【Linux】封装一下简单库 && 理解文件系统
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
一、封装一下简单库
二、理解一下stdin(0)、stdout(1)、stderr(3)
2.1、为什么要有0、1、2呢?
2.2、特点
2.3、如果我想让2也和1重定向到一个文件中?
三、理解文件系统
3.1、看看物理磁盘
3.2、了解一下磁盘的储存结构
3.3、对磁盘的存储进行逻辑抽象
3.4、找到一个文件的步骤:
3.5、逆向的路径解析 --- OS自己做的
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
一、封装一下简单库
Stdio.h#pragma once#include <string.h>#include <stdlib.h>#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>#define LINE_SIZE 1024#define FLUSH_NOW 1#define FLUSH_LINE 2#define FLUSH_FULL 4// 文件结构体类型struct _myFILE{ unsigned int flags; int fileno; // 缓冲区 char cache[LINE_SIZE];// 文件的缓冲区 int cap; int pos; // 下次写入的位置};typedef struct _myFILE myFILE;myFILE* my_fopen(const char* path, const char* flag);void my_fflush(myFILE* fp);ssize_t my_fwrite(myFILE* fp, const char* data, int len);void my_fclose(myFILE* fp);Mystdio.c#define _CRT_SECURE_NO_WARNINGS 1#include "mystdio.h"myFILE* my_fopen(const char* path, const char* flag){ int flag1 = 0;// 打开文件的模式 int iscreate = 0;// 是否要创建文件 mode_t mode = 0666;// 文件的初始权限 if (strcmp(flag, "r") == 0) { flag1 = (O_RDONLY); } else if (strcmp(flag, "w") == 0) { flag1 = (O_WRONLY | O_CREAT | O_TRUNC); iscreate = 1; } else if (strcmp(flag, "a") == 0) { flag1 = (O_WRONLY | O_CREAT | O_APPEND); iscreate = 1; } else { } int fd = 0; // 根据是否要创建文件来使用不同的open()函数 if (iscreate) fd = open(path, flag1, mode); else fd = open(path, flag1); if (fd < 0) return NULL; myFILE* fp = (myFILE*)malloc(sizeof(myFILE)); if (!fp) return NULL; fp->fileno = fd; fp->flags = FLUSH_LINE;// 行刷新 fp->cap = LINE_SIZE;// 缓冲区的容量 fp->pos = 0;// 当前写入文件的位置 return fp;}void my_fflush(myFILE* fp){ write(fp->fileno, fp->cache, fp->pos); fp->pos = 0;}// 写入数据:把用户将数据写入stdout文件当中(语言级的文件缓冲区内),将语言级的缓冲区内的内容拷贝到OS的内核级的缓冲区内ssize_t my_fwrite(myFILE* fp, const char* data, int len){ // 写入操作本质是拷贝, 如果条件允许,就刷新,否则不做刷新 // 将数据拷贝到语言级的缓冲区 memcpy(fp->cache + fp->pos, data, len); //肯定要考虑越界, 自动扩容 fp->pos += len; if ((fp->flags & FLUSH_LINE) && fp->cache[fp->pos - 1] == '\n') { // 将语言级的缓冲区的数据拷贝到OS中对应的文件的内核级缓冲区 my_fflush(fp); } return len;}void my_fclose(myFILE* fp){ my_fflush(fp); close(fp->fileno); free(fp);}Testfile.c#define _CRT_SECURE_NO_WARNINGS 1#include "mystdio.h"#include <string.h>#include <stdio.h>#include <unistd.h>#define FILE_NAME "log.txt"int main(){ myFILE* fp = my_fopen(FILE_NAME, "w"); if (fp == NULL) return 1; const char* str = "hello bit"; int cnt = 10; char buffer[128]; while (cnt) { sprintf(buffer, "%s - %d", str, cnt); my_fwrite(fp, buffer, strlen(buffer)); // strlen()+1不需要 cnt--; sleep(1); my_fflush(fp); } my_fclose(fp); return 0;}结论:C语言为什么要在FILE中提供用户级缓冲区 ----- 为了减少底层调用系统调用的次数,让使用C语言的IO函数(printf,fprintf)效率更高。
二、理解一下stdin(0)、stdout(1)、stderr(3)
2.1、为什么要有0、1、2呢?
0、1 -----> 用户要知道数据从哪里来,数据要到哪里去。2 -----> 把正确的信息和错误的信息区分开来。2.2、特点
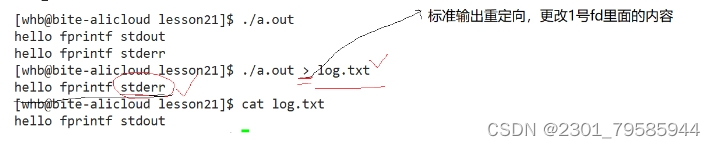
我们是要将原本打印在屏幕行的数据打印在 log.txt 里,为什么stderr还在屏幕上显示?
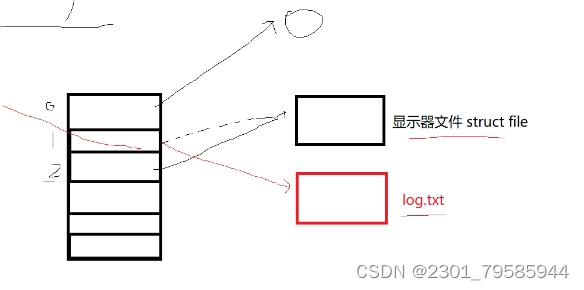
标准输出重定向的本质:更改文件描述符表中下标为1的内容(地址)。下标为1的内容原先是显示器文件的地址,现在更改为 log.txt 文件的地址。
下标为1和下标为2的空间的地址都是指向显示器文件的;下标为2的空间中的地址没有被改变,依然指向显示器文件的地址。所以,stderr仍然打印在屏幕上。
2.3、如果我想让2也和1重定向到一个文件中?
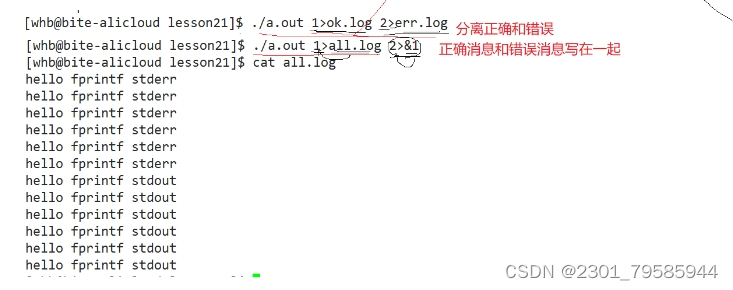
./a.out 1>ok.log 2>err.log将下标为1的内容更改成 ok.log 文件的地址;将下标为2的内容更改成 err.log 文件的地址;将正确和错误的信息分离开来。
./a.out 1>all.log 2>&1将下标为1的内容更改成 all.log 文件的地址;取下标为1的内容的地址更改下标为2的内容;从而使2和1重定向到一个文件中。

C语言中的 perror 本质是向2对应的文件打印,printf() 本质是向1对应的文件打印。
C++中的 cout 对应的是 printf;cerr 对应的是 perror。
三、理解文件系统
3.1、看看物理磁盘


3.2、了解一下磁盘的储存结构
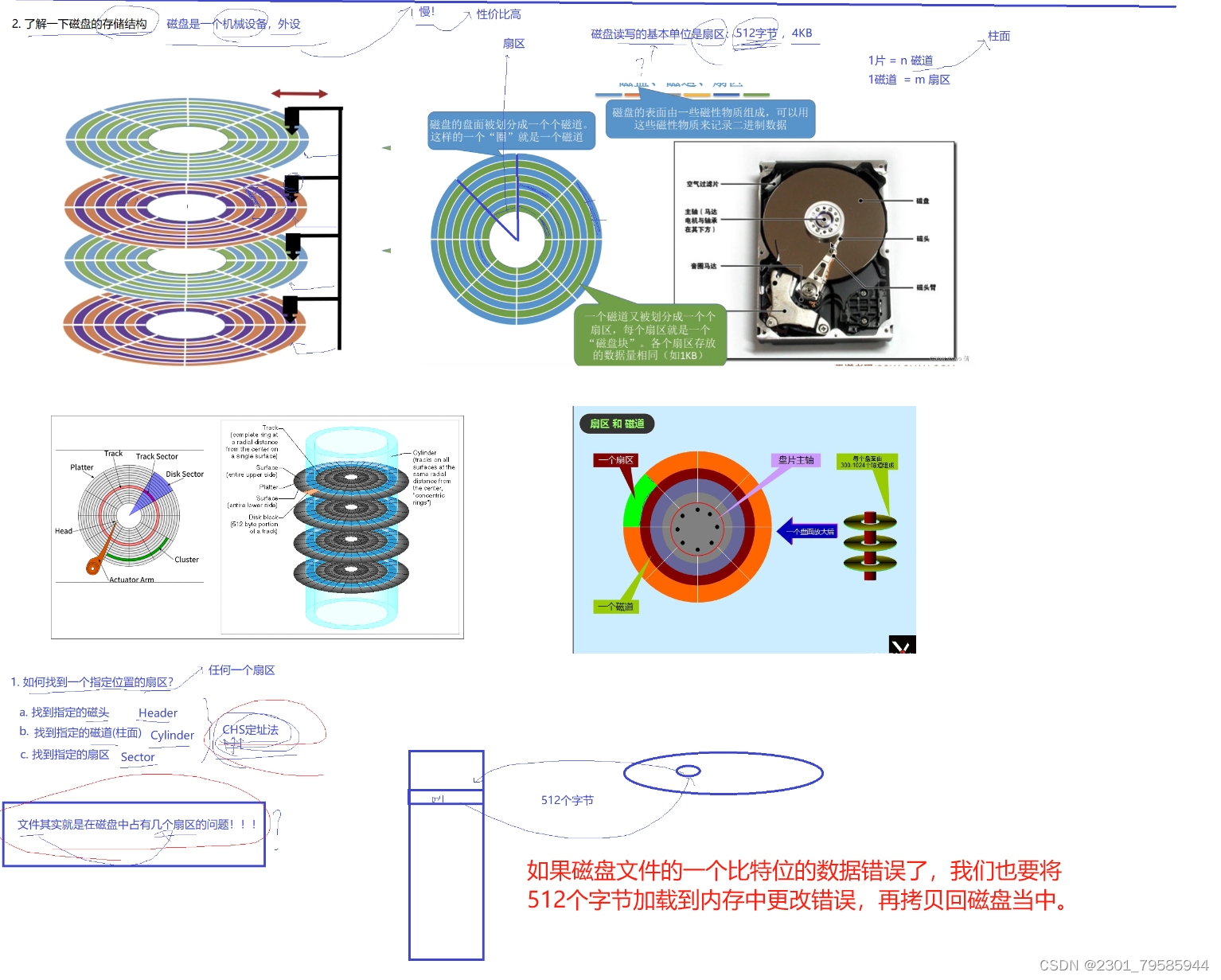
3.3、对磁盘的存储进行逻辑抽象
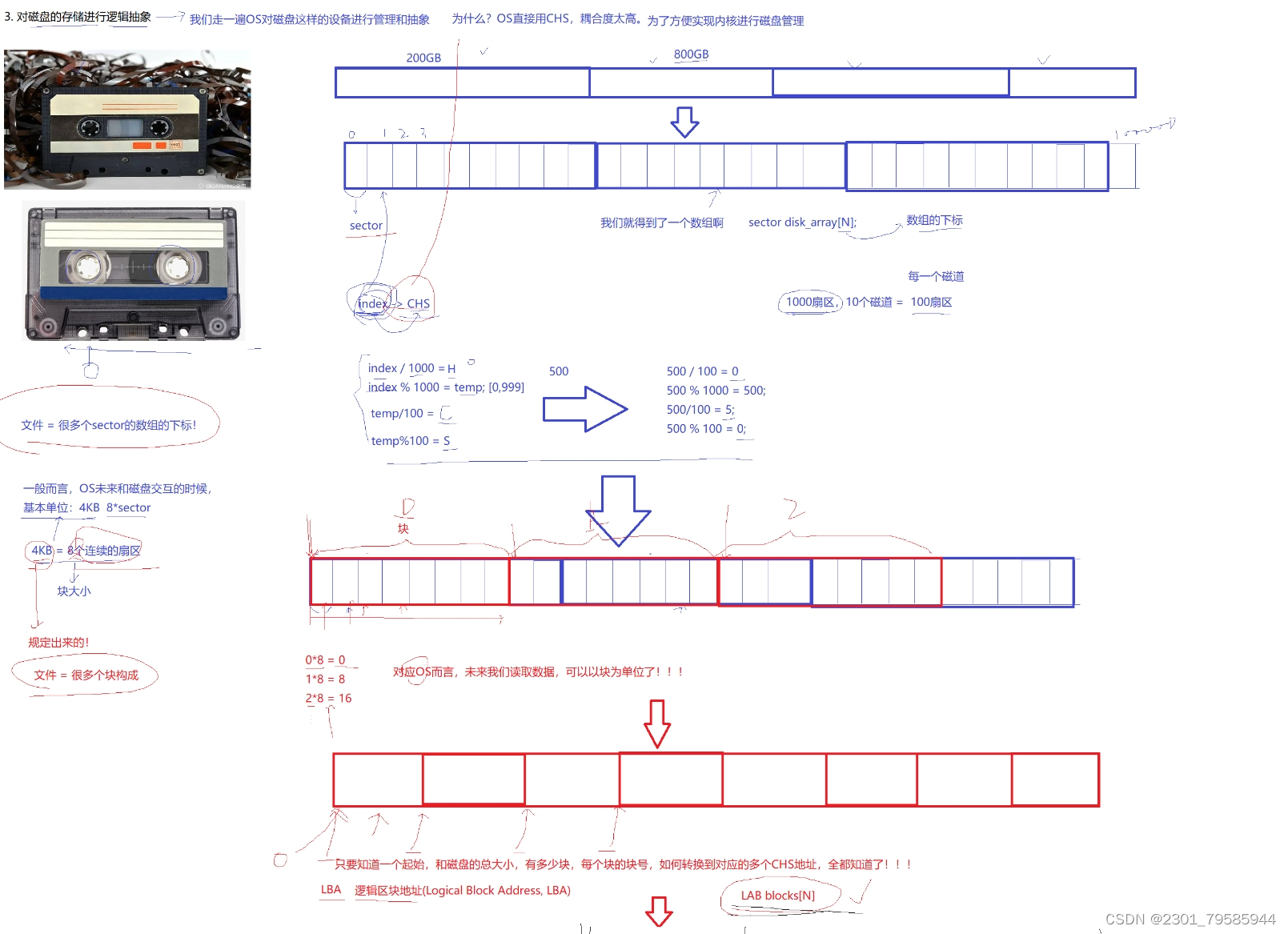
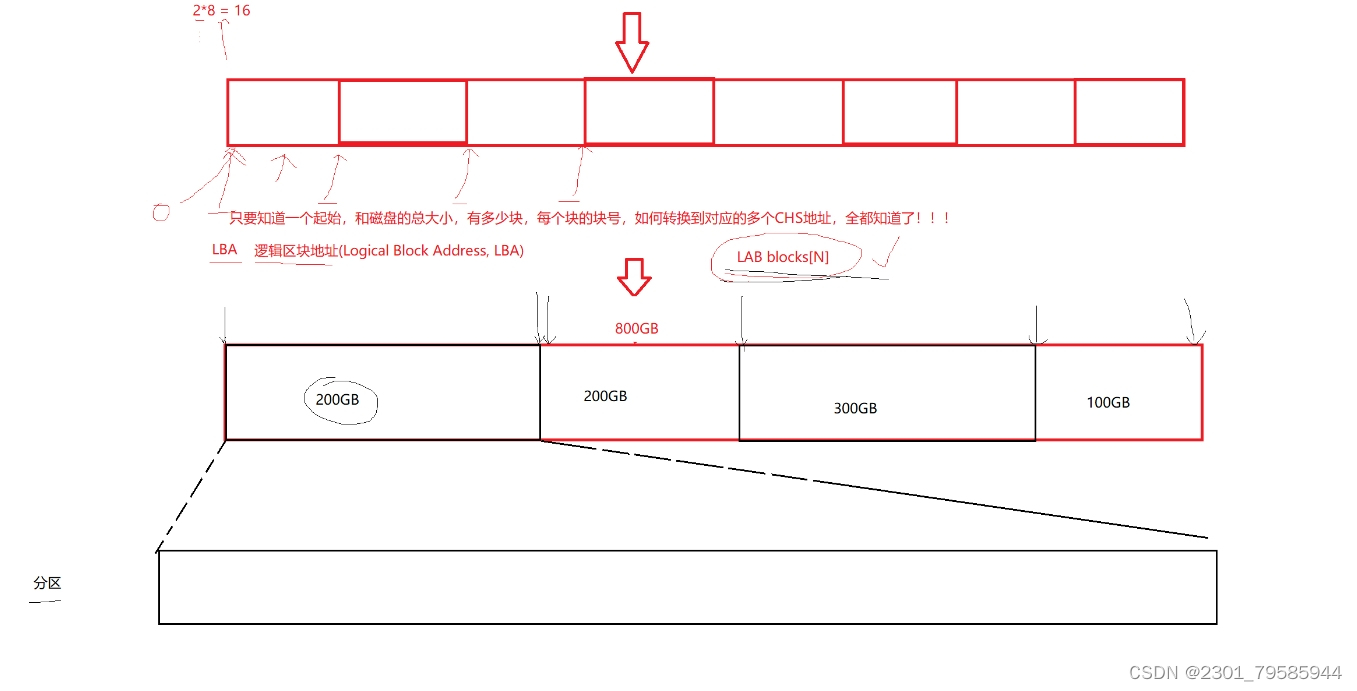
假如:一个磁盘有800GB,我们把800GB分为4个区,每个区200GB,再将每个分区分组,我们只要管理好每一个分组,就能管理好一个分区,进而管理好磁盘。
格式化:在每一个分区内部分组,然后写入文件系统的管理数据。
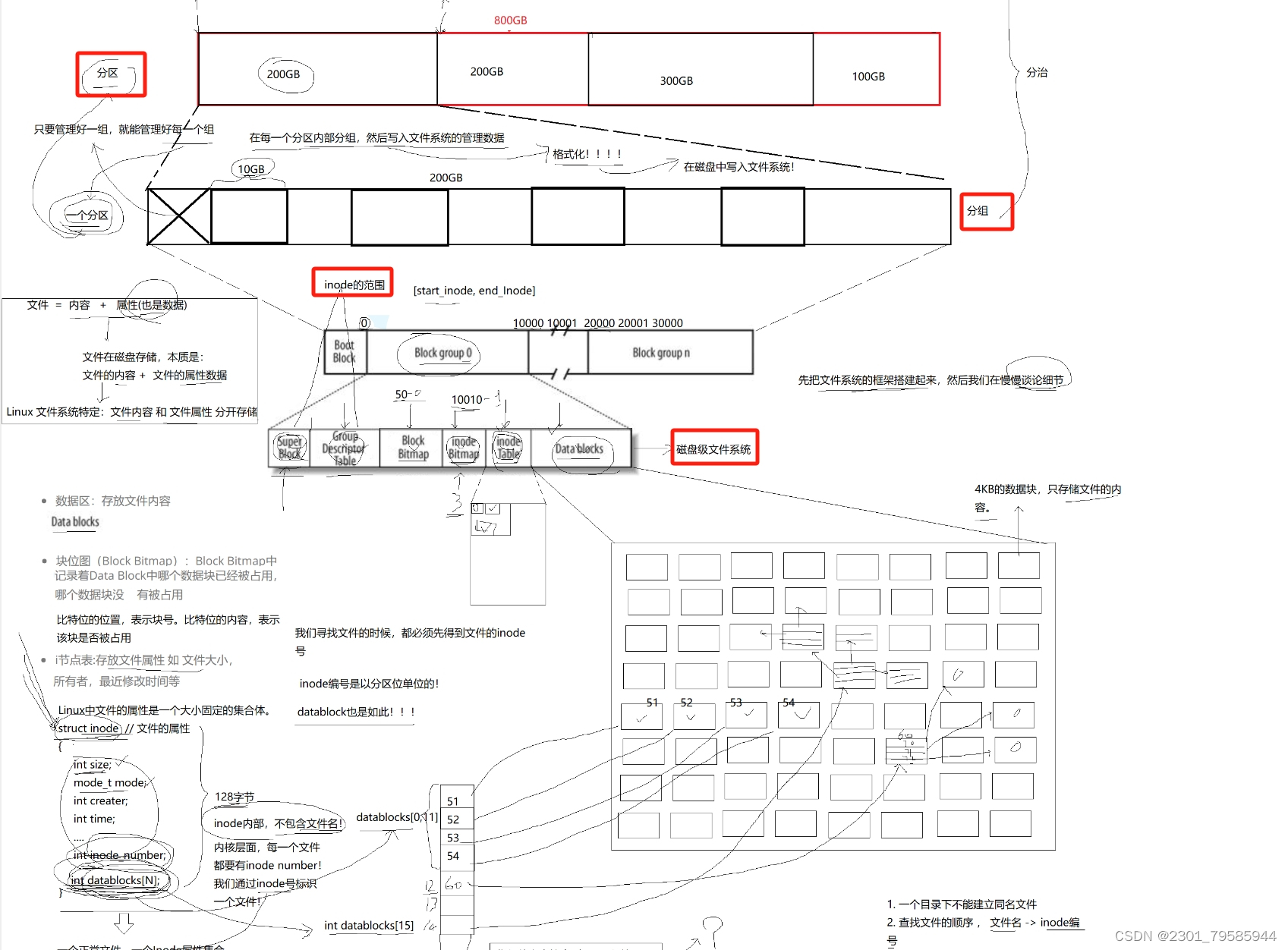
文件在磁盘存储的本质:=文件的内容+文件的属性数据。
Linux文件系统特定:文件内容和文件属性分开存储。
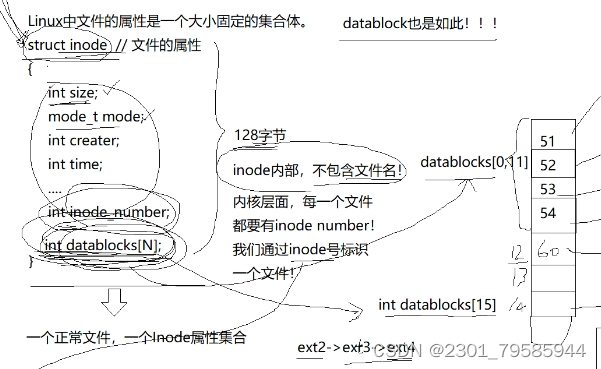
