系列文章目录
springboot整合webmagic入库mysql,定时任务爬取网站系列
提示:完整的代码在最后面
文章目录
前言二、使用步骤 1.引入库2.读入数据总结
前言
之前的文章以springboot定时任务的标题来写的,那几篇文章压根就跟springboot没啥太大关系,结果到这篇文章才真正的用到,主要也是以前没怎么写过博客,尤其是系列的,属于想到哪里就写到哪里。如果你觉得哪里逻辑乱可以评论留言,虽然我不一定会听你的。
一、爬取网站
爬取网站:三农头条-中国农网
二、使用步骤
1.相关环境
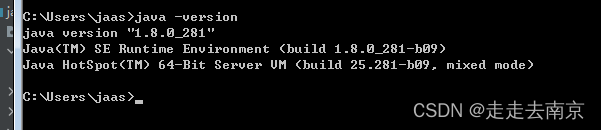
jdk版本
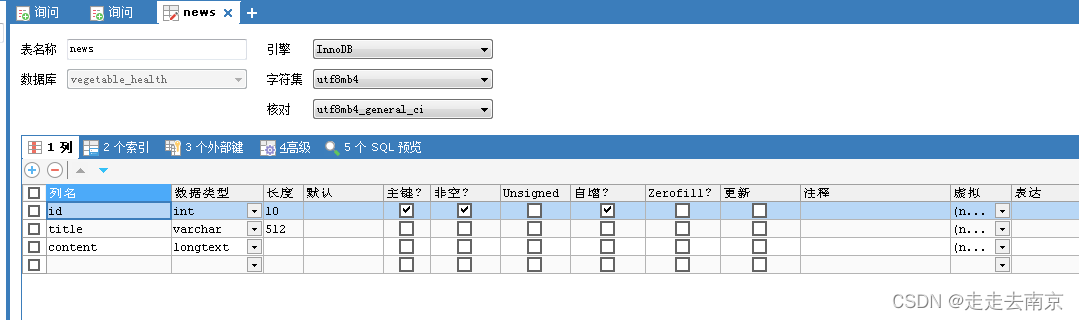
mysql数据库表:
pom主要信息(我这里并没有使用作者提供的webmagic-selenium)
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>${webmagic.version}</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>${webmagic.version}</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency><!-- <dependency>--><!-- <groupId>us.codecraft</groupId>--><!-- <artifactId>webmagic-selenium</artifactId>--><!-- <version>${webmagic.version}</version>--><!-- </dependency>--> <!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java --> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>4.1.1</version> <exclusions> <exclusion> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency> 2.创建FarmerPageProcessor类
代码如下:
package com.spiden.bazaspiden.processor;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Spider;import us.codecraft.webmagic.pipeline.ConsolePipeline;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.selector.Html;import java.util.List;/** * @author 张高昌 * @date 2024/1/9 10:22 * @description: 爬取中国农网 */public class FarmerPageProcessor implements PageProcessor { // 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等 private Site site = Site.me().setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { // 部分二:定义如何抽取页面信息,并保存下来 Html html = page.getHtml(); List<String> all = html.links().regex("https://www.farmer.com.cn/\\d+/\\d+/\\d+/\\d+\\.html").all(); page.addTargetRequests(all); } @Override public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new FarmerPageProcessor()) //从哪个网站开始爬取 .addUrl("https://www.farmer.com.cn/farmer/xw/sntt/list.shtml") .addPipeline(new ConsolePipeline()).run(); }}
其中regex的规则我在上一篇文章已经说过了,这里就不在重复了。如果不清楚可以看下我上一篇文章webmagic三:爬取网站csdn(小试牛刀)-CSDN博客。
运行后我们发现是all集合中是空的,并不是我们想要的。肯定是哪里出了问题。
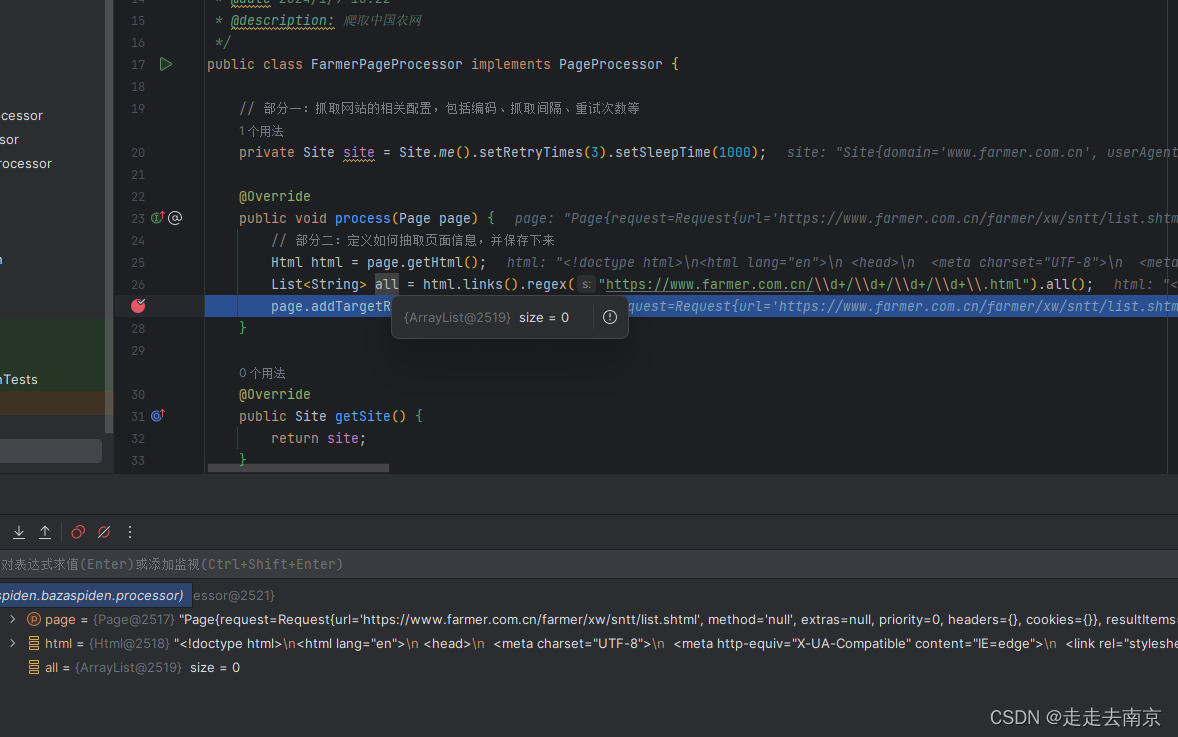
3.排查问题
List<String> all1 = html.links().all();
添加上面的代码再次调试看看
