需要具备较强的逻辑推理能力,然而大部分运控算法仍处于发展初期,指令生成速度慢且简单,这也是机器人发展亟待突破的关键之一。特斯拉的人形机器人在2022年10月时只能实现缓慢行走与挥手,2023年12月已经可以流畅的行走与抓取鸡蛋等物品,显示出运控能力的迭代加快。

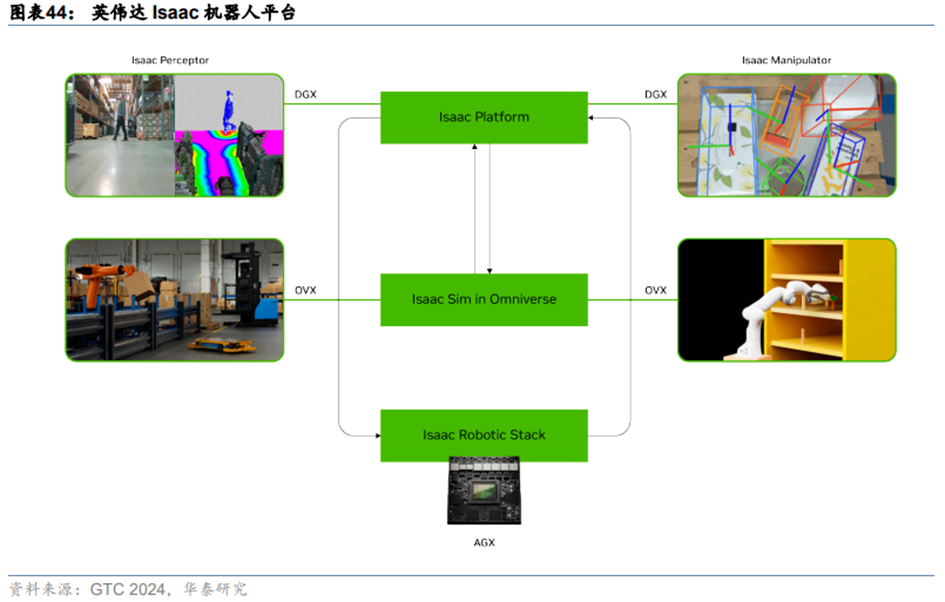
英伟达升级了Issac机器人平台,从训练、仿真、推理三方面赋能机器人行业发展。在自动驾驶方面,英伟达同样也推出了Drive平台。**1)训练平台:**用于训练机器人的基础模型。包含英伟达推出的“Project GR00T”人形机器人通用模型、以及其他主流的VLM/LLM等生成式AI通用基础模型,可以在此基础上进行感知、决策、规控等方面训练和强化学习。**2)仿真平台:**在Omniverse基础上打造了机器人仿真平台Isaac SIM。在数字孪生环境中,实现和真实环境一样的开发和测试效果,如获取真实环境中难以得到的数据,可以加快开发流程和减少开发成本。**3)端侧平台:**机器人本体的部分做了低功耗高性能的嵌入式计算平台,以及感知、决策规划等的AI算法增强的应用部署。如英伟达推出的Jetson Thor SoC片上系统开发硬件,内置了下一代Blackwell GPU(此前英伟达也推出过针对汽车的DRIVE Thor套件),带宽达到100GB/s,AI计算性能达到800TFLOPs。
**AI大模型的运用正加速高阶智能驾驶的发展,**特别是在感知端,特斯拉的FSD很好证明了AI大模型可以更大程度提升机器视觉对摄像头输入的图像信息的处理能力,完善视觉感知。而结合激光雷达的多感知融合方案,在远距离感知和探测精度上具备优势,随着激光雷达的价格快速下探到千元机水平,以及AI大模型加强算法对点云等稀疏特征数据处理能力,多感知融合长期依旧有希望成为高阶智驾的主流方案。
**机器人方面,**垂直类场景机器人如无人运送机、扫地机器人、工厂机械臂等在加速渗透,但通用型人形机器人由于其多模态感知、高精准运控、以及对泛化和涌现能力等要求高,受限于软件难度和硬件高成本压力,或尚难以在短期内实现快速降本及大规模应用。特斯拉研发的Optimus人形机器人作为行业内关注度极高的机器人产品,我们预计将首先量产应用于工厂和仓库,从事较为清晰可控的拣选搬运工作,未来才会逐渐迭代扩大应用场景。据特斯拉在2024年股东大会上的计划,到2025年将有超过1000个甚至几千个具有一定程度自主性的Optimus在特斯拉工作,未来应用规模会不断扩大。
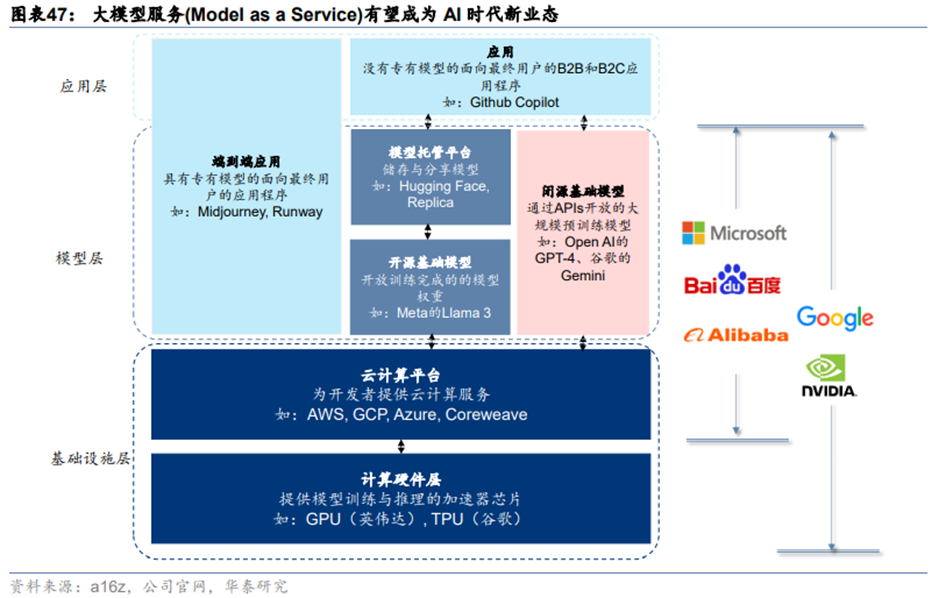
4、大模型是推动云计算发展的“锚”
**AI大模型是云计算业务的“锚”,云厂商以大模型为重要底座,推动云计算业务向MaaS转型。**目前已有多家科技巨头将大模型能力部署在云端,或以私有化部署方式提供给企业用户,以模型API调用费、模型托管服务费、按项目收费的定制化解决方案等形式获得收入。海外,微软推出了Azure OpenAI,谷歌推出了VertexAI,英伟达推出了AI Foundations;国内,阿里、百度、字节跳动、腾讯等公司均推出了基于自有云服务的MaaS模式,商汤等公司也推出了基于自有AIDC和大模型能力的MaaS服务。其中,大模型的来源包括厂商自身训练的闭源模型和开源模型,以及第三方开源模型。以微软Azure为例,用户可选择OpenAI的闭源模型,微软自己的开源模型Phi系列,以及Llama等第三方开源模型。
**AI开始拉动云计算收入增长。**以微软为例,从2Q23到1Q24的四个季度,AI分别贡献Azure及其他云服务收入增速的1%/3%/6%/7%。谷歌在4Q23、1Q24业绩会上表示,AI对谷歌云的贡献不断提升,对垂直整合的AI产品组合的需求强劲,这为谷歌云在每个产品领域创造新的机会。亚马逊在1Q24业绩会上表示,基础设施建设与AWS AI功能正在重新加速AWS的增长率。生成式AI和模型训练需求驱动,AI收入占百度AI智能云收入在4Q23/1Q24分别达到4.8%/6.9%,其中大部分收入来自模型训练,但来自模型推理的收入快速增长。
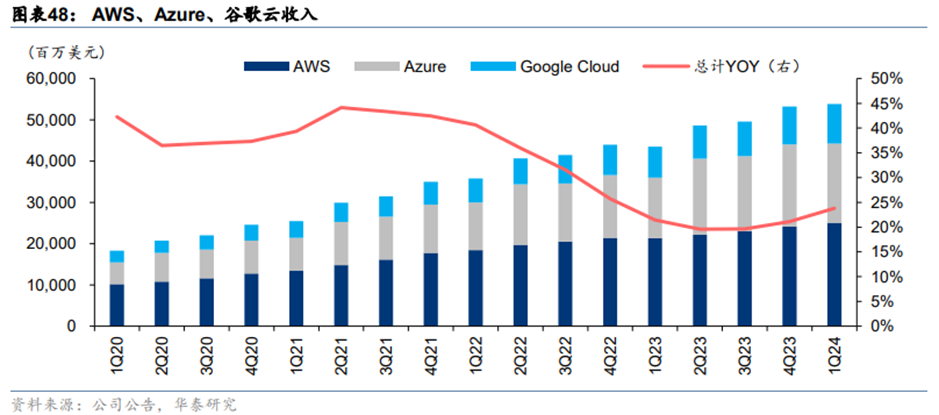
