AIGC,Artificial Intelligence Generated Content,人工智能生成内容
AIGC for code,AI生成代码
1 Github Copilot
1.1 简介
Copilot是由微软的子公司Github与openAI共同开发的人工智能(AI)驱动的编程助手。它能够直接在你的编辑器中,为你提供代码片段或者整个函数的建议,以帮助你更快地编写和完成代码。这个工具可以被看作是一个自动的代码完成工具,它能理解自然语言,也能理解代码本身的上下文
Copilot 的建议来源于公开源代码的大量数据,这使得它能够处理各种编程语言和框架,而且它的性能会随着时间的推移和它的使用而不断提高。它的目标是成为一种强大的工具,使得开发者可以更高效地编写代码,而且即使在对某种编程语言或者框架不熟悉的情况下,也能得到有用的建议
然而,值得注意的是,尽管 GitHub Copilot 提供了有价值的代码建议,但它并不能保证建议的代码总是正确的,或者总是符合最佳实践。因此,开发者仍然需要对 Copilot 提供的代码进行审查,以确保代码的质量和安全性
1.2 pycharm使用实例
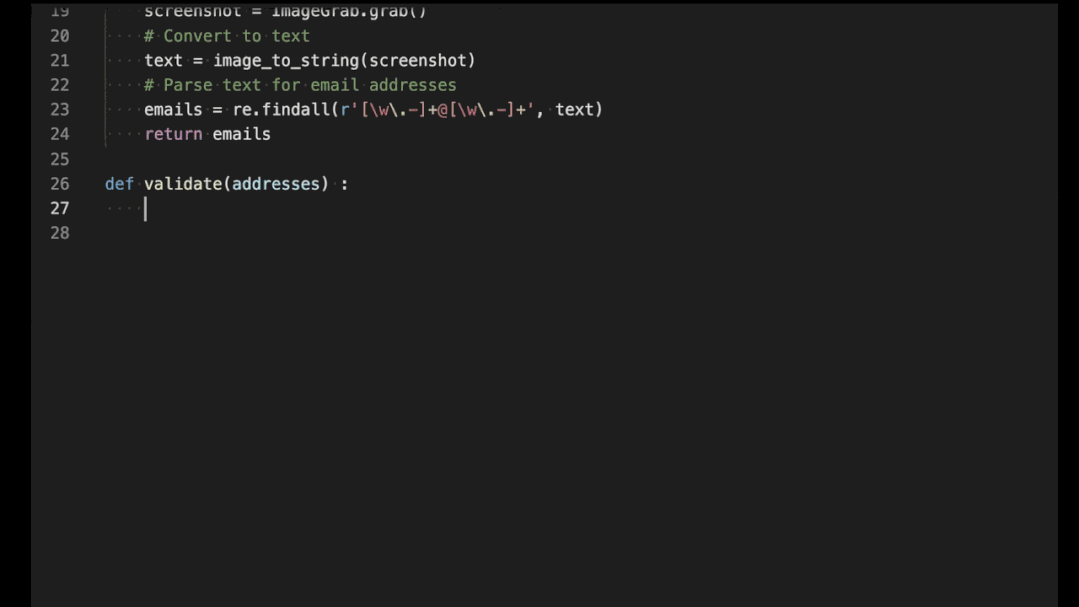
copilot自动编程实例
1.3 相关技术
AIGC的模型都是基于大语言模型(Large Language Model),Github Copilot是基于openAI的大语言模型,特别是GPT3和codex。但是这些模型都是从Transformer演变而来,Transformer架构最早是由谷歌在2017年的一篇论文提出,现在是自然语言处理的主流模型,是一个最基本的结构,现在与CNN、RNN、GNN、GAN称为深度学习五大基本网络。
GPT-3:GPT-3(生成预训练Transformer 3)是OpenAI开发的第三代大型语言模型。它使用了1750亿个模型参数,是当时世界上最大的语言模型。GPT-3在各种自然语言处理任务中都表现出了强大的性能,包括文本生成、文本分类、情感分析等。
Codex:Codex是OpenAI基于GPT-3开发的一个特化版本,专门用于处理代码。它在公开和私有的代码库上进行训练,包括GitHub上的公开代码库。这使得Codex能够理解和生成各种编程语言的代码。
Transformer,架构是一种深度学习模型架构,特别适合处理有顺序关系的数据,如文本或代码。它的关键组成部分是自注意力机制(self-attention mechanism),这使得模型可以对输入序列中的每个元素的上下文关系进行建模。
GitHub Copilot使用这些模型的方式是,当你在编辑器中输入代码时,它会将你已经输入的代码作为输入传递给模型,然后模型会生成可能的代码补全建议。这种方式使得GitHub Copilot可以为几乎任何编程语言生成代码建议,只要该语言在模型的训练数据中有足够的表示。
需要注意的是,虽然GitHub Copilot可以生成代码,但它并不理解代码的含义,也不能理解复杂的程序设计或软件工程原则。它只是根据在大量代码上的训练来生成可能的代码补全。
2023年2月份,Github Copilot进行了一次重大更新,用于生成代码的codex模型已经升级。代码建议的质量大规模提升,以及用户建议的时间也减少。在2023年2月14日这篇报道指出,在所有安装了github copilot的开发者中,他们有46%的代码是由Github copilot生成的,而在Java开发者中,这个比例更是达到了61%。
