NVIDIA Container Runtime官网
GitHub仓库:Docker 是开发人员采用最广泛的容器技术。借助 NVIDIA Container Runtime,开发人员只需在创建容器期间注册一个新的运行时,即可将 NVIDIA GPU 暴露给容器中的应用程序。用于 Docker 的 NVIDIA Container Runtime 是托管在GitHub 上的开源项目。
文章目录
简介安装环境要求开始安装 使用示例添加 NVIDIA Runtime设置环境变量GPU枚举驱动功能约束DockerfileDocker ComposeCompose v2.3 写法更精细的控制
简介
NVIDIA Container Runtime is a GPU aware container runtime, compatible with the Open Containers Initiative (OCI) specification used by Docker, CRI-O, and other popular container technologies. It simplifies the process of building and deploying containerized GPU-accelerated applications to desktop, cloud or data centers.
NVIDIA Container Runtime 是一种 GPU 感知容器运行时,与 Docker、CRI-O 和其他流行容器技术使用的 Open Containers Initiative (OCI) 规范兼容。 它简化了构建容器化 GPU 加速应用程序并将其部署到桌面、云或数据中心的过程。
With NVIDIA Container Runtime supported container technologies like Docker, developers can wrap their GPU-accelerated applications along with its dependencies into a single package that is guaranteed to deliver the best performance on NVIDIA GPUs, regardless of the deployment environment.
借助 NVIDIA Container Runtime 支持的容器技术(如 Docker),开发人员可以将其 GPU 加速应用程序及其依赖项打包到一个包中,无论部署环境如何,都能保证在 NVIDIA GPU 上提供最佳性能。
安装
本文参考NVIDIA Container Toolkit 官方安装文档在 Ubuntu 22.04 中安装
环境要求
已安装 NVIDIA Linux 驱动程序,且版本 >= 418.81.07内核版本 > 3.10 的GNU/Linux x86_64Docker >= 19.03架构 >= Kepler(或计算能力 3.0)的 NVIDIA GPU开始安装
设置包存储库和 GPG 密钥distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listsudo apt-get updateupdate可能会报错:
sudo apt-get update
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.
解决方案参见官方文档Conflicting values set for option Signed-By error when running apt update
sudo apt-get install -y nvidia-docker2sudo nvidia-ctk runtime configure --runtime=dockersudo systemctl restart dockersudo docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi看到类似如下的输出说明安装成功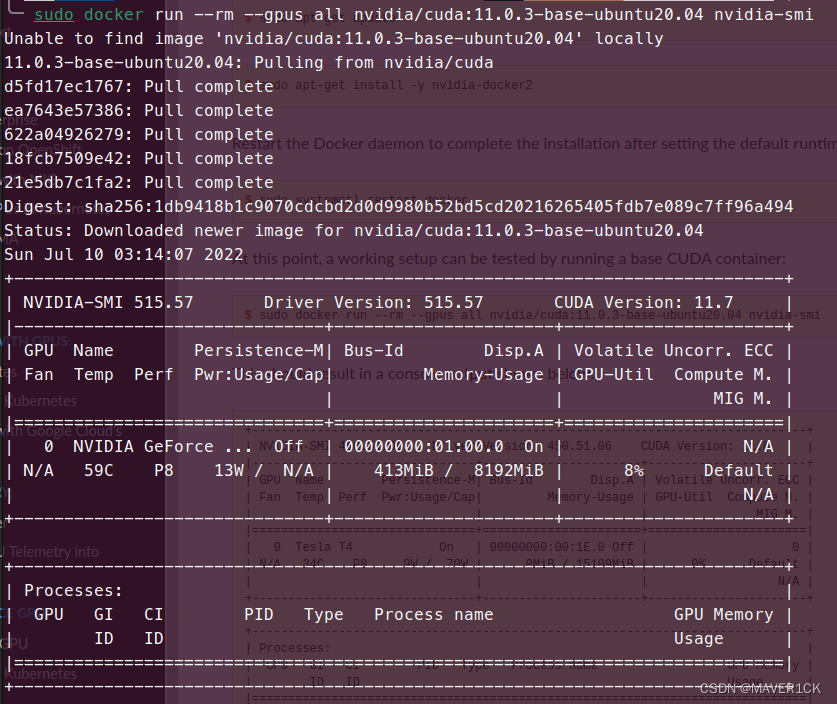
使用示例
参考官方文档User Guide
添加 NVIDIA Runtime
因为在上文中已经安装了 nvidia-docker2 所以不需要添加 NVIDIA Runtime
设置环境变量
用户可以使用环境变量控制 NVIDIA 容器运行时的行为——尤其是枚举 GPU 和驱动程序的功能。
而在NVIDIA提供的基本的CUDA镜像中已经设置好了这些环境变量。
GPU枚举
使用 --gpus 或使用环境变量 NVIDIA_VISIBLE_DEVICES 可以控制容器能够使用哪些GPU
NVIDIA_VISIBLE_DEVICES 的取值如下所示
Possible values | Description |
|---|---|
| a comma-separated list of GPU UUID(s) or index(es).(GPU UUID 或索引的逗号分隔列表) |
| all GPUs will be accessible, this is the default value in base CUDA container images.(所有的GPU都可以使用,这是基本的CUDA容器镜像使用的默认值) |
| no GPU will be accessible, but driver capabilities will be enabled.(所有GPU都不能使用,但启用了驱动程序的功能) |
|
|
当使用 --gpu 指定GPU时,应同时使用 device 参数,示例如下
docker run --gpus '"device=1,2"' \ nvidia/cuda nvidia-smi --query-gpu=uuid --format=csv启用所有的GPU
docker run --rm --gpus all nvidia/cuda nvidia-smi使用 NVIDIA_VISIBLE_DEVICES 启用所有的GPU