**大模型降价吸引客户上云。**2024年5月,字节、阿里云、百度、科大讯飞和腾讯相继宣布降价策略,调低面向B端市场的大模型API调用费用。大模型API降价得益于算力芯片性能的提升与推理部署的优化,其目的在于吸引客户使用公有云,购买云厂商的计算、存储、网络和安全等基础产品。
5、大模型赋能搜索和广告等互联网传统业务
搜索、广告是互联网厂商的代表性传统业务,AI大模型赋能业务效果提升。AI从算法优化广告推送机制、广告内容生成两方面助力互联网公司广告业务。微软推出Copilotin Bing,Google发布生成式搜索体验(Search Generative Experience,SGE),提供更精准、更个性、更智能的搜索结果。其中,微软Bing借力GPT模型能力,市场份额有所提升。
(1)广告:AI算法优化推送机制,生成式AI实现自动化广告制作
**AI技术通过算法优化推送机制,提高用户流量与广告转化率。**根据Meta Ads公司官网数据,推出Reels短视频后,得益于人工智能驱动的发现引擎,推送内容与用户偏好更加贴合,Instagram用户的平均使用时间增加了24%,超过40%的广告主选择投递Reels形式的广告。Google应用AI技术改进Lens视觉搜索以及图片文本跨模态多重搜索,Lens21-23年用户增长四倍,月使用数达到120亿次。
**机器学习算法匹配广告和最相关受众,提高广告转化率。**Meta Ads引入类似受众和细分定位功能,精确识别并推送广告给最有可能转化的潜在用户,从而显著降低单次增量转化费用中值达37%。同时,Google采用AI驱动的竞价系统,优化广告排序和出价策略,以促进用户进行购买意向性行为,并通过数据分析生成归因报告,为广告主推荐高效指标,以提高广告转化率和投资回报率。
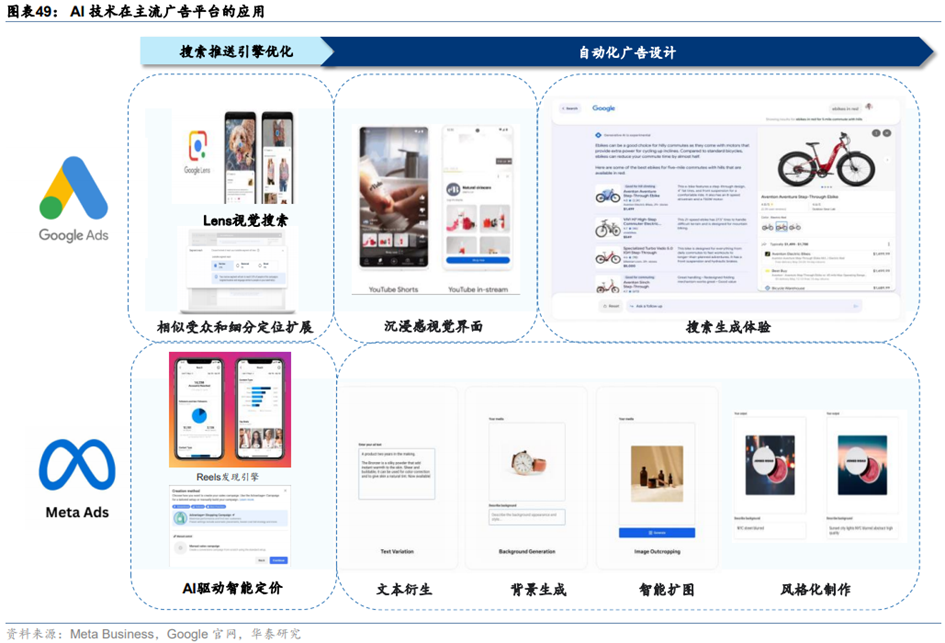
**生成式AI实现自动化广告制作,提高广告创意表现与营销效果。**1)Meta Ads推出的Advantage+Creative是一个内置的免费AI广告创作工具,它通过文本衍生、背景生成、智能扩图和风格化制作等细分功能,自动化地生成和美化广告内容。广告主仅需提供基础创意和目标受众信息,AI便能创建多个广告版本,并筛选出最可能吸引目标受众的版本。此外,AI还能对广告进行细节调整,如亮度、宽高比和文本布局,以提升广告质量。使用Advantage+Creative的广告主不仅能够提高广告支出回报率(ROAS)达32%,而且77%的广告主表示每周可以节省数小时的工作时间,从而有效降低了广告制作的成本和时间投入。2)Google运用人工智能技术,根据用户查询上下文实时优化搜索广告,并通过机器学习提升广告视觉效果。其生成式AI工具Performance Max简化了广告制作流程,自动生成文本和图片。此外,Google的自动创建素材技术(ACA)和Demand Gen广告系列进一步优化广告内容,提高视觉吸引力,有效降低广告主获取客户的成本,其中CPA中值下降了17.3%,同时广告转化次数增加了18%。
(2)搜索:引入大模型后,Bing份额提升
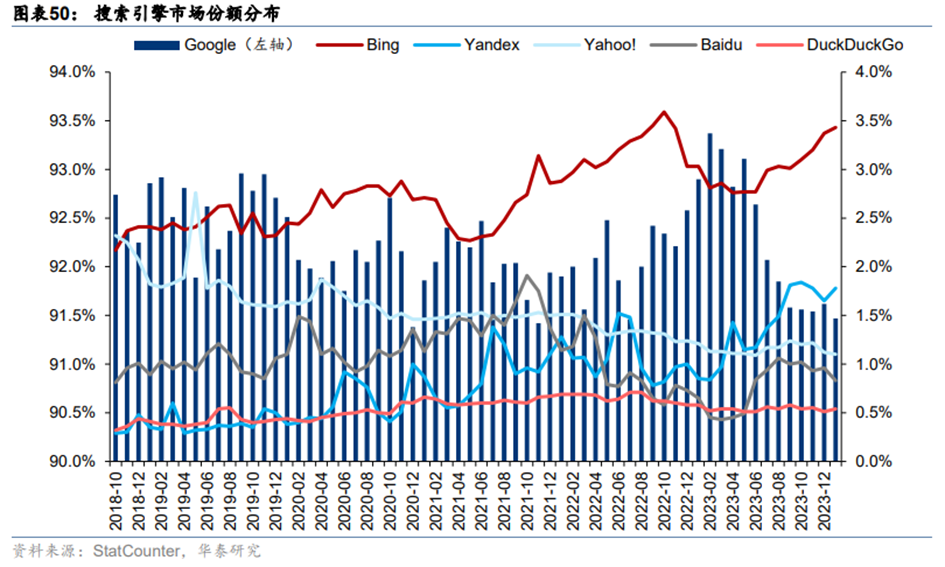
谷歌作为搜索市场的领导者,其市场份额自2015年以来在PC和移动端均超过90%。公司最初主要依赖理解式AI技术,从2001年的拼写纠正系统开始,到2019年采用BERT优化搜索排名,谷歌不断推进AI技术。如今,谷歌已发展出比BERT强大1000倍的多模态、多线程统一大语言模型MUM,以更深入地理解和组织网络内容。
**随着搜索总量的增加和用户需求的多元化,有效率、高质量的多模态交互搜索成为发展趋势。**谷歌为应对搜索总量增长和用户需求多样化,于2023年启动了搜索生成式体验(SGE)实验,依托生成式AI大模型Gemini,自动创建搜索内容摘要并提供垂直领域推荐。AI Overviews作为SGE的进阶版本,在2024年Google I/O大会上作为25年来最大更新推出,与谷歌核心搜索系统集成,确保结果准确性。尽管AI Overviews继承了SGE的多功能特性,包括视频搜索和多步骤问题解决,但在推出两周后遭遇质疑,谷歌进行了一些改进。然而,根据BrightEdge的调查,AI Overviews在搜索结果中的使用频率已从最初的84%降至约15%。
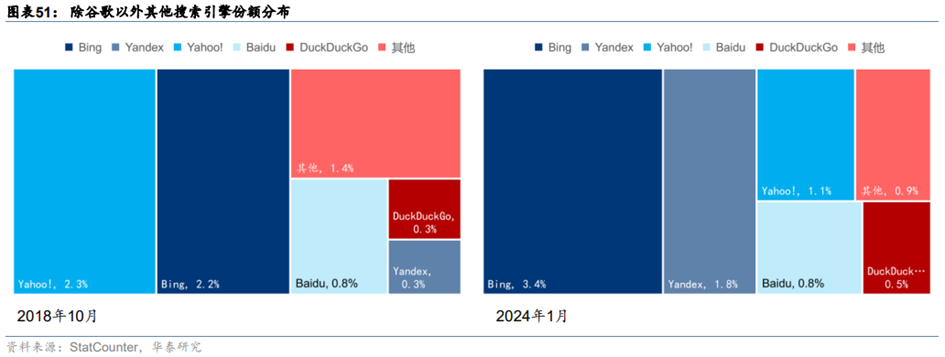