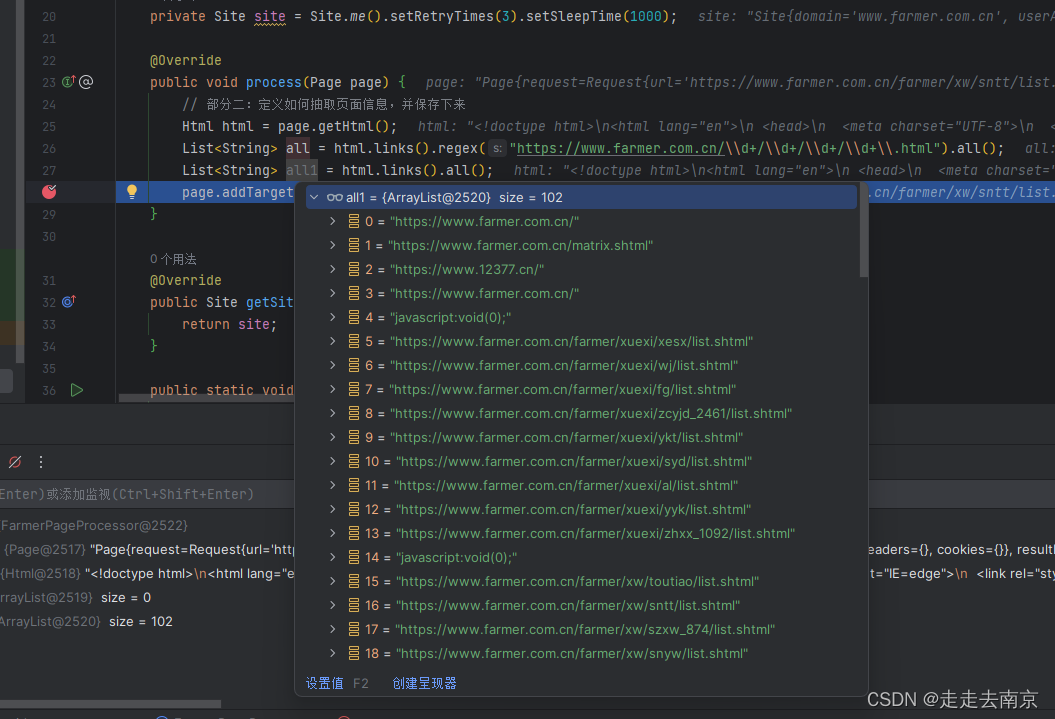
我们发现所有的有效链接中,并没有我们在浏览器打开想要爬取的链接。
我们想要爬取的链接如下图:(图片违规了,自己打开网站看)

我们要爬取的连接是这样的:
https://www.farmer.com.cn/2024/01/11/99944535.html
https://www.farmer.com.cn/2024/01/11/99944532.html
原因:这个页面是通过 js 以及 ajax 动态加载的。
如果不了解为什么的可以看下webmagic作者的这篇文章使用Selenium来抓取动态加载的页面 - 黄亿华的个人空间 - OSCHINA - 中文开源技术交流社区
4.解决
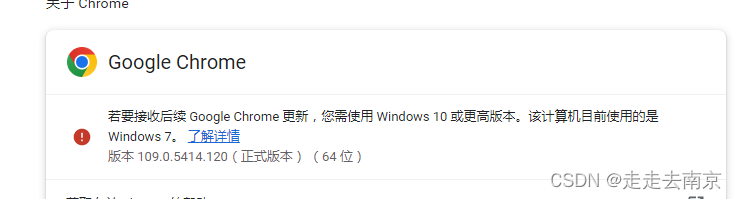
谷歌浏览器旧版本下载地址:Download older versions of Google Chrome for Windows, Linux and Mac
我当前的谷歌浏览器版本:109.0.5414.120
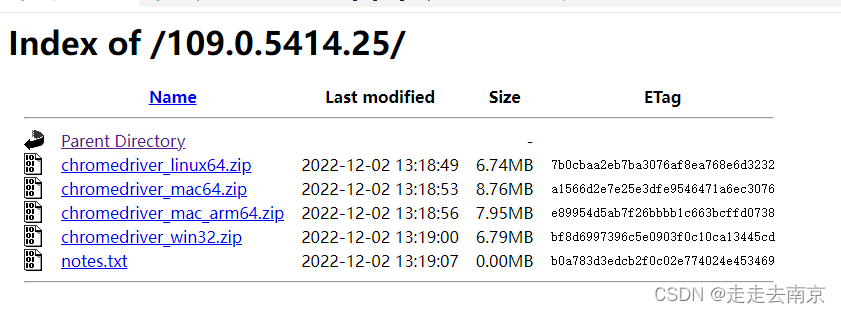
chromedriver下载地址:(不清楚为什么没有120版本的驱动,但是25也可以)
https://chromedriver.storage.googleapis.com/index.html
如果你无法打开谷歌旧历史版本可以从这里下载:
https://download.csdn.net/download/qq_28827185/88730566
5.代码
新建FarmerPageProcessor类
package com.spiden.bazaspiden.processor;import org.springframework.stereotype.Component;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.selector.Html;import java.util.List;/** * @author 张高昌 * @date 2024/1/9 10:22 * @description: 爬取中国农网 */@Componentpublic class FarmerPageProcessor implements PageProcessor { // 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等 private Site site; @Override public void process(Page page) { // 部分二:定义如何抽取页面信息,并保存下来 Html html = page.getHtml(); List<String> all = html.links().regex("https://www.farmer.com.cn/\\d+/\\d+/\\d+/\\d+\\.html").all(); page.addTargetRequests(all); // 部分三:将爬取到的数据保存在page中,方便Pipeline对其持久化操作 page.putField("title", page.getHtml().xpath("/html/body/div[5]/div[2]/div[2]/div[1]").toString()); page.putField("content", page.getHtml().xpath("/html/body/div[5]/div[2]/div[2]/div[4]").toString()); } @Override public Site getSite() { if (site == null) { site = Site.me().setRetryTimes(3).setSleepTime(1000); } return site; }}新建FarmerPipeline类
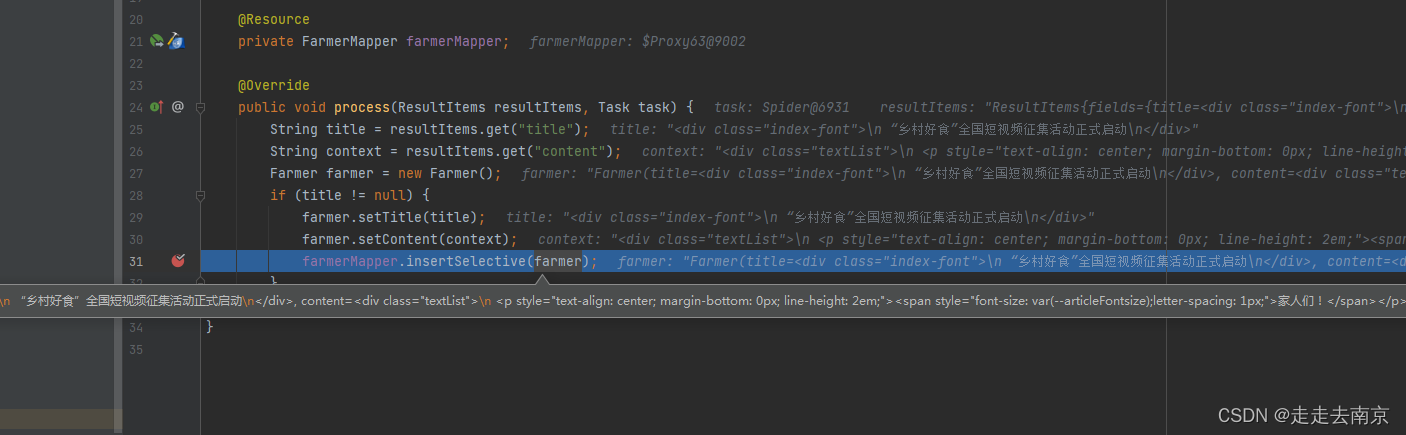
package com.spiden.bazaspiden.pipeline;import com.spiden.bazaspiden.mapper.FarmerMapper;import com.spiden.bazaspiden.model.Farmer;import org.springframework.stereotype.Component;import us.codecraft.webmagic.ResultItems;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.pipeline.Pipeline;import javax.annotation.Resource;/** * @author 张高昌 * @version 1.0 * @date 2024/1/10 14:44 */@Componentpublic