Llama2是Meta最新开源的语言大模型,训练数据集2万亿token,上下文长度是由Llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,最重要的是,该模型可用于研究和商业用途。
一、准备工作
1、本文选择微调的基础模型是Llama2-chat-13B-Chinese-50W( 如何部署Llama2大模型,可以转到在Linux系统下部署Llama2(MetaAI)大模型教程-CSDN博客)
2、由于大部分笔记本电脑无法满足大模型Llama2的微调条件,因此可以选用autodl平台(算力云)作为部署平台。注:显存选择40GB以上的,否则微调过程会报错。
二、创建新实例(需要对数据盘进行扩容20GB)
基础的数据盘内存无法满足微调要求,因此需要对数据盘进行扩容。点击已经部署好Llama2大模型实例的“更多”中的“克隆实例”。
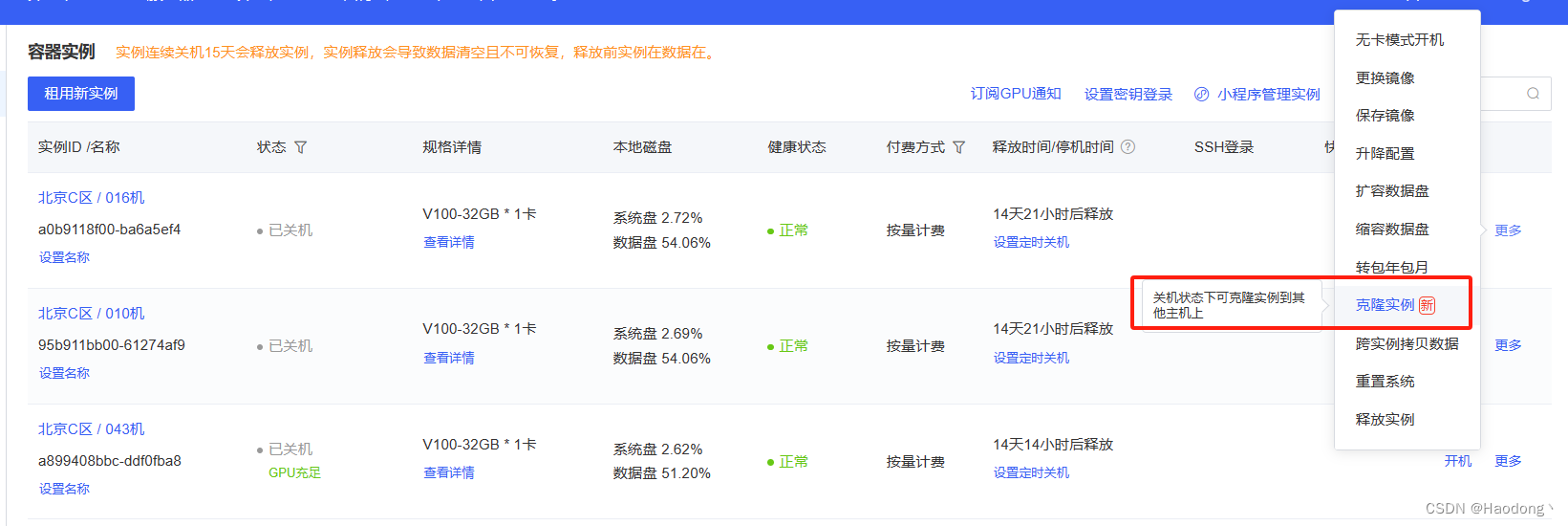
勾选“数据盘”。
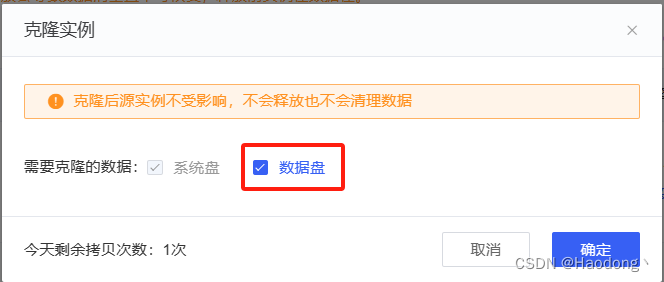
选择可扩容的主机。

选择“需要扩容”,填写“20”GB。
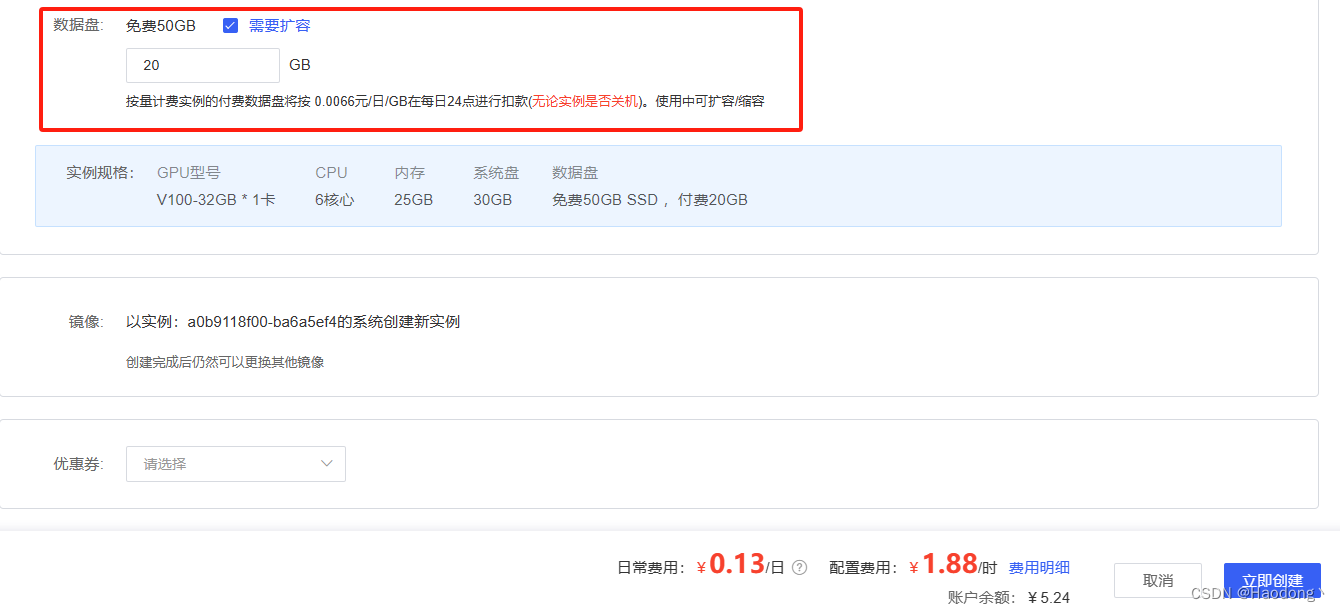
填写完成后,点击“立即创建”。创建完成后,不要着急,等待一会儿。状态栏的“运行中”下面会出现“正在拷贝数据集”字样,等待数据集拷贝完成。

当“正在拷贝数据集”字样消失后,说明拷贝完成,点击JupyterLab。

三、下载、预处理微调数据集
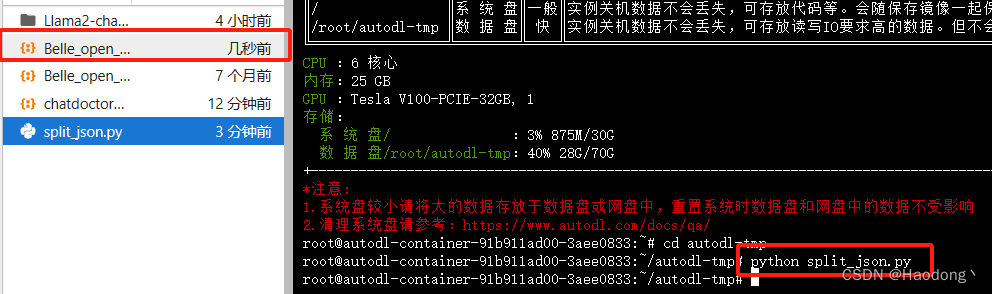
先cd到数据盘autodl-tep,并设置学术加速,然后运行以下代码下载数据集。
如果你有自己的数据集,那么可以选择使用自己的数据集。
wget https://huggingface.co/datasets/BelleGroup/train_0.5M_CN/resolve/main/Belle_open_source_0.5M.json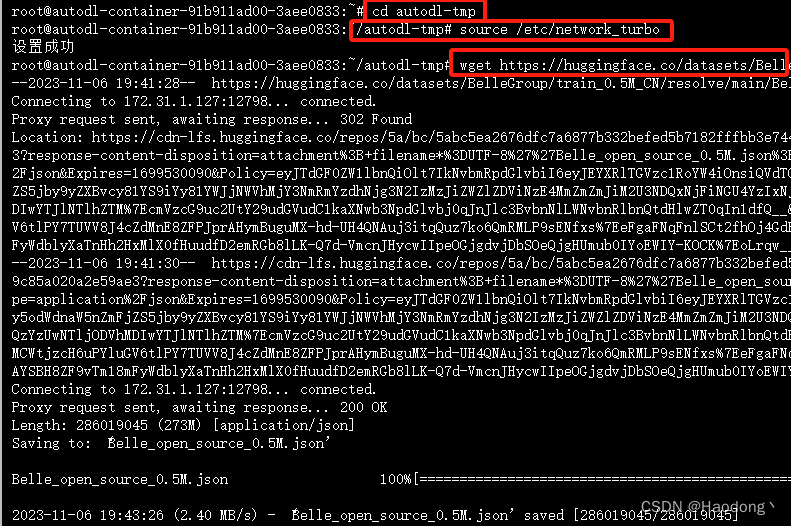
原始数据集共有50万条数据,格式:{"instruction":"xxxx", "input":"", "output":"xxxx"}
数据集下载完毕之后,需要对数据集进行预处理。新建一个文件:split_json.py. 右击,点击“新建文件”,然后将文件名改为split_json.py即可。
