
送给大家一句话:
人生最遗憾的,莫过于,轻易地放弃了不该放弃的,固执地坚持了不该坚持的。 – 柏拉图
(x(x_(x_x(O_o)x_x)_x)x)
(x(x_(x_x(O_o)x_x)_x)x)
(x(x_(x_x(O_o)x_x)_x)x)
底层比较
1 前言2 编译使用比较2 如何加载Thanks♪(・ω・)ノ谢谢阅读!!!下一篇文章见!!!
1 前言
我们前两篇文章讲解了如何建立动静态库与如何使用动静态库。
接下来我们就来深入聊聊动静态库。
2 编译使用比较
那么 gcc编译的时候是怎么进行的:
gcc不加-static选项默认使用动态库,没有提供动态库就只能使用静态库gcc加-static选项就使用静态库 那么-static的意义是什么呢?
一般我们的操作系统都是动态库 并且在对.o文件打包的时候:
ar -rc 文件名...动态库使用gcc -shared,前提是.o文件里进行-fPIC位置无关码的设置gcc -fPIC -c 文件名 使用的方法:
静态库: 安装到操作系统中,.h 文件放入/user/include中,.a文件放入/lib64/中 就可以了gcc test.c -I../mylib/include/ -L ../mylib/lib -lmyc 使用命令直接表明使用的头文件路径,库文件路径和使用的库 动态库: 直接安装到系统中/lib64/(或者建立软连接)命令行修改环境变量修改环境变量初始化脚本文件.bashrc增添配置文件 预测一下,如果我们使用别人的库,别人应该给我们提供什么?一批头文件 + 一批库文件(.so .a)
2 如何加载
如果要谈库是如何加载的,就要想来谈一谈可执行程序是怎么运行的!
首先,可执行程序与库都是磁盘文件。在可执行程序的运行之前需要先找到对应的文件。静态库很简单,不需要考虑这么多,因为在编译期间就把静态库的内容拷贝到了可执行文件当中。就不必谈论找到静态库这一说了。动态库就不一样,需要在运行的过程中寻找与加载!
根据我们先前学习的进程相关知识,可以大致画出一个示意图:
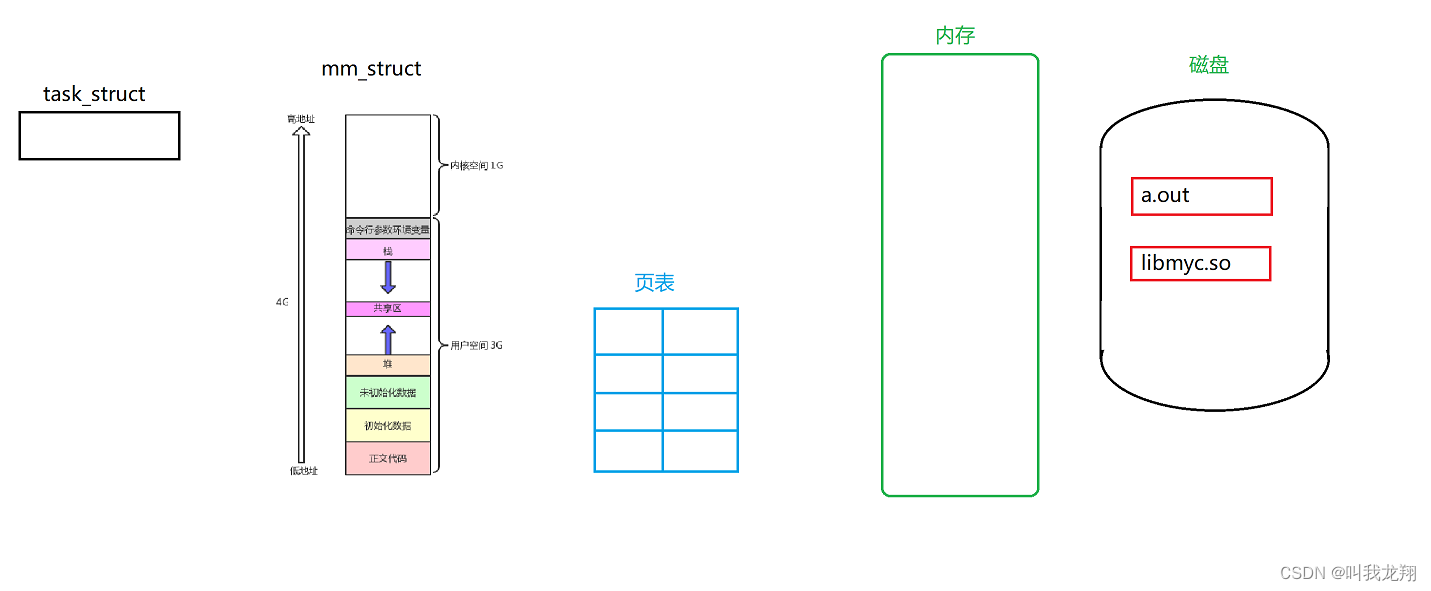
可执行程序运行的过程会把磁盘中a.out的文件读入到内存中,并形成对应的进程PCB模块与数据模块,然后就进入执行队列中进行调度运行。但是对应的方法并没有在可执行程序中,所以动态库是怎样被调用的呢?又是什么时候被调用呢?