**微软Bing引入GPT模型能力开启生成式Web搜索新体验,市场份额提升。**微软为Bing搜索引擎引入了基于GPT模型的AI增强型搜索助手NewBing,后升级为Copilot,该助手通过提供生成式Web搜索体验,帮助Bing的市场份额从2023年2月的2.8%提升至2024年1月的3.4%,并且在新推出的四个月内日活用户超过1亿,其中三分之一为新用户。Copilot的推出使得Bing的搜索流量大幅增长,累计支持了50亿次搜索对话,推动了微软FY2Q24季度搜索与广告收入的同比增长近10%。
**Perplexity AI,一家在2022年8月成立的新兴独角兽公司,致力于开发结合对话和链接功能的自然语言搜索引擎。**截至2024年1月,该平台的月活跃用户已超过1000万,且在短短两个月内公司估值翻倍,达到10亿美元。Perplexity AI的产品利用包括GPT-4o、Claude-3等在内的第三方大型模型,并通过检索增强生成技术(RAG)连接外部知识库,以提高搜索结果的准确性。该搜索引擎能够理解自然语言,支持聊天对话搜索、智能文档管理和文本生成,并能进行多轮对话和预测后续问题。Perplexity AI为免费用户提供无限次快速搜索和有限的5次专业搜索,而Pro订阅用户支付20美元/月或200美元/年的费用后,每日可使用300次专业搜索。
06
国内外大模型
1、海外:微软OpenAI与谷歌领先,Meta选择开源的防御性策略
微软和OpenAI是目前大模型技术水平、产品化落地最为前沿的领军者,其对颠覆式创新的持续投入是当前领先的深层原因。谷歌技术储备丰厚,自有业务生态广阔并且是AI落地的潜在场景,过去由于管理松散未形成合力,谷歌从2023年开始整合Google Brain和Deepmind,目前正在产品化、生态化加速追赶。Meta选择模型开源的防御性策略,以应对OpenAI、谷歌等竞争对手的强势闭源模型。
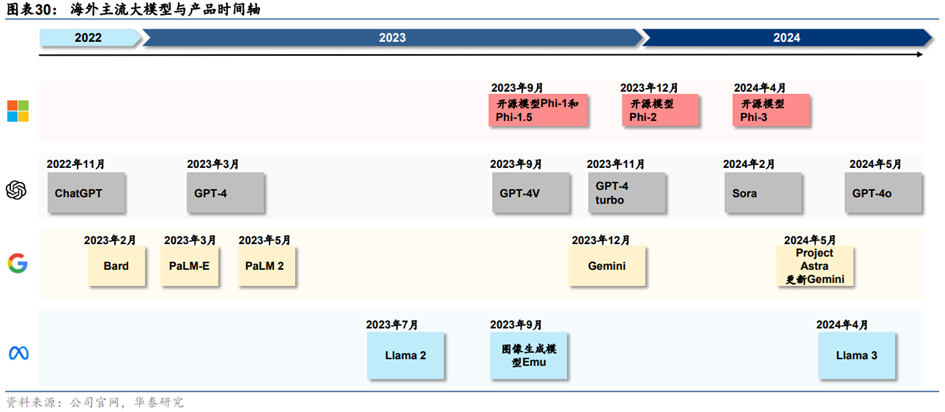
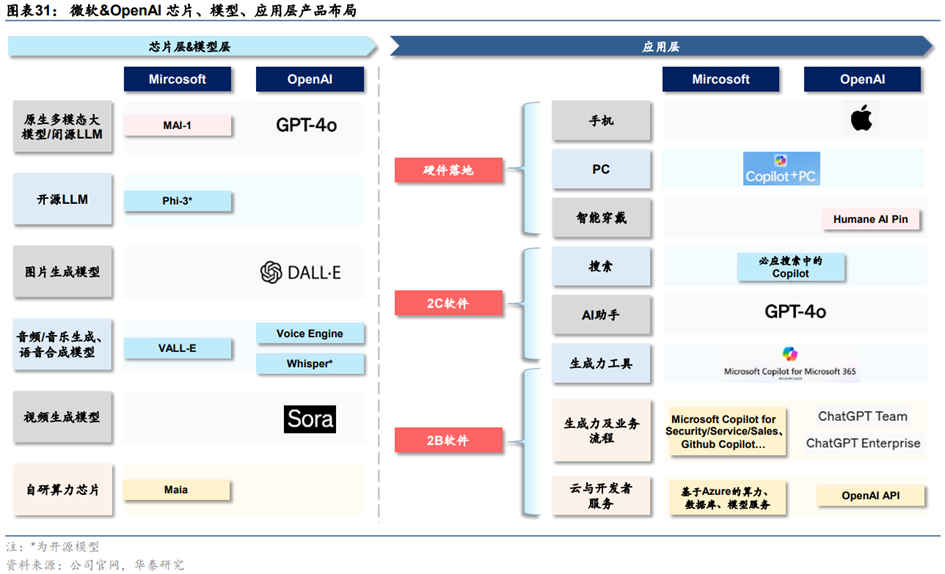
(1)微软OpenAI:闭源模型全球领先,大模型产品化处于前沿
**OpenAI最前沿模型GPT系列持续迭代。**2022年11月,OpenAI推出的基于GPT-3.5的ChatGPT开启了AI大模型热潮。此后,OpenAI持续迭代GPT系列模型:1)2023年3月发布GPT-4,相比GPT-3.5仅支持文字/代码的输入输出,GPT-4支持输入图像并且能够真正理解;2)2023年9月发布GPT-4V,升级了语音交互、图像读取和理解等多模态功能;3)2023年10月将DALL・E3与ChatGPT结合,支持文生图功能;4)2023年11月发布GPT-4 Turbo,相比GPT-4性能提升,成本降低,支持128ktokens上下文窗口(GPT-4最多仅为32k);5)2024年5月发布其首个端到端多模态模型GPT-4o,在文本、推理和编码智能方面实现了GPT-4 Turbo级别的性能,同时在多语言、音频和视觉功能上性能更优。GPT-4o的价格是GPT-4 Turbo的一半,但速度是其2倍。得益于端到端多模态模型架构,GPT-4o时延大幅降低,人机交互体验感显著增强。
**OpenAI多模态模型布局完整。**在多模态模型方面,除了文生图模型DALL・E3,OpenAI在2024年2月推出了文生视频模型Sora,Sora支持通过文字或者图片生成长达60秒的视频,远超此前Runway(18秒)、Pika(起步3秒+增加4秒)、Stable Video Diffusion(4秒)等AI视频应用生成时长,此外还支持在时间上向前或向后扩展视频,以及视频编辑。
**微软Phi系列小模型面向开源,将自研MAI系列大模型。**微软自研小模型为客户提供更多选择,2023年发布Phi-1.0(1.3B)、Phi-1.5(1.3B)、Phi-2模型(2.7B),2024年开源了Phi-3系列,包括3款语言模型——Phi-3-mini(3.8B)、Phi-3-small(7B)和Phi-3-medium(14B),以及一款多模态模型Phi-3-vision(4.2B)。此外,据Theinformation2024年5月报道,微软将推出一款参数达5000亿的大模型,内部称为MAI-1,由前谷歌AI负责人、Inflection CEO Mustafa Suleyman负责监督。
**产品化方面,微软与OpenAI将大模型能力对原有的软件产品、云计算业务、智能硬件进行全面升级。**1)微软围绕企业办公、客户关系管理、资源管理、员工管理、低代码开发等业务环节具有完整的产品矩阵,2023年以来推出相应的Copilot产品对原有产品进行AI大模型赋能,其中产品化最早、最为核心的是面向企业办公场景的Copilotfor Microsoft 365,以及面向C端用户的Copilot for Windows,以及集成在Bing搜索、Edge浏览器的Copilot。2)云计算业务方面,Azure云业务向MaaS服务发展,提供算力、模型、数据工具、开发工具等服务。3)智能硬件方面,微软在2024年5月发布GPT-4o加持的Copilot+PC,除微软Surface以外,联想、戴尔、惠普、宏碁、华硕等PC厂商也将发布Copilot+PC新品。
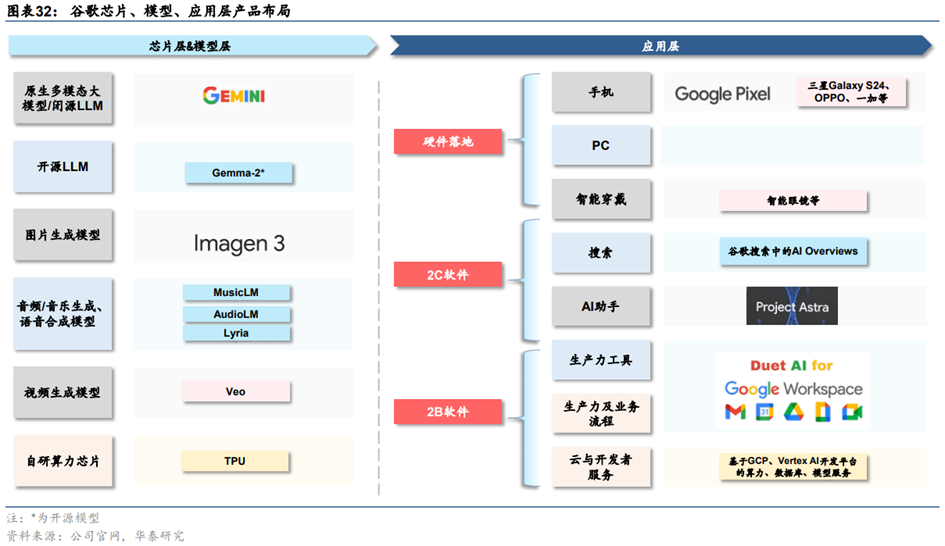
(2)谷歌:闭源模型全球领先,自有业务生态及AI潜在落地空间广阔
**谷歌最****前沿的闭源模型从PaLM系列切换到Gemini。**2022-2023年,PaLM系列模型是谷歌的主力模型,2022年4月发布的PaLM、2022年10月发布的Flan PaLM以及2023年5月I/O大会发布的PaLM-2都是谷歌当时的主力大模型。2023年12月,谷歌发布全球首个原生多模态模型Gemini,包含Ultra、Pro和Nano三种不同大小。根据Gemini Technical Report,Ultra版在绝大部分测试中优于GPT-4。2024年2月,谷歌发布Gemini 1.5 Pro,性能更强,并且拥有突破性的达100万个Tokens的长上下文窗口。
2024年5月I/O大会上,谷歌对Gemini再次更新:1)发布1.5Flash,是通过API提供的速度最快的Gemini模型。在具备突破性的长文本能力的情况下,它针对大规模地处理高容量、高频次任务进行了优化,部署起来更具性价比。1.5Flash在总结摘要、聊天应用、图像和视频字幕生成以及从长文档和表格中提取数据等方面表现出色。2)更新1.5Pro。除了将模型的上下文窗口扩展到支持200万个tokens之外,1.5Pro的代码生成、逻辑推理与规划、多轮对话以及音频和图像理解能力进一步提升。
**产品化方面,谷歌将大模型能力融入自有软件业务、云计算和智能硬件之中。**1)自有软件业务:谷歌在2023年5月I/O大会上宣布将PaLM2应用在超过25种功能和产品中,包括2B办公套件Workspace、聊天机器人Bard等等。随着谷歌主力大模型切换到Gemini,Workspace和Bard背后的大模型也同步切换。2)云计算:谷歌通过Vertex AI和Google AI Studio向MaaS延伸。VertexAI是AI开发和运营(AI Ops)平台,支持组织开发、部署和管理AI模型。Google AI Studio是基于网络的工具,可以直接在浏览器中设计原型、运行提示并开始使用API。3)智能硬件:2024年下半年,据Techweb,谷歌有望在10月推出Pixel9系列,预计将搭载基于最新Gemini模型的AI助手,执行复杂的多模态任务。
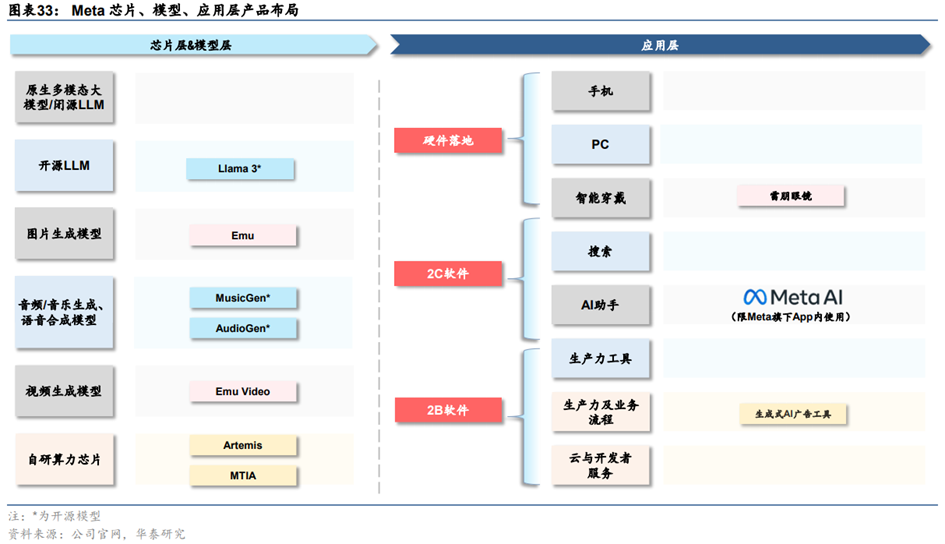
(3)Meta:Llama开源模型领先
