目录
一、string模拟实现
1.1构造析构
1.2迭代器
1.3修改
1.4查找
1.5substr 深浅拷贝的区别
1.6比较函数与流插入流提取
二、string类的拷贝
2.1浅拷贝与深拷贝
2.2传统版与现代版区别
2.3写时拷贝(了解)
三、vs和g++下string结构的说明
3.1vs下的string结构
3.2g++下的string结构
一、string模拟实现
想要模拟实现自己的string类,主要的是构造、拷贝构造、迭代器、修改、查找等功能。
实现一个简单的string 不考虑模板等一些复杂的优化结构
namespace xc{class string{public:private:char* _str;size_t _size;size_t _capacity;};}1.1构造析构
简单的构造函数:
class string{public:string():_str(nullptr),_size(0),_capacity(0){}string(const char*str){_size = strlen(str);_capacity = _size;//定义的容量就是有效数据个数 new的话需要考虑 \0_str = new char[_capacity + 1];strcpy(_str, str);}const char* c_str()//暂时没有写流提取,流插入所以转换为 _str打印{return _str;}private:char* _str;size_t _size;size_t _capacity;};
程序崩溃,无法打印,原因是 string的无参构造 _str 初始化为 nullptr,转换为字符串打印时候会解引用知道遇到\0终止 但是这里对空指针进行了解引用 所以程序崩溃
优化合并一下:
class string{public:/*string():_str(new char[1]{""}),_size(0),_capacity(0){}*/string(const char*str=""){_size = strlen(str);_capacity = _size;//定义的容量就是有效数据个数 new的话需要考虑 \0_str = new char[_capacity + 1];strcpy(_str, str);}~string(){delete[]_str;_str = nullptr;_size = _capacity = 0;}const char* c_str()//暂时没有写流提取,流插入所以转换为 _str打印{return _str;}private:char* _str;size_t _size;size_t _capacity;};一些频繁调用的短小函数可以直接在类里面定义实现 默认为 内联inline
const char* c_str()const //暂时没有写流提取,流插入所以转换为 _str打印{return _str;}size_t size()const{return _size;}size_t capacity()const{return _capacity;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos)const{assert(pos < _size);return _str[pos];}1.2迭代器
实现基本的迭代器(正向迭代器和const正向迭代器)功能以支持 范围for,迭代器遍历
public:typedef char* iterator;typedef char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin()const{return _str;}const_iterator end()const{return _str + _size;}
1.3修改
声明定义分离的模式,可能涉及扩容可以先处理一个 reserve 函数
//.hvoid reserve(size_t n);void push_back(char ch);void append(const char*str);string& operator+=(char ch);string& operator+=(const char*str);//.cppvoid string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);//拷贝内容delete[]_str;_str = tmp;//交换指针_capacity = n;}}void string::push_back(char ch){if (_capacity == _size){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = ch;}string& string::operator+=(char ch){push_back(ch);return *this;}
