Yann LeCun 朝着 “世界模型” 又近了一步。
Meta最新的开源工作OpenEQA:从文字模型到世界模型,可以像人一样记忆、推理的新基准,AI理解物理空间又近了一步。
场景1:
假设你正准备离开家,但找不到你的工牌。
现在,你可以询问你的智能眼镜,“我的工牌在哪里”,它会告诉你位置。作为智能体的眼镜可能会利用它的情景记忆来回答工牌在餐桌上。
场景2:
如果你在回家的路上饿了,你可以问问你家的机器人是否还有水果。它会像管家一样在房子里寻找,并可能回答说“水果篮里还有香蕉”。
,时长00:19
想象一下,一个具身的人工智能代理充当家用机器人的大脑或一副时尚的智能眼镜,它们通过自然语言理解环境并回答有关问题的任务。
这样的智能体需要利用视觉等感官模式来了解周围环境,比如智能眼镜上的代理可以通过回忆来实现这种理解,而移动机器人则通过主动探索环境来实现。
这类似于构建一个“世界模型”:一个智能体对外部世界进行内部表示,并允许用户通过语言等方式对外部真实世界进行查询。

什么是 OpenEQA?
Meta 刚刚推出的 OpenEQA,是第一个支持情景记忆和主动探索用例的开放词汇基准数据集,用来衡量 AI 代理对其环境的理解。
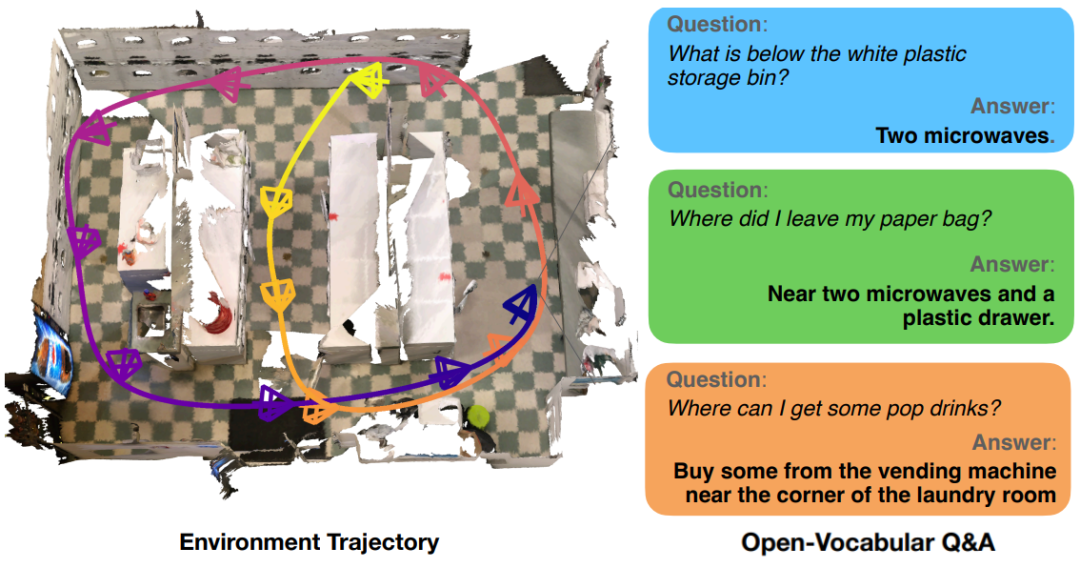
▲图1. Meta 开源的 OpenEQA 基准,其中包含1600多个非模板问题,测试属性识别、空间理解、功能推理和世界知识等方面。
OpenEQA 包含两个任务,一个是情景记忆 EQA,其中具身 AI 代理根据其对过去经验的回忆回答问题(就像刚才帮你回忆工牌位置的眼镜)。
另一个则是主动 EQA,其中代理必须在环境中采取行动以收集必要的信息并回答问题,比如在房间里搜索水果来完成对用户询问的回复。
OpenEQA 包含超过 1600 个由人类生成的高质量问题,这些问题来自超过 180 个真实世界环境。
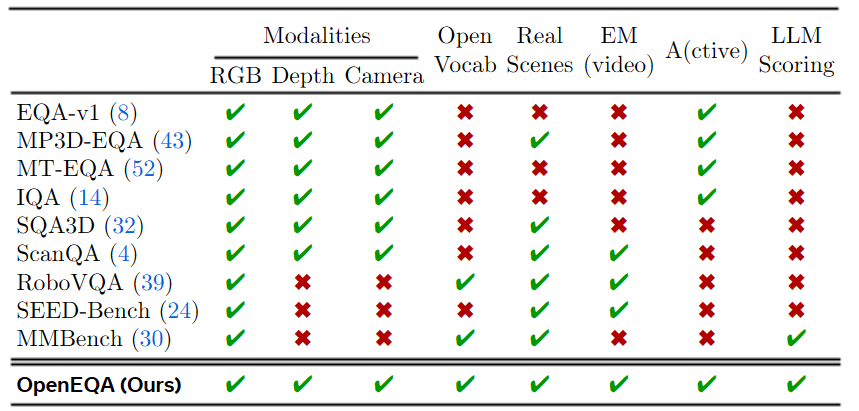
▲表1. OpenEQA 与现有基准测试。OpenEQA 具有多种模态、真实场景、主动代理和自动评分。
EQA 和 VQA 领域已经得到了广泛的研究,但是作者的方法和以前的基准显著不同,主要体现在输入模态、真实世界空间的场景/扫描、以及开放词汇的问题和答案等方面。
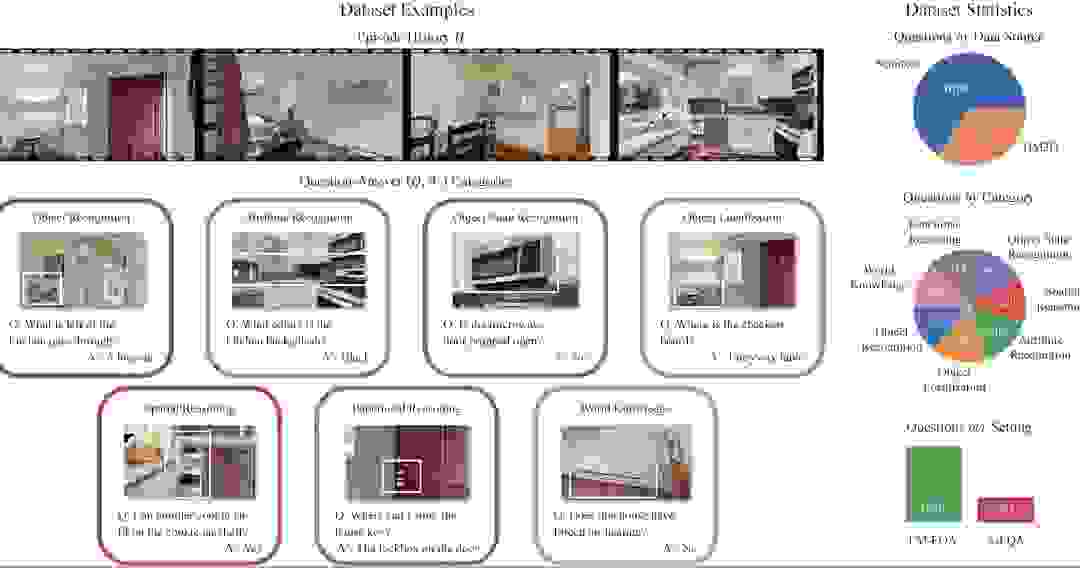
▲图3. OpenEQA的示例问题和数据集统计。在 OpenEQA 数据集中,episode history H 提供了一个类似家庭参观的场景。EQA 代理必须回答来自 7 个 EQA 类别的多样化的、人类生成的问题 Q,旨在匹配 Ground Truth A*。
特别是,OpenEQA 是第一个针对EQ (EQA) 的开放词汇基准,并支持记忆片段和主动设置。
实现这一目标的关键技术包括:1. 视频和真实环境扫描,如ScanNet、Gibson和HM3D,以及能够渲染这些场景的模拟器;2. 能够评分开放式答案的大型语言模型 (LLMs)。
这种技术上的结合能使模型能够通过观看视频片段,从人类注释者那里获取问题并回应,然后对其进行自动评分。
基于此,作者还提供了一个自动的基于LLM(大型语言模型)的评估协议,与人类判断有很好的相关性。
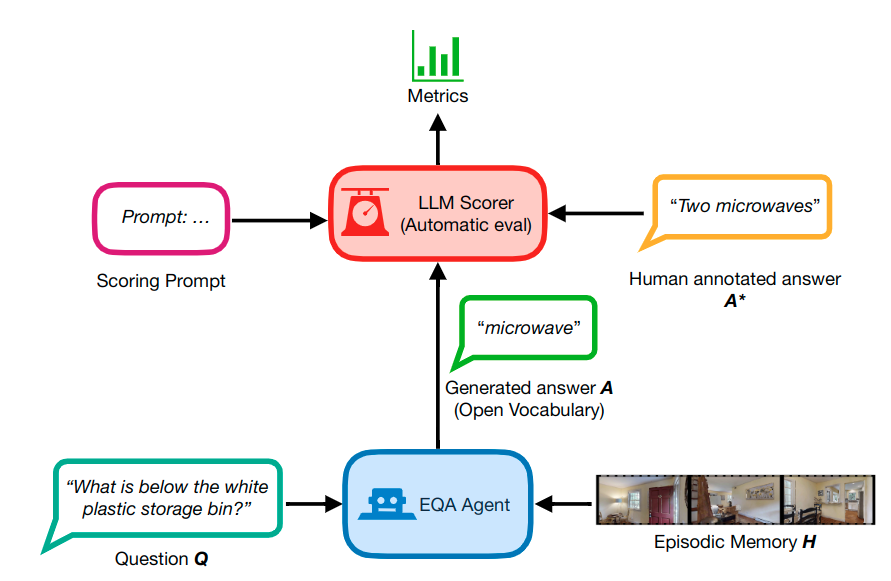
▲图4. LLM-Match 评估和工作流程的图示。
开放词汇的特性使得 EQA 更加逼真,但由于多种正确答案的存在,对其进行评估也带来挑战。
一种评估方法是进行人类试验,但这可能会非常缓慢且昂贵,特别是对于基准测试而言。
作为一种替代方案,作者使用 LLM 来评估由 EQA 代理生成的开放词汇答案的正确性。
实验
作者在四类 LLMs 上进行了实验,并发现多帧视觉语言模型(例如GPT-4V)胜过其他 LLM Agent,这表明感知和语言紧密结合可能会极大地有益于 EQA 任务。
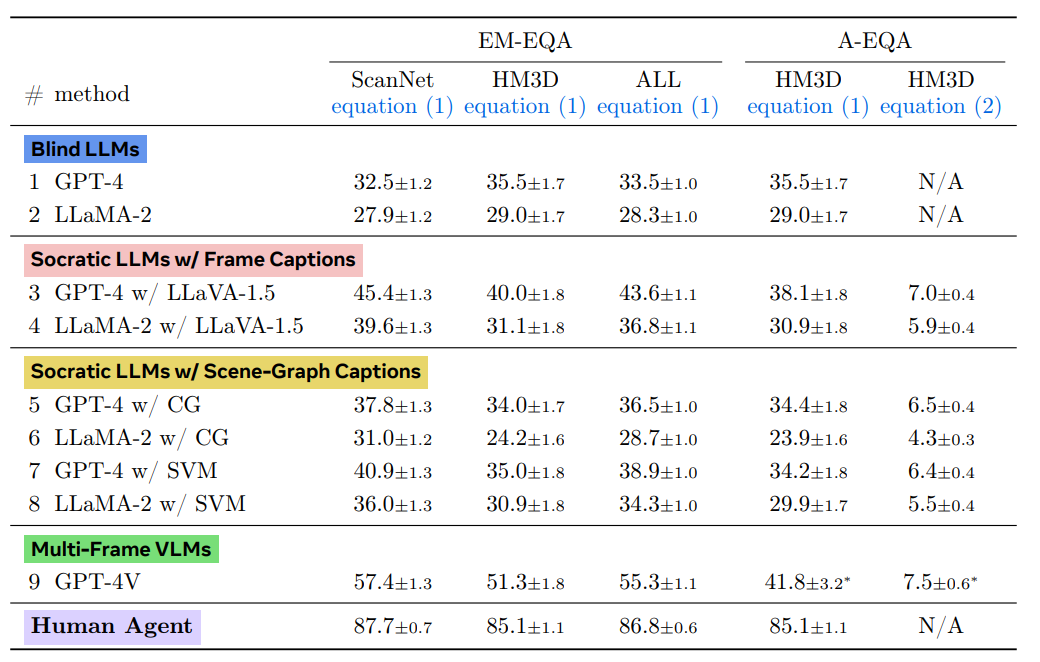
▲表2.
但是作者也发现仅文本的语言模型(LLMs)作为基线表现出乎意料的强大,其中GPT-4和LLaMA-2在EM-EQA上分别达到33.5和28.3的分数。
虽然这远低于 GPT-4V 或人类水平的表现,但这表明世界具有很大程度的规律性,并且对几个问题的答案可以在没有特定环境的显式视觉背景下“有效猜测”。
在每组 Agent 中,GPT-4 始终表现优于LLaMA-2。这表明更大的 LLMs 可能是良好 EQA 性能的关键因素。
在比较 EM-EQA 和 A-EQA 中 Agent 的表现时,通常观察到 A-EQA 中的得分较低。部分原因是A-EQA 中 Agent 使用了全面探索,导致路径更长,通常需要包含长时间的历史信息,其中可能包含对特定问题无关的信息。
在一些情况下,这使得各种 Agent 的表现与仅文本的 LLMs 相当,甚至更低(例如GPT-4 w/ ConceptGraphs)。这凸显了 A-EQA 基准测试的挑战性质以及交互环境中高效探索的重要性。
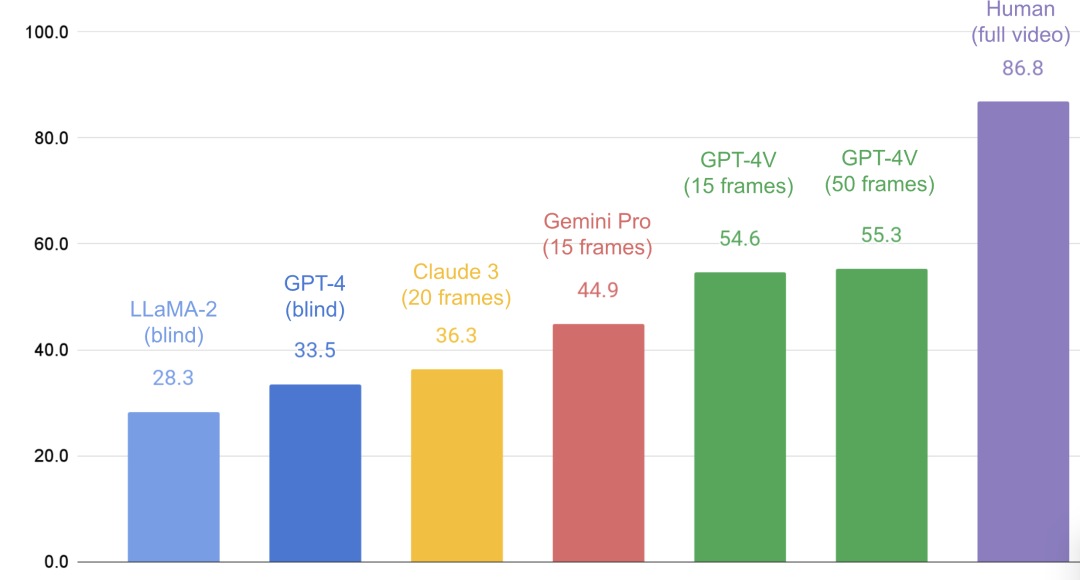
▲图5. LLM vs.多模态 LLM 在 EM-EQA 上的表现。
作者在 OpenEQA 上评估了几个多模态 LLM,包括 Claude 3、Gemini Pro 和 GPT-4V。
这些模型的性能始终优于纯文本 LLM 基线,如 LLaMA-2 或 GPT-4。然而,性能比人类的基线差得多。
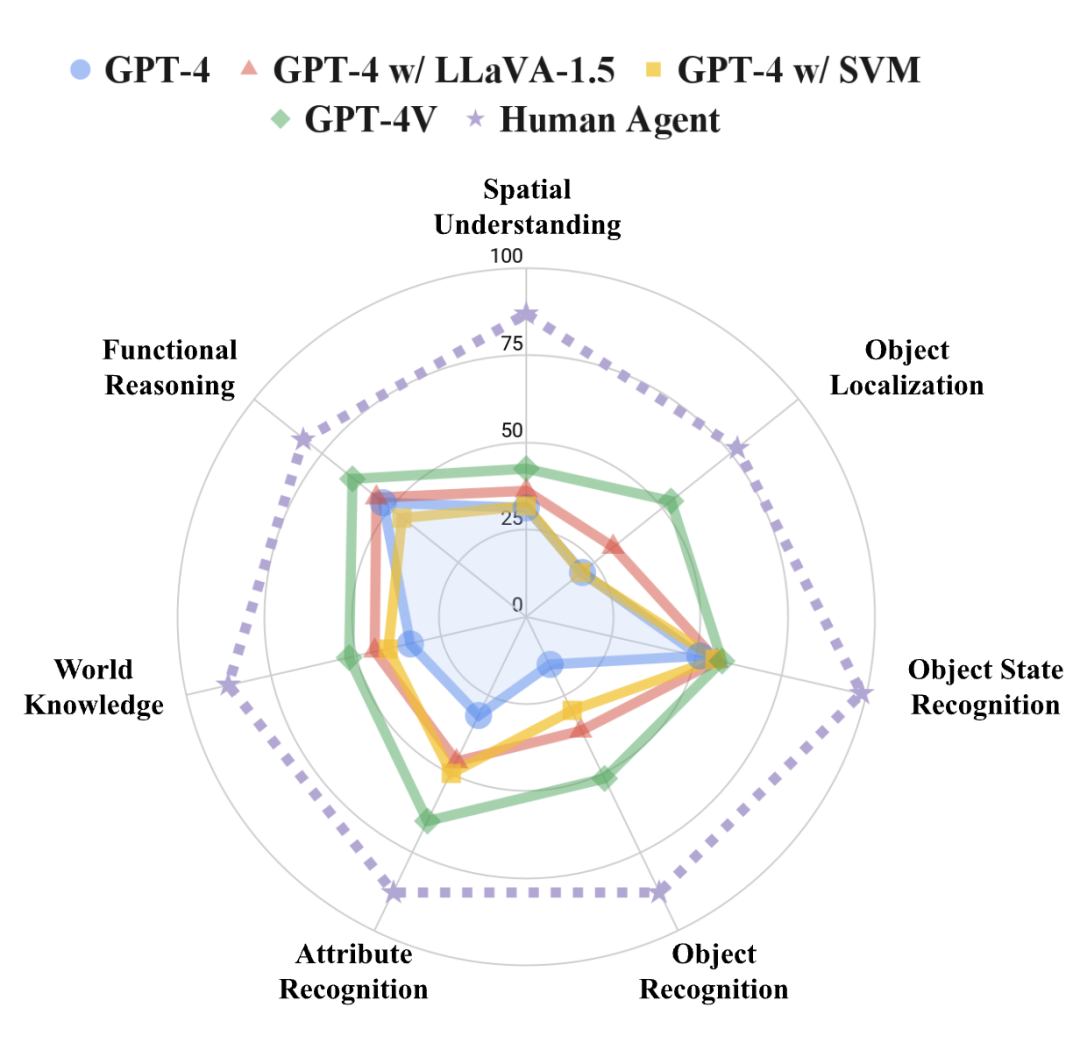
▲图6. EM-EQA的类别级性能。
可以看到,可访问视觉信息的智能体擅长定位以及识别对象和属性,并更好地利用这些信息来回答需要世界知识的问题。
然而,这些智能体在其他类别上的性能更接近纯文本的 LLM 基线(GPT-4),这表明OpenEQA还有很大的改进空间。