**Meta凭借Llama系列开源模型在大模型竞争中独树一帜,目前已发布三代模型。**Meta在2023年2月、7月分别推出Llama与Llama2。Llama2,提供7B、13B、70B三种参数规模,70B在语言理解、数学推理上的得分接近于GPT-3.5,在几乎所有基准上的任务性能都与PaLM540B持平或表现更好。2024年4月,Meta发布Llama3,Llama3性能大幅超越前代Llama2,在同等级模型中效果最优。本次开源参数量为8B和70B的两个版本,未来数个月内还会推出其他版本,升级点包括多模态、多语言能力、更长的上下文窗口和更强的整体功能。最大的400B模型仍在训练过程中,设计目标是多模态、多语言,根据Meta公布的目前训练数据,其性能与GPT-4相当。
**Meta基于LLama系列模型打造智能助手MetaAI、雷朋Meta智能眼镜等硬件产品。**Meta同时更新基于Llama3构建的智能助手MetaAI,无需切换即可在Instagram、Facebook、WhatsApp和Messenger的搜索框中畅通使用MetaAI。Llama3很快将在AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM和Snowflake上推出,并得到AMD、AWS、戴尔、英特尔、英伟达、高通提供的硬件平台的支持。此外,雷朋Meta智能眼镜也将支持多模态的MetaAI。
2、国内:格局清晰,闭源追赶GPT-4,开源具备全球竞争力
复盘过去一年国内基础大模型训练企业在大模型技术、产品化和商业化上的进展:
**1)国内闭源大模型持续追赶OpenAI:**23年中到23年底的国内主流大模型对标GPT-3.5,23年开始对标GPT-4。例如2023年10月更新的文心4.0(Ernie4.0)“综合水平与GPT4相比已经毫不逊色”,2024年1月更新的智谱GLM-4整体性能“逼近GPT-4”,2024年4月更新的商汤日日新5.0“综合性能全面对标GPT-4 Turbo”。
**2)国内竞争格局逐渐清晰,阵营可分为互联网头部企业、上一轮AI四小龙、创业企业。**互联网头部企业中,目前百度与阿里在模型迭代与产品化上领先,字节跳动拥有领先的2C大模型应用豆包,但公开的大模型公司信息较少,腾讯的大模型迭代与产品化稍显落后。商汤是上一代“AI四小龙”公司中唯一在本轮AI2.0浪潮中未曾掉队、持续创新领先的企业。创业公司中布局各有特色:智谱布局完整,开源、闭源模型兼具,2C/2B并重;月之暗面专注2C闭源,以长文本作为差异化竞争点;Minimax选择MoE模型,以2C社交产品切入;百川智能开源、闭源兼具,2B为主;零一万物从开源模型切入,目前开源和闭源模型兼具。
**3)国内开源模型具备全球竞争力。**以阿里Qwen系列、百川智能Baichuan系列、零一万物的Yi系列为代表的国内开源模型成为推动全球开源模型进步的重要力量。
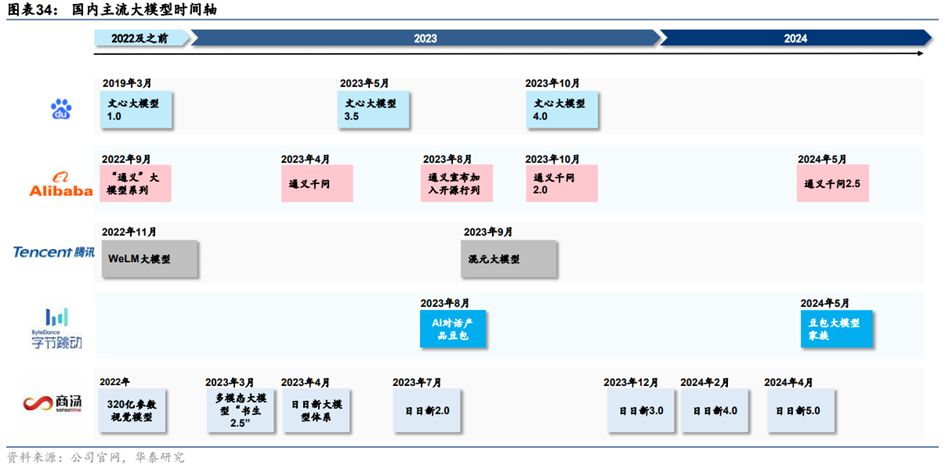
(1)百度:文心大模型持续迭代,B/C端商业化稳步推进
**文心4.0综合能力“与GPT-4相比毫不逊色”。**继2023年3月发布知识增强大语言模型文心一言后,百度在2023年5月发布文心大模型3.5,2023年10月发布文心大模型4.0。相比3.5版本,4.0版本的理解、生成、逻辑、记忆四大能力都有显著提升:其中理解和生成能力的提升幅度相近,而逻辑的提升幅度达到理解的近3倍,记忆的提升幅度达到理解的2倍多。文生图功能方面,文心4.0支持多风格图片生成,一文生多图,图片清晰度提升。据百度创始人、董事长兼CEO李彦宏在百度世界2023上介绍,文心大模型4.0综合能力“与GPT-4相比毫不逊色”。
**AI重构百度移动生态。**百度搜索、地图、网盘、文库等移动生态应用以AI重构。1)搜索:大模型重构的新搜索具有极致满足、推荐激发和多轮交互三个特点。2)地图:通过自然语言交互和多轮对话,升级为智能出行向导,提升用户出行和决策效率。3)百度网盘与文库:AI增加创作能力。网盘可以精准定位视频的特定帧,并总结长视频内容,提取关键信息和亮点。文库利用其庞大的资料库,辅助用户进行写作和制作PPT,成为生产力工具。4)百度GBI:用AI原生思维打造的国内第一个生成式商业智能产品。通过自然语言交互,执行数据查询与分析任务,同时支持专业知识注入,满足更复杂、专业的分析需求。
百度B/C端商业化稳步推进。根据李彦宏2024年4月在Create2024百度AI开发者大会上的演讲,文心一言用户数已经突破2亿,API日均调用量也突破2亿,服务的客户数达到8.5万,利用千帆平台开发的AI原生应用数超过19万。
