
目录
目录
前言:
文档借鉴:Reference - C++ Reference
1.deque
a.deque的结构特点:
b.deque的迭代器结构:
c.面试题:
2.stack
3.queue
4.仿函数
5.priority_queue
6.头文件的包含注意问题
前言:
本篇一共简单实现3个容器,其中stack和queue的底层适配器是deque,所以会先介绍一下deque,而对于优先级队列priority_queue就是使用堆实现的,库中底层适配器是vector,另外对于优先级队列中堆的调整还会使用仿函数进行比较,所以本篇还会简单介绍一下仿函数。
文档借鉴:Reference - C++ Reference
1.deque
a.deque的结构特点:

deque简单来说就是vector和list的合体,再来复习一下vector和list的优缺点:
我们再开看看deque的结构:
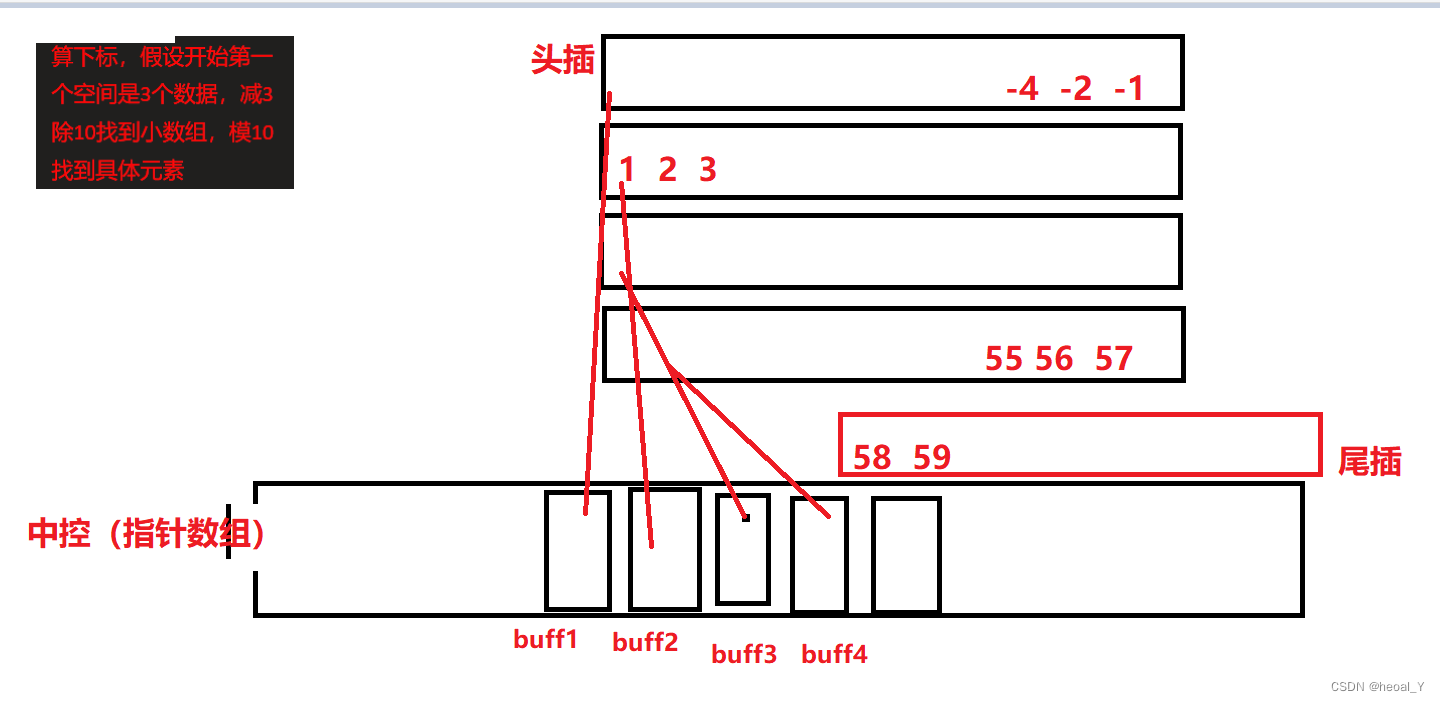
