目录
一、CNN和GCN的关系
二、“图”的预备知识
三、图卷积网络(GCN)
四、针对于高光谱图像分类的网络优化
五、频域的图卷积神经网络
最近看到一篇引用量非常高的文章,是用图卷积网络处理高光谱图像分类任务,于去年7月发布,到现在已经有300+的引用量了,这对于高光谱分类领域来讲是一个非常快也是非常高的数据。接触图卷积神经网络后发现绝大部分资料都在尝试以一种数学推理的方式讲解中间的公式部分,这对于整体理解、把握、使用这个网络造成一定障碍,在阅读了相关资料后,尝试从更宏观的角度去认识这个网络,之后再慢慢加入一些数学内容,以此来力求顺畅的了解和学习这个网络。
一、CNN和GCN的关系
对于传统数据结构的数据集来讲,都属于欧几里得空间,比如图片,视频,音频等,都可以转化为形状非常规整的矩阵,这样的数据结构,就可以通过卷积进行处理,因为卷积核也是非常规整的矩阵。
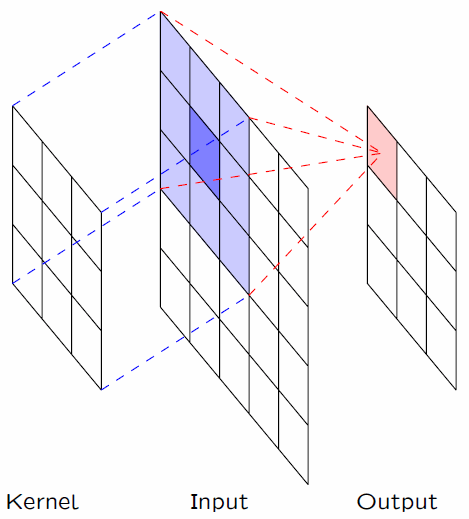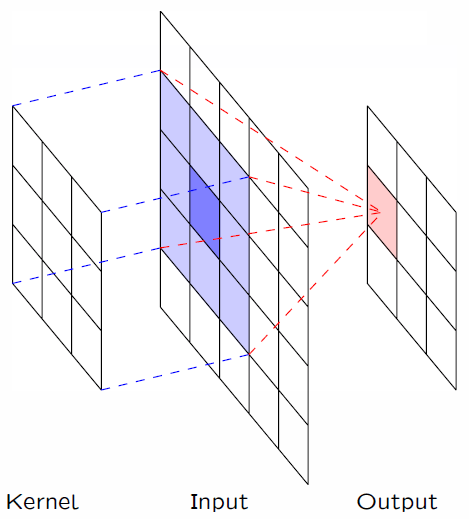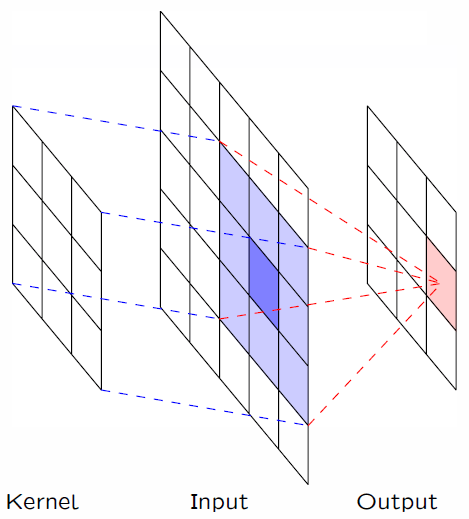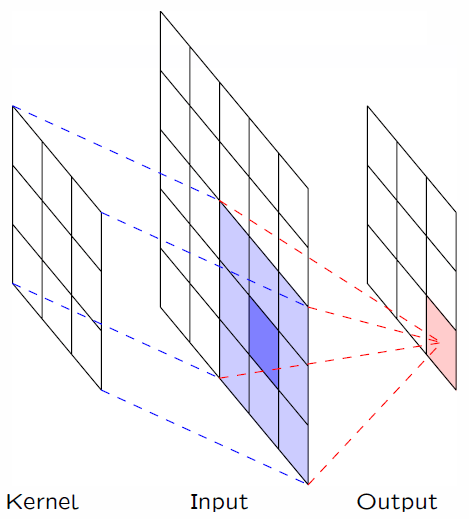 图1.1 CNN的卷积过程
图1.1 CNN的卷积过程
但对于非欧空间的数据结构来讲,就无法实现这种卷积了,比如社交关系网,交通网络图,化学分子结构等。
 图1.2人际关系网络
图1.2人际关系网络  图1.3化学分子结构
图1.3化学分子结构
每个数据节点都有N个边连结不同的节点,而且这些N并不相同。显然,这些数据结构没办法进行传统的卷积处理,因为我们甚至找不到一个size可以随时进行不规则变化的卷积核。那么想要对这种数据通过卷积进行特征学习应该怎么办呢,此时变提出了GCN,也就是这篇文章的主角,图卷积神经网络。这种网络需要1.能使用计算机处理(使数据结构变得规整,例如矩阵),2.除了保留每个节点的信息外,还要包含相邻节点的信息。
二、“图”的预备知识
图神经网络(GNN)是对“图”进行处理,图便是以上人际关系网络、化学分子结构等这样的数据结构类型。把他概括为下图,我们把这种没有箭头指向的图称为无向图,代表两个节点间是双向互通的。而GNN中几乎只用到了这种无向图。另一种有箭头的单向的结构我们成为有向图。
 2.1 无向图
2.1 无向图 2.1所表示的图中有4个节点,在“图”中我们称这种节点为顶点,顶点之间的连线我们称为“边”,度表示一个顶点所连接的边的个数,比如2.1中该图含有四个顶点V1,V2,V3,V4,V3的度为2,V1的度为3,V2的度为1…… 。顶点之间相互直接连接的,我们称为一阶邻居顶点,比如V2,V3,V4就是V1的一阶邻居顶点,中间最少隔1个顶点的我们称为二阶邻居顶点,比如V4是V2的二阶邻居顶点,以此类推有高阶邻居顶点。