动态库也会写入到内存中,并通过页表映射到地址空间中的共享区。让调用的时候通过共享区来找到对应的方法实现。
其他的可执行文件相要调用动态库中的方法是,也可以通过页表来映射就可以。所以动态库只需要在内存中存在一份
有个问题:我们的可执行程序,编译成功之后,如果没有加载运行,二进制代码中有没有对应的“地址”?
接下来我们来通过程序代码来探究一下。
我们创建一个新的目录,并写一段代码:
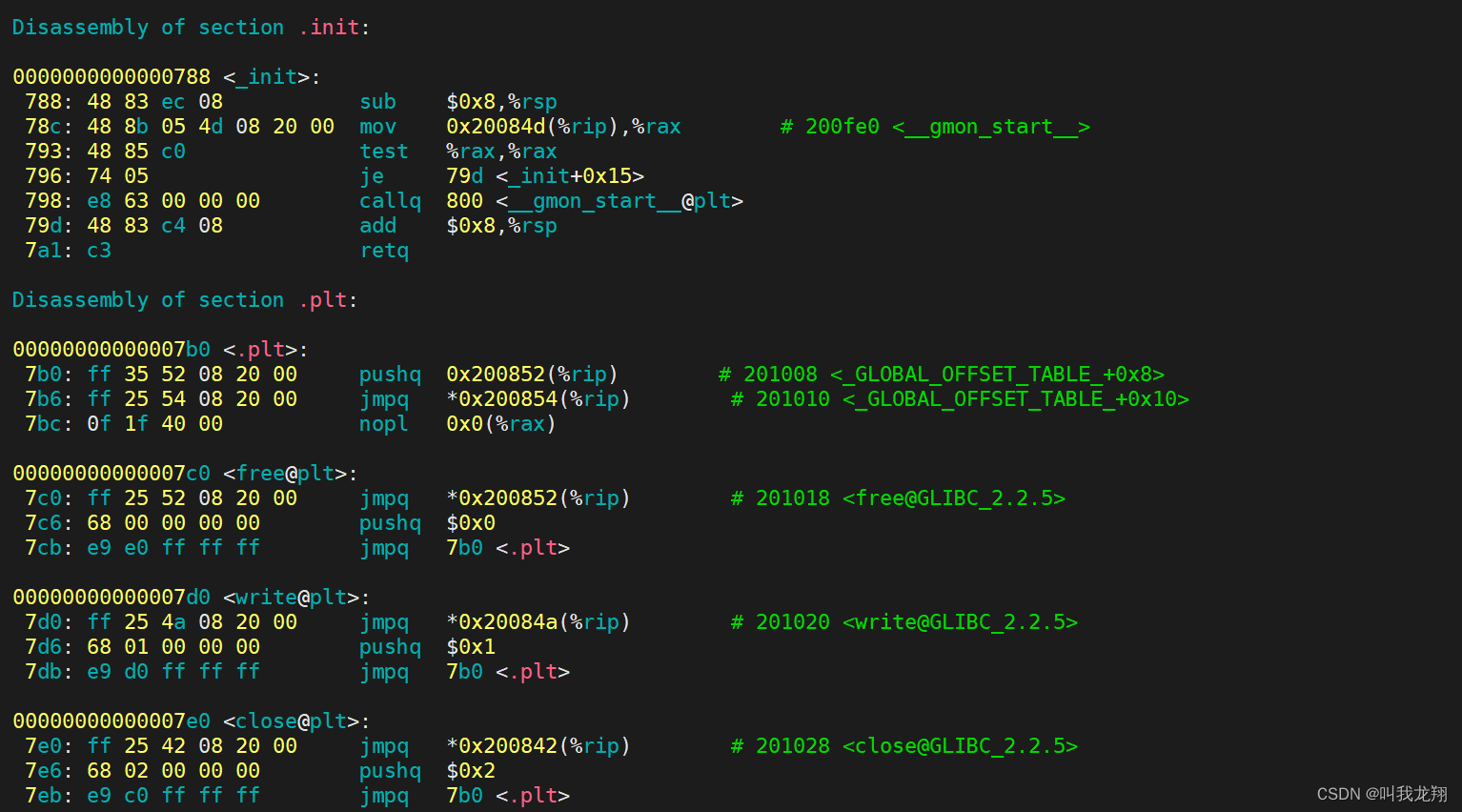
1 #include<stdio.h> 2 3 int sum(int top) 4 { 5 int i = 1; 6 int ret = 0; 7 for(; i <= top ; i++) 8 { 9 ret += i; 10 } 11 12 return ret; 13 } 14 15 int main() 16 { 17 int top = 100; 18 int res = sum(top); 19 20 