显然是因为没有\0终止符才出现了乱码
void string::push_back(char ch){if (_capacity == _size){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = ch;_str[_size] = '\0';}
接下来实现字符串的插入
void string::append(const char* str)//加的字符串可能需要扩容 需要if判断{size_t len = strlen(str);if (_size + len > _capacity){//大于2倍 就需要多少开多少 少于2倍就开2倍空间reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);}strcpy(_str + _size, str); //第一个参数为\0地址_size += len;}string& string::operator+=(const char* str){append(str);return *this;}
指定位置的插入删除
void insert(size_t pos, char ch);void insert(size_t pos, const char*str);void erase(size_t pos, size_t len=npos);private:char* _str;size_t _size;size_t _capacity;static const size_t npos;增加了一个新成员变量 npos 该静态成员变量需要声明定义分离
void string::insert(size_t pos, char ch){assert(pos <= _size);if (_capacity == _size){reserve(_capacity == 0 ? 4 : _capacity * 2);}移动数据 需要单独处理\0//for (int i = _size-1; i >=(int)pos; i--)//{//_str[i+1] = _str[i];//}//_str[pos] = ch;//_str[++_size] = '\0';//直接将 \0 也视为字符 移动开来for (int i = _size; i >= pos; i--){_str[i + 1] = _str[i];}_str[pos] = ch;++_size;}
程序崩溃?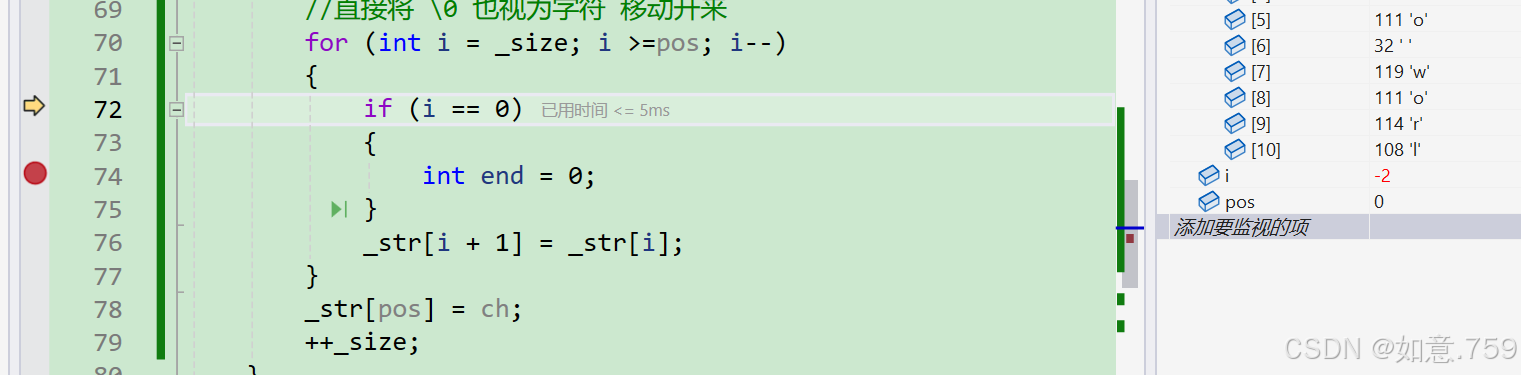
可以看到 i 小于0仍然进入循环,补充当 两个数据类型不同进行比较等操作时 范围小的会向范围大的进行整形提升 在这里 i 变为了无符号整数 解决办法 将 pos进行强制转换为 int 即可
void string::insert(size_t pos, char ch){assert(pos <= _size);if (_capacity == _size){reserve(_capacity == 0 ? 4 : _capacity * 2);}直接将 \0 也视为字符 移动开来//for (int i = _size; i >=(int)pos; i--)//{//_str[i + 1] = _str[i];//}//_str[pos] = ch;//++_size;for (int i = _size + 1; i > pos; i--){_str[i] = _str[i - 1];}_str[pos] = ch;++_size;}//可以对比插入一个字符的逻辑 只是 len值为1的特殊情况 画图理解 临界条件void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);}for (int i = _size + len; i > len+pos-1; i--){_str[i] = _str[i - len];}for (int i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;}void string::erase(size_t pos, size_t len){assert(pos < _size);//pos等于 _size 那么会删掉\0//判断 len大于剩余的所有 就直接修改 \0的位置if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{for (int i = pos + len; i <= _size; i++){_str[i - len] = _str[i];}_size -= len;}}Tip:插入多个数据可以类比插入一个数据的逻辑关系 特殊到一般的思想转换,最重要的是不能凭自己的感觉思考,认真画图分析
