简介
随着大数据时代的到来,尤其是近年来人工智能、深度学习和自然语言处理等领域的发展,非结构化数据呈现出爆炸式增长。传统的数据库技术,诸如关系型数据库,在处理结构化数据时表现卓越,但在面对大量图片、文本、音频等非结构化数据时,由于这些数据不具备固定的模式和表结构,传统方法在理解和处理这些数据时显得力不从心。另外,在类似推荐系统、图像识别、语义搜索等场景下,通常需要快速找出与查询样本最相似的数据,传统数据库面对此类问题时,往往也无效高效处理。
在这种背景下,向量数据库应运而生,其核心理念来源于数据的向量化表示和向量化检索,贝格迈思AiSQL向量数据库通过机器学习模型将复杂的非结构化数据转化为高维空间中的向量,这样原本看似无法直接比较的各类数据就可以用数学上的向量间距离或相似度来进行度量。这一转变意味着数据库不再仅限于管理和检索固定格式的数据,而是能够支持对非结构化数据进行高效的相似性搜索和分析。在检索方面,AiSQL向量数据库利用高效的近似最近邻搜索算法(Approximate Nearest Neighbor Search, ANNS),可在大规模多模态数据集中迅速定位出相似结果。
AiSQL向量数据库应用场景:智能客服
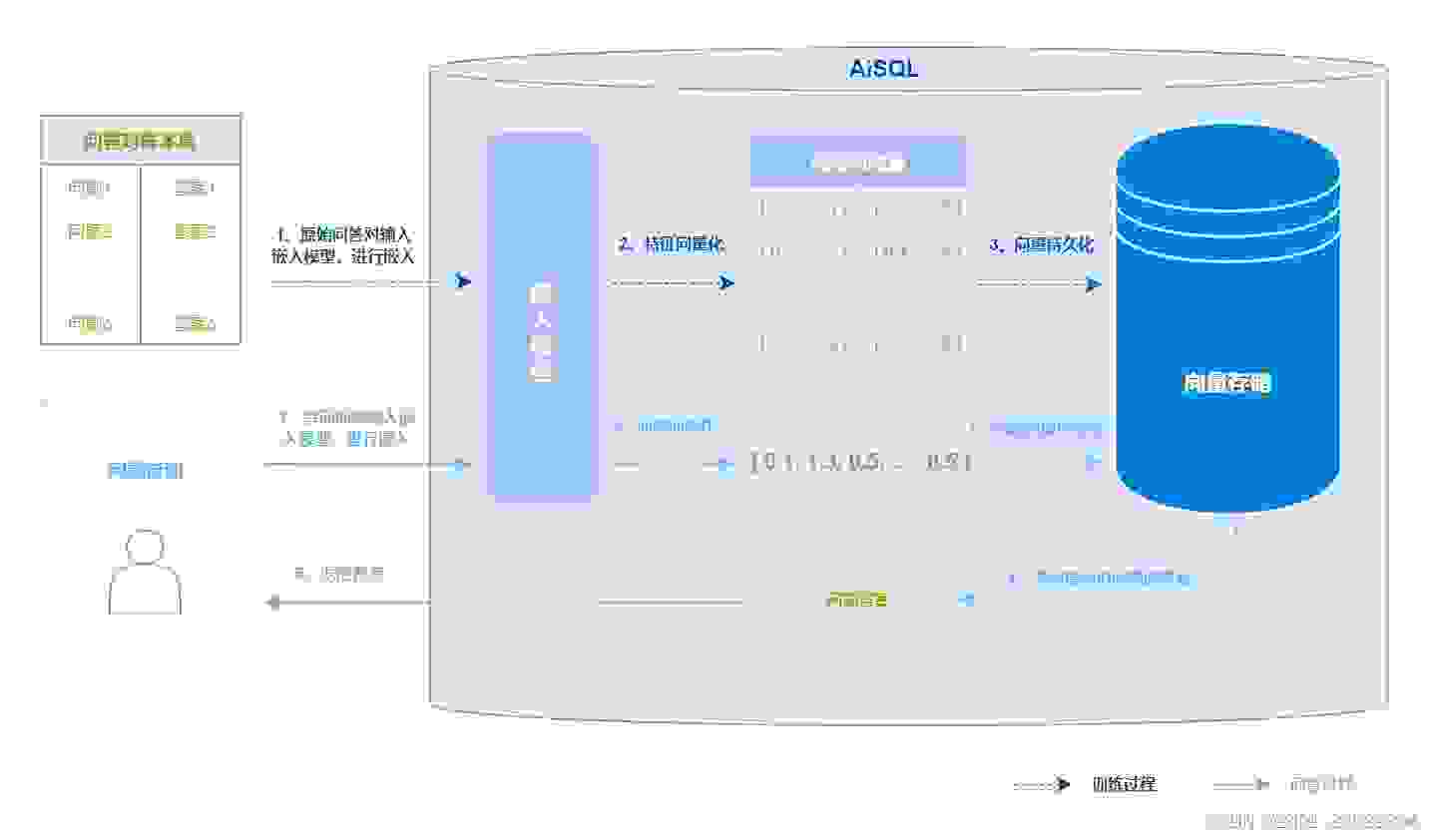
智能客服场景主要包括以下两个过程:
1、 训练过程。首先将原始问题和候选答案集转换为向量表示,这通过Embedding模型实现。每个问题和答案都会被映射为一个固定长度的向量,如图中的[0.1, …, 1]、[0.2, …, 2]等,然后将这些向量持久化存储,这就完成了训练的过程。
2、查询过程。经过第一步,原始问题向量已经生成,在这一步,我们使用相同的嵌入模型将查询问题向量化,然后通过相似度算法找到最相似的原始问题,把对应的答案返回给用户。
这个算是最简单的一个向量数据库使用场景,优点是轻量化,不需要大模型参与,缺点也很明显,答案都是固定的,不够多样化,而且最终只返回一个答案,准确率偏低,适合用于问题差异性大,原始问题集覆盖全面的场景。
一个改进的方法是返回多个问题答案对,提交给大模型,由大模型来组织答案。
AiSQL向量数据库应用场景:图片检索
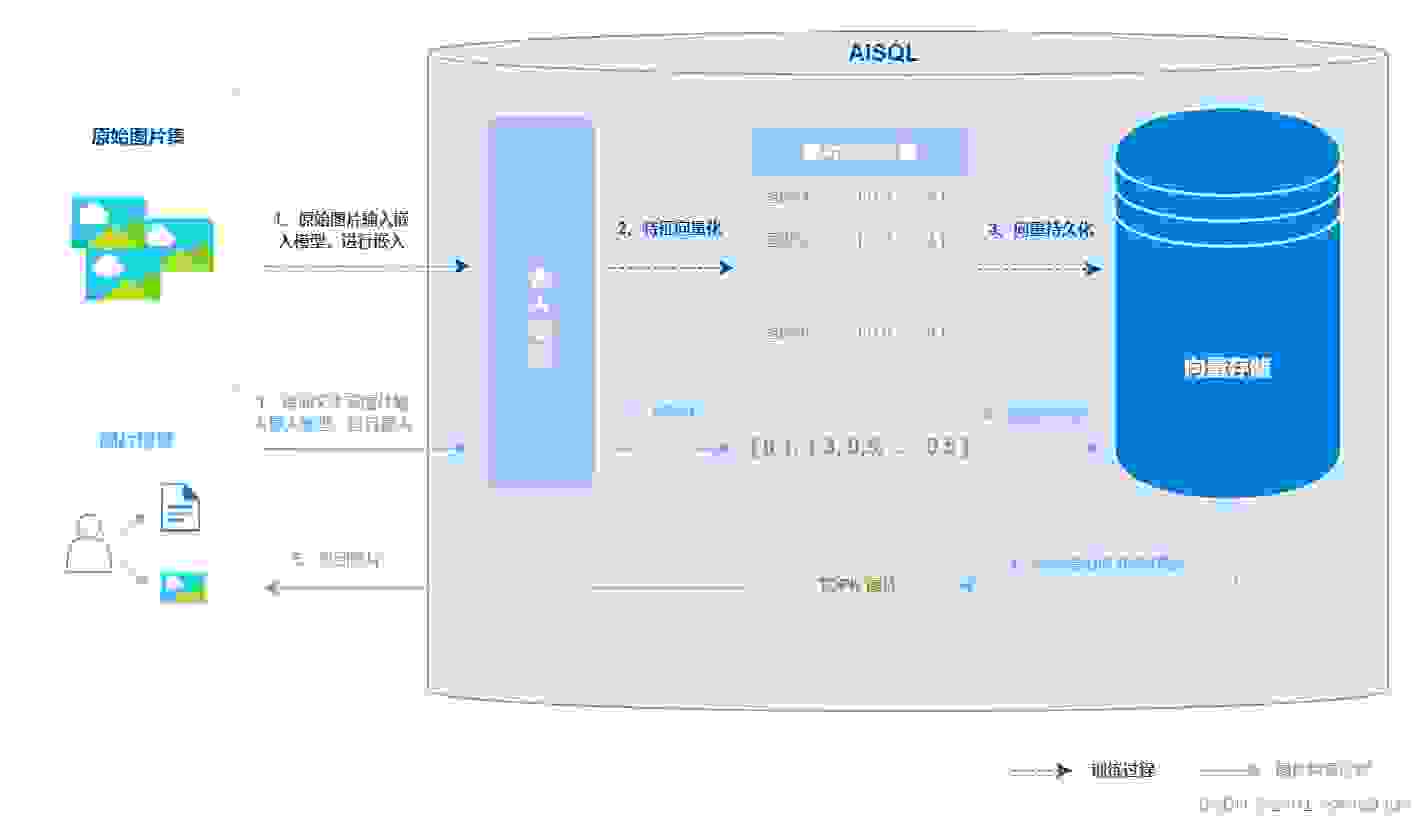
在现实当中,人脸识别、车牌识别、故障检测等技术在生活领域和工业领域都等到广泛的应用,这背后都有向量检索技术的影子。
在使用向量技术进行图片检索时,通常包括以下几个主要步骤:
1、准备原始的图片集合,比如在人脸识别领域,我们需要有用户的人脸数据及用户标签。
2、特征提取模型对原始图片集合进行处理,提取图片的特征向量表示,这里的特征提取模型使用图片的嵌入模型,比如CLIP,然后持久化存储这些向量特征。
3、将用户输入的查询图片按照第二步的方法提取特征向量,与现有的特征向量库进行匹配,找到最相似的图片或图片集合。
4、如果匹配成功(可以设定相似度阈值),则从数据库中检索与匹配图片相关的信息,并返回给用户。
当然,这个流程也可以扩展,如果匹配不成功,则将新上传的图片及其特征向量存储到图片集合和特征库中,以供后续检索使用,在这个过程中,可能需要用户参与,给新图片打标签。
最终,用户可以获得与输入图片最相关的信息,或者为未匹配的新图片贡献了数据,扩充了系统的图像和特征库。
总的来说,这是一个基于内容的图像检索系统,能够快速在大规模图像数据中查找相似图像,同时也支持对新图像的录入和索引,不断丰富系统的图像数据库。
AiSQL向量数据库应用场景:视频检索
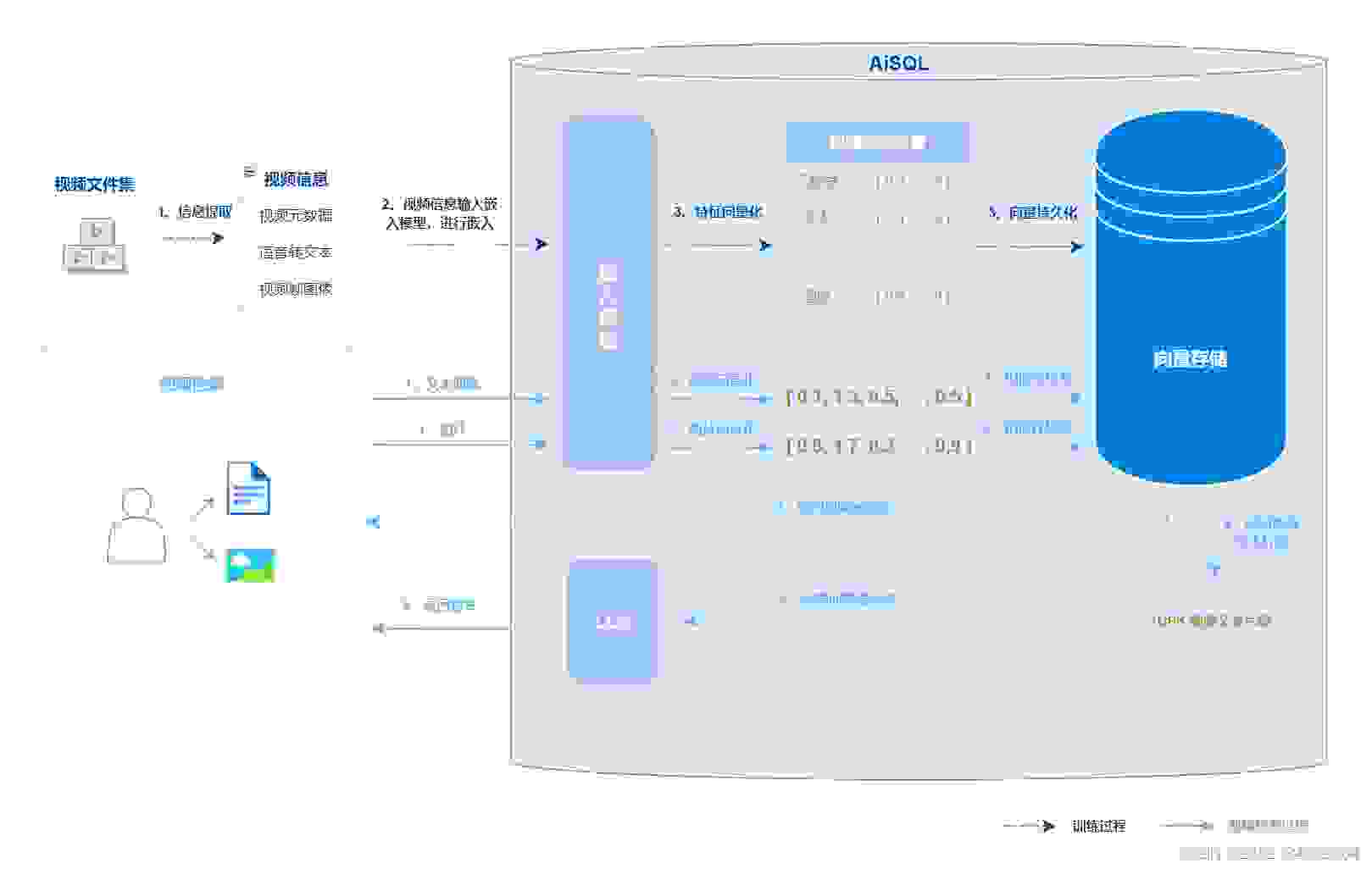
视频检索常见的用例有根据截图找视频、根据简介或者台词找电影、个性化视频推荐等;
视频检索主要包括以下几个步骤:
1、准备一个原始的视频集合用于训练。
2、系统对视频信息进行提取,包括视频元数据(标题、描述等文本信息)、语音的文本内容及视频帧图像。
3、将提取的信息输入到多模态特征提取模型中,该模型能够从视频的不同模态(文本、图像等)中提取特征向量表示。
4、基于提取的特征向量,将用户的查询与现有视频向量库进行匹配,得到与查询最相关的视频或者视频推荐列表。另外,如果用户输入查询文本,系统还可以把查询文本当成问题,从语音文本的上下文寻找答案。
AiSQL向量数据库应用场景:音频检索
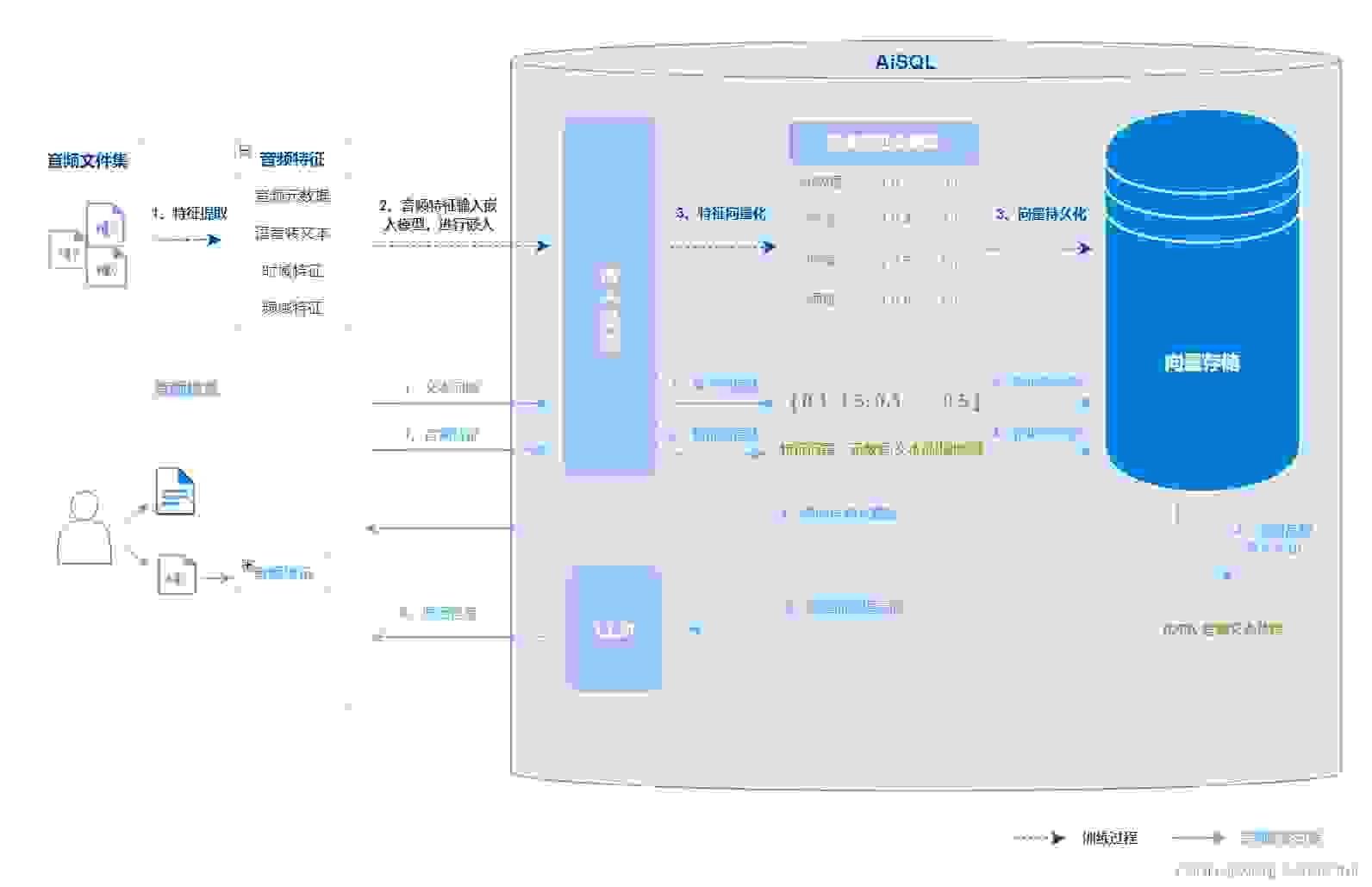
音频检索的应用领域包括语音识别、音乐识别、音乐推荐等。
音频检索包括以下几个主要步骤:
1、准备原始音频集合及对应的元数据供查询,系统会对音频数据进行预处理,提取音频特征,如时域特征、频谱特征、语音文本信息等。
2、将提取的各种特征及元数据输入到Embedding模型中,将音频映射为向量表示,得到音频的特征向量并将其持久化存储。
3、将查询音频的特征向量与现有音频特征向量库进行匹配,根据向量相似性计算匹配分数,得到与查询最相关的音频元数据(比如语音识别的指令或者音乐的名称)。
4、如果用户输入文本并且音频中存在语音文本,也可以利用语音文本来回答用户的问题。
AiSQL向量数据库应用场景:基因比对

基因比对在生物的同源性分析、疾病诊断及预防等方面都有重要的意义,将向量技术应用于基因比对主要包括以下几个步骤:
1、准备已知的DNA序列数据集,包含序列片段及元数据,元数据可能包含生物的物种信息、疾病的种类及病灶等标签数据。
2、对输入的DNA序列进行k-mer编码。k-mer编码是将DNA序列切分成长度为k的子序列。例如,当k=4时,DNA序列 “AGTCGTCGTCGC…” 会被分割成 “AGTC”、“GTCG”、“TCGT”…等四元体子序列,这样做可以让整个序列看起来更像一个语言句子,方便向量化表示。
3、对处理后的定长序列进行特征向量化,将每个子序列映射为一个固定维度的数值向量,构成了表示该DNA序列的特征向量。
4、针对查询的DNA序列重复执行步骤2-3,得到其对应的特征向量表示。
5、从已知数据集中检索出与查询序列相似的DNA元数据,用于后续的物种分析、疾病分析等。
该流程通过将DNA序列数字化为特征向量,并计算向量之间的相似性,从而实现对DNA序列的相似性分析和鉴定,在生物信息学等领域具有广泛的应用价值。
AiSQL向量数据库应用场景:自然语言转SQL
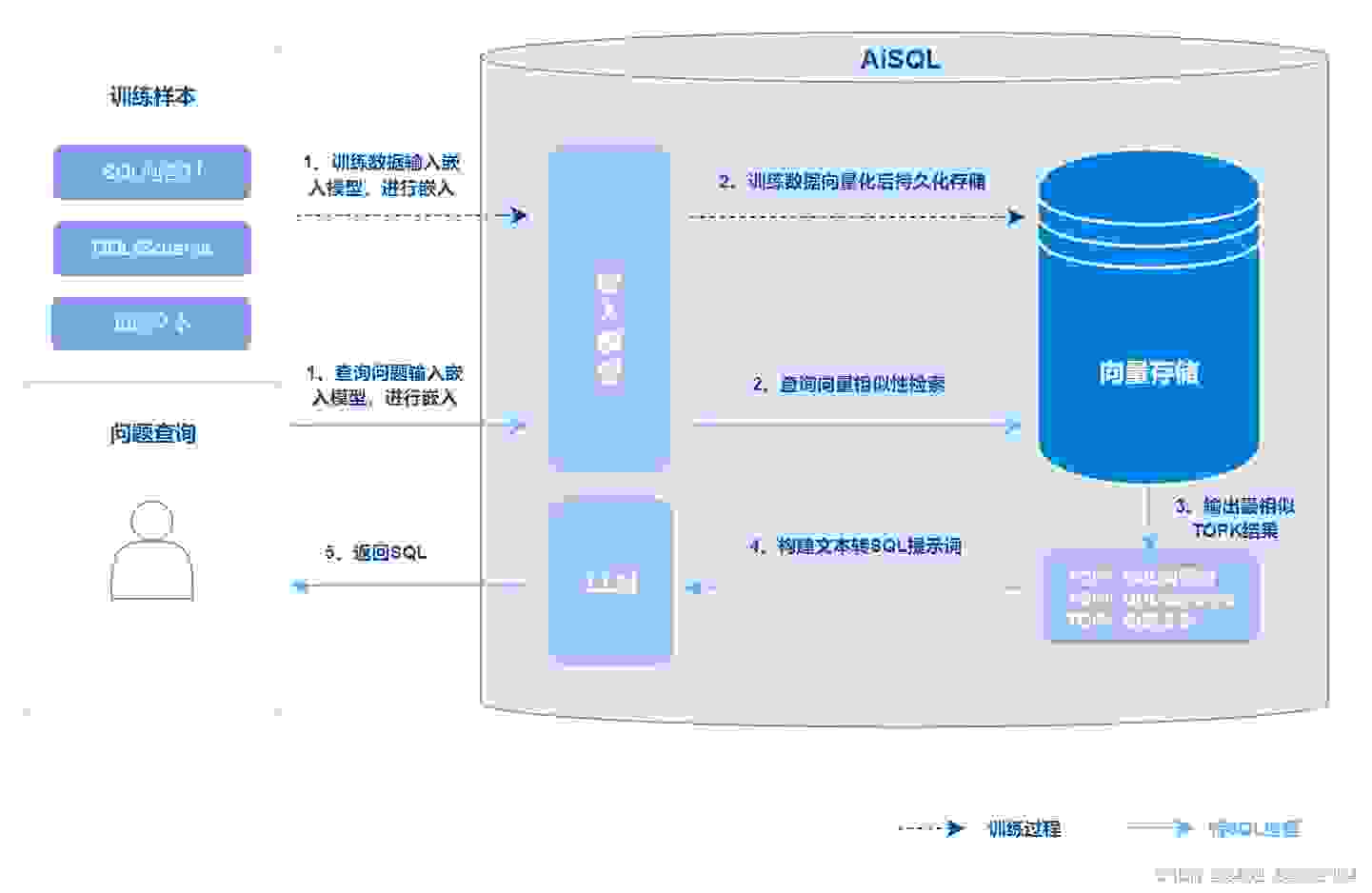
单纯使用微调模型来执行text to sql的任务,在微调数据覆盖范围内能达到很好的效果,但是在泛化的场景下,往往表现不佳,这时候可以结合RAG技术来提升精确率。
1、训练样本收集阶段,主要收集SQL问答对、DDL/Schema定义和知识文本。
2、向量化索引阶段,分别对SQL问答对、DDL/Schema定义和知识文本进行嵌入,形成向量化特征,并持久化存储;
3、向量化检索阶段,对查询问题进行向量化,使用相似度算法从样本数据特征向量库检索相似的样本,这些返回的样本中,包含SQL问答对、Schema定义及额外的知识文本。
4、SQL生成阶段,把检索出来的相似样本数据作为大模型的few-shots,构造text to sql提示词,由大模型生成SQL语句。
总结
以上是AiSQL向量数据库一些常用的场景,除此之外,也可以广泛应用于电子商务、垃圾邮件过滤、知识产权保护、搜索引擎、金融风险评估、智能投顾、投资组合优化等方面。