printf("result:%d\n",res); 21 22 return 0 ; 23 } 我们把他编译一下,之后进行反汇编objdump -S code,下面就是程序汇编代码:
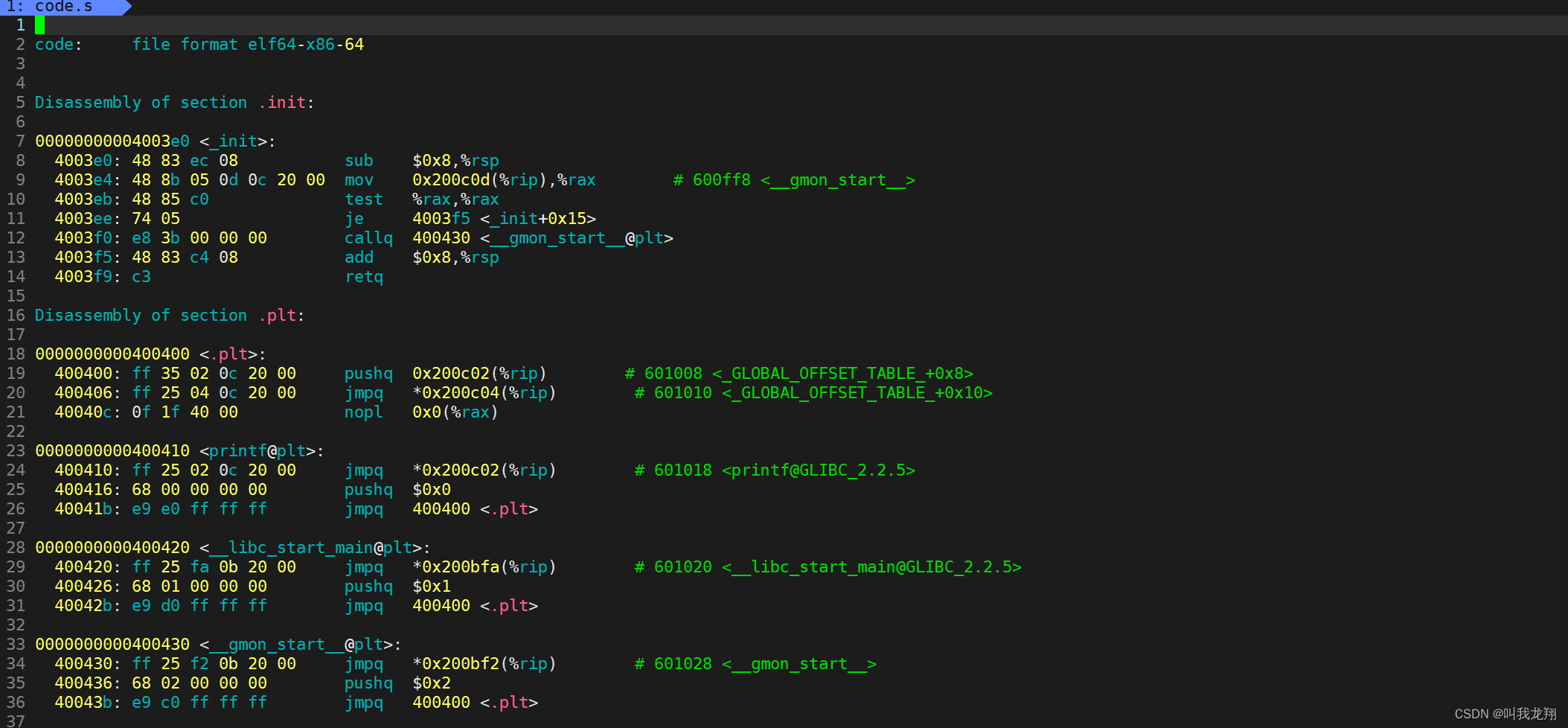
其中可以看到,前面都有一列地址,所以我们的可执行程序里面默认包含着地址。我们之间看源代码不用加载运行,就可以想象着一步一步运行我们的程序!
我们介绍一下ELF格式的程序,二进制是有自己的固定格式的,elf可执行程序的头部储存这可执行程序的属性!
可执行程序会变成无数条汇编语句,每条汇编语句都有对应的地址!那这个地址是什么地址,又是如何进行编址的呢?当前环境当中就是从000000... 到 ffffff... 的地址(虚拟地址也叫逻辑地址)来进行平坦模式的编址。这样通过0 + 偏移量 就可以调用对应汇编的语句
操作系统中还要一个加载器,可以通过地址将数据拷贝到内存中。通过ELF+加载器 可以帮我们找到这个程序的开始与结束位置!!!
进程我们知道:进程 = 内核数据结构 + 代码与数据
那现在有个问题:当我们要加载这个程序时,是先加载内核数据结构还是先加载代码与数据呢?
来我们来进行模拟一下:
首先我们肯定是要形成PCB(状态 ,优先级…)然后更关键的是创建地址空间(mm_struct),里面有区域划分(code_start , code_end , global_start),那么这些区域划分的初始值从哪里来呢???初始值从可执行程序来!通过可执行程序自身的头部属性信息(虚拟地址)来初始化地址空间。虚拟地址空间不是操作系统独有的 ,OS ,编译器,加载器都会存在虚拟地址此时就可以来把程序加载到内存中了 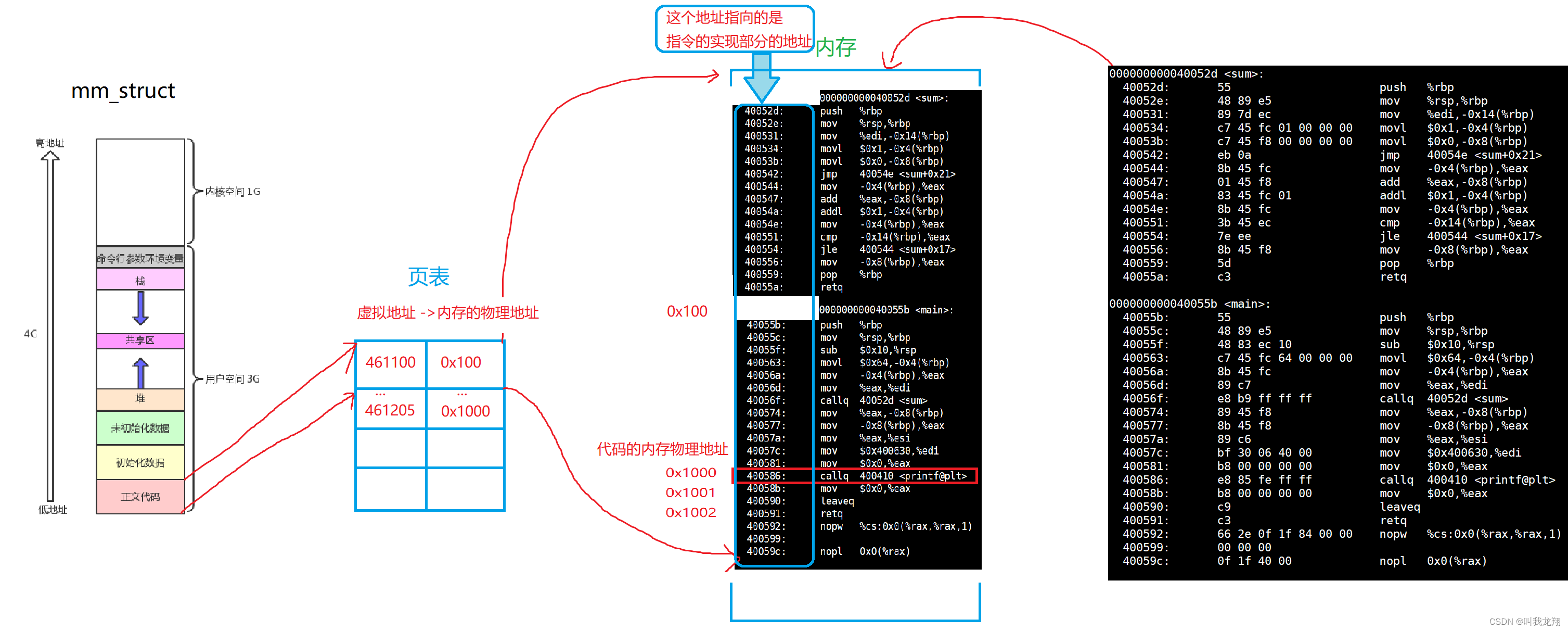
CPU中存在这样一个寄存器pc指针,用来指向当前执行指令的下一条指令的地址,pc指向哪里,CPU就执行哪里的语句!
依次进行就可以完成代码的执行!
总结一下:
进程创建阶段,初始化地址空间,让CPU知道main函数的入口地址加载 -> 每一行代码与数据就都有了物理地址,自己的虚拟地址自己也就知道了,就可以构建映射了接下来我们就来看看动态库是如何加载的:
先来看看动态库的回报代码,发现也是使用平坦模式进行编址的!
