利用openpose提取自建数据集骨骼点训练st-gcn,复现st-gcn
0、下载st-gcn
参考:
gitbub上fork后导入到gitee快些: st-gcn下载
也可以直接下载zip文件后解压
1、处理准备自己数据集
数据集要求将相同类别的视频放到同一文件夹,我这里用到一个较老的数据集:training_lib_KTH.zip,六种行为放到六个不同文件夹。
用于st-gcn训练的数据集视频帧数不要超过300帧,5~6s的视频时长比较好,不要10几s的视频时长。要不然会报
index 300 is out of bounds for axis 1 with size 300这种错误。因此对上面数据集进一步裁剪为6s的大概150帧(此视频帧率为25后面利用FFmpeg再次改变帧率为30时,时长会变长到8s)。裁剪后视频文件如下
原始数据集和裁剪为6s的数据集放在链接:
链接:https://pan.baidu.com/s/1oHQyo-c3e5YXb52b-O0STQ?pwd=x166
提取码:x166
2、准备环境,搭建openpose环境
搭建openpose环境是为了利用open pose提取knetics-skeleton视频的骨骼点,openpose环境的搭建可参考以下视频:openpose环境搭建
以及参考博客:windows 10下,自编译openpose代码此处注意如果用cuda,最好先下载vs后再下载cuda
3、利用openpose提取自己视频骨骼数据
st-gcn作者有提供他们整理好并使用的kinetics-skeleton数据集,他们数据集格式如下图所示:
接下来参考:用自建kinetics-skeleton行为识别数据集训练st-gcn网络流程记录中的2部分对视频数据进行resize至340x256的大小,30fps的帧率。然后调用openpose的进行骨骼点数据的检测和输出。
#!/usr/bin/env python# coding:gbkimport osimport argparseimport jsonimport shutilimport numpy as npimport torchimport skvideo.io#from processor.io import IOimport toolsimport tools.utils as utils# if __name__ == '__main__':#class PreProcess(IO):class PreProcess(): def start(self): work_dir = 'D:/st-gcn' type_number = 6 action_filename_list = ['boxing', 'handclapping', 'handwaving', 'jogging', 'running', 'walking'] for process_index in range(type_number): action_filename = action_filename_list[process_index] # 标签信息 labelAction_name = '{}_{}'.format(action_filename,process_index) #labelAction_name = 'xxx_{}'.format(process_index) label_no = process_index # 视频所在文件夹 originvideo_file = 'D:/dataSet/training_lib_KTH_cut_6s/{}/'.format(action_filename) # resized视频输出文件夹 需要自己创建几个动作的文件夹 resizedvideo_file = './mydata/training_lib_KTH_cut_6s/resized/{}/'.format(action_filename) videos_file_names = os.listdir(originvideo_file) # 1. Resize文件夹下的视频到340x256 30fps for file_name in videos_file_names: video_path = '{}{}'.format(originvideo_file, file_name) outvideo_path = '{}{}'.format(resizedvideo_file, file_name) writer = skvideo.io.FFmpegWriter(outvideo_path, outputdict={'-f': 'mp4','-vcodec': 'libx264', '-s': '340x256', '-r': '30'}) reader = skvideo.io.FFmpegReader(video_path) for frame in reader.nextFrame(): writer.writeFrame(frame) writer.close() print('{} resize success'.format(file_name)) # 2. 利用openpose提取每段视频骨骼点数据 resizedvideos_file_names = os.listdir(resizedvideo_file) for file_name in resizedvideos_file_names: outvideo_path = '{}{}'.format(resizedvideo_file, file_name) # openpose = '{}/examples/openpose/openpose.bin'.format(self.arg.openpose) #openpose = '{}/OpenPoseDemo.exe'.format(self.arg.openpose) openpose = 'D:/openpose-master/build/x64/Release/OpenPoseDemo.exe' video_name = file_name.split('.')[0] output_snippets_dir = './mydata/training_lib_KTH_cut_6s/resized/snippets/{}'.format(video_name) output_sequence_dir = './mydata/training_lib_KTH_cut_6s/resized/data' output_sequence_path = '{}/{}.json'.format(output_sequence_dir, video_name) #label_name_path = '{}/resource/kinetics_skeleton/label_name_action.txt'.format(work_dir)#自己创建好标签文档,里面文档内写好动作名称 label_name_path = '{}/resource/kinetics_skeleton/label_name_action{}.txt'.format(work_dir,process_index) with open(label_name_path) as f: label_name = f.readlines() label_name = [line.rstrip() for line in label_name] # pose estimation openpose_args = dict( video=outvideo_path, write_json=output_snippets_dir, display=0, render_pose=0, model_pose='COCO') command_line = openpose + ' ' command_line += ' '.join(['--{} {}'.format(k, v) for k, v in openpose_args.items()]) shutil.rmtree(output_snippets_dir, ignore_errors=True) os.makedirs(output_snippets_dir) os.system(command_line) # pack openpose ouputs video = utils.video.get_video_frames(outvideo_path) height, width, _ = video[0].shape # 这里可以修改label, label_index video_info = utils.openpose.json_pack( output_snippets_dir, video_name, width, height, labelAction_name, label_no) if not os.path.exists(output_sequence_dir): os.makedirs(output_sequence_dir) with open(output_sequence_path, 'w') as outfile: json.dump(video_info, outfile) if len(video_info['data']) == 0: print('{} Can not find pose estimation results.'.format(file_name)) return else: print('{} pose estimation complete.'.format(file_name))if __name__ == '__main__': p=PreProcess() p.start()运行代码之前提前再st-gcn里面建好/mydata/training_lib_KTH_cut_6s_resized文件夹,并在文件夹中将六种行为的文件夹也创建好,‘boxing’, ‘handclapping’, ‘handwaving’, ‘jogging’, ‘running’, ‘walking’。运行之前也需要创建标签文档0到5:
每个文档里面是100个动作标签
运行完如下所示:
此时打开data能看到所有视频的骨骼数据,snippets里面每个json文件存的是单帧骨骼数据,data里面每个json文件都是一个视频的所有骨骼点数据。data里面json文件打开如下图所示: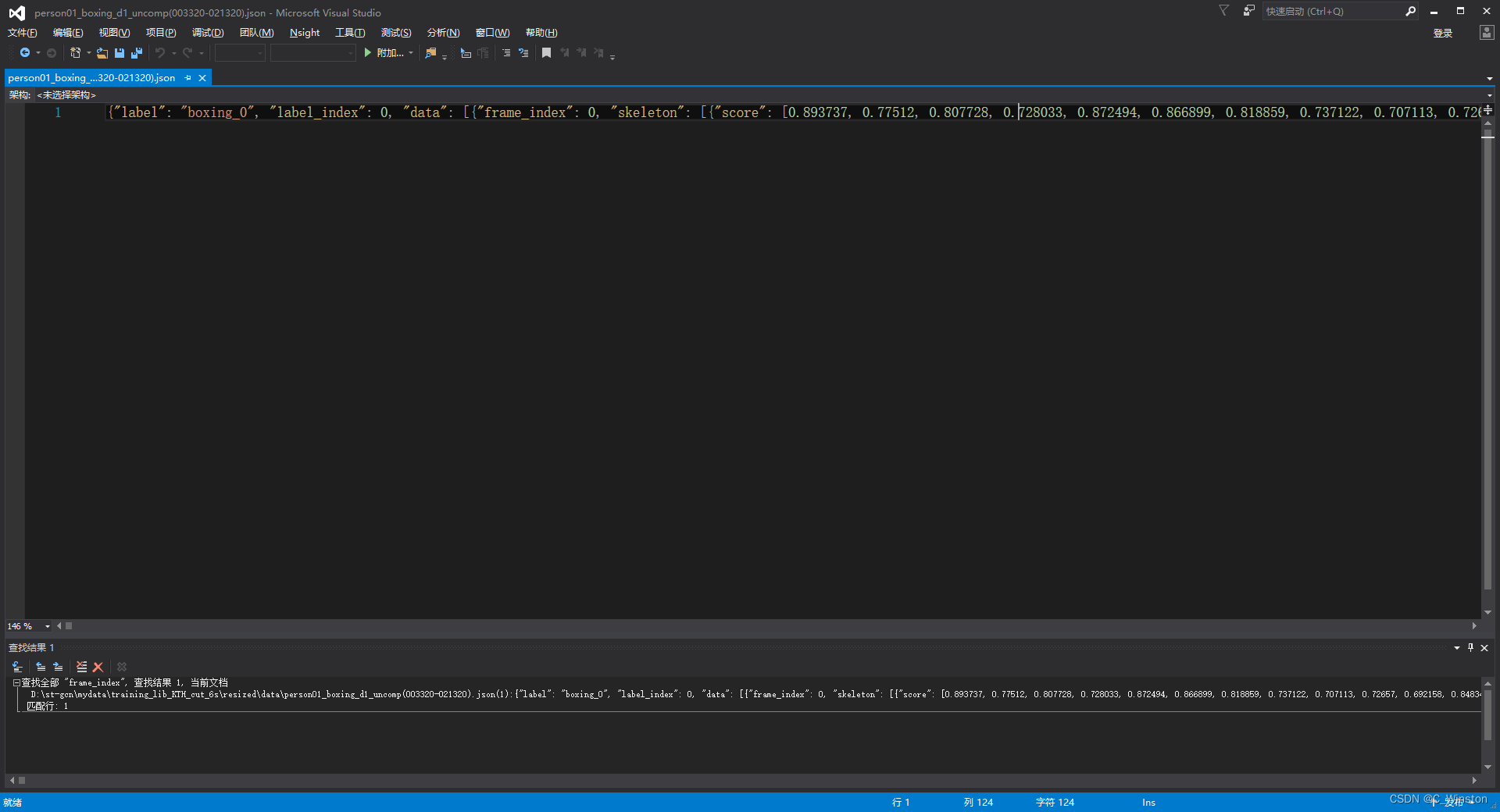
4、整理骨骼点数据,生成st-gcn运行的格式
首先将data里面的数据分成训练集、验证集、测试集按照6:2:2划分.
将01到15复制kinetics_train,16-20放到val,21-25放到test。
import jsonimport osif __name__ == '__main__': train_json_path = './mydata/kinetics-skeleton/kinetics_train' val_json_path = './mydata/kinetics-skeleton/kinetics_val' test_json_path = './mydata/kinetics-skeleton/kinetics_test' output_train_json_path = './mydata/kinetics-skeleton/kinetics_train_label.json' output_val_json_path = './mydata/kinetics-skeleton/kinetics_val_label.json' output_test_json_path = './mydata/kinetics-skeleton/kinetics_test_label.json' # train_json_names = os.listdir(train_json_path) val_json_names = os.listdir(val_json_path) test_json_names = os.listdir(test_json_path) train_label_json = dict() val_label_json = dict() test_label_json = dict() for file_name in train_json_names: name = file_name.split('.')[0] json_file_path = '{}/{}'.format(train_json_path, file_name) json_file = json.load(open(json_file_path)) file_label = dict() if len(json_file['data']) == 0: file_label['has_skeleton'] = False else: file_label['has_skeleton'] = True file_label['label'] = json_file['label'] file_label['label_index'] = json_file['label_index'] train_label_json['{}'.format(name)] = file_label print('{} success'.format(file_name)) with open(output_train_json_path, 'w') as outfile: json.dump(train_label_json, outfile) for file_name in val_json_names: name = file_name.split('.')[0] json_file_path = '{}/{}'.format(val_json_path, file_name) json_file = json.load(open(json_file_path)) file_label = dict() if len(json_file['data']) == 0: file_label['has_skeleton'] = False else: file_label['has_skeleton'] = True file_label['label'] = json_file['label'] file_label['label_index'] = json_file['label_index'] val_label_json['{}'.format(name)] = file_label print('{} success'.format(file_name)) with open(output_val_json_path, 'w') as outfile: json.dump(val_label_json, outfile) for file_name in test_json_names: name = file_name.split('.')[0] json_file_path = '{}/{}'.format(test_json_path, file_name) json_file = json.load(open(json_file_path)) file_label = dict() if len(json_file['data']) == 0: file_label['has_skeleton'] = False else: file_label['has_skeleton'] = True file_label['label'] = json_file['label'] file_label['label_index'] = json_file['label_index'] test_label_json['{}'.format(name)] = file_label print('{} success'.format(file_name)) with open(output_test_json_path, 'w') as outfile: json.dump(test_label_json, outfile)生成如下: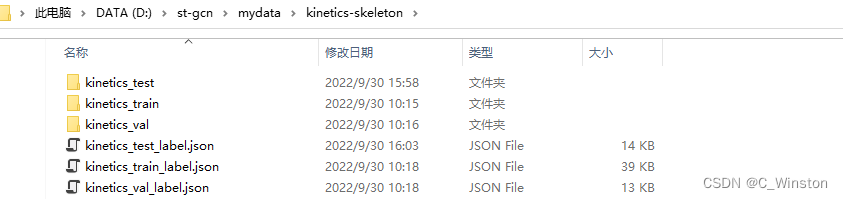
再利用stgcn训练代码中自带了数据转换代码tools/kinetics_gendata.py,使用该脚本将kinetics-skleton数据集转换为训练使用的npy与pkl文件。
这里参考博客:数据转换中的三数据转换。以下地方需要修改:
num_person_in=1, #observe the first 5 persons num_person_out=1, #then choose 2 persons with the highest score part = ['train', 'val','test']frame不用修改即可前面视频已经裁剪过
运行脚本后: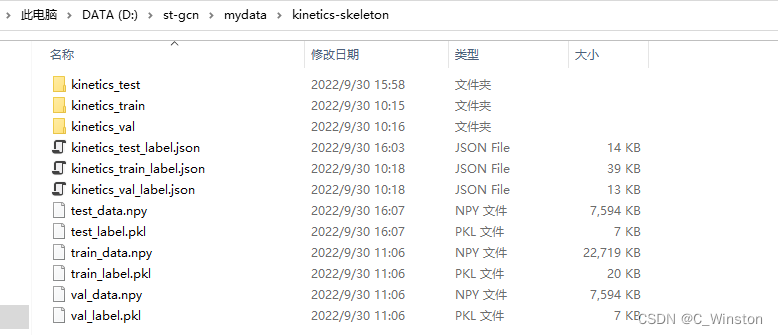
5、训练st-gcn网络
这部分参考st-gcn训练自建行为识别数据集中的5、6部分即可
我的train.yaml是这样修改的:
work_dir: ./work_dir/recognition/kinetics_skeleton/ST_GCN# feederfeeder: feeder.feeder.Feedertrain_feeder_args: random_choose: True random_move: True window_size: 150 # data_path: ./data/Kinetics/kinetics-skeleton/train_data.npy# label_path: ./data/Kinetics/kinetics-skeleton/train_label.pkl data_path: ./mydata/kinetics-skeleton/train_data.npy label_path: ./mydata/kinetics-skeleton/train_label.pkltest_feeder_args:# data_path: ./data/Kinetics/kinetics-skeleton/val_data.npy# label_path: ./data/Kinetics/kinetics-skeleton/val_label.pkl data_path: ./mydata/kinetics-skeleton/val_data.npy label_path: ./mydata/kinetics-skeleton/val_label.pkl# modelmodel: net.st_gcn.Modelmodel_args: in_channels: 3 num_class: 6 edge_importance_weighting: True graph_args: layout: 'openpose' strategy: 'spatial'# training#device: [0,1,2,3]device: [0]batch_size: 32test_batch_size: 32#optimbase_lr: 0.1step: [20, 30, 40, 50]num_epoch: 50执行训练代码:
python main.py recognition -c config/st_gcn/kinetics-skeleton/train.yaml6、测试
可修改test.yaml利用刚刚自己的测试集进行测试
weights: ./work_dir/recognition/kinetics_skeleton/ST_GCN/epoch50_model.pt#weights: ./models/st_gcn.kinetics.pt# feederfeeder: feeder.feeder.Feedertest_feeder_args:# data_path: ./data/Kinetics/kinetics-skeleton/val_data.npy# label_path: ./data/Kinetics/kinetics-skeleton/val_label.pkl# data_path: ./mydata/kinetics-skeleton/val_data.npy# label_path: ./mydata/kinetics-skeleton/val_label.pkl data_path: ./mydata/kinetics-skeleton/test_data.npy label_path: ./mydata/kinetics-skeleton/test_label.pkl# modelmodel: net.st_gcn.Modelmodel_args: in_channels: 3 num_class: 6 edge_importance_weighting: True graph_args: layout: 'openpose' strategy: 'spatial'# test phase: testdevice: 0test_batch_size: 32然后执行
python main.py recognition -c config/st_gcn/kinetics-skeleton/test.yaml注:作者也是一位初学者,此文章供参考讨论,有什么问题欢迎讨论多多指教!