接下来,将以下代码复制粘贴至文件split_json.py中。这段程序的作用是对数据集进行拼接,只使用introduction和output,并仅选择1000条数据作为演示。但在正常生产环境中,我们就需要更大的数据量。
import random,jsondef write_txt(file_path,datas): with open(file_path,"w",encoding="utf8") as f: for d in datas: f.write(json.dumps(d,ensure_ascii=False)+"\n") f.close()with open("/root/autodl-tmp/Belle_open_source_0.5M.json","r",encoding="utf8") as f: lines=f.readlines() changed_data=[] for l in lines: l=json.loads(l) changed_data.append({"text":"### Human: "+l["instruction"]+" ### Assistant: "+l["output"]}) r_changed_data=random.sample(changed_data, 1000) write_txt("/root/autodl-tmp/Belle_open_source_0.5M_changed_test.json",r_changed_data)运行以下代码对split_json.py进行执行。
python split_json.py生成了一个新的json文件Belle_open_source_0.5M_changed_test.json,说明运行成功。
拼接好的数据格式:{"text":"### Human: xxxx ### Assistant: xxx"}
四、运行微调文件
1、返回启动页,新建一个notebook。
2、安装相关包
输入之后,按Shift+Enter运行。
!pip install -q huggingface_hub!pip install -q -U trl transformers accelerate peft!pip install -q -U datasets bitsandbytes einops wandb左上角由 [*] 变为 [1] 后,说明安装成功。

3、设置学术加速
4、登录huggingface的notebook