**C端商业化:**2023年10月推出文心一言4.0后,百度开启收费计划,开通会员后可使用文心大模型4.0,非会员则使用3.5版本。会员单月购买价格为59.9元/月,连续包月价格为49.9元/月,文心一言+文心一格联合会员价格为99元/月。文心一言会员可享受文心大模型4.0、文生图能力全面升级、网页端高阶插件、App端单月赠送600灵感值等权益,文心一格会员可享受极速生成多尺寸高清图像、创作海报和艺术字、AI编辑改图修图等权益。
**B端落地:**三星Galaxy S24 5G系列、荣耀Magic8.0均集成了文心API,汽车之家使用文心API支持其AIGC应用程序。根据百度4Q23业绩会,百度通过广告技术改进和帮助企业构建个性化模型,在4Q23已经实现数亿元人民币的收入,百度预计2024年来自AI大模型的增量收入将增长至数十亿元人民币,主要来源包括广告和人工智能云业务。
(2)阿里巴巴:通义大模型开源闭源兼具,落地行业广泛
**通义千问****2.5中文性能追平GPT-4 Turbo。**通义千问自2023年4月问世以来,2023年10月发布性能超越GPT-3.5的通义千问2.0,2024年5月发布通义千问2.5。在中文语境下,2.5版文本理解、文本生成、知识问答&生活建议、闲聊&对话,以及安全风险等多项能力上赶超GPT-4。
**通义践行“全模态、全尺寸”开源。**2023年8月,通义宣布加入开源行列,已陆续推出十多款开源模型。根据阿里云公众号,截至2024年5月,通义开源模型下载量已经超过700万。大语言模型方面,通义开源了参数规模横跨5亿到1100亿的八款模型:小尺寸模型参数量涵盖0.5B、1.8B、4B、7B、14B,可便捷地在手机、PC等端侧设备部署;大尺寸模型如72B、110B能够支持企业级和科研级的应用;中等尺寸模型如32B则在性能、效率和内存占用之间找到最具性价比的平衡点。此外,通义还开源了视觉理解模型Qwen-VL、音频理解模型Qwen-Audio、代码模型CodeQwen1.5-7B、混合专家模型Qwen1.5-MoE。
面向B端客户,通义通过阿里云服务企业超过9万,与诸多行业头部客户达成合作。根据阿里云公众号,截至2024年5月,通义通过阿里云服务企业超过9万、通过钉钉服务企业超过220万,现已落地PC、手机、汽车、航空、天文、矿业、教育、医疗、餐饮、游戏、文旅等领域。
面向C端用户,通义千问APP升级为通义APP,集成文生图、智能编码、文档解析、音视频理解、视觉生成等全栈能力,打造用户的全能AI助手。
(3)腾讯:混元大模型赋能自身业务生态实现智能化升级
**混元已经接入腾讯多个核心产品和业务,赋能业务降本增效。**2023年9月,腾讯上线混元大模型。混元已升级为万亿级别参数的MOE架构模型。截至2023年9月,包括腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器在内的超过50个核心业务和产品接入混元大模型;2023年10月超过180个内部业务接入混元;2024年4月,腾讯所有协作SaaS产品超过400个应用全面接入混元,包括企业微信、腾讯会议、腾讯文档、腾讯乐享、腾讯云AI代码助手、腾讯电子签、腾讯问卷等等。
(4)字节跳动:豆包大模型赋能内部业务,对话助手“豆包”用户数量居前
**字节跳动在2023年并未对外官宣其大模型,在2024年5月火山引擎原动力大会上首次公开发布。**字节豆包大模型家族涵盖9个模型,主要包括通用模型pro、通用模型lite、语音识别模型、语音合成模型、文生图模型等等。字节跳动并未说明模型参数量、数据和语料,而是直接针对应用场景进行垂直细分。豆包大模型在2023年完成自研,已接入字节内部50余个业务,包括抖音、飞书等,日均处理1200亿Tokens文本,生成3000万张图片。
2C产品方面,字节跳动基于豆包大模型打造了AI对话助手“豆包”、AI应用开发平台“扣子”、互动娱乐应用“猫箱”以及AI创作工具星绘、即梦等。