class FarmerPipeline implements Pipeline { @Resource private FarmerMapper farmerMapper; @Override public void process(ResultItems resultItems, Task task) { String title = resultItems.get("title"); String context = resultItems.get("content"); Farmer farmer = new Farmer(); if (title != null) { farmer.setTitle(title); farmer.setContent(context); farmerMapper.insertSelective(farmer); } }}新建Farmer
package com.spiden.bazaspiden.model;import lombok.Data;/** * @author 张高昌 * @version 1.0 * @date 2024/1/10 17:24 */@Datapublic class Farmer { private String title; private String content;}新建FarmerMapper接口
package com.spiden.bazaspiden.mapper;import com.spiden.bazaspiden.model.Farmer;import org.apache.ibatis.annotations.Mapper;/** * @author 张高昌 * @version 1.0 * @date 2024/1/10 17:22 */@Mapperpublic interface FarmerMapper { int insertSelective(Farmer record);}sql文件
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.spiden.bazaspiden.mapper.FarmerMapper"> <insert id="insertSelective"> insert into news (title, content) values (#{title}, #{content}) </insert></mapper>新建定时任务
package com.spiden.bazaspiden.task;import com.spiden.bazaspiden.pipeline.FarmerPipeline;import com.spiden.bazaspiden.processor.FarmerPageProcessor;import com.spiden.bazaspiden.utils.AppConfig;import com.spiden.bazaspiden.webmagic.selenium.NewSeleniumDownloader;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import us.codecraft.webmagic.Spider;import javax.annotation.Resource;/** * @author 张高昌 * @date 2024/1/4 19:45 * @description: 爬虫定时任务 */@Componentpublic class NewsScheduled { /** * 一定要将Pipeline的实现类交给spring管理 */ @Resource private FarmerPipeline farmerPipeline; //爬取地址目前先写在这里,后续是要爬取多个网站 private String pathUrl = "https://www.farmer.com.cn/farmer/xw/sntt/list.shtml"; /** * 10分钟执行一次 */ @Scheduled(cron = "0 0/10 * * * ? ") public void testFarmer() { Spider spider = Spider.create(new FarmerPageProcessor()); spider.addUrl(pathUrl) .setDownloader(new NewSeleniumDownloader(AppConfig.getChromeDriverPath) .setSleepTime(2000)) //开启5个线程爬取,意味着浏览器会打开5个窗口同时操作 .thread(5) .addPipeline(farmerPipeline) .run();// spider.setExitWhenComplete(true);// spider.start();// spider.stop(); }}这里需要特别特别特别注意的地方是NewSeleniumDownloader()这个类,我是修改了这个类,webmagic作者已经抛弃了phantomjs,如果你想要使用作者的,就必须降低版本否则会出现各种问题,我在这里被坑了很久。
新建NewSeleniumDownloader、WebDriverPool、selenium.properties
package com.spiden.bazaspiden.webmagic.selenium;import org.openqa.selenium.By;import org.openqa.selenium.Cookie;import org.openqa.selenium.WebDriver;import org.openqa.selenium.WebElement;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Request;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.downloader.AbstractDownloader;import us.codecraft.webmagic.selector.Html;import us.codecraft.webmagic.selector.PlainText;import java.io.Closeable;import java.io.IOException;import java.util.Map;/** * @author 张高昌 * @version 1.0 * @date 2024/1/10 13:50 */public class NewSeleniumDownloader extends AbstractDownloader implements Closeable { private volatile WebDriverPool webDriverPool; private Logger logger = LoggerFactory.getLogger(getClass()); private int sleepTime = 0; private int poolSize = 1; /** * 新建 * * @param chromeDriverPath chromeDriverPath */ public NewSeleniumDownloader(String chromeDriverPath) { System.getProperties().setProperty("webdriver.chrome.driver", chromeDriverPath); } /** * Constructor without any filed. Construct PhantomJS browser * * @author bob.li.0718@gmail.com */ public NewSeleniumDownloader() { // System.setProperty("phantomjs.binary.path", // "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs"); } /** * set sleep time to wait until load success * * @param sleepTime sleepTime * @return this */ public NewSeleniumDownloader setSleepTime(int sleepTime) { this.sleepTime = sleepTime; return this; } @Override public Page download(Request request, Task task) { checkInit(); WebDriver webDriver = null; Page page = Page.fail(request); try { webDriver = webDriverPool.get(); logger.info("downloading page " + request.getUrl()); webDriver.get(request.getUrl()); try { if (sleepTime > 0) { Thread.sleep(sleepTime); } } catch (InterruptedException e) { e.printStackTrace(); } WebDriver.Options manage = webDriver.manage(); Site site = task.getSite(); if (site.getCookies() != null) { for (Map.Entry<String, String> cookieEntry : site.getCookies() .entrySet()) { Cookie cookie = new Cookie(cookieEntry.getKey(), cookieEntry.getValue()); manage.addCookie(cookie); } } /* * TODO You can add mouse event or other processes * * @author: bob.li.0718@gmail.com */ WebElement webElement = webDriver.findElement(By.xpath("/html")); String content = webElement.getAttribute("outerHTML"); page.setDownloadSuccess(true); page.setRawText(content); page.setHtml(new Html(content, request.getUrl())); page.setUrl(new PlainText(request.getUrl())); page.setRequest(request); onSuccess(page, task); } catch (Exception e) { logger.warn("download page {} error", request.getUrl(), e); onError(page, task, e); } finally { if (webDriver != null) { webDriverPool.returnToPool(webDriver); } } return page; } private void checkInit() { if (webDriverPool == null) { synchronized (this) { webDriverPool = new WebDriverPool(poolSize); } } } @Override public void setThread(int thread) { this.poolSize = thread; } @Override public void close() throws IOException { webDriverPool.closeAll(); }}package com.spiden.bazaspiden.webmagic.selenium;import org.openqa.selenium.WebDriver;import org.openqa.selenium.chrome.ChromeDriver;import org.openqa.selenium.firefox.FirefoxDriver;//import org.openqa.selenium.phantomjs.PhantomJSDriver;//import org.openqa.selenium.phantomjs.PhantomJSDriverService;import org.openqa.selenium.remote.DesiredCapabilities;import org.openqa.selenium.remote.RemoteWebDriver;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.FileReader;import java.io.IOException;import java.net.MalformedURLException;import java.net.URL;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.Properties;import java.util.concurrent.BlockingDeque;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.atomic.AtomicInteger;/** * @author 张高昌 * @version 1.0 * @date 2024/1/10 13:59 */public class WebDriverPool { private Logger logger = LoggerFactory.getLogger(getClass()); private final static int DEFAULT_CAPACITY = 5; private final int capacity; private final static int STAT_RUNNING = 1; private final static int STAT_CLODED = 2; private AtomicInteger stat = new AtomicInteger(STAT_RUNNING); /* * new fields for configuring phantomJS */ private WebDriver mDriver = null; private boolean mAutoQuitDriver = true; private static final String DEFAULT_CONFIG_FILE = "selenium.properties"; private static final String DRIVER_FIREFOX = "firefox"; private static final String DRIVER_CHROME = "chrome"; private static final String DRIVER_PHANTOMJS = "phantomjs"; protected static Properties sConfig; protected static DesiredCapabilities sCaps; /** * Configure the GhostDriver, and initialize a WebDriver instance. This part * of code comes from GhostDriver. * https://github.com/detro/ghostdriver/tree/master/test/java/src/test/java/ghostdriver * * @author bob.li.0718@gmail.com * @throws IOException */ public void configure() throws IOException { // Read config file sConfig = new Properties(); String configFile = DEFAULT_CONFIG_FILE; if (System.getProperty("selenuim_config")!=null){ configFile = System.getProperty("selenuim_config"); }// sConfig.load(new FileReader(configFile)); sConfig.load(Thread.currentThread().getContextClassLoader().getResourceAsStream(configFile)); // Prepare capabilities sCaps = new DesiredCapabilities(); sCaps.setJavascriptEnabled(true); sCaps.setCapability("takesScreenshot", false); String driver = sConfig.getProperty("driver", DRIVER_PHANTOMJS); // Fetch PhantomJS-specific configuration parameters if (driver.equals(DRIVER_PHANTOMJS)) { // "phantomjs_exec_path" if (sConfig.getProperty("phantomjs_exec_path") != null) {// sCaps.setCapability(// PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,// sConfig.getProperty("phantomjs_exec_path")); } else { throw new IOException(// String.format(// "Property '%s' not set!",// PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY) ); } // "phantomjs_driver_path" if (sConfig.getProperty("phantomjs_driver_path") != null) { System.out.println("Test will use an external GhostDriver");// sCaps.setCapability(// PhantomJSDriverService.PHANTOMJS_GHOSTDRIVER_PATH_PROPERTY,// sConfig.getProperty("phantomjs_driver_path")// ); } else { System.out .println("Test will use PhantomJS internal GhostDriver"); } } // Disable "web-security", enable all possible "ssl-protocols" and // "ignore-ssl-errors" for PhantomJSDriver // sCaps.