目录
前言
项目背景
数据集
设计思路
神经网络
LSTM网络结构
实验环境
实验结果分析
更多帮助
前言
?大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
?对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
?基于深度学习的驾驶员分心行为检测系统
项目背景
随着汽车行业的快速发展,驾驶员分心行为已经成为导致交通事故的重要因素之一。因此,开发一种能够实时检测驾驶员分心行为的系统具有重要的实际意义。基于深度学习的驾驶员分心行为检测系统,通过利用卷积神经网络等深度学习技术,可以实现对驾驶员分心行为的准确检测。此课题的研究对于促进智能交通技术的发展,提高道路安全,具有重要意义。
数据集
由于网络上没有现有的合适的数据集,我决定自己去拍摄视频,收集驾驶员行为数据并制作了一个全新的数据集。这个数据集包含了各种驾驶员行为的视频,其中包括正常驾驶、分心驾驶等行为。通过现场拍摄,我能够捕捉到真实的驾驶员行为和多样的驾驶环境,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为驾驶员分心行为检测研究提供有力的支持,并为该领域的发展做出积极贡献。

数据扩充是提高模型鲁棒性和泛化能力的重要手段。在本研究中,我们对收集到的驾驶员行为视频数据进行了多样化的数据扩充。包括使用视频剪辑、颜色变换、添加噪声等方法来生成新的训练样本。这些扩充后的数据能够帮助模型更好地学习和理解驾驶员行为的复杂性,提高模型在实际应用中的表现力。同时,数据扩充还可以增加模型的泛化能力,使其在面对未见过的数据时仍能保持良好的性能。

设计思路
神经网络
针对个体分心驾驶行为风险的预测问题,提出了一个模块化插件式神经网络,称为驾驶行为风险预测神经网络(DBRPNN)。该网络由特征处理模块(FPM)、记忆模块(MM)和预测模块(PM)组成。FPM负责对历史车辆或道路的分心驾驶行为风险等级进行分级和标准化,而MM利用LSTM捕捉风险等级变化的时间依赖性。最后,PM将神经网络的输出转换为风险等级。通过训练映射函数f,可以计算下一时刻车辆或路段的分心驾驶行为风险等级。这种模块化的神经网络方法能够更好地预测个体的分心驾驶行为风险,而不仅仅是计算分心驾驶行为的数量。
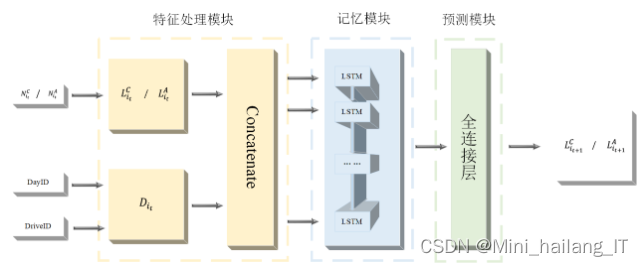
使用层次化的方法将驾驶过程中的风险等级进行分类。采用了K-means++算法对风险等级进行聚类,该算法根据数据特征参数与聚类中心的距离确定样本的类别。在无监督学习中,训练数据没有预先标记的类别信息,聚类算法旨在通过学习无标记数据的内在特征和规律,将样本划分为不相交的簇。K-means算法的目标是最小化平方误差,通过迭代优化来近似求解最优解。而K-means++算法则改进了初始聚类中心的选择,使其分散开,避免陷入局部最优解或收敛缓慢的情况。通过这种层次化的聚类方法,可以将驾驶行为的风险等级进行有效分类。
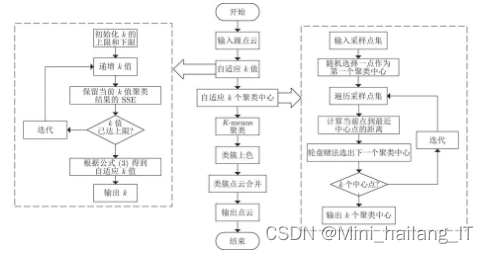
根据历史上的分心驾驶行为数据,按照不同的时间间隔对每辆车的行为数量进行汇总,并使用K-means++算法将其聚类为三个风险等级(0、1、2)。同样地,根据分心驾驶行为发生点将路段划分,并计算每个路段内车辆分心驾驶行为的平均数量。再次使用K-means++算法将路段的行为平均数量聚类为三个风险等级。风险等级0表示低风险状态,无需采取行动;风险等级1表示中等风险状态,根据情况采取相应措施;风险等级2表示高风险状态,需要立即采取措施。通过这种方法,可以对车辆和道路的分心驾驶行为进行风险评估和等级划分。
LSTM网络结构
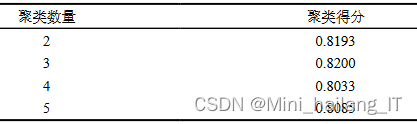
在交通预测中采用了基于图的模型,因为空间相关性对交通状况有很大影响。传统的图模型常用邻接矩阵和拉普拉斯矩阵来表示图结构,而经典的图卷积网络(GCN)通过编码节点之间的相邻关系来表示图。然而,在实时的交通预测中,时间上的依赖性也需要被考虑。本文通过将网格作为节点来初始化GCN,并定义了两个图来权衡边的连接关系,包括k阶连接图和道路连接图。基于图的分心驾驶风险预测模型,以解决交通预测中空间相关性和道路连接关系的问题。模型利用GCN来表示图结构,并通过初始化节点和定义邻接矩阵、拉普拉斯矩阵以及道路连接矩阵来捕捉空间关系和道路连接关系。同时,模型考虑了时间上的依赖性,动态地分析网格之间的相关性。通过综合考虑空间和时间特征,该模型能够更准确地预测分心驾驶行为的风险。
在分心驾驶风险预测中,网络的输出需要与当前时刻的输入以及过去一段时间的输出相连。为了处理时间序列数据并具有短期记忆能力,循环神经网络(RNN)被广泛应用。RNN的神经元可以接收来自其他神经元以及其自身的信息,形成一个循环网络结构。然而,基本RNN存在梯度弥散问题,这个问题被长短时记忆(LSTM)神经网络成功解决。LSTM通过增加一个新的内部状态和门控机制相对于基本RNN进行了增强。这样的改进使得LSTM能够更准确地表征时间序列数据,进而提升分心驾驶风险预测的性能。
