
目录
一.引言
二.SnowNLP 情感分析
1.安装 SnowNLP
2.测试 SnowNLP
三.SnowNLP 自定义训练
1.数据集准备
2.训练与保存
3.模型替换
4.模型测试
5.SnowNLP 原理
◆ Bayes 公式
◆ 先验概率
◆ 后验概率
◆ 情感模型
四.总结
一.引言
SnowNLP 是一个基于 Python 的简洁的自然语言处理工具包,它提供了文本情感分析、关键词提取、文本分类等功能。该工具包具有简单易用的接口,可帮助用户快速实现文本处理和情感分析任务。SnowNLP 的设计理念是简洁高效,它采用了一些先进的自然语言处理算法,同时也尽量减少了不必要的复杂性,使得用户可以轻松地应用它来处理文本数据。本文主要包括两部分:
◆ SnowNLP 情感分析
◆ SnowNLP 自定义训练
二.SnowNLP 情感分析
1.安装 SnowNLP
pip install snownlp -i https://pypi.tuna.tsinghua.edu.cn/simple
出现 Successfully 即为安装成功,博主这里 Py == 3.8、snownlp == 0.12.3。
2.测试 SnowNLP
from snownlp import SnowNLPdef sentiment_analysis(text): # 使用SnowNLP对中文文本进行情感分析 s = SnowNLP(text) # SnowNLP的sentiments方法返回情感倾向分数,越接近1表明情感越积极,越接近0表明情感越消极 sentiment_score = s.sentiments return sentiment_score直接调用 SnowNLP 方法获取中文文本情感,这里返回 sentiment_score,以 0.5 为界限,越接近于 1 越积极,反之越消极。
text = "角色塑造太单调,毫无震撼力!" score = sentiment_analysis(text) print(f"情感分数: {score}") if score > 0.5: print("该语句是积极的。") else: print("该语句是消极的。")
三.SnowNLP 自定义训练
1.数据集准备
自定义训练数据集主要在原生 SnowNLP 无法满足自己场景的情况下,可以自定义积极、消极的文本,按行放置到 txt 文件中,供 sentiment 进行调整。下面以影视评价为例,pos 和 neg 各添加 100 条影评信息。
◆ pos.txt

◆ neg.txt
2.训练与保存
from snownlp import sentimentdef train_self_model(): pos = "./pos.txt" neg = "./neg.txt" sentiment.train(neg, pos) sentiment.save("sentiment.marshal")训练结束后会在输出目录得到一个 .marshal.3 的文件:

3.模型替换
要使用自己生成的 marshal 模型需要到 python site-package 库里把 SnowNLP sentiment 原始的 mershal.3 模型文件替换掉。
◆ 获取 Site-Packages 路径
在当前 python 环境目录下执行下述脚本获取 Site-Packages 文件路径:
def get_site_pkg_path(): import site # Add snownlp/sentiment return site.getsitepackages()[0]执行后获取对应 Site-Packages 路径地址:
cd /Users/XXX/miniforge3/PythonTest/lib/python3.8/site-packages
◆ 修改 mershal 模型
cd snownlp/sentiment备份 sentiment 库文件夹下的 sentiment.marshal.3 文件,将我们 output 的模型文件 cp 到这里。
Tips:
最好备份下原始的模型,要不然将来需要还得再 pip install。
4.模型测试
继续调用第二节情感分析一节的 sentiment_analysis 函数测试。
◆ 完整的训练负样本
使用训练过的负样本会得到非常逼近区间 [0,1] 的分数,正样本大家也可以测试下。
text = "角色塑造太单调,毫无震撼力!" score = sentiment_analysis(text) ----------------------------- 情感分数: 3.992483776915634e-07 该语句是消极的。
◆ 删减的训练负样本
使用删减过的负样本同样可以得到可靠的情感分析分数。
text = "毫无震撼力!" score = sentiment_analysis(text) ------------------------------- 情感分数: 0.004951768064722417 该语句是消极的。
◆ Bad Case 分析
自定义训练模型后原始判定为消极的句子可能判定为积极,我们去掉消极词后可以看到是由于其他词的 Positive Ratio 太高,从而把 Negative 的词的 Ratio 带高了,从而造成误判。所以如果大家使用自定义模型,需要注意其可能在你的专业领域得到靠谱的情感分析,但是之前的泛化能力受到影响。
text = "这个产品真的很垃圾!" 情感分数: 0.9208253155767703 该语句是积极的。 ------------------------- text = "这个产品真的很!" 情感分数: 0.9480748399538199 该语句是积极的。
5.SnowNLP 原理
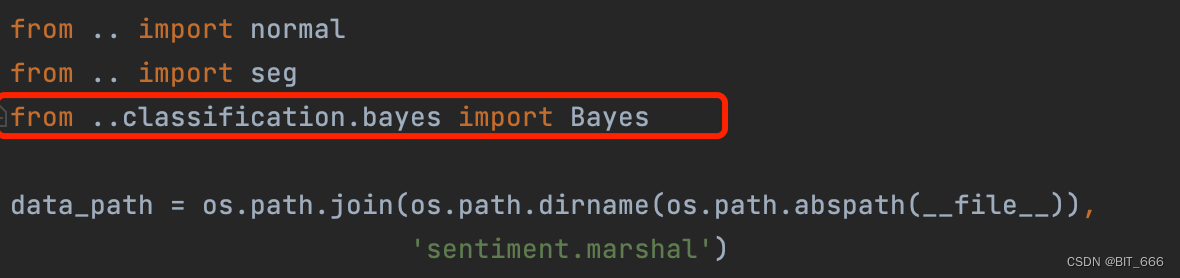
上面是 sentiment 的 __init__ 初始化代码,可以看到其使用的模型类型为 Bayes 概率统计模型,这个模型我们之前在机器学习部分讲过,其通过计算条件概率进行情感分析,核心思想是通过训练样本的分词结果构建先验概率分布,再基于先验概率分布计算出现某个情况后的后验概率。
◆ Bayes 公式

◆ 先验概率

假设男生女生各 50 人,其通过 B/G 代表,则 P(B) = P(G) = 50 / (50 + 50) = 0.5。
其次规定事件 T 为是否穿长裤,其中男生 75% 的概率穿长裤,即 P(T|B) = 0.75,女生 50% 的概率穿长裤,即 P(T|G) = 0.5,这里 P(T|B/G) 即为先验概率,是我们通过概率统计计算而得。
◆ 后验概率
由条件概率公式可得,可以理解为穿长裤的男生的数量与男生穿长裤的数量一致:
P(BT) = P(B) * P(T|B) = P(T) * P(B|T)
由全概率公式可得,可以理解为穿长裤的概率等于男生、女生穿长裤的概率之和:
P(T) = P(B) * P(T|B) + P(G) * P(T|G)
所以可以推导出:
P(B|T) = P(B)·P(T|B) / P(T)
这里 P(B) 男生的概率、P(T) 穿长裤的概率、P(T|B) 男生穿长裤的概率都有,计算可得穿长裤的是男生的概率 P(B|T)。
◆ 情感模型
而对于上面情感分析的场景,我们 P(Sentiment) 即为积极 P、消极 N 两种选择,我们获取 text 进行分词得到 w1、w2 且可以得到 P(S|Wi) 即当前词的情感,从而最后推导出情感分析的概率计算:
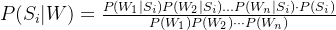
其中 Wi 为 Text W 中文本分词的结果,Si 对应 P、N 两种情感,我们计算 P(Si|W) 即文本对应的情感 S,P(Wi) 为对应词语出现的频次,P(Wi|Si) 为积极或消极场景中该词出现的概率,以此类推即可计算 Score。
四.总结
SnowNLP 采用 Bayes 模型,支持自定义训练,开箱即用也很轻便,有需要情感分析的同学可以使用,当然语言模型 Bert 甚至大模型 LLM 现在也具备该场景功能,有兴趣的同学也可以微调模型获得更专业的情感分析模型。
完整的 Bayes 实战代码可以参考: 朴素贝叶斯-分类及Sklearn库实现 机器学习实战。