
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨
?? 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。?
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。?
记得先点赞?后阅读哦~ ??
?? 所属专栏:Python
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨??


目录
基于Python的jieba和wordcloud库实现华丽词云制作
效果展示:
准备工作:
jieba库:
wordcloud库:
修改源:
完整代码:
示例1:
效果图
示例2:
效果图1:
效果图2:
基于Python的jieba和wordcloud库实现华丽词云制作
效果展示:

准备工作:
安装jieba库和wordcloud库
jieba和wordcloud是两个在自然语言处理和数据可视化领域非常常用的Python库。
jieba库:
jieba是一个优秀的中文分词工具,它能够将一段中文文本切分成一个一个的词语。jieba库提供了多种分词模式和功能,包括精确模式、全模式、搜索引擎模式等。使用jieba库可以帮助你更好地处理中文文本,进行文本分析和挖掘。
wordcloud库:
wordcloud是一个用于生成词云图的库。词云图是以词语的重要性或频率为基础,通过字体大小和颜色的不同来展示词语的热度。wordcloud库可以根据给定的文本数据生成漂亮的词云图,使得文本中的关键词能够直观地展现出来。你可以自定义词云的形状、颜色、字体等参数。
这两个库结合起来,你可以使用jieba库对文本进行分词处理,然后利用wordcloud库生成词云图,从而实现对文本数据的可视化展示和分析。这对于文本挖掘、情感分析、舆情监控等任务非常有用。
修改源:
如果安装卡在最后阶段,安装不了,可使用这个修改源
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
将上面的代码中的numpy改为jieba、wordcloud即可在终端命令行安装!


完整代码:
示例1:
import jiebaimport wordcloudf = open("文案.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud( \ width = 1000, height = 700,\ background_color = "white", font_path = "msyh.ttc" )w.generate(txt)w.to_file("grwordcloud.png")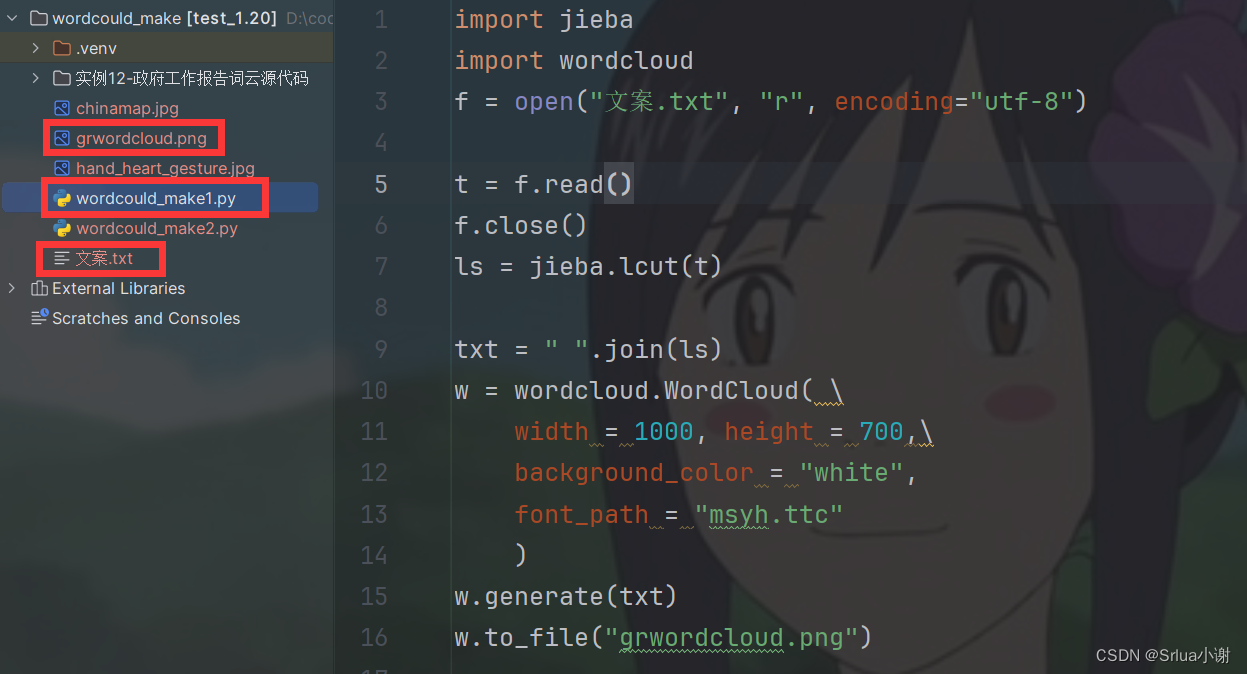
在目录下我们需要准备好一个.txt文本文件,内容自拟,博主这里准备了九十个词汇

