张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 特征 - 第2页
ICCV 2021 | 表现SOTA!CurveNet:面向点云几何形状的长距离特征提取网络_阿木寺的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 586次

点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达WalkintheCloud:LearningCurvesforPointCloudsShapeAnalysis作者单位:悉尼大学,新南威尔士大学项目网页:https://curvenet.github.io/代码:https://github.com/tiangexiang/CurveNet论文:https://arxiv.org/abs/2105.01288导读:点云处理一直以来是计算机视觉领域中的一项具有挑
【集成学习系列教程3】LightGBM_Juicy B的博客
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 480次

1.7LightGBM1.7.1概述前面我们介绍了AdaBoost和GBDT这两种Boosting方法,它们已经在很多问题上发挥了强大的威力,也已经具有较好效率。但是,如今的数据集正在朝着样本数越来越巨大,特征维度也越来越高的方向发展,此时这两种传统的Boosting方法在效率和可扩展性上已经不能满足现在的需求了。主要原因是:传统的Boosting算法中的基学习器需要通过对所有样本点的每一个特征都进行扫描来计算信息增益&#x
「ORB_SLAM2|3实践笔记」构造函数Frame::Frame() 、去畸变UndistortKeyPoints()、计算虚拟右目横坐标ComputeStereoFromRGBD_小秋SLAM和DL实践笔记
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 509次

生成帧会传入彩色图mImGray、深度图imDepth、时间戳timestamp、左目提提取特征的指针mpORBextractorLeft、词典指针mpORBVocabulary、相机内参mK、畸变系数mDistCoef、基线×焦距mbf、深度因子mThDepth帧有一个全局的唯一IDmnId=nNextId++然后传入彩色图提取特征ExtractORB(0,imGray)这里使用mpORBextractorLeft提取图像特征,然后将特征存储在std::vector<cv::KeyPoint>
Python计算树模型(随机森林、xgboost等)的特征重要度及其波动程度:基于熵减的特征重要度计算及可视化、基于特征排列的特征重要性(feature permutation)计算及可视化_data+scenario+science+insight
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 577次
Python计算树模型(随机森林、xgboost等)的特征重要度及其波动程度:基于熵减的特征重要度计算及可视化、基于特征排列的特征重要性(featurepermutation)计算及可视化目录
Distilling Holistic Knowledge with Graph Neural Networks论文解读_Daft shiner的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 467次
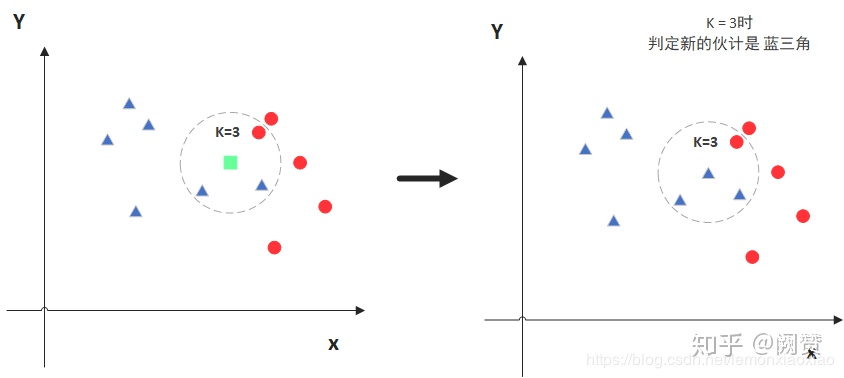
这是一篇ICCV2021的文章,提出了一种新的知识蒸馏方式(HolisticKnowledgeDistillation)原文链接代码链接Figure1为Individual、Relational、HolisticKnowledgeDistillation三种不同的知识蒸馏方式的区别.这里根据RelationalKnowledgeDistillation解读以及RelationalKnowledgeDistillation简单介绍一下这几种知识蒸馏方式的区别:先
机器学习基础一站通_NOMSGGG的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 503次
目录一.流程总览(本文主要是红框部分)二.特征处理部分1.总体概述 1.1一些常见问题2.具体处理(具体顺序看上面红框)2.1缺失值处理(删or填)2.2数据格式处理(数据集划分,时间格式等)2.3数据采样(过采样or下采样,不均衡时候用)2.4数据预处理(把原数据转更好用形式→标准,归一,二值)2.5特征提取(把文字转为可以用的→字典,中英文,DNA,TF)2.6降维(过滤(低方
三、用矩阵求解多元线性回归_并不傻的袍子
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 656次
一、多元线性回归函数上面解决了只有单一变量(面积)的房子价格预测问题,但是如果存在多个特征如:面积、卧室数量、楼层、修建年限等多个特征,如下:我们用m表示样本数量,n表示特征数量,表示输入的第i个样本,表示输入的第i个样本的第j个特征。只有一个变量时假设函数是:,现在我们有4个特征,所以假设函数变为:,我们引入=1,则方程可以变为:,写成矩阵形式为: 则这就是多特征的
睿智的目标检测52——Keras搭建YoloX目标检测平台_Bubbliiiing的学习小课堂
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 521次
睿智的目标检测52——Keras搭建YoloX目标检测平台学习前言源码下载YoloX改进的部分(不完全)YoloX实现思路一、整体结构解析二、网络结构解析1、主干网络CSPDarknet介绍2、构建FPN特征金字塔进行加强特征提取3、利用YoloHead获得预测结果三、预测结果的解码1、获得预测框与得分2、得分筛选与非极大抑制四、训练部分1、计算loss所需内容2、正样本特征点的必要条件3、SimOTA动态匹配正样本4、计算Loss训练自己的YoloX
2021陇剑杯网络安全大赛wp-JWT部分(详细题解)_偷一个月亮
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 535次
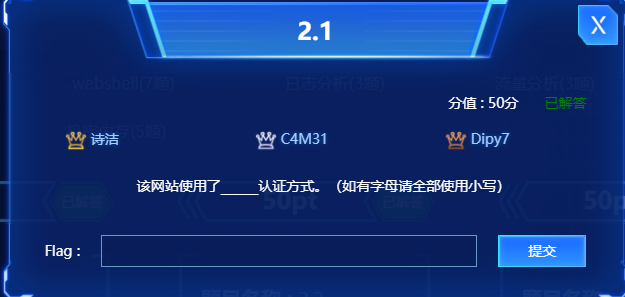
2021陇剑杯网络安全大赛-JWT部分(详细题解)2.1token特征eyJ2.22.32.42.52.6
TensorFlow实现自注意力机制(Self-attention)_盼小辉丶的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 563次
TensorFlow实现自注意力机制(Self-attention)自注意力机制(Self-attention)计算机视觉中的自注意力Tensorflow实现自注意力模块自注意力机制(Self-attention)自注意力机制(Self-attention)随着自然语言处理(NaturalLanguageProcessing,NLP)模型(称为“Transformer”)的引入而变得流行。在诸如语言翻译之类的NLP应
search zhannei
最新文章
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1