?发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。
在现代软件开发中,日志系统是至关重要的组成部分。它们不仅用于故障排查和性能监控,还可以提供关键业务洞察。本文将介绍如何利用ELK(Elasticsearch、Logstash和Kibana)与Fluentd结合,构建一个高效的分布式日志系统,并提供Python案例代码来演示其用法。
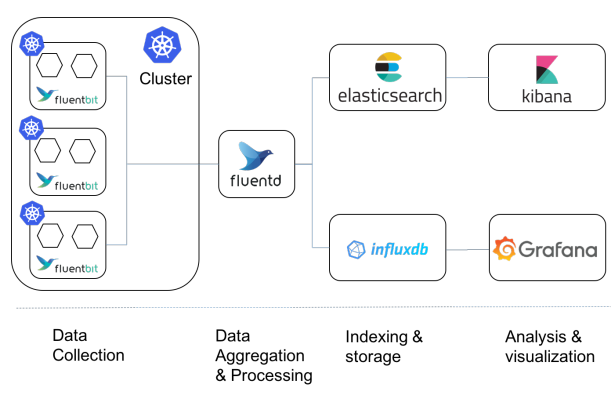
什么是ELK和Fluentd?
ELK Stack:ELK是一个流行的日志管理解决方案,由三个核心组件组成:
Elasticsearch:用于存储和索引日志数据的分布式搜索引擎。Logstash:用于日志收集、过滤和转发的数据处理管道。Kibana:提供日志数据的可视化和分析工具。Fluentd:Fluentd是一款开源的数据收集器,可以轻松地收集、转换和转发日志数据。它支持多种输入和输出插件,具有高度灵活性和可扩展性。

构建分布式日志系统的步骤
1. 安装和配置ELK Stack
安装Elasticsearch:根据官方文档安装Elasticsearch,并确保其运行在你的环境中。安装Logstash:下载并安装Logstash,并配置输入和输出插件以连接到Fluentd。安装Kibana:安装Kibana并与Elasticsearch集成,以便可视化日志数据。2. 配置Fluentd
安装Fluentd:安装Fluentd并确保其可用于收集日志数据。配置输入插件:配置Fluentd的输入插件以接收日志数据,例如HTTP、TCP或UDP输入插件。配置输出插件:配置Fluentd的输出插件以将日志数据发送到Elasticsearch,这样数据就可以被索引和存储。3. 编写Python应用程序
下面是一个简单的Python示例代码,演示如何在Python应用程序中记录日志并将其发送到Fluentd。
import loggingimport fluent.handler# 配置日志记录器logger = logging.getLogger('example')logger.setLevel(logging.DEBUG)# 创建Fluentd处理程序fluent_handler = fluent.handler.FluentHandler('myapp', host='fluentd_host', port=24224)# 设置日志处理程序的日志级别fluent_handler.setLevel(logging.DEBUG)# 将Fluentd处理程序添加到日志记录器中logger.addHandler(fluent_handler)# 记录一些日志logger.debug('This is a debug message')logger.info('This is an info message')logger.warning('This is a warning message')logger.error('This is an error message')logger.critical('This is a critical message')4. 查看日志数据
启动你的Python应用程序并生成日志。使用Kibana连接到Elasticsearch,并配置索引模式以查看日志数据。探索和分析日志数据,以获得有关应用程序性能和行为的洞察。5. 高级配置和优化
数据格式化:在Fluentd配置中,你可以使用过滤器来格式化日志数据,以便更好地适应你的需求。例如,可以使用Fluentd的Record Modifier插件来添加额外的字段或重新命名现有字段。
性能优化:对于高流量的环境,可以考虑使用Fluentd的缓冲机制来缓冲和批量发送日志数据,以减少网络开销和提高性能。此外,可以通过合理配置Elasticsearch集群和索引策略来优化数据的存储和检索性能。
安全性配置:在配置ELK和Fluentd时,务必考虑安全性。确保所有组件都受到适当的访问控制,并使用加密来保护数据在传输过程中的安全性。此外,可以考虑使用认证和授权机制来限制对日志数据的访问。
6. 监控和维护
监控系统状态:定期监控ELK和Fluentd的系统状态和性能指标,以便及时发现并解决潜在的问题。可以使用监控工具如Prometheus和Grafana来实现这一目的。
定期维护:定期对ELK和Fluentd进行维护,包括升级软件版本、清理日志数据、优化索引等操作,以确保系统的稳定性和可靠性。
故障排除:当出现日志系统故障时,需要及时进行排查和修复。可以通过查看日志、监控指标和分析数据来定位问题,并采取相应的措施解决。
7. 容错和可伸缩性
容错机制:在设计分布式日志系统时,考虑引入容错机制以确保系统的稳定性和可用性。可以使用Fluentd的插件来实现故障转移和自动恢复功能,以及在Elasticsearch集群中配置副本来保证数据的可靠性。