Block Group:许多个数据块(4kb)组成,用来存放文件的内容。超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:block 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了GDT,Group Descriptor Table:块组描述符,描述整个分组里的使用情况,比如:一共有多少inode,一共有多少数据块呢?inode、数据块和Bitmap已经被占据了多少呢?那么下一个被分配的inode编号是几?由GDT来进行统一管理。块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用(比特位的位置,表示块号。比特位的内容,表示该块是否被占用。)inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。i节点表:存放文件属性,如:文件大小,所有者,最近修改时间等。超级块(Super Block):不是每个分组都有的。分配inode编号的范围。如果一个磁盘的某一分组的Super Block不小心被刮花了,那么可以通过其它分组的Super Block来恢复。我们寻找文件的时候,都必须先得到inode的编号。inode编号是以分区为单位的!
但是你凭什么直接拿到inode的编号,我们一直使用的都是文件名啊!!!!
谈谈目录:
目录 = 文件属性 + 文件内容。 目录也是一个文件。
一个目录下不能建立同名文件;查找文件的顺序,文件名 -----> inode的编号;目录的r,本质是是否允许我们读取目录的内容;目录的内容是:文件名与inode的映射关系!!!目录的w,新建文件,最后一定要向当前所处的目录内容中写入,文件名与inode的映射关系。如何理解文件的增删查改呢?
增:建立文件名与inode的映射关系。删:将该文件的inode编号在位图中对应的比特位置为0。我们常说的将系统格式化,恢复出厂设置,其实就是将位图中的1全部置为0。
3.4、找到一个文件的步骤:
我们找到一个指定的文件 -----> 文件所在的目录 ------> 打开目录 -----> 根据文件名与inode的映射关系 -----> 找到目标文件inode。
但是有一个前提是:inode的编号是不能跨分区的,我们怎么才能知道我们的文件在哪一个分区内呢?
结论:比如:我用的云服务器一般只有一个盘(vda),一个盘对应了一个分区,在Linux中要访问一个分区其实要将这个分区进行挂载的,挂载也就是将一个磁盘分区和文件系统的一个目录进行关联,所以,未来进入分区,其实是进入一个指定的目录的。
分区 ----> 写入文件系统(格式化)(就是将在分组中写入管理的数据,但是此时这个分区还不能使用) ----> 挂载到指定目录下 ----> 进入该目录,自然就在该目录的分区下 ----> 在指定的分区中进行文件操作。
这也就是我们在Linux系统中,定位一个文件,在任何时候,都要有路径的原因!!!因为有路径,你就知道在哪个分区。
3.5、逆向的路径解析 --- OS自己做的
要打开当前目录,当前目录也是一个文件,你得找到当前目录的inode,那么你就得找到当前目录的上级目录;所以Linux在找到任何一个路径下的一个文件时,Linux系统一定要给我们逆向的递归式的路径解析;直到找到了根目录,就类似于找到了一个递归出口一般,然后再反向的逐次打开我们的文件。
逆向的路径解析,我们的Linux系统会一直做,那么必然会导致效率方面下降,所以Linux系统为了支持逆向路径解析,系统会把已经解析过的路径给我们进行缓存起来;那么将来要打开文件时,把要解析的路径,先在缓存里找,找不到,再解析。
总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
登录后可发表评论
点击登录