此外,GitHub Copilot 还推出了一种基于 AI 的漏洞预防系统,该系统可以实时阻止不安全的编码模式,使代码建议更加安全。这个模型针对最常见的易受攻击的编码模式,包括硬编码的凭据、SQL 注入和路径注入。新系统利用 LLMs 来近似静态分析工具的行为,甚至可以在不完整的代码片段中检测到易受攻击的模式,迅速阻止不安全的编码模式并用其他建议替换它们。
笼统的说Copilot 的工作原理可以大致分为两个阶段:第一阶段是从海量代码库中抽取出有效的代码段和语句,这些代码段用于训练AI模型;第二阶段则是谷歌的自然语言处理技术和深度神经网络技术,将文本解析成进一步的代码、注释等,从而提示开发者编写高质量的代码片段。
具体来说,Copilot 的背后算法是基于 大语言模型 按seq to seq(序列到序列)学习框架,主要包括以下几个组件:
自然语言处理(NLP)技术:Copilot 通过自然语言处理技术对文本进行解析,理解开发者的输入和上下文,从而生成相关代码。该技术利用机器学习算法,分析和理解开发者的输入、代码语义及语境信息,同时把它与语言模型库中存储的大量现有的代码片段及编码习惯进行比对和匹配,以找到最佳的代码片段相关提示。
对抗训练:Copilot 采用了对抗训练(adversarial training)的方法,该方法训练出一组生成“正确”的代码(例如与开发者输入匹配、正确运行的代码),然后又提供一些近似的输入,以训练模型如何在模糊的环境下生成正确的代码。
大量的训练集:Copilot 借助了GitHub 提供训练代码的大量数据,进行深度学习和训练。这个数据集包含了超过数亿行的代码,其中包括不同编程语言和框架的代码,这使得 Copilot 可以学习如何生成和提示各种语言和框架的代码。
深度神经网络:Copilot 采用了Transformer 模型、多层感知器和卷积神经网络等深度学习技术来实现代码自动生成,这些技术将海量的训练数据输入到神经网络中,通过深度学习不断优化神经网络的权值,以产生最准确的代码提示和生成。
从这些算法和技术背后,Copilot 的原理可以被概括为:基于开发者的输入和上下文语言,采用机器学习和深度学习技术进行代码编写提示;将其与已存在的代码库和语义模型进行比对和试验,以生成最佳的代码。总体来说,Copilot 结合了大规模 AI 能力和优秀的训练集,可以帮助开发者快速编写代码、加速开发速度,进一步提高了软件开发效率
1.4 codex介绍
既然Github Copilot的主体模型部分都是由openAI提供的codex和gpt3,那接下来介绍一下codex。
2 codex
2.1 简介
Codex 是 OpenAI 公司推出的 GPT-3(Generative Pre-trained Transformer – 3)的多个派生模型之一。它是基于GPT语言模型,使用代码数据进行 Fine-Tune(微调)而训练出的专门用于代码生成/文档生成的模型。
codex 模型参数从12M到12B不等,是目前最强的编程语言预训练模型。Codex 能够帮助程序员根据函数名和注释自动补全代码、直接生成代码、自动补充测试样例,并支持多种编程语言。本期 Azure OpenAI 官方指南将详解 Codex 的模型结构如何帮助程序员实现自动代码生成。
2.2 codex 的模型结构
OpenAI CTO 兼联合创始人 Greg Brockman 表示,“Codex 将是一款能够施展程序员力量的重要工具”。Codex 项目负责人 Wojciech Zaremba 则将 Codex 视为编码历史演变的下一阶段。那么,Codex 是如何颠覆编码的?