有了图的一些基本定义后
,我们开始考虑,无论图的结构有多奇怪,最后都是要送入计算机中去处理的,那么我们希望找一个规整的结构来表征个这个图,比如用矩阵来表征,这样就可以将其送入计算机中去处理了。那么这个矩阵至少需要两部分来组成,第一,需要能表征各个顶点之间的关系,即有无连接,进一步最好可以考虑到这种连接的强弱。第二,需要包含各个节点本身的信息,即要表征出节点自己都分别是谁。
根据上述两个指导,我们逐步实现,先满足第一个条件,即,表征各个顶点之间的关系,这就引入了“邻接矩阵”这个概念,我们来看看邻接矩阵做了什么事情。以2.1为例,我们希望表达各个顶点之间的关系,即需要分别表达V1到(V1,V2,V3,V4)的关系和V2到(V1,V2,V3,V4)等等一直到V4和大家的关系。不难发现我们需要两个维度
| V1 | V2 | V3 | V4 | |
| V1 | 0 | 1 | 1 | 1 |
| V2 | 1 | 0 | 0 | 0 |
| V3 | 1 | 0 | 0 | 1 |
| V4 | 1 | 0 | 1 | 0 |
上表中表示了从Vi到Vj的关系,我们将直接相连接的顶点关系看作是1,不直接相连接的顶点关系看作0,这样我们就得到了邻接矩阵A,这个矩阵能很好的表达各顶点相互之间的关系。进一步,如果能在各边附近标注出该边的强弱关系,那我们就能进一步完善这个矩阵,而非只用(0,1)表示。如图2.2和下表
 图2.2 带强弱关系的图
图2.2 带强弱关系的图
| V1 | V2 | V3 | V4 | |
| V1 | 0 | 2 | 5 | 6 |
| V2 | 2 | 0 | 0 | 0 |
| V3 | 5 | 0 | 0 | 3 |
| V4 | 6 | 0 | 3 | 0 |
到此为止,第一个问题解决了,通过邻接矩阵A我们可以很好的表征出图中各个顶点之间的关系,那么接下来需要解决第二个问题,即表征各个顶点各自的特征。
比如说V1是一个人,这个顶点里储存了他的一些个人信息,并通过某种编码方式将这种信息表征为数字(embedding):假设对V1来讲,姓名为239,性别为2,身高为175,体重为120,对于V2来讲,姓名为542,性别为1,身高为168,体重为100,以此类推,对Vi全部进行编码,由此便得到了i个向量,比如V1的向量为H1(239,2,175,120),V2的向量为H2(542,1,168,100),我们称这个向量为对应顶点的信号。之后将得到的i个列向量拼接成一个矩阵H(H1,H2,H3,H4)⊺,其中H为分块矩阵,用一列表示。
| H1 | 239 | 2 | 175 | 120 |
| H2 | 542 | 1 | 168 | 100 |
| H3 | 937 | 2 | 188 | 150 |
| H4 | 365 | 1 | 163 | 90 |
我们取A矩阵中的第一行 A1,A1点乘H,即有:
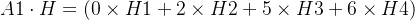
可以看出,这个结果是V1的邻居节点信号的加权求和,其中权重为关系强弱数值,由A提供,但是这个权重并没有进行归一化,也就是说,如果某个节点的邻居顶点越多,关系数值越强,这个结果就越大,为了避免这种情况,我们进行了归一化操作,即,让权重除以该节点所有边的关系数值的和,上这些边的关系数值成为真正意义上和为1的“权值”。那么我们所需要的数学过程即让A的每一行都除以该行的和。这是我们引入一个新的矩阵D,这个矩阵为对角矩阵,每行对角线上的元素为A的这行的元素和,也就是该顶点的度。
| 13 | 0 | 0 | 0 |
| 0 | 2 | 0 | 0 |
| 0 | 0 | 8 | 0 |
| 0 | 0 | 0 | 9 |
执行![]() 操作,即把A的每个关系数值都归一化了,变成权重,结果为
操作,即把A的每个关系数值都归一化了,变成权重,结果为
| 0 | 2/13 | 5/13 | 6/13 |
| 2/2 | 0 | 0 | 0 |
| 5/8 | 0 | 0 | 3/8 |
| 6/9 | 0 | 3/9 | 0 |
此时,执行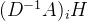 ,即
,即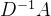 的第i行和H相乘,(设i取1,就是第一行)得到
的第i行和H相乘,(设i取1,就是第一行)得到
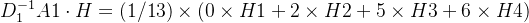
所有行都进行同样的操作,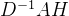 ,则每一行的量纲都一样了,不会出现某一行计算结果特别夸张。此时我们来考虑这个结果是什么,它相当于是某一个顶点周围所有顶点的信号按关系(权重)相加(聚合),那么这个结果就能表征出周围节点对自己的影响了,同时由于是通过矩阵进行运算,数据结构变得很规整,可以使用计算机来运算。
,则每一行的量纲都一样了,不会出现某一行计算结果特别夸张。此时我们来考虑这个结果是什么,它相当于是某一个顶点周围所有顶点的信号按关系(权重)相加(聚合),那么这个结果就能表征出周围节点对自己的影响了,同时由于是通过矩阵进行运算,数据结构变得很规整,可以使用计算机来运算。
三、图卷积网络(GCN)
到这里,我们需要思考两个个问题:
第一,这种影响是需要一个客体来承受的:
比如说我有五个朋友,有的关系好,有的关系一般,有的关系差,他们的学习能力也各不相同,我想知道我交了这五个朋友后,我的成绩会变成什么样子。在这个例子中,我就是客体,需要承受五个朋友的影响,最终要表达出我交这五个朋友的后果,这这后果才是我最终想要计算的东西。而刚刚的计算中,显然缺少“我”的参与,比如:
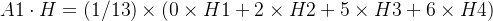
可以看到,都是V2,V3,V4的信号H1,H2,H3来加权求和的,没有V1的信号H1(即没有“我”)的信息,那么假设,我本身是个学霸,他们根本对我产生不了影响,或者我学习巨差,跟他们交朋友,对我的提升很大,这样的话如果想表征交朋友的“后果”,那么“我”的信息必不可少,因此我们需要对邻接矩阵A进行一点点完善,把“我”的信息加进去,创造新的矩阵

同时D也随之发生变化,变为
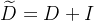
其中I为单位阵,这样,新的计算公式为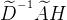 ,这样加权的时候就得考虑”我“的信息了,至于我的信息占比多少理论上可以自行设定,即
,这样加权的时候就得考虑”我“的信息了,至于我的信息占比多少理论上可以自行设定,即
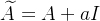
其中a为强度参数,当然D也得随之变化。不过在实际中,我们并不需要考虑这个问题,因为”后果“的量纲和”分数“的量纲并不需要一致,即后果并不非要用分数衡量,可以把他当成一种新的量纲的评价指标,在这个指标下,“我的”权重只占度值分之1,只需要把“我”的信息考虑进去即可,这样这个结果就有了物理意义,即他们对我影响的“后果”,换句话说,我受到他们影响后变成了什么样子。这个时候,我们突然意识到,这个结果不就在一定程度上是“新的我”吗?所有顶点经过这样的计算后,都变成了新的自己,这样我们又得到了一个图,新的图中,大家关系仍保持不变(无论边还是关系数值),我们又可以重新来计算一轮了。不过这个时候新的我已经包含了和我直接相连的原顶点的信息了,正如例子中,新的V1此时已经包含了旧的(V1,V2,V3,V4)的信息了,而新的V4也包含了(V1,V3,V4)的信息,但注意,第一轮计算中,因为V4和V2没有直接相连,所以V4不包含V2的信息,那么第二次影响时,由于V4和V1有边,新的V1又包含原V2的信息,那么新的V4可以通过新的V1来获取一部分原来V2的信息了,那么我们发现,当只通过一轮计算(或称为一次传播)后,只有一阶邻居顶点的信息可以相互影响,当通过二次传播后,二阶邻居顶点间的信息也发生了交互,以此类推,当通过N次传播后,N阶邻居顶点的信息也发生了交互。这就实现了表征顶点间的相互影响后果的矩阵计算。
第二,关系数值我们一般是通过两顶点信号之间的欧氏距离得到的,这只跟这两个顶点有关系,与其二阶邻居的信号是无关的,但是显然,邻居的邻居对我影响应该也是有的,我们怎样才能把二阶邻居的影响考虑进来呢?
比如,我叫V2,是个自闭症患者,班里一共四个人,我们自己的信号为社交能力值,我只认识V1,认识V1也不是因为我和他聊得来,纯纯是因为V1是个社牛,V1谁都认识。在这个例子中,如果考虑V2经过一次传播后形成的新V2,是通过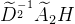 计算的,结果为
计算的,结果为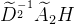 =(1/3)×(2×H1 + 1×H2 + 0×H3 + 0×H4) =2/3 H1 + 1/3H2 ,可以看出,此时新的V2的信号绝大部分来源于原来V1的信号,这当然不行,怎么经过一次传播后,把我一个社恐变成了社牛,这显然传播仍然存在问题,我希望能把二阶邻居和一阶邻居都考虑进去,二阶邻居和一阶邻居数量差别较大的时候,我希望能衰减这种影响,尽可能让自己的信号和别人的信号尽可能的分开来,那么就容易得到两种思路了,一是传播中我尽可能保留自己的权重,削减别人的权重,即对
=(1/3)×(2×H1 + 1×H2 + 0×H3 + 0×H4) =2/3 H1 + 1/3H2 ,可以看出,此时新的V2的信号绝大部分来源于原来V1的信号,这当然不行,怎么经过一次传播后,把我一个社恐变成了社牛,这显然传播仍然存在问题,我希望能把二阶邻居和一阶邻居都考虑进去,二阶邻居和一阶邻居数量差别较大的时候,我希望能衰减这种影响,尽可能让自己的信号和别人的信号尽可能的分开来,那么就容易得到两种思路了,一是传播中我尽可能保留自己的权重,削减别人的权重,即对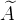 做处理,第二是让“我”的信号根据传播产生某种线性变化,即随着二阶邻居和一阶邻居数量差别越大我信号越小,这样也可以把我和别人区分出来,也可以有我自己单独的特征,就是信号特别小嘛。GCN中是按照第二个思路来的,在数学上新的传播过程表示为:
做处理,第二是让“我”的信号根据传播产生某种线性变化,即随着二阶邻居和一阶邻居数量差别越大我信号越小,这样也可以把我和别人区分出来,也可以有我自己单独的特征,就是信号特别小嘛。GCN中是按照第二个思路来的,在数学上新的传播过程表示为:
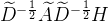
由于D和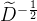 都是对角线矩阵,我们可以将它看作一个单位阵经过了一系列初等变换,还是只做倍乘的初等变换,对A左乘一个
都是对角线矩阵,我们可以将它看作一个单位阵经过了一系列初等变换,还是只做倍乘的初等变换,对A左乘一个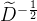 右乘一个
右乘一个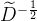 ,左乘相当于对A做行初等变换,右乘相当于对A做列初等变换。那么
,左乘相当于对A做行初等变换,右乘相当于对A做列初等变换。那么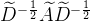 可以看作对
可以看作对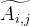 进行了如下操作 :
进行了如下操作 :
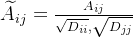
这样,当一阶邻居顶点j的度(边数量,也就是它的一阶邻居数量)很大,那么传播一次后信号就会变得很小,比如对V2来讲:
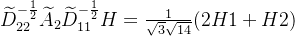
因为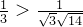 ,可以看出将新V2的信号进行了衰减,衰减因子为
,可以看出将新V2的信号进行了衰减,衰减因子为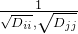 ,显然,只有当i=j时,权重和才等于1,其他时候都<1,且i,j差别越大,衰减因子衰减的越狠。以上,第二个问题也得到了解决。
,显然,只有当i=j时,权重和才等于1,其他时候都<1,且i,j差别越大,衰减因子衰减的越狠。以上,第二个问题也得到了解决。
到这里我们已经解决了图的矩阵表示,这个矩阵不仅含有自己的信号,还含有各个顶点之间的关系,且每一层传播都有新的信号产生,这些新的信号相当于CNN中 Y = XW+ b 中的各层X了,我们类比CNN,可以称之前每次传播所得到的值为每层的特征,那么我们想利用图进行卷积神经网络的训练,则需要加入能捕获信息的可训练参数矩阵W和b,再通过一个激活函数,就完美对应了卷积神经网络CNN,所以我们有了最终的向前传播公式:
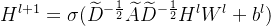
以上就是图卷积神经网络传播公式的详解。其中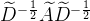 是固定的,所有层都不变化,接下来就与CNN如出一辙,构建全连接层,损失函数,反向传播,更新参数。
是固定的,所有层都不变化,接下来就与CNN如出一辙,构建全连接层,损失函数,反向传播,更新参数。
四、针对于高光谱图像分类的网络优化
整个网络的传播已经介绍完了,那么它实现了什么功能呢?我们分为两个方面来考虑:
1.无/半监督:即我们在输入样本时,会将无标签的样本(顶点及其信号)一起输入进网络,在每次网络进行传播时,这些没有标签顶点的信号,都能接收到附近信号的信息,形成新的特征后成为下一层的“新的自己”,这实际上是一种“近朱者赤,近墨者黑”的传播方式,经过几次传播后,会出现聚类的效果,即某一些顶点的信号越来越相似,但又保留自己的一部分原始信息,从而达到的聚类的效果;
2.监督:这就是本文开头提到的高光谱图像分类那篇文章所用的思路,传统的GCN都是采用半监督和无监督模式的,在输入时就将无标签的测试集输入进网络里,测试集慢慢被“传染”了有标签的顶点的信息后,慢慢相似化,形成聚类,而我们期望训练时只用训练集,测试时可以在不重新训练网络的情况下预测新的样本标签。于是我们仿照CNN的思路,做出三个方面的改动:
第一、加入softmax分类函数。
第二、减少计算量,计算量和我们每次输入出的样本大小有关,例如高光谱的数据,UP数据集有4w多个样本,每个样本的波段数103(信号),在这个例子中,如果直接使用GCN的话,需要以此输入所有的样本,那么D和A是40000×40000的矩阵,H是40000×103的矩阵,W是103×103的矩阵,计算复杂度为(40000 * 103 * 103),而在CNN中每次更新的矩阵几乎都是多个3×3和5×5之类的堆叠,如此巨大的样本量下,相对于CNN来讲是非常耗费显存的。据于此,上述提到的文献提供一个思路解决问题,按照cnn里分batch的方式进行,将高光谱图像的训练集随机划分为不同的小区域,每个小区域中进行随机选10个像素点,并生成一张图,多次选点保证这个小区域里所有的有效像素都被选到,则令这个小区域里所有的图为一个batch。这样每个H的是10×103,计算复杂度为(10*103*103),会极大减小计算量。
第三、支持未经训练的样本直接通过训练好的网络进行预测。通过第二条,我们实现了用batch的方式划分训练集,训练网络,那么此时,我们只要把测试集的数据,按照训练集的方式也划分成一个个区域并生成图,将生成的图送入训练好的网络便实现了:未经训练的样本也可以通过训练好的网络进行预测。
那么GCN对于CNN来讲有什么优势呢?我们将每一个顶点得信号看作是一个样本得输入,那么GCN可以实现这样一种功能:当空间信息分布在在非欧空间时,即没有规整得相邻关系时,各个输入样本之间的关系及其关系强弱可以被考虑进网络。而通常情况下CNN输入的各个样本之间的关联性信息并没有被输入网络中去。在高光谱中,虽然3D-CNN和2D-CNN已经加入了空间信息,但,但对原始高光谱数据的空间信息提取也仅在一个patch里,这个pacth中有时包含多种地物,而patch的标签仅仅由中心点的像元标签决定,所以会存在如下情况,当中心点附近几个像元是不同于标签的地物时,他们的patch非常相近,标签却又不相同,训练的难度就会增大。在改进后的GCN中,由于输入不在是patch,而是包含更远处信息的图,图中的各个信号点也是在某一定区域内随机选择的,避免了出现不同的标签的图(pacth)过于相似的问题,所以在生成的预测结果图中,边界会更加清晰。
五、频域的图卷积神经网络
本来是事情到这里已经结束了,但是有大佬提出了用频域的思想来解释图卷积神经网络,因为频域的乘积对应空域的卷积,而乘积显然比卷积要方便计算,于是将需要卷积的信号和卷积核做傅里叶变换或拉普拉斯变化,变换到频域后相乘,再变换回空域,此时得到的结果就是空域的卷积结果了,即
![g\star f = F^{-1}[F[g]\cdot F[f]]](http://zhangshiyu.com/zb_users/upload/2024/04/20240421121908171367314872054.png)
其中F[·]为傅里叶变换或拉普拉斯变换。
想法是好的,但是式子中的(g,f)都是函数啊,存在傅里叶级数,自然是可以做变换,但我们图结构形式的傅里叶变换又是什么呢?