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, new // String[] { // "--web-security=false", // "--ssl-protocol=any", // "--ignore-ssl-errors=true" // }); ArrayList<String> cliArgsCap = new ArrayList<String>(); cliArgsCap.add("--web-security=false"); cliArgsCap.add("--ssl-protocol=any"); cliArgsCap.add("--ignore-ssl-errors=true");// sCaps.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS,// cliArgsCap); // Control LogLevel for GhostDriver, via CLI arguments// sCaps.setCapability(// PhantomJSDriverService.PHANTOMJS_GHOSTDRIVER_CLI_ARGS,// new String[] { "--logLevel="// + (sConfig.getProperty("phantomjs_driver_loglevel") != null ? sConfig// .getProperty("phantomjs_driver_loglevel")// : "INFO") }); // String driver = sConfig.getProperty("driver", DRIVER_PHANTOMJS); // Start appropriate Driver if (isUrl(driver)) { sCaps.setBrowserName("phantomjs"); mDriver = new RemoteWebDriver(new URL(driver), sCaps); } else if (driver.equals(DRIVER_FIREFOX)) { mDriver = new FirefoxDriver(sCaps); } else if (driver.equals(DRIVER_CHROME)) { mDriver = new ChromeDriver(sCaps); } else if (driver.equals(DRIVER_PHANTOMJS)) {// mDriver = new PhantomJSDriver(sCaps); } } /** * check whether input is a valid URL * * @author bob.li.0718@gmail.com * @param urlString urlString * @return true means yes, otherwise no. */ private boolean isUrl(String urlString) { try { new URL(urlString); return true; } catch (MalformedURLException mue) { return false; } } /** * store webDrivers created */ private List<WebDriver> webDriverList = Collections .synchronizedList(new ArrayList<WebDriver>()); /** * store webDrivers available */ private BlockingDeque<WebDriver> innerQueue = new LinkedBlockingDeque<WebDriver>(); public WebDriverPool(int capacity) { this.capacity = capacity; } public WebDriverPool() { this(DEFAULT_CAPACITY); } /** * * @return * @throws InterruptedException */ public WebDriver get() throws InterruptedException { checkRunning(); WebDriver poll = innerQueue.poll(); if (poll != null) { return poll; } if (webDriverList.size() < capacity) { synchronized (webDriverList) { if (webDriverList.size() < capacity) { // add new WebDriver instance into pool