编程主要分为两个阶段,第一个阶段是认真思考问题并尝试理解,第二个阶段是把这些小片段与现有代码映射起来,包括库、函数以及 API。通过自然语言模型结构与代码数据集训练,在第二个阶段,Codex 模型的优势显露无疑。“Codex 的出现,让专业程序员们告别了不少令人头痛的苦差事。”
2.2.1 模型结构|在GPT模型上加入额外token
Codex 的模型结构和 GPT 完全一样,为了尽可能地利用 GPT 的文本表示,Codex 使用了和 GPT-3 一样的分词器。但因为代码中词的分布和自然语言中词的分布有很大区别,GPT-3 的分词器在表示代码时可能不是非常有效。Codex 论文显示在 GPT-3 的分词器中加入了额外的一些 token 来表示不同长度的空格,这样在表示代码时可以少使用 30% 的 token。
推理时,使用核采样不断采样 Codex 生成的 token,直到碰见以下字符中的任何一个:"\nclass","\ndef","\n#","\nif" , '\nprint'。这样可以大大减小模型第一和最后一层的参数量。实验证明 Codex 可以通过增加模型规模持续精进。
2.2.2 数据集|用于微调和评测
2.2.2.1 Fine-tuning数据集
首先是用来做 Fine-Tuning 的 code 数据集。在2020年5月,Codex 从 Github 的 54,000,000 个公开代码仓上收集了数据,包括 179 GB 大小在 1 MB 以下的独一无二的 python 文件,在经过过滤后,最终的数据集大小为 159GB。
2.2.2.2 评测数据集
Codex 将生成代码的功能正确性作为评测指标,关注从 docstrings 生成 python 函数的任务,并通过 unit tests 的方法来评测生成代码的正确性。评测指标采用的是 pass@k。评测数据集包含 HumanEval 和 APPS 两个数据集。
HumanEval 构建了一个包括164个人工手写的编程问题的数据集,其中每个编程问题包括函数头、docstrings、函数体和几个 unit tests。HumanEval 中的编程问题可以用来评估语言理解能力、推理能力、算法能力和简单的数学能力,该数据集已经开源。人工手写是非常重要的:因为如果直接从网上找,比如说从 leetcode 上去扒,很有可能导致数据穿越。
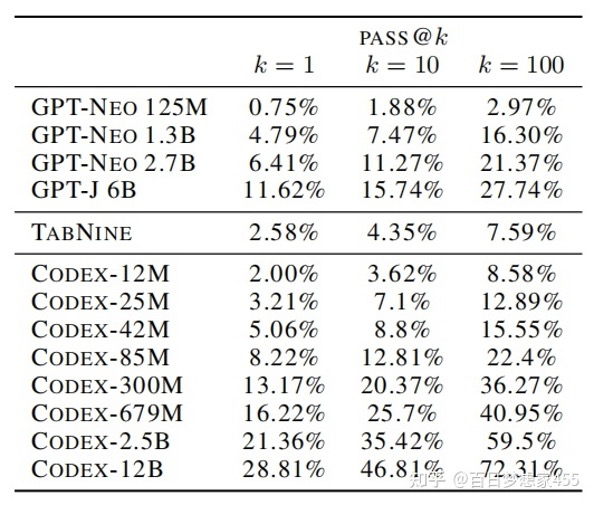
Codex、GPT-Neo、GPT-J 和 TabNine 在 HumanEval 上的实验结果对比如下图所示,可以发现 Codex-300M 的效果优于 GPT-J 6B。
2.2.3评估框架
主流的Seq2seq任务的评估框架是BLEU score,然而,这是一种模糊匹配的相似度衡量,对于代码生成任务,哪怕错一个字符,就会带来完全不同的结果,因此,作者提出了一种用于评估Python代码生成的指标,即Pass@K,其定义如下:

大概意思是在生成的k个答案中,只要有一个能够执行正确就算对。而且,在验证时,作者手工进行书写标注了一个新的数据集,这是因为网上的数据很有可能都在训练集中,下图举了几个自己标注的数据集示例:

2.3 codex模型变种
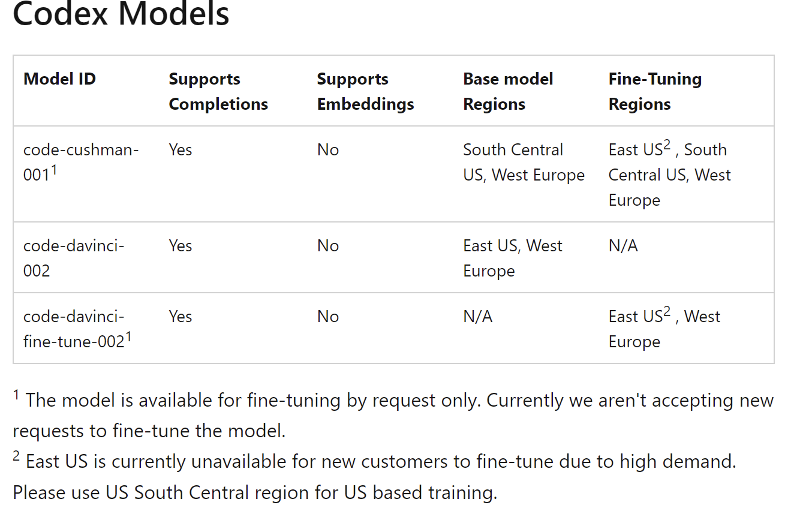