运行成功,如果有警告可以忽视

这是我们可以查看我们目录下生成的wordcloud图片文件
效果图

如果已经存在同名文件,则会覆盖原图片文件
示例2:
import jiebaimport wordcloudfrom matplotlib.pyplot import imread# 读取词云形状的图片,这里使用了一个名为 "chinamap.jpg" 的图片作为词云形状mask = imread("chinamap.jpg")# 定义排除词语的集合,但是当前代码中未使用到该集合excludes = {}# 打开文案文件 "文案.txt",并读取其中的内容f = open("文案.txt", "r", encoding="utf-8")t = f.read()f.close()# 使用jieba分词将文本内容分词ls = jieba.lcut(t)# 将分词结果转换成以空格分隔的字符串txt = " ".join(ls)# 创建词云对象,并设置词云的参数,包括宽度、高度、背景颜色、字体路径和形状等w = wordcloud.WordCloud(\ width=1000, height=700,\ background_color="white", font_path="msyh.ttc", mask=mask)# 根据分词结果生成词云图w.generate(txt)# 将生成的词云图保存为图片文件 "grwordcloud1.png"w.to_file("grwordcloud1.png")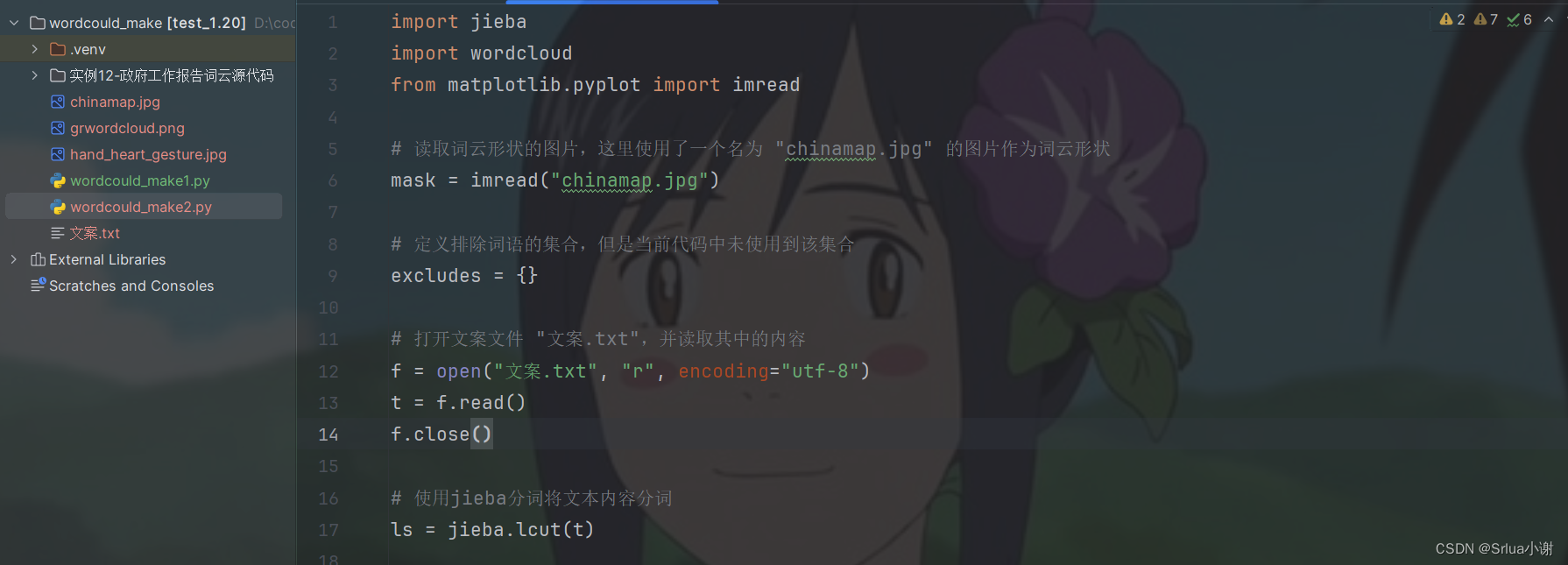
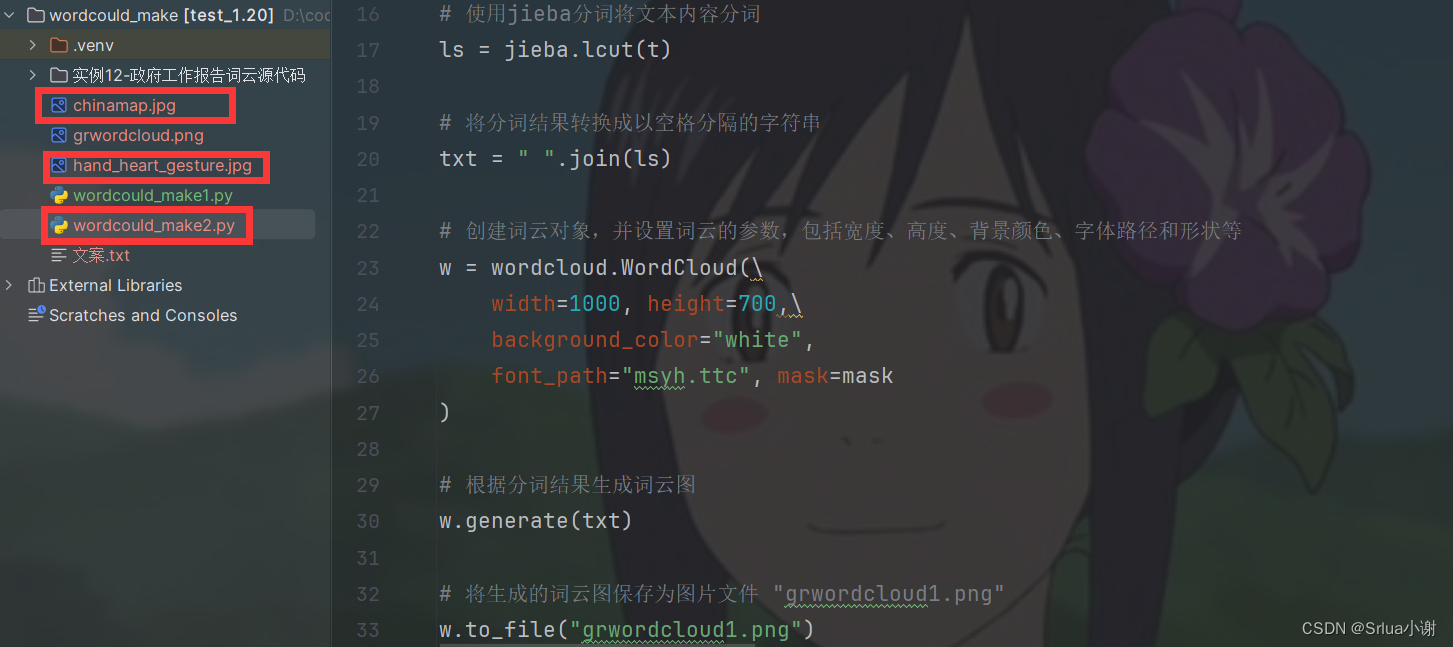
这里博主提前准备了两个用于做词语的底图chinamap.jpg和hand_heart_gesture.jpg的文件


