1 前言
前后端分离的"前"特指浏览器端(或客户端),直接呈现给用户的;后端是服务器端,处理业务逻辑和数据,不呈现给用户。例如把JSP中静态的HTML部分拿出来,变成简单的HTML文件,放在HTTP服务器上,浏览器只要获取到这些HTML就可以了。动态的数据部分用HTML里的JS通过AJAX的方式从服务器端(servlet等)获取,然后动态操作Dom,完成动态内容的展示。这样前后端就分离了。

本文主要通过编写一个小的demo帮助读者建立前后端连接的实例,当然前后的连接的方法各有不同,各有优势,笔者的水平有限,如果读者有什么见解,欢迎在评论区指出,不胜感激。
2 数据库的建立
所有的业务逻辑都是为数据服务的,无论是前端还是后端。
首先,我们先建立一个数据库(如何建立一个数据库,建表,写数据,就不赘述了)
笔者使用navicat建库建表(强烈推荐使用navicat,Navicate 专注数据库的客户端软件,使用起来很方便) 直接上图数据库数据及结构如下

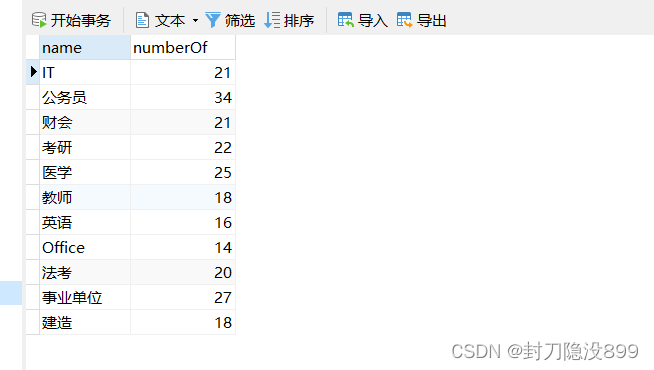
3 后端servlet的编写
3.1建立web项目
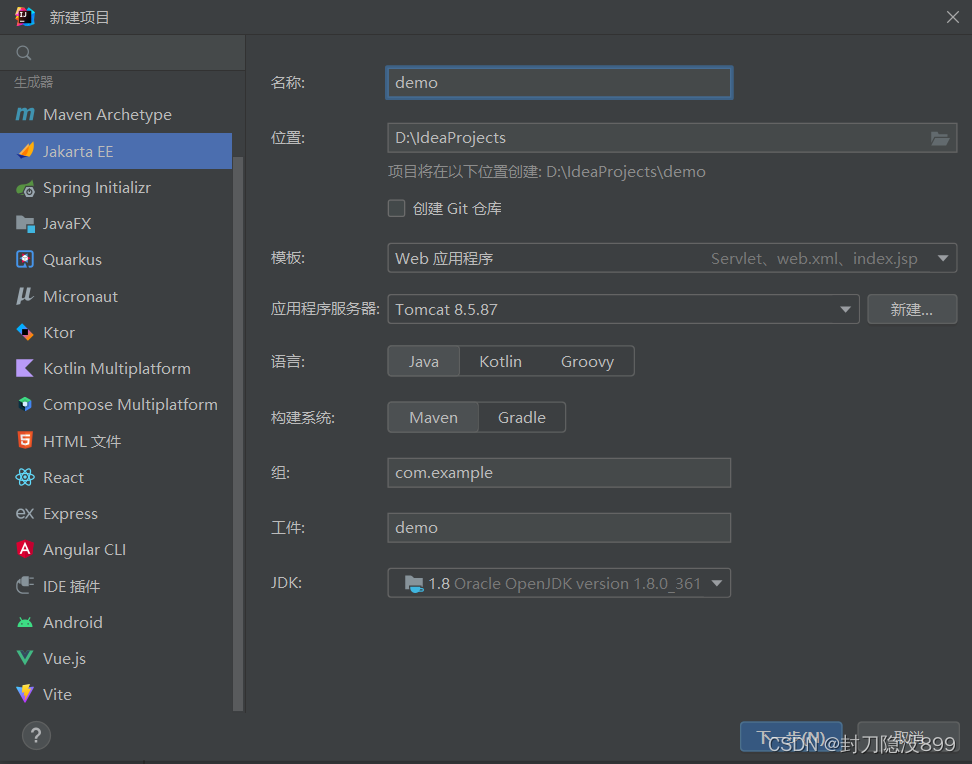
使用IDEA创建一个javaEE项目 使用web应用程序 如图所示
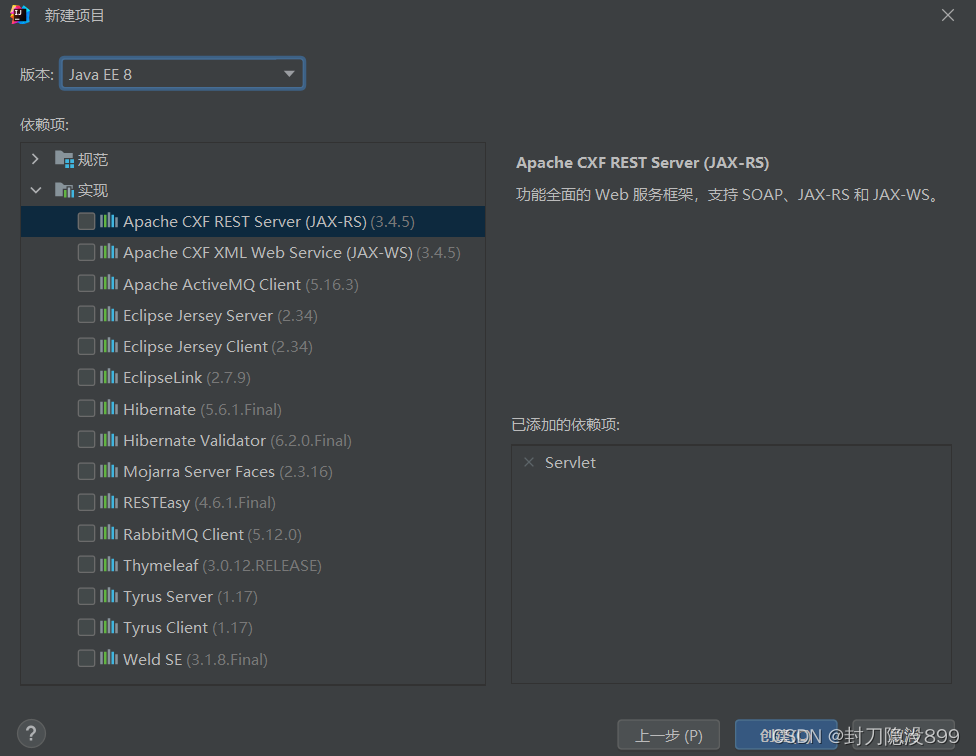
接下来选取对应的javaEE版本笔者这边选取的是EE8 ,别忘了添加依赖项Servlet
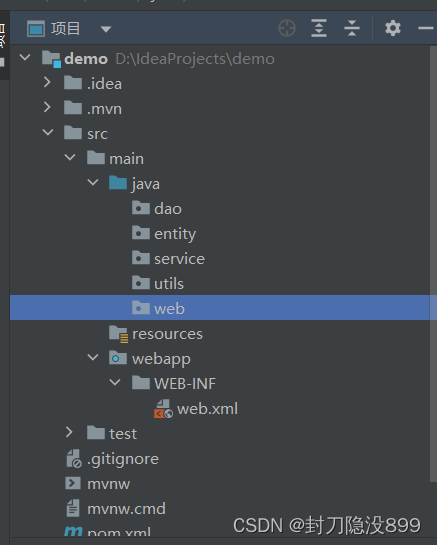
创建成功后可以将原先自动生成的servlet和jsp删去,创建如下的目录
dao主要做数据持久层的工作,负责与数据库进行联络的一些任务都封装在此
service主要负责业务模块的应用逻辑应用设计设计接口设计其实现类
web负责具体的业务模块流程的控制。在此层要调用service层的接口来控制业务流程。负责url映射(action)。针对具体的业务流程,会有不同。我们具体的设计过程可以将流程进行抽象归纳,设计出可以重复利用的子单元流程模块。简单来说就是在里面写servlet。
utils这个主要放置一些编写的工具类,如正则类,数据库连接工具等
entity主要存放一些实体类
3.2 添加依赖项和配置文件
依赖项在pom.xml文件中 其中前3个依赖项是我们连接数据库的
最后一个jackson是我们用来处理json数据的
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.33</version> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.17</version> </dependency> <!-- https://mvnrepository.com/artifact/commons-dbutils/commons-dbutils --> <dependency> <groupId>commons-dbutils</groupId> <artifactId>commons-dbutils</artifactId> <version>1.7</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.15.0</version> </dependency>
配置文件用来连接数据库db.properties放在resources目录下
里面数据库的名字登录用户登录密码修改成自己的即可
url=jdbc:mysql://localhost:3306/xingweifenxi?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTCdriverClassName=com.mysql.cj.jdbc.Driverusername=rootpassword=123456initialSize=10maxActive=20
3.3 编写对于目录下的类
3.3.1 entity
首先建立一个career类
编写实体类代码如下 注意注意注意这个实体类是用来接收数据库数据的建议变量的名称要和数据库的字段对应,如果不是对应的,读者可以自己试试