CodeX:在所有Github上公开的Python文件上进行训练,由docstring生成对应的函数;Codex 擅长 Python,精通十多种语言,包括c#、JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL 和 Shell。Codex 的模型包含:code-davinci-002、code-cushman-001(按能力大小排列)。
CodeX-S:在CodeX基础上,选取了一些高质量、独立的函数模型进行Fine-tune,也是做由docstring生成对应的Python函数代码的任务;
CodeX-D:与CodeX任务相反,由Python函数代码生成docstring。
2.3.1 davinci
与 GPT-3 类似,Davinci 是最强大的 Codex 模型,可以执行其他模型能够执行的任何任务,而需要更少的指令。对于需要深入理解内容的应用程序,Davinci 可以产生最好的结果。更强大的功能需要更多的计算资源,因此 Davinci 的成本更高,速度也不如其它模型。
2.3.2 cushman
很强大,同时速度很快。当谈到分析复杂任务时,Davinci 更强,而 Cushman 是许多代码生成任务的能干模型。Cushman 通常也比 Davinci 跑得更快、更便宜。
2.4 应用场景实例
Codex 模型主要应用在IT科技部门的代码研发流程自动化上。
2.4.1编写程序
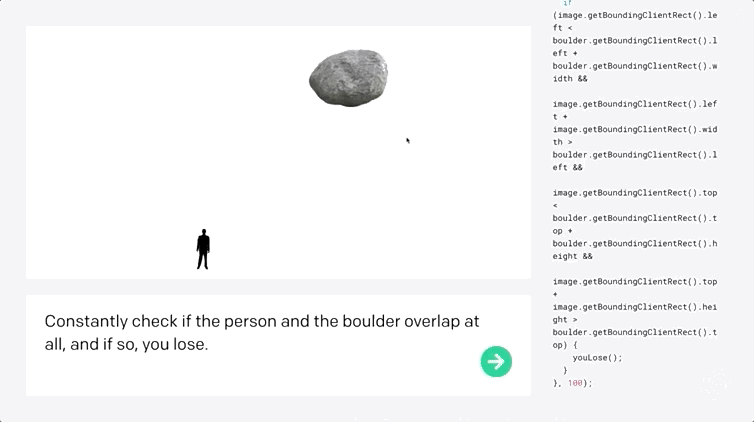
比如开发小游戏,准确率高达72%!Codex 不仅能够收到指令后自行编程,还能够开发小游戏。
2.4.2辅助编程
微软、OpenAI、GitHub 联合推出了自动代码生成 AI Copilot,Copilot 能够在用户输入过程中随时提供补全代码行内容的建议。
2.5 相关影响
只能处理简单问题,训练代价巨大,文档越长生成效果越差
过度依赖
与实际需求不匹配
男性偏见(Github男性用户居多)
程序员失业
安全隐患(用来写病毒程序)
环境影响(训练耗电)
法律问题(照抄别人的商业代码毫不知情)
3 aiXcoder
aiXcoder是国内首款已商业化落地的AI智能编程系统,基于当前SOTA的代码大模型,不仅可通过自然语言实现方法级代码生成,还能完成整行及多行的智能代码补全
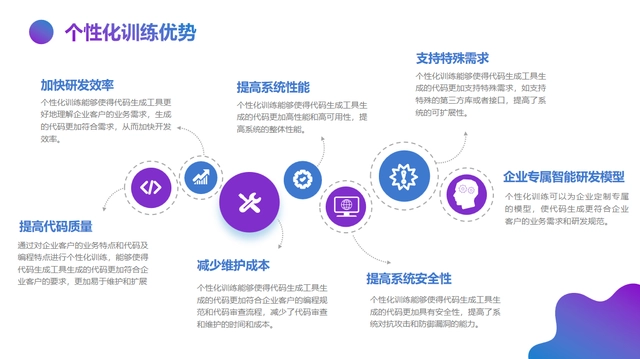
在免费服务个人开发者的同时,aiXcoder同步推出企业级智能开发应用——aiXcoder「企业版」。aiXcoder「企业版」核心优势在于可进行私有化部署,并对企业代码进行个性化训练,进一步提升企业研发效率和代码质量,助力企业快速响应市场需求
企业私有化部署:
在企业内部环境下,用基于Docker的容器化技术配置好运行环境后,将aiXcoder的整套软件(包括大模型和代码)部署在企业内网的深度学习服务器上。在不连外网的情况下,企业也能使用aiXcoder提供的智能编程服务,保障企业信息及代码安全
企业个性化训练:
是指对企业内部代码进行数据处理、增量训练,通过学习企业内部代码编程模式,最终得到个性化训练后的企业版新模型。新模型与原模型相比,更贴近企业实际项目应用场景,在企业内部使用时,预测准确性将得到提升