所以同样的,与加载可执行程序类似,会把动态库读入内存中,并建立对应的页表映射,**动态库的虚拟地址在进程地址空间里是在共享区里的。**那么对应的函数方法就有了起始与终止位置
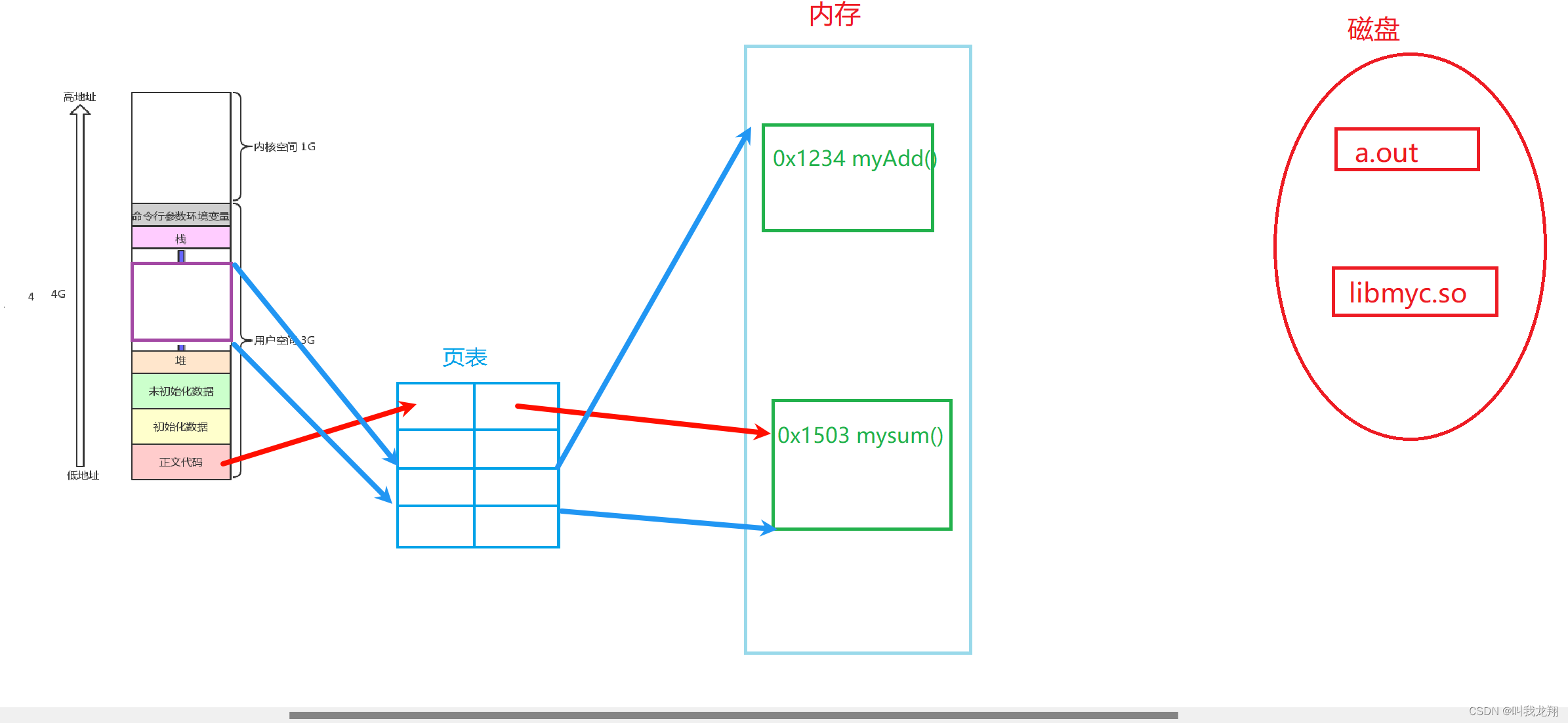
那么当代码运行的时候,指向到了库函数,这是怎么处理?
首先,库的虚拟地址储存在共享区在磁盘中,动态库的编址是平坦模式的编址,其地址0x1234就像是距离0000...的一个偏移量然后在共享区里,这个偏移量是没有改变的1所以想要执行库函数,就直接到共享区通过库的起始地址 + 偏移量找到对应的函数就可以执行了。所以只有了偏移量与库的初始地址,无论库加载到哪里都可以成功寻找到该函数 -> 也就验证了位置无关码!所以形成.o文件的时候就要加上-fPIC!!! 同样其他进程也可以通过共享区的库的起始地址 + 偏移量映射,来访问内存中的函数。库函数调用,其实也是在进程的地址空间里来回跳转!!!与非库函数类似奥!
那么怎么知道一个库有没有被加载到内存中呢?
动态库是由操作系统来管理的,所以就要有对应的描述结构体!!!所以使用的时候,想要知道有没有加载,就可以通过库的名称来找到对应的描述结构体,来查看是否被加载!!!