水平扩展:随着应用程序规模的增长,日志系统也需要能够水平扩展以应对更高的数据流量。通过在Fluentd和Elasticsearch中采用集群和分片的方式,可以实现系统的水平扩展,从而提高性能和容量。
8. 自动化部署和管理
自动化部署:利用自动化工具如Ansible、Chef或Docker来自动化部署和配置ELK和Fluentd组件,以减少手动操作并确保环境的一致性。
自动化监控和警报:设置监控和警报系统来实时监测日志系统的状态和性能,并在出现异常情况时及时通知运维团队进行处理。
9. 进一步的集成和扩展
与其他系统集成:除了Python应用程序外,还可以将ELK和Fluentd集成到其他类型的应用程序和系统中,如Java、Node.js、Docker容器等,以实现全面的日志管理和监控。
添加附加功能:根据特定的业务需求,可以考虑添加附加功能和插件来扩展日志系统的功能,如日志审计、实时警报、数据分析等。
在Python应用程序中集成Fluentd来发送日志数据到ELK Stack
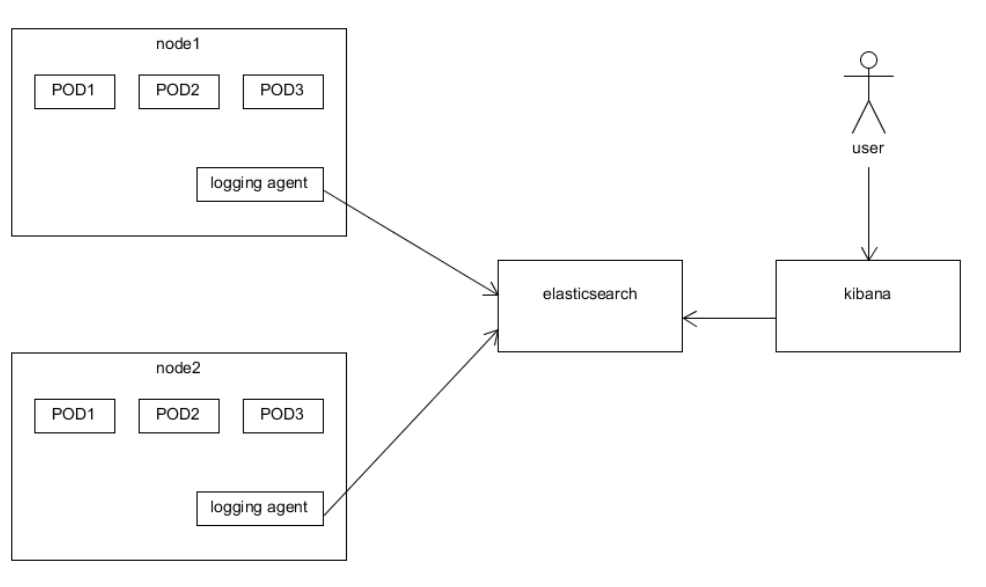
首先,确保在你的系统中已经安装并配置好了Fluentd、Elasticsearch和Kibana。然后,按照以下步骤进行操作:
步骤 1:安装必要的库
确保安装了 fluent-logger 库,它是用于在Python中发送日志到Fluentd的库。
pip install fluent-logger步骤 2:配置Fluentd
在Fluentd的配置文件中,添加输入插件以接收Python应用程序发送的日志,并配置输出插件以将日志数据发送到Elasticsearch。
# fluentd.conf<source> @type forward port 24224</source><match **> @type elasticsearch host localhost port 9200 index_name fluentd type_name fluentd</match>
步骤 3:在Python应用程序中发送日志
使用以下示例代码,在你的Python应用程序中记录日志并发送到Fluentd。
import loggingfrom fluent import sender# 配置日志记录器logger = logging.getLogger('example')logger.setLevel(logging.DEBUG)# 配置Fluentd发送器fluent_sender = sender.FluentSender('myapp', host='localhost', port=24224)# 创建自定义日志处理程序class FluentHandler(logging.Handler): def emit(self, record): log_entry = self.format(record) fluent_sender.emit('app.logs', log_entry)# 将自定义日志处理程序添加到日志记录器中logger.addHandler(FluentHandler())# 记录一些日志logger.debug('This is a debug message')logger.info('This is an info message')logger.warning('This is a warning message')logger.error('This is an error message')logger.critical('This is a critical message')# 关闭Fluentd发送器fluent_sender.close()步骤 4:查看日志数据
启动你的Python应用程序并生成日志。然后,使用Kibana连接到Elasticsearch,并配置索引模式以查看日志数据。你应该能够在Kibana中看到你的日志数据,并对其进行分析和可视化。
通过这些步骤,你已经成功地构建了一个将日志数据从Python应用程序发送到ELK Stack的分布式日志系统。通过调整和优化Fluentd和ELK的配置,你可以进一步提高系统的性能和可靠性,以满足你的特定需求。
步骤 5:增加日志格式化和字段
在实际应用中,你可能需要对日志进行格式化,并添加额外的字段以提供更多的上下文信息。下面是如何在Python应用程序中实现这一点:
import loggingfrom fluent import sender# 配置日志记录器logger = logging.getLogger('example')logger.setLevel(logging.DEBUG)# 配置Fluentd发送器fluent_sender = sender.FluentSender('myapp', host='localhost', port=24224)# 创建自定义日志处理程序class FluentHandler(logging.Handler): def emit(self, record): log_entry = self.format(record) extra_fields = {'custom_field': 'value'} # 添加自定义字段 log_entry.update(extra_fields) fluent_sender.emit('app.logs', log_entry)# 将自定义日志处理程序添加到日志记录器中logger.addHandler(FluentHandler())# 设置日志格式formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')logger.handlers[0].setFormatter(formatter)# 记录一些日志logger.debug('This is a debug message')logger.info('This is an info message')logger.warning('This is a warning message')logger.error('This is an error message')logger.critical('This is a critical message')# 关闭Fluentd发送器fluent_sender.close()在这个示例中,我们通过 extra_fields 添加了一个自定义字段,并更新了日志条目。你可以根据实际需求添加更多的字段,以便在Kibana中更好地分析和理解日志数据。
进一步优化和扩展
在构建分布式日志系统时,除了基本的功能外,还有许多进一步的优化和扩展可以考虑,以满足特定的需求和场景。
日志级别过滤
有时候,你可能只想记录特定级别以上的日志。你可以在Fluentd的配置中添加过滤器来仅转发满足条件的日志。例如,只转发警告级别以上的日志:
<match app.logs> @type relabel @label @warn</match><label @warn> <filter **> @type grep regexp1 level warning|error|critical # 只接受警告、错误和严重级别的日志 </filter> <match **> @type elasticsearch host localhost port 9200 index_name fluentd type_name fluentd </match></label>
日志数据采样
在高流量的环境中,为了减少存储和处理成本,可以考虑采样部分日志数据。在Fluentd中,你可以使用采样插件来实现这一点,例如 sampling 插件。
实时警报和监控
除了存储和分析日志数据外,你可能还希望实时监控系统状态并设置警报。可以利用ELK Stack的Watcher功能或者其他监控工具来实现这一点,当系统出现异常情况时即时通知相关人员。
日志数据的生命周期管理
随着时间的推移,日志数据可能会变得庞大且不再需要保留所有的历史数据。可以考虑设置数据的生命周期管理策略,定期清理和归档旧的日志数据,以节省存储空间并提高检索性能。
数据安全和隐私保护
对于敏感数据,例如用户个人信息或支付信息,必须采取额外的安全措施来保护数据的安全和隐私。在日志系统中,可以使用加密、授权和审计机制来确保数据的安全性和合规性。
通过这些进一步的优化和扩展,你可以构建一个更加强大、灵活和安全的分布式日志系统,以满足不断变化的业务需求和挑战。
总结
在本文中,我们探讨了如何构建一个高效的分布式日志系统,通过结合ELK(Elasticsearch、Logstash和Kibana)与Fluentd这两个强大的工具。我们首先介绍了ELK Stack和Fluentd的基本概念和功能,然后提供了详细的步骤和示例代码来展示如何在Python应用程序中集成Fluentd,将日志数据发送到ELK Stack进行存储和分析。
通过结合ELK和Fluentd,我们可以获得许多优势,包括:
实时监控和分析:ELK Stack提供了强大的实时监控和分析功能,可以帮助我们及时发现并解决问题。灵活的日志收集和转发:Fluentd具有灵活的插件系统,可以轻松地收集、转换和转发各种类型的日志数据。可视化和洞察:Kibana提供了直观且强大的可视化工具,可以帮助我们深入理解日志数据,并从中获取有价值的洞察。除了基本功能外,我们还介绍了一些进一步优化和扩展的方法,如日志级别过滤、数据采样、实时警报和监控、数据生命周期管理以及数据安全和隐私保护。这些技术可以帮助我们构建一个更加强大、灵活和安全的日志系统,以满足不断变化的业务需求和挑战。
最后,我们强调了持续学习和实践的重要性,只有不断探索新技术和最佳实践,我们才能构建出更加智能、高效和可靠的分布式日志系统,为用户提供更好的体验和服务。