LSTM(长短时记忆)是一种循环神经网络的变体,其关键在于其特殊的循环单元结构。LSTM的循环单元结构包括以下四个主要组成部分:
输入门(Input Gate):输入门决定是否将新的输入信息纳入到记忆中。它通过使用sigmoid函数来控制输入的权重,将输入值与先前的记忆结合起来。遗忘门(Forget Gate):遗忘门决定是否将先前的记忆保留下来。它通过使用sigmoid函数来控制遗忘的权重,决定将多少记忆保留下来。细胞状态(Cell State):细胞状态是LSTM的记忆部分,用于存储和传递信息。它可以被更新和重置,以便保留或丢弃相关信息。输出门(Output Gate):输出门决定从细胞状态中提取多少信息并输出到下一个时间步。它通过使用sigmoid函数来控制输出的权重,并使用tanh函数来规范化细胞状态。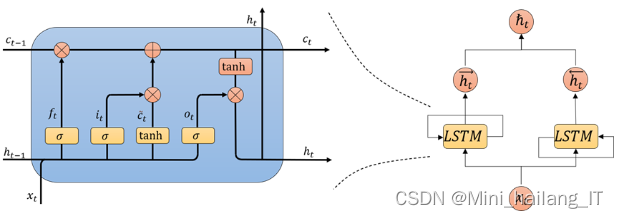
实验环境
DBRPNN是基于AI平台PyTorch 3.9构建的分心驾驶行为识别模型。该模型在训练过程中使用了一台配备Intel Core i5 CPU和Graphics 630的计算机,并在Windows 10操作系统上运行。PyTorch是一个广泛用于深度学习的开源框架,它提供了丰富的工具和函数来构建、训练和评估神经网络模型。使用PyTorch构建DBRPNN模型可以充分利用其灵活性和易用性,从而更高效地实现分心驾驶行为的识别。计算机配备的Intel Core i5 CPU和Graphics 630为训练提供了一定的计算能力和图形处理能力,有助于加速训练过程和提升模型性能。
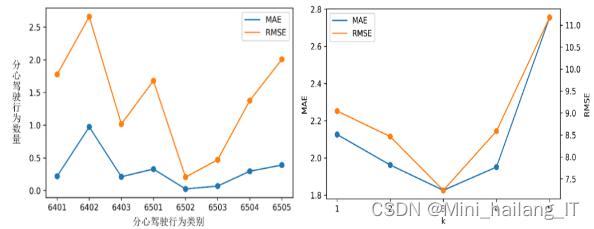
实验结果分析
在训练过程中,DBRPNN模型使用了交叉熵作为损失函数,这是一种常用于分类任务的损失函数。优化器选择了Adam,它是一种自适应学习率的优化算法,能够有效地更新模型参数以最小化损失函数。学习率被设置为0.01,用于控制每次参数更新的步长。为了进行高效的训练,批处理量被设置为64,即每次从训练数据中选择64个样本进行参数更新。模型的训练迭代次数(EPOCH)被设置为100,这是指将训练数据集中的样本全部用于训练的次数。
为了避免过度拟合,采用了早期停止(Early Stopping)方法来控制迭代次数。当损失函数不再改善或EPOCH达到100时,训练过程结束,以防止模型在训练数据上过度拟合。评估网络性能的指标包括准确率和加权精确率。准确率表示预测正确的样本占总样本的百分比,用于评估整体分类准确性。对于三级分类任务,需要计算每个级别的精确率并进行加权计算。精确率是指预测为阳性的实际样本的百分比,用于衡量分类模型在特定类别上的准确性。
相关代码示例:
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropoutfrom tensorflow.keras.optimizers import Adam# 读取数据集data = pd.read_csv("distracted_driving_data.csv")# 分割特征和标签X = data.drop("risk_label", axis=1)y = data["risk_label"]# 数据预处理scaler = StandardScaler()X = scaler.fit_transform(X)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建混合神经网络模型model = Sequential()model.add(Dense(64, activation="relu", input_shape=(X_train.shape[1],)))model.add(Dropout(0.2))model.add(Dense(64, activation="relu"))model.add(Dropout(0.2))model.add(Dense(1, activation="sigmoid"))# 编译模型model.compile(loss="binary_crossentropy", optimizer=Adam(learning_rate=0.001), metrics=["accuracy"])# 训练模型model.fit(X_train, y_train, batch_size=64, epochs=100, validation_data=(X_test, y_test), verbose=2)# 在测试集上进行预测y_pred = model.predict_classes(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print("Accuracy:", accuracy)海浪学长项目示例: