张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 - 第17647页
结构体全解,适合初学者的一条龙深度讲解(附手绘图详解)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 322次

我们知道,C语言是允许我们自己来创造类型的,这些类型就叫做——自定义类型。自定义类型又包括结构体类型,联合体类型还有枚举类型。今天的文章,我们就着重讲解这其中的结构体类型。目录结构体的声明1.1结构的基础知识1.2结构的声明1.3匿名结构体的情况1.4结构的自引用 1.5重命名匿名结构体的情况1.6 结构体变量的定义和初始化 1.7 结构体内存对齐1.8为什么存在内存对齐?1.9我们可以耍些小聪明达到节省空间的效果。2.1修改默认对齐数2.2结构体传参3.1位段3.2位段的内存分配3.3位段的跨平台问题结构体的声明1.1结构的基础知识结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。1.2结构的声明
PTA L1-025 正整数A+B(详解)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 264次

前言:本期是关于正整数A+B的详解,内容包括四大模块:题目,代码实现,大致思路,代码解读,今天你c了吗?题目: 题的目标很简单,就是求两个正整数A和B的和,其中A和B都在区间[1,1000]。稍微有点麻烦的是,输入并不保证是两个正整数。输入格式:输入在一行给出A和B,其间以空格分开。问题是A和B不一定是满足要求的正整数,有时候可能是超出范围的数字、负数、带小数点的实数、甚至是一堆乱码。注意:我们把输入中出现的第1个空格认为是A和B的分隔。题目保证至少存在一个空格,并且B不是一个空字符串。输出格式:如果输入的确是两个正整数,则按格式A+B=和输出。如果某个输入不合要求,则在相应位置输出?,显然此时和也是?。输入样例1:123456输出样例1:123+4
Python | 基础入门篇Part01——注释、数据类型、运算符、字符串
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 357次