package entity;public class career { private String name; private int numberOf; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getNumberOf() { return numberOf; } public void setNumberOf(int numberOf) { this.numberOf = numberOf; } @Override public String toString() { return "career{" + "name='" + name + '\'' + ", numberOf=" + numberOf + '}'; }}3.3.2 service
service中的结构
接口CareerService代码如下
package service;import entity.career;import java.util.List;public interface CareerService { List<career> getAll(); // 查询所有用户信息}实现类CareerServiceImpl代码如下,因为还没有编写dao可能会有报红
package service.Impl;import dao.CareerDao;import dao.Impl.CareerIDaompl;import entity.career;import service.CareerService;import java.util.List;public class CareerServiceImpl implements CareerService { CareerDao dao = new CareerIDaompl(); @Override public List<career> getAll() { return dao.getAll(); }}3.3.3 utils
这里面放一个连接数据库的工具类JdbcUtil 代码如下
package utils;import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;import java.io.InputStream;import java.util.Properties;public class JdbcUtil { private static DataSource dataSource; static { // 读取资源目录下的配置文件,以输入流的方式返回 InputStream is = JdbcUtil.class.getClassLoader().getResourceAsStream("db.properties"); Properties p = new Properties(); try { p.load(is); dataSource = DruidDataSourceFactory.createDataSource(p); } catch (Exception e) { throw new RuntimeException(e); } } public static DataSource getDataSource(){ return dataSource; }}
3.3.4 dao
dao中的结构

接口CareerDao代码如下
package dao;import entity.career;import java.util.List;public interface CareerDao { List<career> getAll(); // 查询所有用户信息}实现类CareerDaoImpl代码如下