try { configure(); innerQueue.add(mDriver); webDriverList.add(mDriver); } catch (IOException e) { e.printStackTrace(); } // ChromeDriver e = new ChromeDriver(); // WebDriver e = getWebDriver(); // innerQueue.add(e); // webDriverList.add(e); } } } return innerQueue.take(); } public void returnToPool(WebDriver webDriver) { checkRunning(); innerQueue.add(webDriver); } protected void checkRunning() { if (!stat.compareAndSet(STAT_RUNNING, STAT_RUNNING)) { throw new IllegalStateException("Already closed!"); } } public void closeAll() { boolean b = stat.compareAndSet(STAT_RUNNING, STAT_CLODED); if (!b) { throw new IllegalStateException("Already closed!"); } for (WebDriver webDriver : webDriverList) { logger.info("Quit webDriver" + webDriver); webDriver.quit(); webDriver = null; } }}selenium.properties配置文件
# What WebDriver to use for the tests#driver=phantomjs#driver=firefoxdriver=chrome#driver=http://localhost:8910#driver=http://localhost:4444/wd/hub# PhantomJS specific config (change according to your installation)#phantomjs_exec_path=/Users/Bingo/bin/phantomjs-qt5#phantomjs_exec_path=d:/phantomjs.exe#chrome_exec_path=E:\\demo\\crawler\\chromedriver.exe#phantomjs_driver_path=/Users/Bingo/Documents/workspace/webmagic/webmagic-selenium/src/main.js#phantomjs_driver_loglevel=DEBUGchrome_driver_loglevel=DEBUG
如果你想使用作者提供的或者对作者写的感兴趣可以看这里:
https://github.com/code4craft/webmagic/blob/develop/webmagic-selenium/src/main/java/us/codecraft/webmagic/downloader/selenium/SeleniumDownloader.java
最后一步在springboot启动类上面加上@EnableScheduling
@EnableScheduling@SpringBootApplicationpublic class BazaSpidenApplication { public static void main(String[] args) { SpringApplication.run(BazaSpidenApplication.class, args); }}启动项目:
看下数据库
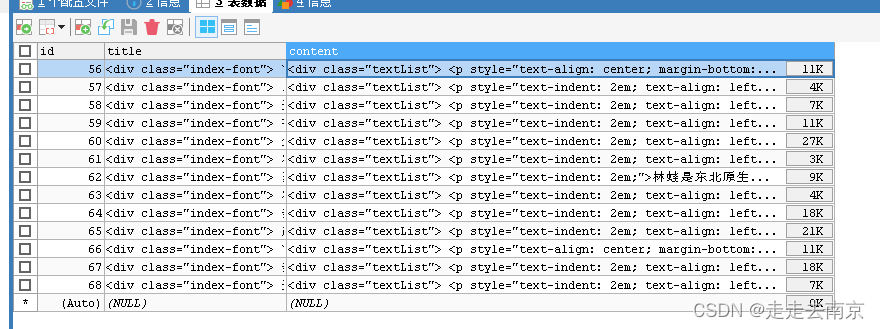
完整的代码地址:baza-spiden: springboot整合webmagic+mybatis入库
总结
这里需要特别注意的就是谷歌浏览器的版本以及谷歌驱动的版本,这2个如果不对就会出现各种神奇的问题。还有就是selenium-java这个包也很重要。
这里本来时想按照我写代码时出现的问题一个个都写上去的,后面想想太麻烦了,就把这个过程直接省掉了。
这里爬虫的基本操作就结束了,但是有几个问题在这里:
1.以我们公司实际的需求为例,要求爬取50多个跟农业相关的网站,每个网站的页面布局又不一样,规则也不一样。
2.xpath的规则谁来填写?总不能让我来去一个个网站找到,然后再在代码里写好xpath规则吧?
3.因为我这里爬取的是新闻网站,领导要求把图片保存到我们自己的服务器。
4.每个网站的页面文章样式,布局是不一样的,我这里需要将那些样式全部都去除掉。(好吧,天大地大,领导要求的最大)