这里需要到:https://huggingface.co/settings/tokens 中复制token。token获取方式可以参考:如何获取HuggingFace的Access Token;如何获取HuggingFace的API Key-CSDN博客
然后执行下列语句:
from huggingface_hub import notebook_loginnotebook_login()将token复制进去:
5、初始化wandb
首先需要先到:https://wandb.me/wandb-server 注册wandb。进入网址后,点击右上角进行登录注册。
注册完毕后在https://wandb.ai/authorize中复制Key:
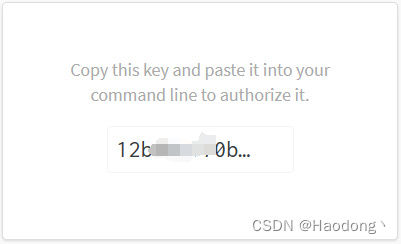
运行代码:
import wandbwandb.init()将复制的Key粘贴进去,然后再Enter。如果左侧出现文件夹wandb说明运行成功。
6、导入相关包
from datasets import load_datasetimport torch,einopsfrom transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArgumentsfrom peft import LoraConfigfrom trl import SFTTrainer7、加载上面拼接好之后的1000条数据
dataset = load_dataset("json",data_files="/root/autodl-tmp/Belle_open_source_0.5M_changed_test.json",split="train")
8、配置本地模型
base_model_name ="/root/autodl-tmp/Llama2-chat-13B-Chinese-50W"bnb_config = BitsAndBytesConfig( load_in_4bit=True,#在4bit上,进行量化 bnb_4bit_use_double_quant=True,# 嵌套量化,每个参数可以多节省0.4位 bnb_4bit_quant_type="nf4",#NF4(normalized float)或纯FP4量化 博客说推荐NF4 bnb_4bit_compute_dtype=torch.float16,)9、配置GPU
device_map = {"": 0}#有多个gpu时,为:device_map = {"": [0,1,2,3……]}10、加载本地模型