package dao.Impl;import dao.CareerDao;import entity.career;import org.apache.commons.dbutils.QueryRunner;import org.apache.commons.dbutils.handlers.BeanListHandler;import utils.JdbcUtil;import java.sql.SQLException;import java.util.List;public class CareerIDaoImpl implements CareerDao { private QueryRunner runner = new QueryRunner(JdbcUtil.getDataSource()); @Override public List<career> getAll() { String sql = "SELECT * FROM career ORDER BY numberOf ASC"; try { return runner.query(sql,new BeanListHandler<>(career.class)); } catch (SQLException e) { throw new RuntimeException(e); } }}3.3.5 web
首先,需要编写一个过滤器,用来解决跨域问题,
跨域问题是什么呢?
当一个请求url的协议,域名,端口三者之间任意一个与当前的url不同都即为跨域
当前页面url 被请求页面url 是否跨域 原因
http://www.test.com/ http://www.test.com/index.html 否 同源(协议、域名、端口号相同)
http://www.test.com/ https://www.test.com/index.html 跨域 协议不同(http/https)
http://www.test.com/ http://www.baidu.com/ 跨域 主域名不同(test/baidu)
http://www.test.com/ http://blog.test.com/ 跨域 子域名不同(www/blog)
出于浏览器的同源策略限制.同源策略是一种约定,它是浏览器最核心也是最基本的安全功能,如果缺少了同源策略,则浏览器的正常的功能可能会受到影响,跨域收是Web是构建在同源策略基础上的,浏览器只是针对同源策略的一种实现,同源策略会阻止一个域的JavaScript脚本和另一个域的内容进行交互,所谓同源(即指同一个域)就是两个页面具备同样的协议(protocol),主机(host)和端口号(port)
跨域请求出现错误的条件: 浏览器同源策略 && 请求是ajax类型
解决方法有
ajax的jsonp
CORS方式(这个方法是在后端配置一些信息,本文使用的便是此方法)
Nginx转发
先来看一些web中的结构,一个Serlvet和一个过滤器
CareerSerlvet代码如下
package web;import com.fasterxml.jackson.databind.ObjectMapper;import entity.career;import service.CareerService;import service.Impl.CareerServiceImpl;import javax.servlet.ServletException;import javax.servlet.annotation.WebServlet;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.List;@WebServlet(name = "CareerSerlvet",value = "/Career")public class CareerSerlvet extends HttpServlet { private ObjectMapper objectMapper = new ObjectMapper(); @Override protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); CareerService service = new CareerServiceImpl(); List<career> result = service.getAll(); System.out.println(result.toString()); response.setContentType("application/json;charset=UTF-8"); String respjson = objectMapper.writeValueAsString(result); response.getWriter().write(respjson); } }Filter是用来解决跨域问题的 其中代码如下