接下来我们需要探寻一下傅里叶变换的本质,首先我们来看看传统的傅里叶级数
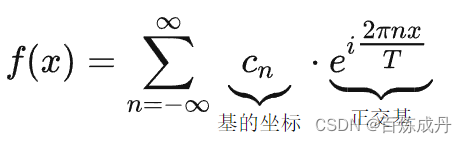
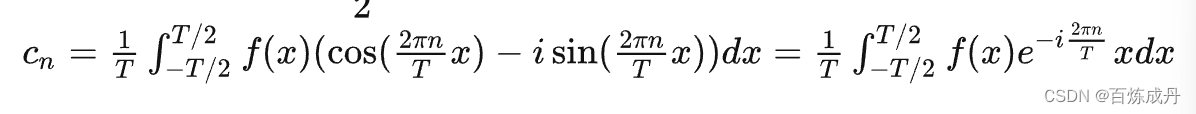
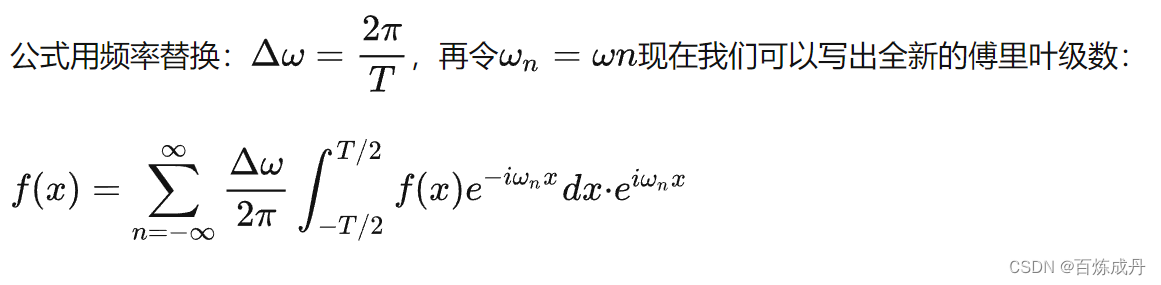

到这里我们发现F(w)无非就是在求各个基的系数Cn,而且这个求法就是让f(x)和基的共轭相乘再求积分,把f(x)和基从连续对应到离散里,不就是对应元素相乘再相加,这不正是两个向量的点积吗?通过这种点积就能确定在某一个w下的F(w)的值,分别进行多次不同w下的点积就能求出F(w)了。我们做个总结,求传统的傅里叶变换的本质上,就是再求与正交基的内积的那些系数Cn
现在开始进行类比,在图中,要参与卷积计算的是各层的信号,那么“f(x)”就有了,那么只要找到一组正交基就行了。传统的傅里叶变换是对一个函数进行的,将函数离散后是一个一维的数组,所以基是一个关于w的一维函数就行了,而我们需要对顶点进行傅里叶变换,各个顶点之间还需要考虑相互的影响,那我们找的这组正交基就至少需要包含邻接矩阵的信息。那么传统的傅里叶变换是的正交基有那些要求呢?这里穿插一些数学结论,我们之所以能用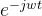 作为基函数,是因为其满足拉普拉斯算子的特征方程,w和特征值有关。我们来看一下特征方程的定义:
作为基函数,是因为其满足拉普拉斯算子的特征方程,w和特征值有关。我们来看一下特征方程的定义:

其中A是一种变换,V是特征向量,λ是特征值。 满足:
满足:
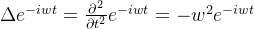
其中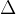 为拉普拉斯算子,即二阶导算子。可以看出,这个式子中,
为拉普拉斯算子,即二阶导算子。可以看出,这个式子中,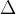 就是变换法则A,
就是变换法则A,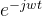 是特征向量V(虽然
是特征向量V(虽然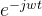 只有一个元素而不是数组),
只有一个元素而不是数组),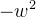 为特征值λ,故
为特征值λ,故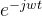 满足拉普拉斯特征方程,所以我们选择
满足拉普拉斯特征方程,所以我们选择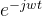 作为基。
作为基。
那么我们相对各个信号求傅里叶变换,能否也找出一种包含邻接矩阵A的信息的“拉普拉斯矩阵”,那样的话求其特征向量就行了,但是这组特征向量需要时正交的,那么最好我们找到的这个拉普拉斯矩阵是实对称矩阵,其特征向量就是正交的了,这组基做归一化后就是一组正交基。
问题来了,在图结构中,有这样的矩阵吗?答案是有,这个矩阵就被称为拉普拉斯矩阵L,算法是L = D - A,D是度矩阵,A是邻接矩阵。多么简洁啊,那L是如何实现拉普拉斯算子的功能的(在图结构里求二阶导功能),这个内容我发现了一位清华的大佬写的非常的好,深入浅出地阐述了拉普拉斯矩阵的意义和直观感受,举了非常恰当的例子来介绍,很适合GCN的初学者来阅读。传送门。