运行成功,生成新文件:
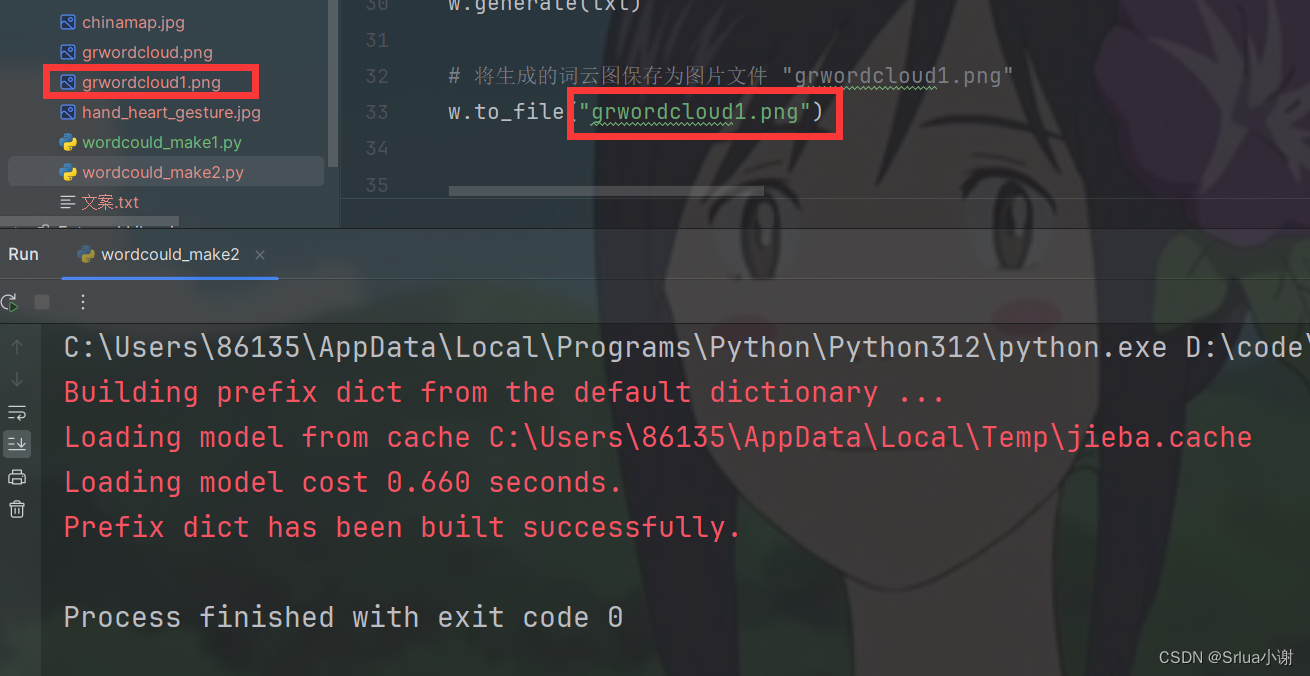
效果图1:

修改文件路径
 效果图2:
效果图2:
 这段代码首先导入了jieba用于中文分词和wordcloud用于生成词云图的库,以及imread函数从matplotlib.pyplot模块用于读取图片。然后通过imread函数读取了一个图片文件作为词云的形状。接着定义了一个空集合excludes,但在当前代码中并未使用到。然后打开了一个名为"文案.txt"的文本文件,并读取其中的内容。使用jieba对文本内容进行分词,然后将分词结果转换成以空格分隔的字符串。接下来创建了一个词云对象w,设置了词云的参数,包括宽度、高度、背景颜色、字体路径和词云形状等。最后根据分词结果生成词云图,并将生成的词云图保存为图片文件"grwordcloud。
这段代码首先导入了jieba用于中文分词和wordcloud用于生成词云图的库,以及imread函数从matplotlib.pyplot模块用于读取图片。然后通过imread函数读取了一个图片文件作为词云的形状。接着定义了一个空集合excludes,但在当前代码中并未使用到。然后打开了一个名为"文案.txt"的文本文件,并读取其中的内容。使用jieba对文本内容进行分词,然后将分词结果转换成以空格分隔的字符串。接下来创建了一个词云对象w,设置了词云的参数,包括宽度、高度、背景颜色、字体路径和词云形状等。最后根据分词结果生成词云图,并将生成的词云图保存为图片文件"grwordcloud。
希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!