1.4查找
size_t string::find(char ch, size_t pos){for (int i = pos; i <_size; i++){if (_str[i] == ch)return i;}}size_t string::find(const char* str, size_t pos){assert(pos < _size);const char* ptr=strstr(_str + pos, str);if (ptr == nullptr){return npos;}elsereturn ptr - _str;//指针相减得到下标}1.5substr 深浅拷贝的区别
string string::substr(size_t pos, size_t len){assert(pos < _size);//判断 len大于剩余元素 更新一下lenif (len > _size - pos){len = _size - pos;}string sub;sub.reserve(len);for (int i = 0; i < len; i++){sub += _str[pos + i];}return sub;}
如果编译器优化激烈一点或者 release版本将直接 修改 suffix 省去拷贝构造
因为没有显示实现拷贝构造,编译器的拷贝构造是浅拷贝
实现一下拷贝构造和赋值重载
//s2(s1)string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}//s2=s1//s1=s1string& operator=(const string& s){if (this != &s){delete[]_str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}return *this;}1.6比较函数与流插入流提取
比较逻辑
.h......private:char* _str;size_t _size;size_t _capacity;static const size_t npos;};//定义在类外bool operator<(const string& s1, const string& s2);bool operator<=(const string& s1, const string& s2);bool operator>(const string& s1, const string& s2);bool operator>=(const string& s1, const string& s2);bool operator==(const string& s1, const string& s2);bool operator!=(const string& s1, const string& s2);.cpp//利用 strcmp 函数比较bool operator<(const string& s1, const string& s2){return strcmp(s1.c_str(), s2.c_str())<0;}bool operator<=(const string& s1, const string& s2){return s1 < s2 || s1 == s2;}bool operator>(const string& s1, const string& s2){return !(s1 <= s2);}bool operator>=(const string& s1, const string& s2){return !(s1 < s2);}bool operator==(const string& s1, const string& s2){return strcmp(s1.c_str(), s2.c_str()) == 0;}bool operator!=(const string& s1, const string& s2){return !(s1 == s2);}流插入与流提取
ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){char ch;ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}}