base_model = AutoModelForCausalLM.from_pretrained( base_model_name,#本地模型名称 quantization_config=bnb_config,#上面本地模型的配置 device_map=device_map,#使用GPU的编号 trust_remote_code=True, use_auth_token=True)base_model.config.use_cache = Falsebase_model.config.pretraining_tp = 1
11、配置QLora
peft_config = LoraConfig( lora_alpha=16, lora_dropout=0.1, r=64, bias="none", task_type="CAUSAL_LM",)12、对本地模型,把长文本拆成最小的单元词(即token)
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_token13、训练参数的配置
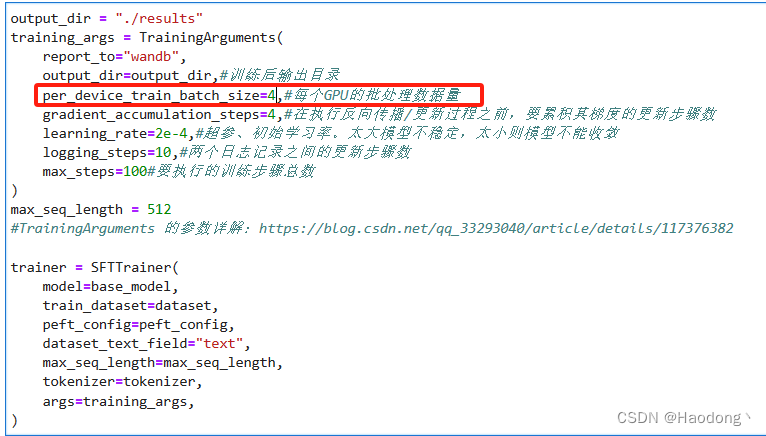
output_dir = "./results"training_args = TrainingArguments( report_to="wandb", output_dir=output_dir,#训练后输出目录 per_device_train_batch_size=4,#每个GPU的批处理数据量 gradient_accumulation_steps=4,#在执行反向传播/更新过程之前,要累积其梯度的更新步骤数 learning_rate=2e-4,#超参、初始学习率。太大模型不稳定,太小则模型不能收敛 logging_steps=10,#两个日志记录之间的更新步骤数 max_steps=100#要执行的训练步骤总数)max_seq_length = 512#TrainingArguments 的参数详解:https://blog.csdn.net/qq_33293040/article/details/117376382trainer = SFTTrainer( model=base_model, train_dataset=dataset, peft_config=peft_config, dataset_text_field="text", max_seq_length=max_seq_length, tokenizer=tokenizer, args=training_args,)14、开始进行微调训练