deque是存储在一个指针数组里面的,从中间开始存小的buff数组(指针数组里面存放的是指针,每个指针指向小的数组),这样头插尾插相比vector就方便了,当中控满了才扩容,扩容代价低是因为是指针数组,扩容只需要扩指针指向的空间就行。
所以deque的优缺点就是:
优点:
1.相比vector,扩容的代价低。
2.头插头删,尾插尾删效率高。
3.也支持随机访问。
缺点:
1.中间插入数据很难搞,如果想要中间插入数据效率高,可以控制每个buff小数组的大小不一样,从而挪动数据的消耗少,但小数组大小不一样随机访问就麻烦了;反过来,如果小数组固定数据,随机访问的效率就高了,但是中间插入数据就慢了,sgi版本采用数据固定,二者都可以,很灵活。
2.没有vector和list优点极致。
应用:
一般引用于栈和队列的底层容器,对于数据多的情况也差不多,高速缓存效率也可以,避免内存碎片化。
顺便一提,对于100万个数据进行排序,都不如vector排序后再拷贝回来速度快: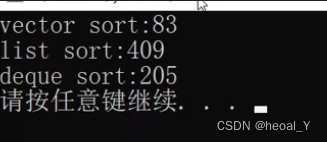
b.deque的迭代器结构:
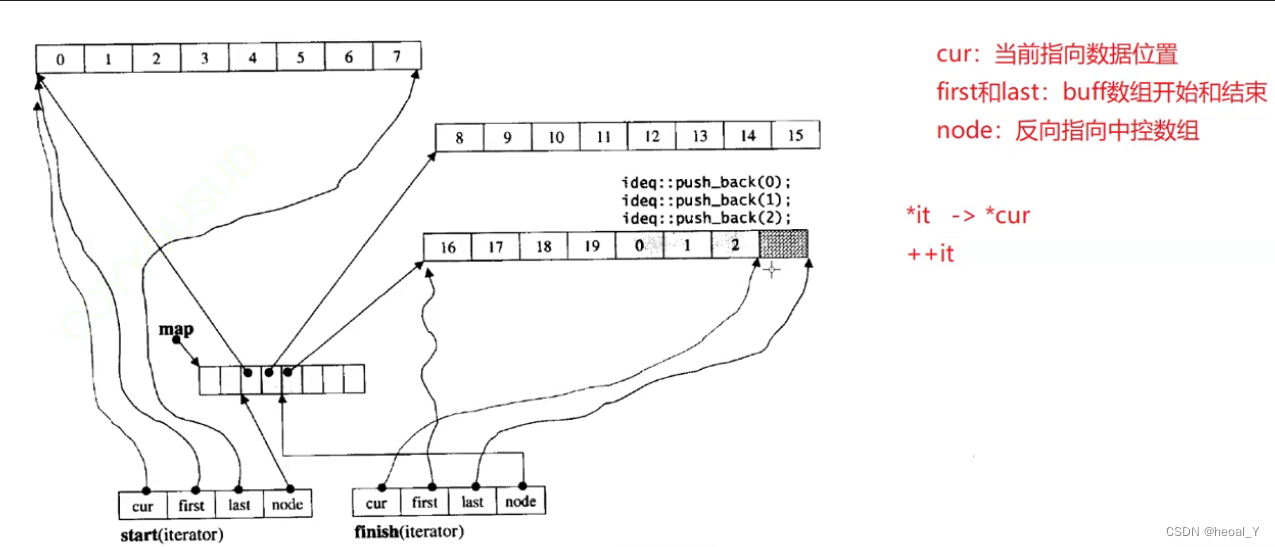
c.面试题:

遍历时频繁检测是否移动到某段小空间的边界了,意思就是需要遍历每个buff小数组,导致效率低下。
注意stack和queue没有迭代器,所以不能使用迭代器遍历。
2.stack
#pragma oncenamespace my_stack{template<class T,class Container=deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};void testStack1(){stack<int, vector<int>> s1;s1.push(1);s1.push(2);s1.push(3);s1.push(4);while (!s1.empty()){cout << s1.top() << " ";s1.pop();}cout << endl;}}3.queue
#pragma oncenamespace my_queue{template<class T,class Container=deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front(){return _con.front();}const T& back(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};void testQueue1(){queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);while (!q.empty()){cout << q.front() << " ";q.pop();}cout << endl;}}需要注意的就是queue不能用vector当适配器,vector没有头插头删(因为效率低下),如果非要使用就要用vector的insert与erase,但是需要挪到数据,效率低下。
4.仿函数

由于仿函数大多是对()进行的运算符重载,所以实际使用看着像函数名,就叫仿函数了,
可以替换函数指针。
5.priority_queue


可以看到文档中就是使用heap也就是堆来模拟的。
#pragma oncenamespace my_priority_queue{template<class T>struct Less{bool operator()(const T& x, const T& y){return x < y;}};template<class T>struct Greater{bool operator()(const T& x, const T& y){return x > y;}};template<class T,class Container=vector<T>,class Compare=Less<T>>//默认小堆class priority_queue{public:void Adjust_up(size_t child){size_t parent = (child - 1) / 2;while (child > 0){if (Compare()(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) * 2;}else{break;}}}void Adjust_down(size_t parent){size_t child = parent * 2 + 1;//假设左孩子小while (child < _con.size()){if (child + 1 < _con.size() && Compare()(_con[child], _con[child+1]))//这里注意不同的仿函数,参数中左右孩子的顺序需要交换{++child;}if (Compare()(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void push(const T& x){_con.push_back(x);Adjust_up(_con.size() - 1);}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();Adjust_down(0);}size_t size(){return _con.size();}bool empty(){return _con.empty();}const T& top(){return _con[0];}private:Container _con;};void test_priority_queue(){priority_queue<int, vector<int>, greater<int>> pq;//priority_queue<int> pq;//priority_queue<int,deque<int>> pq;//容器适配器pq.push(1);pq.push(0);pq.push(5);pq.push(2);pq.push(1);pq.push(7);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;}}根据在堆的向上向下调整中,往仿函数中传的参数先后是parent与child,所以Less就是建小堆 (因为父亲小就交换到下面了,最后是升序),Greater就是建大堆。但是要注意左右孩子的比较,对于不同的仿函数需要传不同的左右孩子的顺序,反正记住左孩子小就++左孩子,找最小的孩子。
使用了匿名对象来进行仿函数的调用。
对于优先级队列的删除数据:

是删除top也就是队列头数据,所以是先交换堆的首尾,再删除尾,再向上调整即可。(交换再删除防止直接删使堆变乱)。
6.头文件的包含注意问题
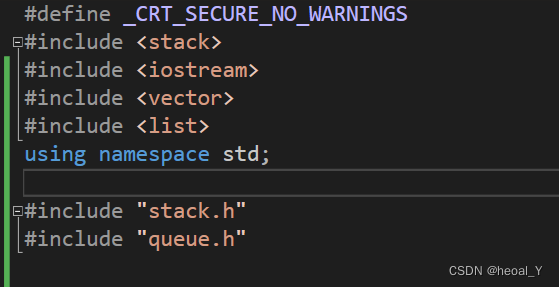
这样包含头文件,在遇到"stack.h"和"queue.h"时会展开,向上找,就能找到这里个头文件中内容需要使用的头文件,并且头文件是不会编译的,而是直接展开,所以在stack和queue头文件中不写需要的头文件也不会报错。
但是需要注意的是,std命名空间的展开不能写在头文件的下面,不让头文件展开后找不到库会报错。