package web;import javax.servlet.*;import javax.servlet.annotation.WebFilter;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;@WebFilter(filterName = "Filter", urlPatterns = "/*")public class Filter implements javax.servlet.Filter { public void init(FilterConfig config) throws ServletException { } public void destroy() { } @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws ServletException, IOException { HttpServletRequest req = (HttpServletRequest) request; HttpServletResponse resp = (HttpServletResponse) response; resp.setHeader("Access-Control-Allow-Origin",req.getHeader("origin")); resp.setHeader("Access-Control-Allow-Methods","*"); resp.setHeader("Access-Control-Allow-Headers","*"); resp.setHeader("Access-Control-Allow-Credentials","true"); request.setCharacterEncoding("UTF-8"); response.setCharacterEncoding("UTF-8"); chain.doFilter(request,response); }}3.4 一些其他配置
首先在我们的webapp目录下写一个index.html,用来充当后端页面。(主要是为了好看,当然也是为了保证能够成功启动)
index.html内容如下
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <title>Title</title></head><body>后端界面</body></html>接着给tomcat的启动配置一下


3.5后端启动和测试
启动成功后我们可以看到这个界面

接下来我们使用postman测试接口(建议取官网下载一下)
postman是一款支持http协议的接口调试与测试工具,其主要特点就是功能强大,使用简单且易用性好 。无论是开发人员进行接口调试,还是测试人员做接口测试,postman都是我们的首选工具之一
这个网址是我们serlvet的网址可以看到发送请求后我们可以接收到数据
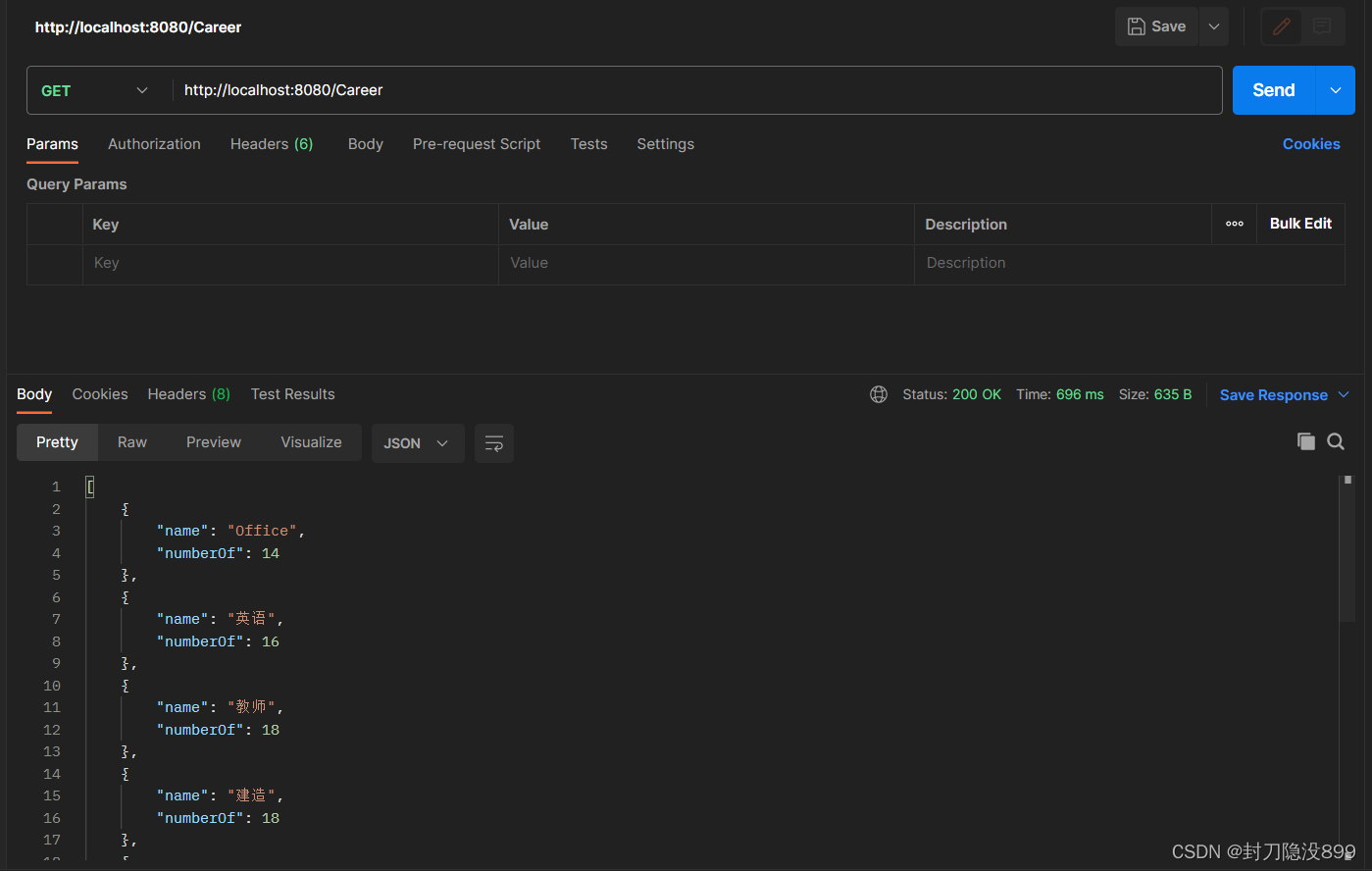
后端接口的编写就到此为止了接下来开始前端页面的编写
4 前端页面的编写
4.1html页面的编写
前端页面编写使用的是VScode
VSCode是一种简化且高效的代码编辑器,同时支持诸如调试,任务执行和版本管理之类的开发操作。它的目标是提供一种快速的编码编译调试工具。然后将其余部分留给IDE(主要是便捷简单,插件多,可支持扩展性强,谁用谁知道)
先建立一个html界面检查一下跨域问题是否解决
代码如下 这段js脚本可以使用postman直接生成
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <script> // WARNING: For GET requests, body is set to null by browsers. var xhr = new XMLHttpRequest(); xhr.withCredentials = true; xhr.addEventListener("readystatechange", function() { if(this.readyState === 4) { console.log(this.responseText); } }); xhr.open("GET", "http://localhost:8080/Career"); xhr.send(); </script></head><body> </body></html>打开控制台可以成功看到输出的数据内容(注意这个过程中后端项目需要一直启动着)