Tip:如果是 in>>ch 的话有分隔符的概念 不能提取到空格
注意到 += 存在扩容概念 难道一次一个 += 吗? 优化一下
istream& operator>>(istream& in, string& s){s.clear();const int N = 256;//创一个字符数组 以数组为整体单元进行+= 提高扩容效率char buff[N];int i = 0;char ch = in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == N - 1){buff[i] = '\0';s += buff;i = 0;}}//提前结束了 buff里面还有字符if (i > 0){buff[i] = '\0';s += buff;}}二、string类的拷贝
2.1浅拷贝与深拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致 多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该 资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
在这里即一个一个字节的拷贝,动态申请资源时候如果浅拷贝会指向同一块资源,会有着程序崩溃的问题

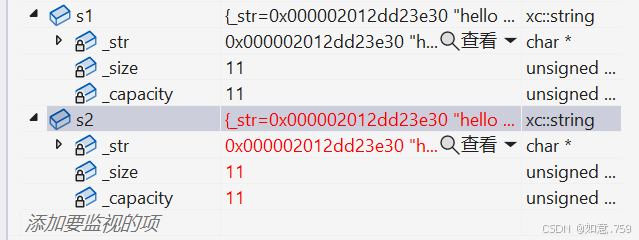
同一块空间析构了两次 程序崩溃
深拷贝即调用拷贝构造,编译器生成的拷贝构造是浅拷贝,需要我们自己显示实现拷贝构造来进行深拷贝

//s2(s1)string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}//s2=s1//s1=s1string& operator=(const string& s){if (this != &s){delete[]_str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}return *this;}
2.2传统版与现代版区别
库里的string拷贝构造赋值重载如何实现的呢? 可以直接交换成员变量 但是需要初始化成员变量
void swap(string& s){std::swap(_str, s._str);std::swap(_capacity, s._capacity);std::swap(_size, s._size);}string(const string& s){string tmp(s.c_str());swap(tmp);}......private:char* _str=nullptr;size_t _size=0;size_t _capacity=0;static const size_t npos;};//需要初始化一下 否则随机值交给tmp存在潜在风险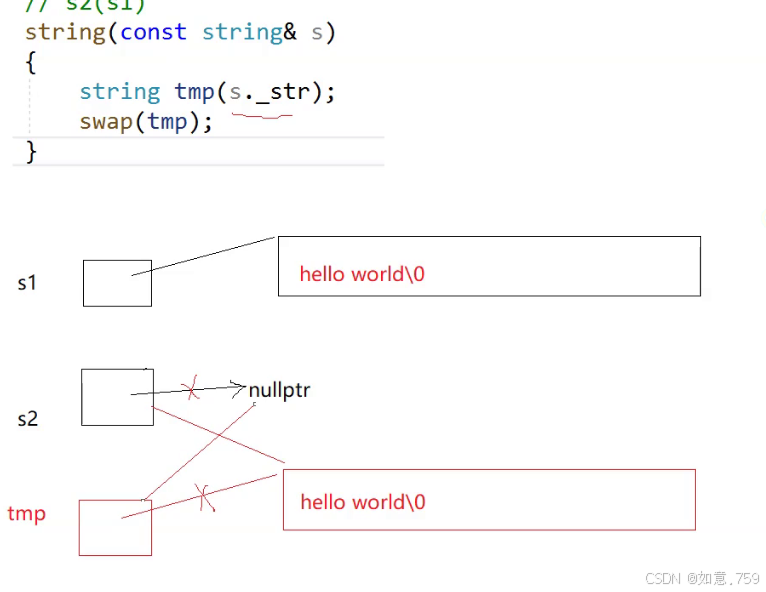
这里的巧妙点在于 tmp 出了作用域会自己调析构函数此时不需要手动析构s2 借用了编译器的作用规则,局部变量出了作用域自动销毁 这也是为什么需要初始化局部变量,因为销毁随机值存在风险
赋值重载:
//s2=s1//s1=s1/*string& operator=(const string& s){if (this != &s){delete[]_str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;}return *this;}*/string& operator=(const string& s){if (this != &s){string tmp(s.c_str());swap(tmp);}return *this;}对比一下传统版的赋值重载, 可以看到现代版不需要手动 delete 了 利用编译器自动销毁了
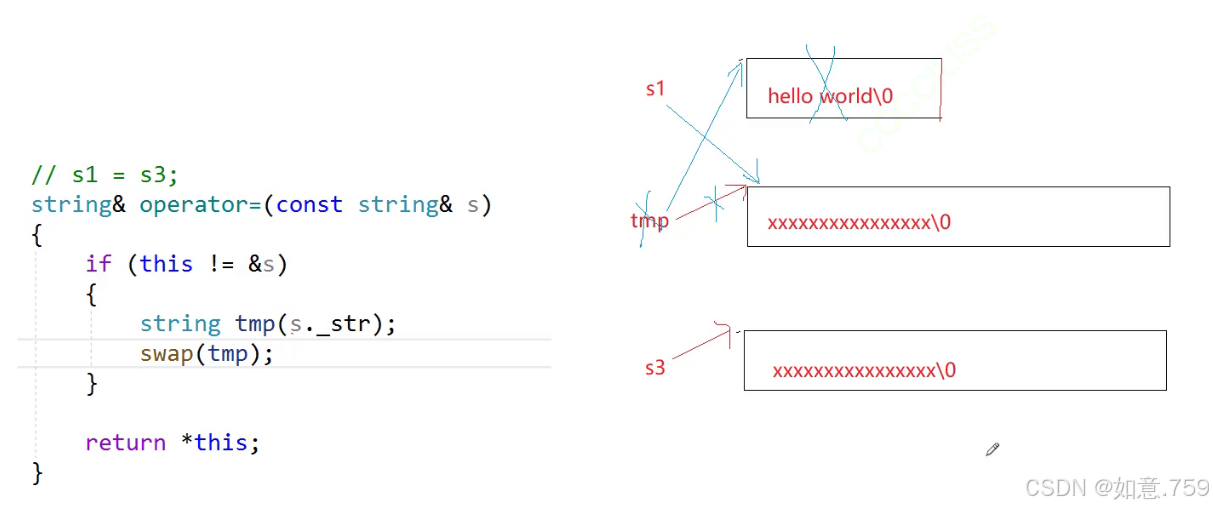
可以看到与拷贝构造相比 tmp 并没有存在的必要性,并不需要保留 s1的数据 优化一下
/*string& operator=(const string &s){if (this != &s){string tmp(s.c_str());swap(tmp);}return *this;}*///最终版 s1=s3string& operator=(string tmp){swap(tmp);return *this;}为什么算法库有swap 我们仍需要手动实现一个成员函数 swap呢?