2B方面,火山引擎也与智能终端、汽车、金融、消费等行业的众多企业已经展开了合作,包括OPPO、vivo、小米、荣耀、三星、华硕、招行、捷途、吉利、北汽、智己、广汽、东风本田、海底捞、飞鹤等。
(5)商汤:“云、边、端”全栈大模型,5.0版本对标GPT-4 Turbo
**商汤日日新5.0综合性能对标GPT-4 Turbo。**2023年4月,商汤正式发布“日日新SenseNova”大模型体系,实现CV、NLP、多模态等大模型的全面布局。2024年4月,商汤日日新SenseNova升级至5.0版本,具备更强的知识、数学、推理及代码能力,综合性能全面对标GPT-4 Turbo。日日新5.0能力提升主要得益三个方面:1)采用MoE架构,激活少量参数就能完成推理。且推理时上下文窗口达到200K左右。2)基于超过10TBtokens训练、覆盖数千亿量级的逻辑型合成思维链数据。3)商汤AI大装置SenseCore算力设施与算法设计的联合调优。
**商汤推出“云、边、端”全栈大模型产品矩阵。**1)云端模型即商汤最领先的基础模型系列。2)在边缘侧,商汤面向金融、医疗、政务、代码四个行业推出商汤企业级大模型一体机。一体机同时支持千亿模型加速和知识检索硬件加速,实现本地化部署,相比行业同类产品,千亿大模型推理成本可节约80%;检索大大加速,CPU工作负载减少50%,端到端延迟减少1.5秒。3)端侧模型方面,SenseChat-Lite1.8B全面领先所有开源2B同级别模型,甚至在大部分测试中跨级击败了Llama2-7B、13B模型。日日新5.0端侧大模型可在中端性能手机上达到18.3字/秒的推理速度,在高端旗舰手机上达到78.3字/秒,高于人眼20字/秒的阅读速度。
(6)智谱AI(未上市):模型布局对标OpenA
**智谱最新基座大模型GLM-4整体性能相比GLM-3提升60%,逼近GPT-4。**2024年1月,智谱发布新一代基座大模型GLM-4,1)基础能力(英文):在MMLU、GSM8K、MATH、BBH、HellaSwag、HumanEval等数据集上,分别达到GPT-494%、95%、91%、99%、90%、100%的水平。2)指令跟随能力:在IFEval的prompt级别上中、英分别达到GPT-4的88%、85%的水平,在Instruction级别上中、英分别达到GPT-4的90%、89%的水平。3)中文对齐能力:整体超过GPT-4。4)长文本能力:在LongBench(128K)测试集上对多个模型进行评测,GLM-4性能超过GPT-4、Claude2.1。5)文生图:CogView3在文生图多个评测指标上,相比DALLE3约在91.4%~99.3%的水平之间。
多模态模型方面,智谱已拥有CogView文生图模型。据钛媒体AGI5月6日报道,智谱正在研发对标Sora的高质量文生视频模型,预计最快年内发布。
**智谱开源多个模型版本,2023年获HuggingFace全球最受欢迎的开源机构第五名,超过OpenAI、Google、微软,也是唯一上榜的中国机构。**高精度双语千亿模型GLM-130B于2022年8月发布并开源,模型的部分模型性能优于GPT-3。类ChatGPT对话模型ChatGLM-6B于2023年3月开源发布,可在消费级显卡上进行本地部署。2023年5月,智谱AI和清华大学KEG实验室开源了支持图像、中文和英文的多模态对话模型VisualGLM-6B,语言模型基于ChatGLM-6B;图像部分通过训练BLIP2-Qformer构建起视觉模型与语言模型的桥梁,用户最低只需8.7G的显存就可以进行本地部署。
**应用:2B合作多家企业深度共创,2C构建AGIC产品矩阵。**2B:据2024年3月14日智谱发布会上介绍,截至2023年底,智谱AI已拥有超2000家生态合作伙伴、超1000个大模型规模化应用,另有200多家企业跟智谱AI进行了深度共创,覆盖传媒、咨询、消费、金融、新能源、互联网、智能办公等多个细分场景的多个头部企业。
2C:智谱已构建了AIGC模型产品矩阵,包括AI提效助手智谱清言ChatGLM、高效率代码模型CodeGeeX、写作助手写作蛙、对话产品小呆对话和文生图模型CogView等。
(7)月之暗面(未上市):专注2C闭源,以长文本作为差异化竞争点