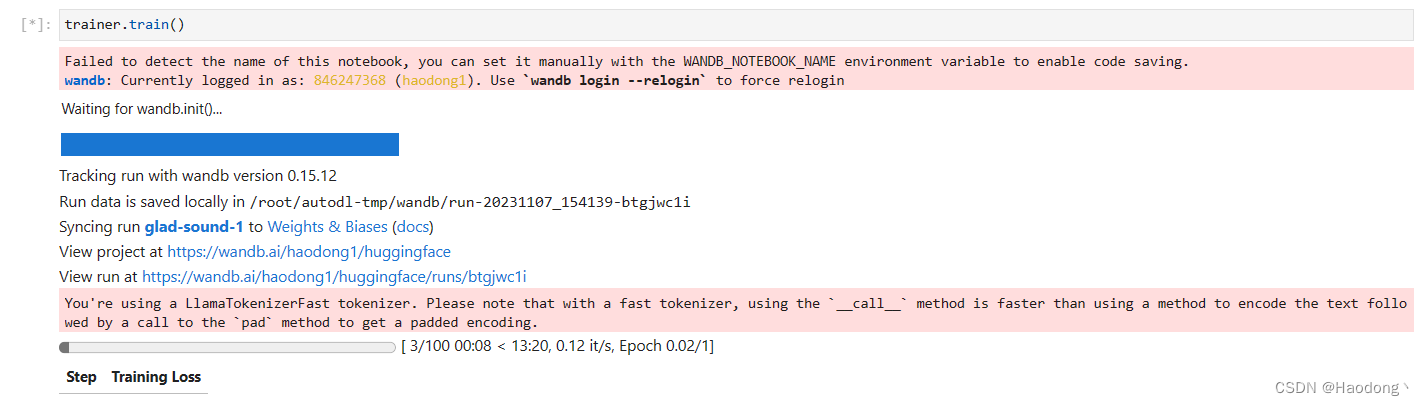
trainer.train()可以看到,随着训练的进行,损失函数在下降:

15、把训练好的模型保存下来
import osoutput_dir = os.path.join(output_dir, "final_checkpoint")trainer.model.save_pretrained(output_dir)五、执行代码合并
把训练好的模型与原始模型进行合并。
1、新建一个merge_model.py的文件,把下面的代码粘贴进去:
from peft import PeftModelfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torch#设置原来本地模型的地址model_name_or_path = '/root/autodl-tmp/Llama2-chat-13B-Chinese-50W'#设置微调后模型的地址,就是上面的那个地址adapter_name_or_path = '/root/autodl-tmp/results/final_checkpoint'#设置合并后模型的导出地址save_path = '/root/autodl-tmp/new_model'tokenizer = AutoTokenizer.from_pretrained( model_name_or_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained( model_name_or_path, trust_remote_code=True, low_cpu_mem_usage=True, torch_dtype=torch.float16, device_map='auto')print("load model success")model = PeftModel.from_pretrained(model, adapter_name_or_path)print("load adapter success")model = model.merge_and_unload()print("merge success")tokenizer.save_pretrained(save_path)model.save_pretrained(save_path)print("save done.")2、新建终端,然后执行上述合并代码,进行合并