有了这个拉普拉斯矩阵后,我们可以求得它的特征向量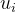 了,由
了,由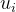 就可以构成这组正交基U,那么对某个信号f进行傅里叶变换就可U得内积形式,即
就可以构成这组正交基U,那么对某个信号f进行傅里叶变换就可U得内积形式,即![F[f] = U^{T}f](http://zhangshiyu.com/zb_users/upload/2024/04/20240421121911171367315184840.png) ,F[·]为傅里叶变换,那逆变换则是将
,F[·]为傅里叶变换,那逆变换则是将 变为f,那么在
变为f,那么在![F[f] = U^{T}f](http://zhangshiyu.com/zb_users/upload/2024/04/20240421121911171367315144527.png) 左右两边同时左乘U即可,因为U是正交阵,所以
左右两边同时左乘U即可,因为U是正交阵,所以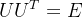 ,那逆变换公式则为:
,那逆变换公式则为:![f = UF[f]](http://zhangshiyu.com/zb_users/upload/2024/04/20240421121912171367315266590.png) 。
。
现在我们将信号f和卷积核h运算,则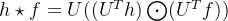 ,其中
,其中 表示对应元素相乘,则可以将
表示对应元素相乘,则可以将 改写为
改写为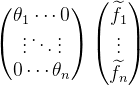 ,其中,
,其中,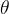 为h的傅里叶变换后的元素,n为信号的维度,
为h的傅里叶变换后的元素,n为信号的维度,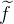 为f的傅里叶变换后的元素将改写后的diag(
为f的傅里叶变换后的元素将改写后的diag(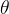 ) =
) = 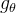 ,所以有
,所以有
![]()
此时我们发现U的列数可以有无穷多个,因为只要在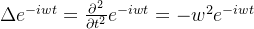 这个式子中把w扩倍,都满足上述关系,那么特征向量有无穷多个,计算那么多的
这个式子中把w扩倍,都满足上述关系,那么特征向量有无穷多个,计算那么多的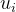 代价太高了,我们把低频的一两个分量用来代替或者说近似整个U就好了,以此为基础做了一些近似,在只取基频的情况下,我们通过近似得到了与时域完全相等的传播公式:
代价太高了,我们把低频的一两个分量用来代替或者说近似整个U就好了,以此为基础做了一些近似,在只取基频的情况下,我们通过近似得到了与时域完全相等的传播公式:
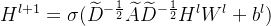
在近似过程中卷积核h的定义式发生了变化,中间的数学过程进行了省略,如果感兴趣可以通过传送门这个连接来看某位清华大佬总结的更为详细的讲解。