月之暗面(MoonshotAI)成立于2023年3月,核心产品是2C对话智能助手Kimi。基础大模型层面,月之暗面训练了千亿级别的通用大模型moonshot。应用层,2023年10月,月之暗面推出全球首个支持输入20万汉字的智能助手产品Kimi,主打无损记忆以及“长文本(LongContext)”,善于读长文、搜网页,可以用于会议纪要、辅助编程、文案写作等场景。2024年3月18日,月之暗面宣布KimiChat在长文本处理能力上取得了重大突破,没有采用常规的渐进式提升路线,无损上下文输入长度跃升至200万字。根据MoonshotAI公众号介绍,公司研发和技术团队从模型预训练到对齐、推理环节均进行了原生的重新设计和开发,不走“滑动窗口”、“降采样”等技术捷径,攻克了很多底层技术难点。据钛媒体3月18日报道,Kimi预计在2024年上半年开启商业化;联合创始人周昕宇同时表示,预计2024年会推出多模态模型及产品。
**月之暗面重视大模型无损上下文长度,创始人认为长文本是新的计算机内存。**创始人杨植麟认为,上下文长度就是大模型的内存,它是决定大模型应用最关键的两个因素(参数量和上下文)之一;个性化过程不是通过微调实现,而是通过支持人机互动历史的长上下文来实现的。上下文数量级的提升,能够进一步打开对AI应用场景的想象力,包括完整代码库的分析理解、可以自主帮人类完成多步骤复杂任务的智能体Agent、不会遗忘关键信息的终身助理、真正统一架构的多模态模型等等。
2024年5月,Kimi推出应用商店Kimi+,上线官方推荐、办公提效、辅助写作、社交娱乐、生活实用5大类,共23个Kimi+,类似OpenI的GPTs、字节跳动的Coze、百度文心一言的智能体平台、通义千问的“百宝袋”等。
07
发展趋势展望
1、数据将成为模型规模继续扩大的瓶颈,合成数据或是关键
**Epoch预测,未来训练数据的缺乏将可能减缓机器学习模型的规模扩展。**据Epoch预测,2030年到2050年,将耗尽低质量语言数据的库存;到2026年,将耗尽高质量语言数据的库存;2030年到2060年,将耗尽视觉数据的库存。由于大参数模型对数据量需求的增长,到2040年,由于缺乏训练数据,机器学习模型的扩展大约有20%的可能性将显着减慢。值得注意的是,以上结论的前提假设是,机器学习数据使用和生产的当前趋势将持续下去,并且数据效率不会有重大创新(这个前提未来可能被新合成技术打破)。
**合成数据是解决数据缺乏的重要途径,但目前相关技术仍需要持续改进。**理论上,数据缺乏可以通过合成数据来解决,即AI模型自己生成训练数据,例如可以使用一个LLM生成的文本来训练另一个LLM。在Anthropic的Claude3技术报告中,已经明确提出在训练数据中使用了内部生成的数据。但是目前为止,使用合成数据来训练生成性人工智能系统的可行性和有效性仍有待研究,有结果表明合成数据上的训练模型存在局限性。例如Alemohammad发现在生成式图像模型中,如果在仅有合成数据或者真实人类数据不足的情况下,将出现输出图像质量的显著下降,即模型自噬障碍(MAD)。能够认为,合成数据是解决高质量训练数据短缺的重要方向,随着技术演进,目前面临的合成数据效果边际递减问题或逐步解决。
2、开源与闭源模型未来将形成互相博弈和竞争格局,AI初创企业面临生存挑战
未来,大模型开源将成为趋势,一方面能降低大模型开发者的使用门槛,另一方面也能提高算法的透明度和可信度。开源模式的任何渐进式改进都在蚕食闭源模型的市场份额,未来两者或在相当长一段时间内形成互相博弈和竞争的格局。
此外,面对性能优异及其快速增多的衍生开源模型,部分AI初创企业可能正在失去存在的意义,市场内自研模型的公司数量或将快速收敛,除了科技巨头外,只有少数具备先发优势的AI初创企业能够在激烈的竞争中生存下来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

?学会后的收获:?
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
?获取方式:
?有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】?