python merge_model.py运行结果:

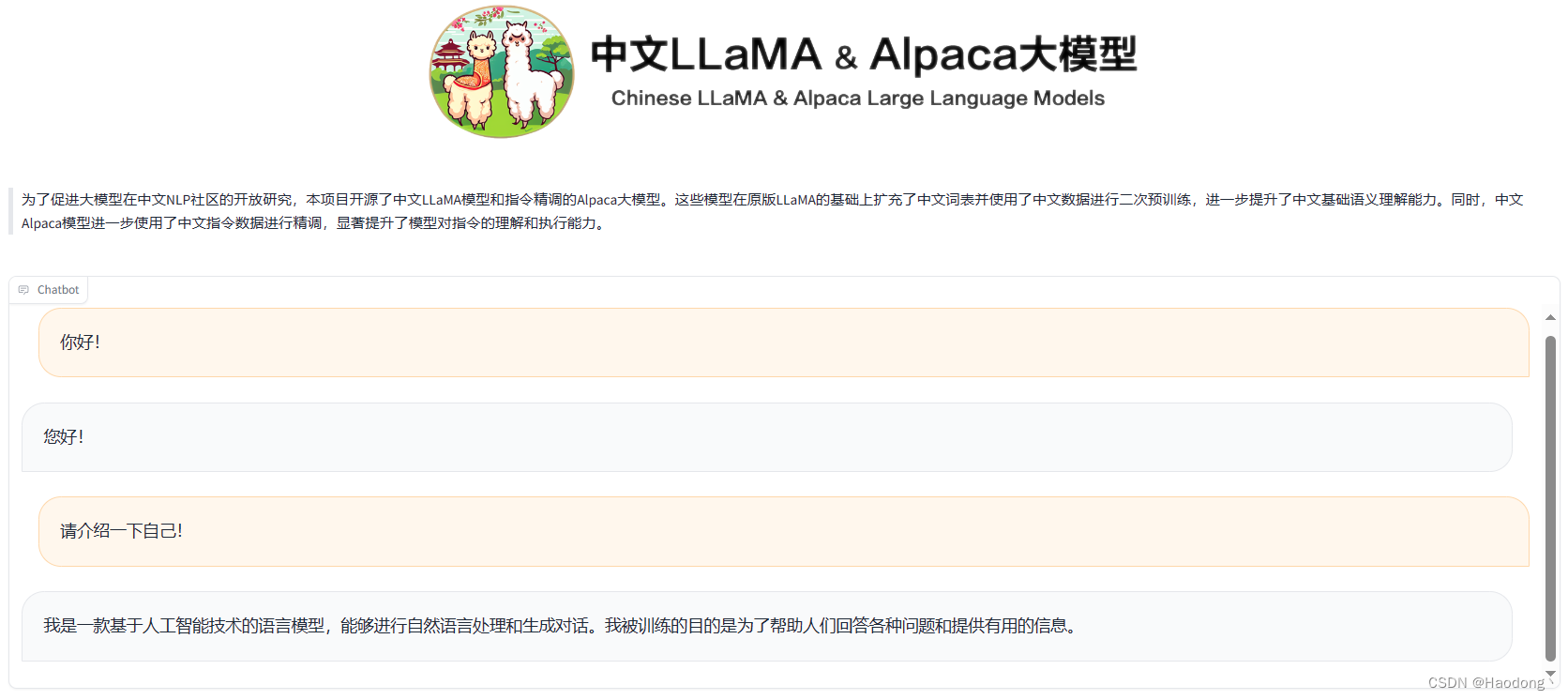
六、使用gradio运行模型
进入Llama2文件夹:cd Llama2
python gradio_demo.py --base_model /root/autodl-tmp/new_model --tokenizer_path /root/autodl-tmp/new_model --gpus 0
七、可能遇到的问题
1、执行代码notebook_login()时报错
报错显示:
(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/whoami-v2 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7fdf07ee4940>: Failed to establish a new connection: [Errno 110] Connection timed out'))"), '(Request ID: 3557b723-1341-4c75-b72a-f8ecf6c6a070)')
解决办法:
这是一个Python的错误信息,表明在使用Hugging Face的连接池时出现了最大重试误。根该错误信息,我们可以推测可能的原因是连接到huggingface.co的连接池达到了最大重试次数,但仍无法建立连接。这可能是由于网络连接问题、服务器不可用或其他问题导致的。
2、执行代码trainer.train()时报错
报错显示:
OutOfMemoryError: CUDA out of memory. Tried to allocate 270.00 MiB (GPU 0; 31.74 GiB total capacity; 29.60 GiB already allocated; 36.88 MiB free; 30.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解决办法一:
将训练参数的配置中的 per_device_train_batch_size 参数设置为2,再执行代码trainer.train(),即可解决。
解决办法二:
报错的主要原因为显存不足,可以更换显存更大的主机。