欢迎交流学习~~专栏:Python学习笔记Python学习系列:Python|基础入门篇Part01——注释、数据类型、运算符、字符串Python|基础入门篇Part01——注释、数据类型、运算符一、注释1.1单行注释1.2多行注释二、常见的数据类型2.1Python中常见的有6种数据类型2.2如何查看数据类型——通过函数type()三、运算符3.1算术运算符3.2赋值运算符和复合赋值运算符四、字符串4.1字符串的定义方式&字符串拼接4.2格式化输出4.3数据输入一、注释Python中有两种注释方法,分为单行注释和多行注释,起解释说明作用:1.1单行注释以#开头,#右边的部分为注释比
基于Python-sqlparse的SQL表血缘追踪解析实现
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 369次
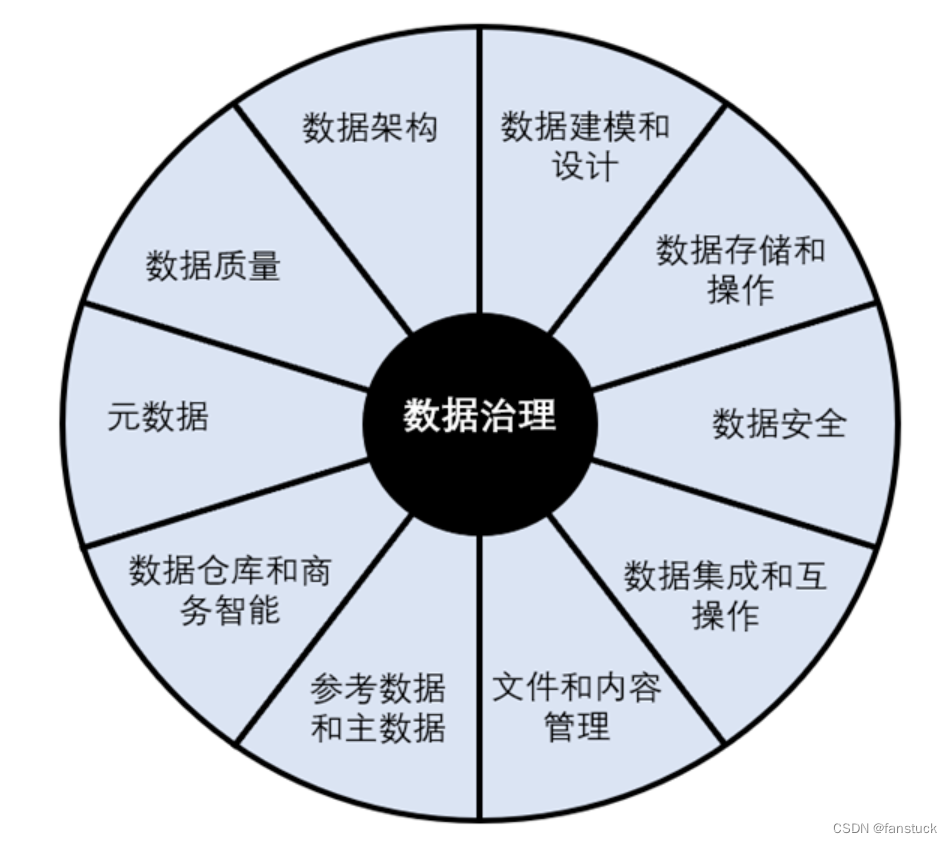
目录前言一、主线任务1.数据治理2.血缘追踪3.SQL表血缘二、实现过程1.目标效果2.代码实现1.功能函数识别2.SQL标准格式 3.解析AST树4.最终效果:点关注,防走丢,如有纰漏之处,请留言指教,非常感谢前言之前我在两篇SQLparse的开源库解析中就说过自己在寻找在python编程内可行的SQL血缘解析,JAVA去解析Hive的源码实践的话我还是打算放到后期来做,先把Python能够实现的先实现完。主要是HiveSQL的底层就是JAVA代码,怎么改写还是绕不开JAVA的。不过上篇系列我有提到过sqlparse,其实这个库用来解析血缘的话也不是不可以,但是能够实现的功能是有限的,目前我实验还行,一些较为复杂的SQL也能解析得出,算是成功达到可部署服务的
江霖宋婉婉小说结局
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 272次

《带顶级空间回六零,我有亿万物资》小说介绍经典小说《带顶级空间回六零,我有亿万物资》是桃桃瑆冰乐倾心创作的一本都市类型的小说,这本小说的主角是江霖宋婉婉,文中的爱情故事凄美而纯洁,文笔极佳,实力推荐。小说精彩段落试读:这价格还算是公道的!在商场最便宜的米都要2块5一斤,各种豆类也都是3,4块一斤了。……...《带顶级空间回六零,我有亿万物资》第3章江霖刘凡金手指空间免费试读中午的时候,他去附近的面馆吃了一份面,还买了几根雪糕。当然他也不只是为了吃,他打算试一下空间存物的功能!如果他记得
《逍遥小子闯都市》快手热推赵天圣柳轻烟免费阅读
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 239次

《逍遥小子闯都市》小说介绍甜宠新书《逍遥小子闯都市》是逆风而上最新写的一本都市类型的小说,这本小说的主角是赵天圣柳轻烟,情节引人入胜,非常推荐。主要讲的是:李小赶紧点点头,这种邀请函,只有主办方才有资格拥有,一般人根本就搞不到。“刚刚是谁说,要倒立来着……...《逍遥小子闯都市》第3章开除他(1920字)免费试读“这个臭流氓,居然送我这种东西。”回到宿舍的柳轻烟不停嘀咕着,旁边的舍友听到后,立刻八卦起来:“轻烟,你遇到下头男了?快给我讲讲。”“其实也没啥。”柳轻烟把刚刚的事情经过讲出来
安装Ubuntu详细教程
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 297次