docker run --rm --runtime=nvidia \ -e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda nvidia-smi使用 NVIDIA_VISIBLE_DEVICES 启用指定的GPU
docker run --rm --runtime=nvidia \ -e NVIDIA_VISIBLE_DEVICES=1,2 \ nvidia/cuda nvidia-smi --query-gpu=uuid --format=csv启用两个GPU(Start a GPU enabled container on two GPUs)
docker run --rm --gpus 2 nvidia/cuda nvidia-smi使用 nvidia-smi 查询 GPU UUID 然后将其指定给容器
nvidia-smi -i 3 --query-gpu=uuid --format=csvuuid
GPU-18a3e86f-4c0e-cd9f-59c3-55488c4b0c24
docker run --gpus device=GPU-18a3e86f-4c0e-cd9f-59c3-55488c4b0c24 \ nvidia/cuda nvidia-smi驱动功能
NVIDIA_DRIVER_CAPABILITIES 控制将哪些驱动程序库/二进制文件挂载到容器中
NVIDIA_DRIVER_CAPABILITIES 取值如下
Possible values | Description |
|---|---|
| a comma-separated list of driver features the container needs.(容器需要的驱动程序功能的逗号分隔列表) |
| enable all available driver capabilities.(启用所有可用的驱动程序功能) |
empty or unset | use default driver capability: |
Driver Capability | Description |
|---|---|
| required for CUDA and OpenCL applications. |
| required for running 32-bit applications. |
| required for running OpenGL and Vulkan applications. |
| required for using |
| required for using the Video Codec SDK. |
| required for leveraging X11 display. |
例如,指定 compute 和 utility ,两种写法
docker run --rm --runtime=nvidia \ -e NVIDIA_VISIBLE_DEVICES=2,3 \ -e NVIDIA_DRIVER_CAPABILITIES=compute,utility \ nvidia/cuda nvidia-smidocker run --rm --gpus 'all,"capabilities=compute,utility"' \ nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi约束
NVIDIA runtime 还为容器提供了在配置文件中定义约束的功能
NVIDIA_REQUIRE_* 是一个逻辑表达式,用于定义容器上的软件版本或 GPU 架构的约束,下面是约束的具体内容
Constraint | Description |
|---|---|
| constraint on the CUDA driver version. |
| constraint on the driver version. |
| constraint on the compute architectures of the selected GPUs. |
| constraint on the brand of the selected GPUs (e.g. GeForce, Tesla, GRID). |
NVIDIA_REQUIRE_CUDA "cuda>=11.0 driver>=450"更多内容查看原文
Dockerfile
可以通过环境变量设置,例如
ENV NVIDIA_VISIBLE_DEVICES allENV NVIDIA_DRIVER_CAPABILITIES compute,utilityDocker Compose
参考Docker 官方文档中的教程
Compose v2.3 写法
services: test: image: nvidia/cuda:10.2-base command: nvidia-smi runtime: nvidia这种写法无法控制GPU的具体属性
更精细的控制
capabilities值指定为字符串列表(例如。capabilities: [gpu])。您必须在 Compose 文件中设置此字段。否则,它会在服务部署时返回错误。count
指定为 int 的值或all表示应保留的 GPU 设备数量的值(假设主机拥有该数量的 GPU)。device_ids
指定为表示来自主机的 GPU 设备 ID 的字符串列表的值。可以在主机上的 nvidia-smi 输出中找到设备 ID 。driver
指定为字符串的值(例如driver: ‘nvidia’)options
表示驱动程序特定选项的键值对。
count 和 device_ids是互斥的。您一次只能定义一个字段。
有关这些属性的更多信息,请参阅 Compose Specification deploy中的部分。
例如,使用主机上的所有GPU和指定的驱动程序功能(虽然NVIDIA_DRIVER_CAPABILITIES取值可以是all,但是这里不能写all,会报错,只能写清楚每一个)
services: test: image: nvidia/cuda:10.2-base command: nvidia-smi deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [compute,graphics,video,utility,display]更多设置示例参见官方文档