对于刚刚落下帷幕的2023年,人们曾经给予其高度评价——AIGC元年。随着 ChatGPT 的火爆出圈,大语言模型、AI 生成内容、多模态、提示词、量化…等等名词开始相继频频出现在人们的视野当中,而在这场足以引发第四次工业革命的技术浪潮里,人们对于人工智能的态度,正从一开始的惊喜慢慢地变成担忧。因为 AI 在生成文字、代码、图像、音频和视频等方面的能力越来越强大,强大到需要 “冷门歌手” 孙燕姿亲自发文回应,强大到连山姆·奥特曼都被 OpenAI 解雇。在经历过 OpenAI 套壳、New Bing、GitHub Copilot 以及各式 AI 应用、各类大语言模型的持续轰炸后,我们终于迎来了人工智能的 “安卓时刻”,即除了 ChatGPT、Gemini 等专有模型以外,我们现在有更多的开源大模型可以选择。可这难免会让我们感到困惑,人工智能的尽头到底是什么呢?2013年的时候,我以为未来属于提示词工程(Prompt Engineering),可后来好像是 RAG 以及 GPTs 更受欢迎?
从哪里开始
在经历过早期调用 OpenAI API 各种障碍后,我觉得大语言模型,最终还是需要回归到私有化部署这条路上来。毕竟,连最近新上市的手机都开始内置大语言模型了,我先后在手机上体验了有大语言模型加持的小爱同学,以及抖音的豆包,不能说体验有多好,可终归是聊胜于无。目前,整个人工智能领域大致可以分为三个层次,即:算力、模型和应用。其中,算力,本质上就是芯片,对大模型来说特指高性能显卡;模型,现在在 Hugging Face 可以找到各种开源的模型,即便可以节省训练模型的成本,可对这些模型的微调和改进依然是 “最后一公里” 的痛点;应用,目前 GPTs 极大地推动了各类 AI 应用的落地,而像 Poe 这类聚合式的 AI 应用功能要更强大一点。最终,我决定先在 CPU 环境下利用 llama.cpp 部署一个 AI 大模型,等打通上下游关节后,再考虑使用 GPU 环境实现最终落地。从头开始训练一个模型是不大现实的,可如果通过 LangChain 这类框架接入本地知识库还是有希望的。
编译 llama.cpp
llama.cpp 是一个纯 C/C++ 实现的 LLaMA 模型推理工具,由于其具有极高的性能,因此,它可以同时在 GPU 和 CPU 环境下运行,这给了像博主这种寻常百姓可操作的空间。在 Meta 半开源了其 LLaMA 模型以后,斯坦福大学发布了其基于 LLaMA-7B 模型微调而来的模型 Alpaca,在开源社区的积极响应下,在 Hugging Face 上面相继衍生出了更多的基于 LLaMA 模型的模型,这意味着这些由 LLaMA 衍生而来的模型,都可以交给 llama.cpp 这个项目来进行推理。对硬件要求低、可供选择的模型多,这是博主选择 llama.cpp 的主要原因。在这篇文章里,博主使用的是一台搭配 i7-1360P 处理器、32G 内存的笔记本,按照 LLaMA 的性能要求,运行 GGML 格式的 7B 模型至少需要 13G 内存,而运行 GGML 格式的 13B 模型至少需要 24G 内存,大家可以根据自身配置选择合适的模型,个人建议选择 7B 即可,因为 13B 运行时间一长以后还是会感到吃力,哎?。
准备工作
在正式开始前,请确保你可以熟练使用 Git,以及具备科学上网的条件,因为我们需要从 Hugging Face 上下载模型。此外,你还需要下载并安装以下软件:
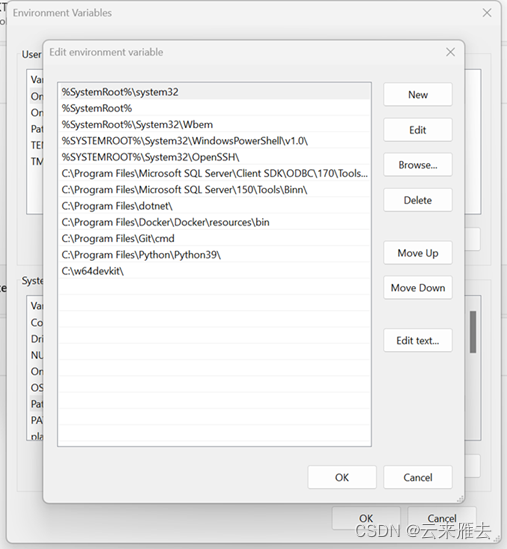
Python: 官方网站、华为镜像,建议选择 3.9 及其以上版本 w64devkit:便携式 C/C++ 编译环境,集成了 gcc、make 等常见的工具 OpenBLAS(可选): 可以提供 CPU 加速的高性能矩阵计算库,建议安装w64devkit 和 OpenBLAS 下载下来都是压缩包,直接解压即可,建议将 w64devkit 解压在一个不含空格和中文的路径下,例如:C:\w64devkit。接下来,我们还需要 OpenBLAS 的库文件和头文件,请将其 include 目录下的内容,全部复制到 C:\w64devkit\x86_64-w64-mingw32\include 目录下;请将其 lib 目录下的 libopenblas.a 文件复制到 C:\w64devkit\x86_64-w64-mingw32\lib 目录下。保险起见,个人建议将 C:\w64devkit 目录添加到 Path 环境变量中,如下图所示:
至此,我们就完成了全部的准备工作。需要说明的是,这里是以 Windows + Make + OpenBLAS 为例进行演示和写作。如果你是 Mac 或者 Linux 系统用户,或者你想 CMake 或者 CUDA,请参考官方文档:https://github.com/ggerganov/llama.cpp,虽然这份文档是纯英文的,但是我相信这应该难不倒屏幕前的各位程序员朋友,哈哈?。
编译过程
好的,对于 llama.cpp 而言,其实官方提供了预编译的可执行程序,具体请参考这里:https://github.com/ggerganov/llama.cpp/releases。通常情况下,普通的 Windows 用户只需要选择类似 llama-b2084-bin-win-openblas-x64.zip 这样的发行版本即可。如果你拥有高性能显卡,可以选择类似 llama-b2084-bin-win-cublas-cu12.2.0-x64.zip 这样的发行版即可,其中的 cu 表示 CUDA,这是由显卡厂商 Nvdia 推出的运算平台。什么样的显卡算高性能显卡呢?就我朴实无华的游戏史观点而言,只要能流畅运行育碧旗下的《刺客信条:大革命》及其后续作品的,都可以算得上高性能显卡。这里,我们选择手动编译,因为通读整个文档你就会发现,llama.cpp 里面提供了大量的编译参数,这些参数或多或少地会影响到你编译的产物。所以&#x