安装Ubuntu详细教程 注:所用Ubuntu版本为Ubuntu20.04。下载链接:VMware:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.htmlUbuntu20.04镜像:https://ubuntu.com/download/1.新建虚拟机,选择自定义,下一步。2.硬件兼容性,选择Workstation16.x,下一步。3.选择安装程序光盘映像文件,路径为映像文件所在文件夹,下一步。 4.创建用户和设置密码,下一步。5.存放位置默认或者根据情况而定,下一步。
基于 Minikube 搭建第一个k8s集群
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 310次

一、前言对于k8s来说,搭建方式有多种,如果是生产环境,一般来说,至少需要3台节点确保服务的高可用性,常用的搭建方式列举如下(提供参考):kubeadm搭建(推荐)一个K8s部署工具,提供kubeadminit和kubeadmjoin ;用于快速搭建k8s集群,比较推荐(也是官方推荐的方式); 二进制包搭建github下载发行版二进制包,手动部署每个组件,组成Kubernetes集群;步骤繁琐,可能会踩很多坑;Minikube搭建是一种轻量化的Kubernetes集群;k8s社区为了帮助开发者和学习者能够更好学习和体验k8s功能而推出的;使用个人PC虚拟化环境,或者低配的云服务器就可以快速构建启动单节点k8s集群;其他方式
Markdown常用数学公式
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 1077次
文章目录先介绍一下markdown常用语法进入正题——数学公式行内公式&行内公式角标(上下标等)数学符号(帽子,无穷,极限)数学运算(加减乘除根式分式)大型运算符(微分积分极限求和)集合运算(子集、并集,交集)逻辑运算(大于小于等于)希腊字母很多情况下,markdown编辑器都自带latex的公式解析功能先介绍一下markdown常用语法标题#一级标题,##二级标题,###三级标题插入图片插入链接[链接名称](链接地址)区块(引用)>markdown(在段落的开头使用)插入流程图,UML,甘特图,流程图等更多具体基本语法可参见:https://www.runoob.com/markdown/md-advance.
快手江霖宋婉婉主角的小说全本章节大结局
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 241次

《带顶级空间回六零,我有亿万物资》小说介绍小说主人公是江霖宋婉婉的书名叫《带顶级空间回六零,我有亿万物资》,本小说的作者是桃桃瑆冰乐最新写的一本都市类小说,内容主要讲述:“这,这我哪有钱还啊!江霖你再等我几天!我肯定还你。”刘凡欲哭无泪,他刚刚还想着找江霖借些钱周转呢!……...《带顶级空间回六零,我有亿万物资》第2章江霖刘凡富二代免费试读出了宿舍后,江霖离开了学校,回到了自己在学校旁边买的小公寓。身为一个大学生,他能有这么多资产,完全是靠着家里!他就是名副其实的富二代!但拥有着这么多
search zhannei
最新文章
-
- 再世医圣番外+结局(江逸,沈甜)小说在线阅读
- 风入江云:结局+番外免费品鉴:结局+番外评价五颗星
- 沈予安陆晚棠小说完本+外篇(一声百转千回)畅享阅读
- 许清梨贺南舟小说(他在回忆尽头)(许清梨贺南舟)完整章节列表_笔趣阁
- (李象)大唐之最强皇太孙无删减小说在线无广告高口碑小说
- 苏沫:+后续+全文(心声暴露,兽夫们夜夜熬红眼)全书在线下载阅读完美终章小说大结局
- (心声暴露,兽夫们夜夜熬红眼)心声暴露,兽夫们夜夜熬红眼小说(苏沫)无套路无弹窗全部章节列表
- 许清梨贺南舟后续(许清梨贺南舟)(他在回忆尽头)完整章节列表_笔趣阁
- 高分_李象小说(大唐之最强皇太孙)(李象)全本完整阅读
- 他在回忆尽头::结局+番外评价五颗星-许清梨贺南舟:结局+番外新上热文
- 叶薇,萧逸璃纹双璧,情定此生电子书+番外篇章+(璃纹双璧,情定此生)免费版在线阅读
- 林蔓枝,墨冽完结篇(身怀空间,我在兽世荒漠养兽夫)章节:结局+番外评价五颗星
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1