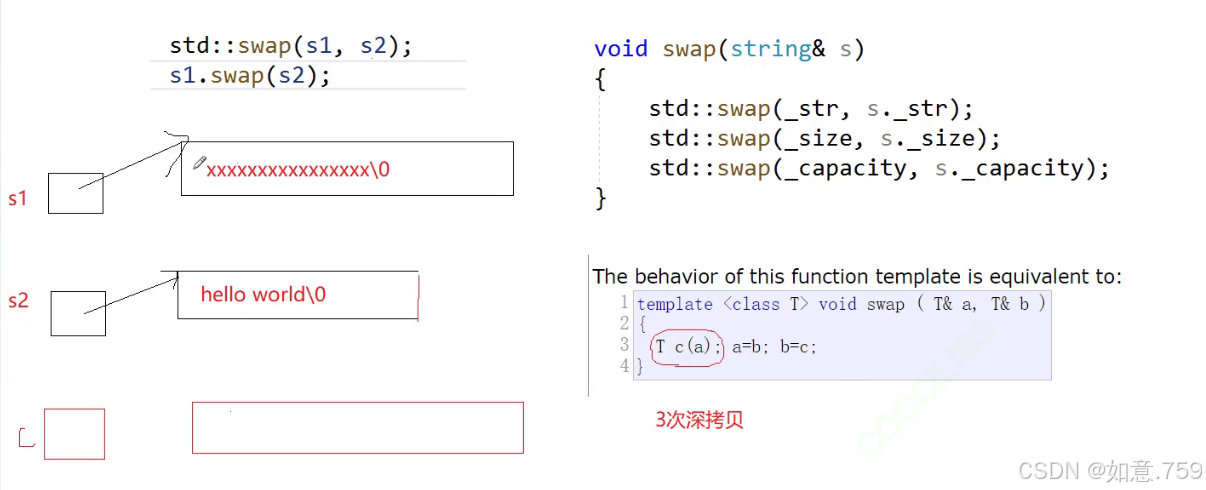
算法库里的自定义类型会进行多次拷贝构造(深拷贝),效率低
事实上 库里面已经实例化了一个模板swap函数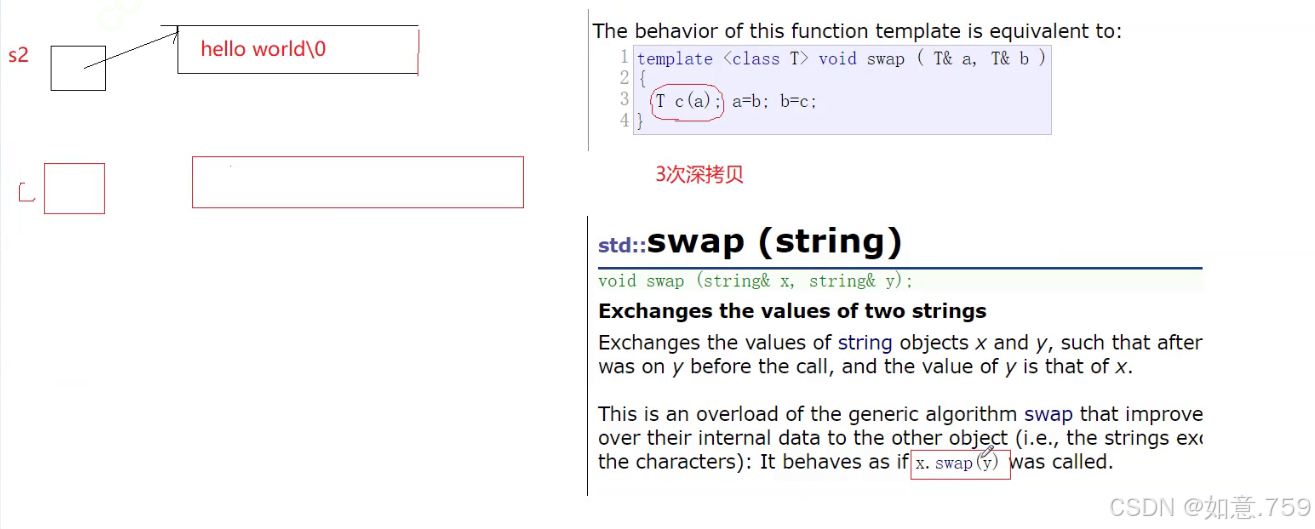
所以最终还是会调用成员函数提高效率
2.3写时拷贝(了解)
析构两次的另外一种解决方法——写时拷贝(引用计数法)
引用计数代表有几个对象指向同一块资源
当计数为0时候才执行析构函数,如果要修改拷贝的对象,那么还是需要进行深拷贝!
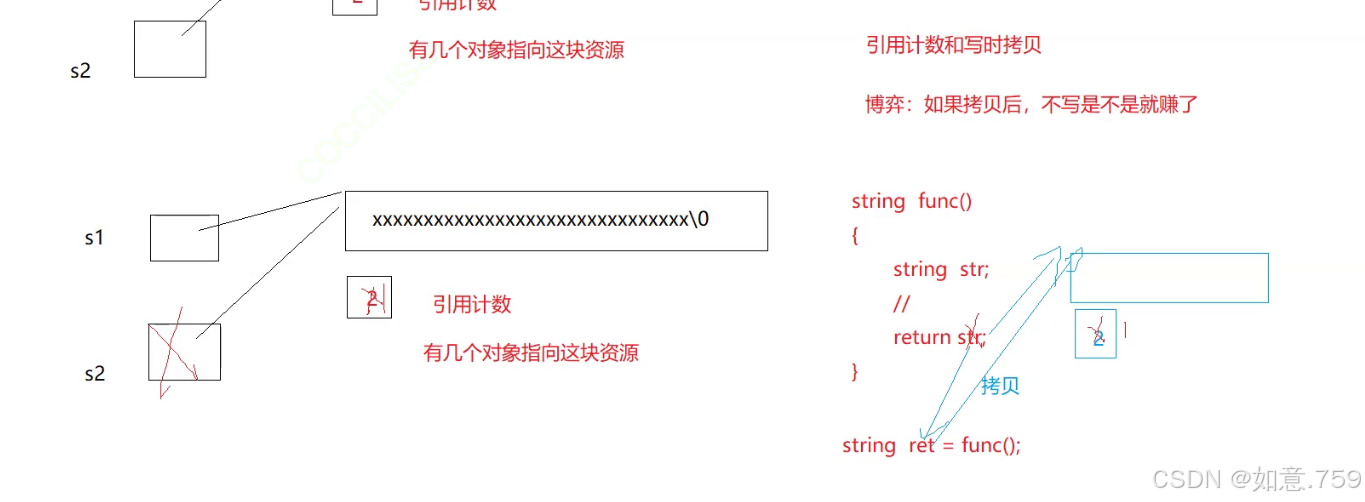
不同编译器底层采取的方案是不同的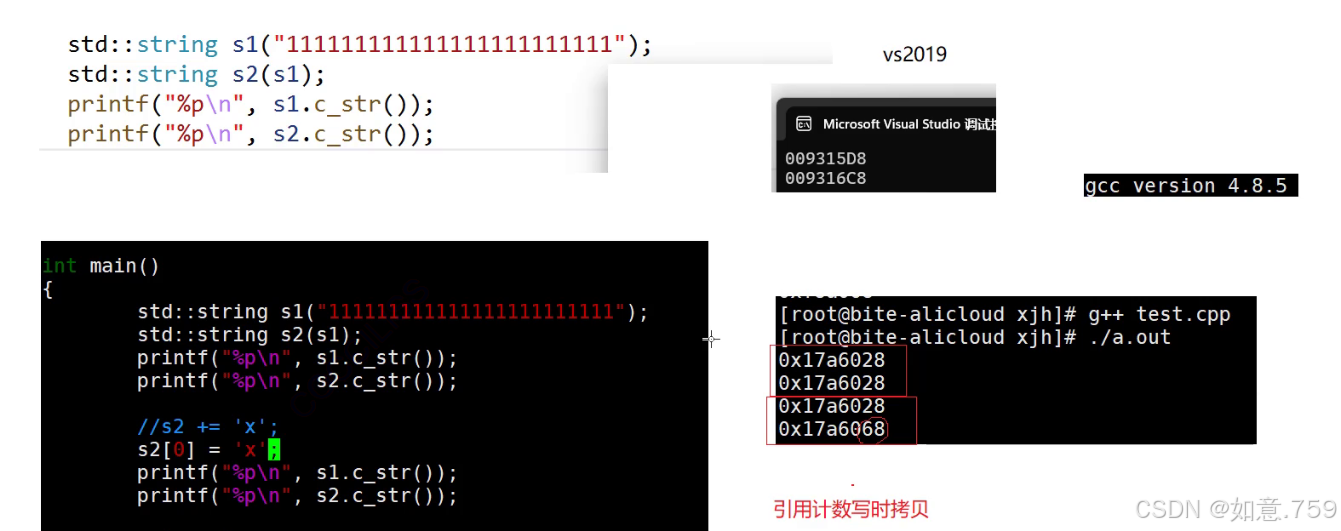
可以看到 gcc 采用了引用计数写时拷贝
三、vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
3.1vs下的string结构
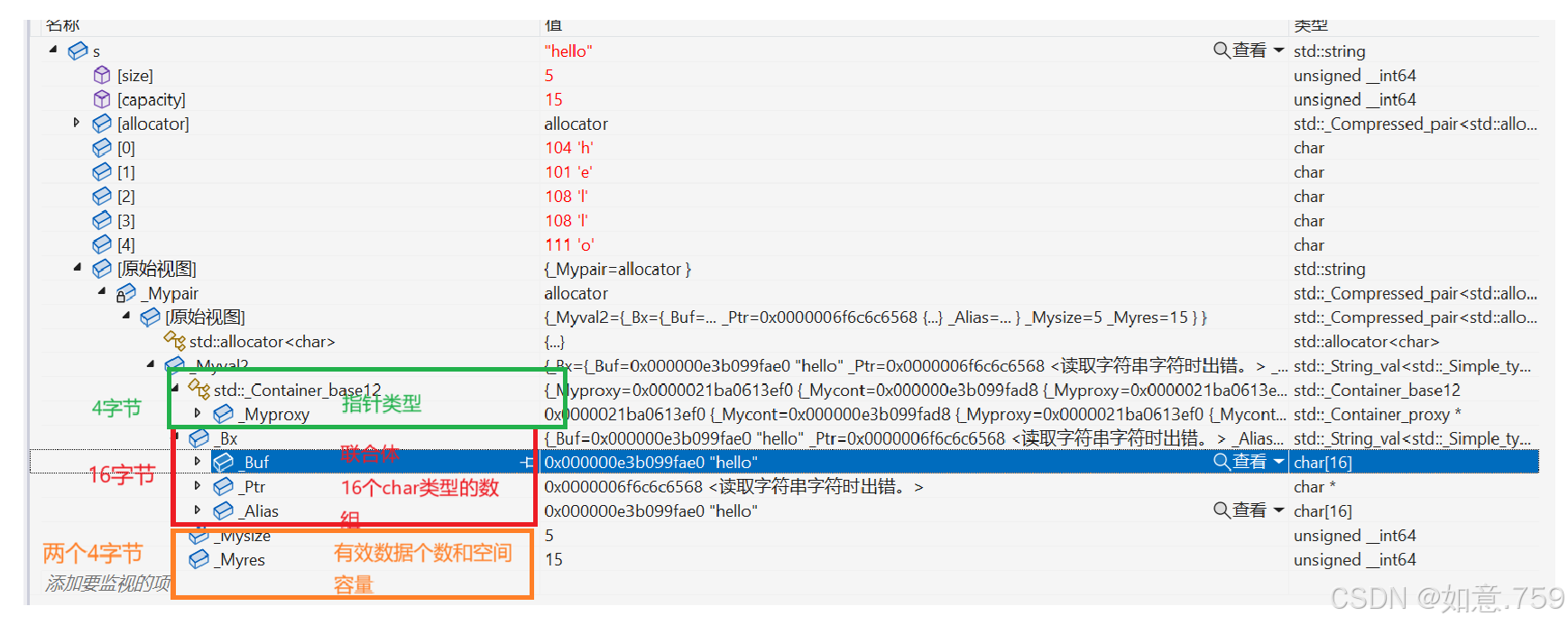
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义
string中字符串的存储空间:
● 当字符串长度小于16时,使用内部固定的字符数组来存放