接下正式编写html中的内容(刚才编写的那一段可以删去了)
html中的内容 引入echarts.js 这个可以去官网下载 引入script.js这个是我们自己建立js文件等会在里面编写内容,先建一个空的即可
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head><body> <div id="main" style="width: 600px;height: 400px;"></div> <script src="echarts.js"></script> <script src="scritp.js"></script></body></html>4.2 js内容的编写
编写scritp.js中的内容
Echarts是百度团队开发的,提供了一些直观,易用的交互方式以便于对展示数据进行挖掘.提取.修正或整合,拥有互动图形用户界面的深度数据可视化工具(具体学习可以去官网看,官网确实很有用)
var careerarr=new Array();//新建一个数组用来储存json数据//ajax请求获取数据var career = new XMLHttpRequest();career.withCredentials = true;career.addEventListener("readystatechange", function() { if(this.readyState === 4) { console.log(this.responseText); careerarr = JSON.parse(this.responseText); //echarts画图部分 var chartDom = document.getElementById('main'); var myChart = echarts.init(chartDom); var option; option = { title : { text: '用户感兴趣职业占比图', left: 'center', top: '28px', textStyle :{ color : 'black', }, }, toolbox: { show: true, }, legend: { orient :'horizontal', textStyle :{ color: 'black', }, }, series: [ { name: 'Nightingale Chart', type: 'pie', radius: [0, '75%'], center: ['50%', '60%'], roseType: 'area', itemStyle: { borderRadius: 8 }, label: { normal: { show: true, formatter: '{b}:{c}: ({d}%)' //自定义显示格式(b:name, c:value, d:百分比) } }, data: [] } ]};//这个是用来遍历获取数据的for(var a of careerarr){ option.series[0].data.push({ 'name': a.name, 'value': a.numberOf, }) console.log(a.name); console.log(a.numberOf); }option && myChart.setOption(option); }});career.open("GET", "http://localhost:8080/Career");career.send();4.3页面效果展示

5 结语
前后端的追求
后端应该追求的是:三高(高并发,高可用,高性能),安全,存储,业务等等。
前端追求的是:页面表现,速度流畅,兼容性,用户体验等等。
这是笔者对前后端的理解,笔者实力有限,只能用这样的技术和语句。
希望这篇文章能够使读者产生一点思维的火花,毕竟星星之火可以燎原