● 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty{ // storage for small buffer or pointer to larger one value_type _Buf[_BUF_SIZE]; pointer _Ptr; char _Alias[_BUF_SIZE]; // to permit aliasing} _Bx;这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建
好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的
容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
3.2g++下的string结构
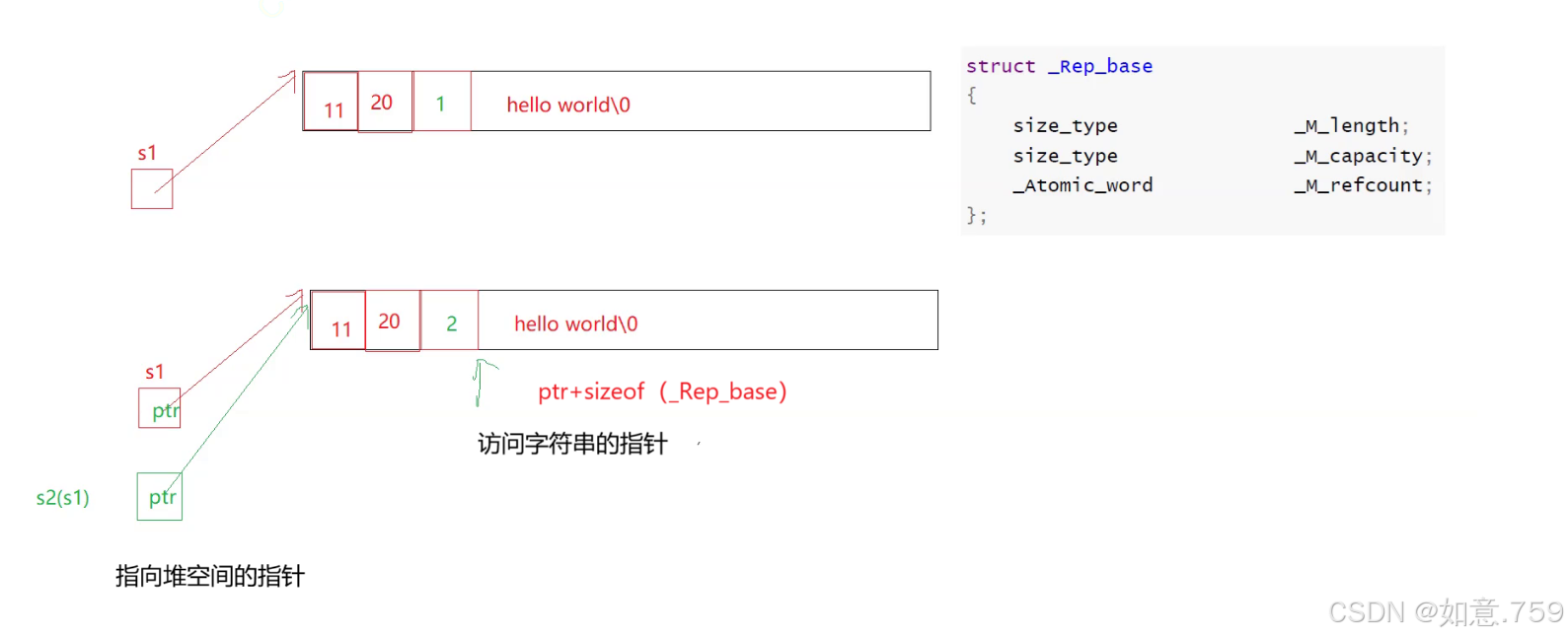
G++下,string是通过写时拷贝实现的,string对象总共占4个字节(32位)/ 8字节(64位),内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
● 空间总大小
● 字符串有效长度
● 引用计数
struct _Rep_base{ size_type _M_length; size_type _M_capacity; _Atomic_word _M_refcount;};
● 指向堆空间的指针,用来存储字符串。