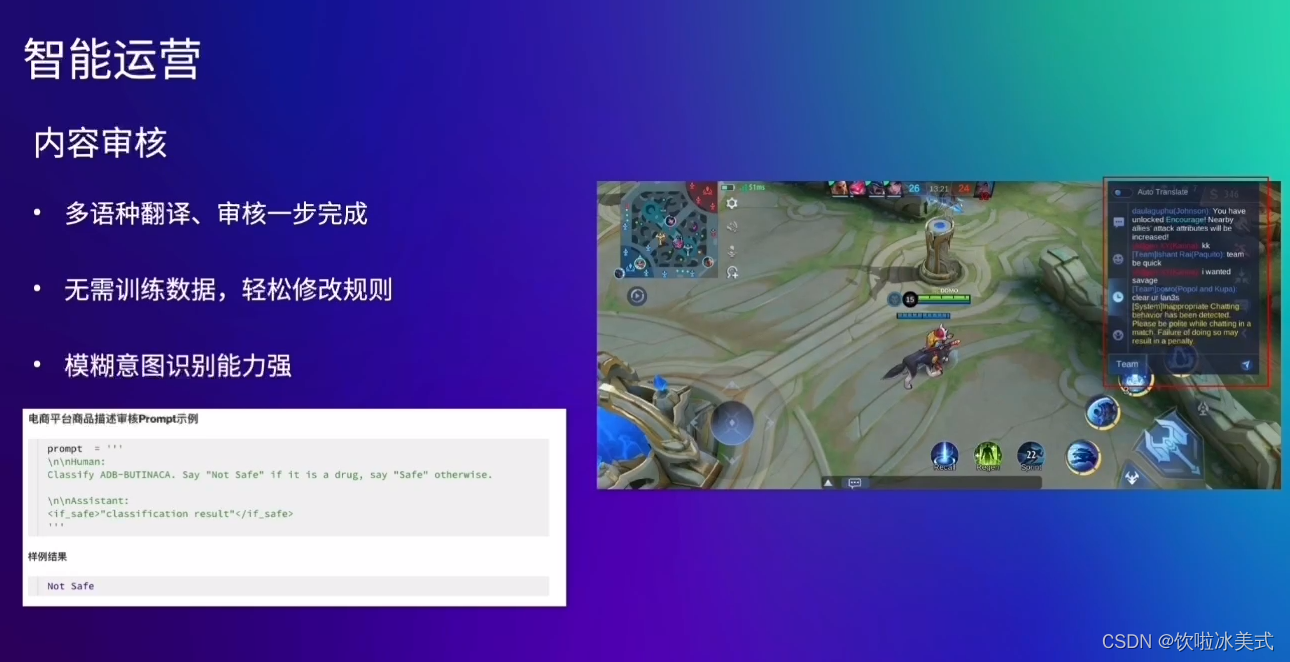
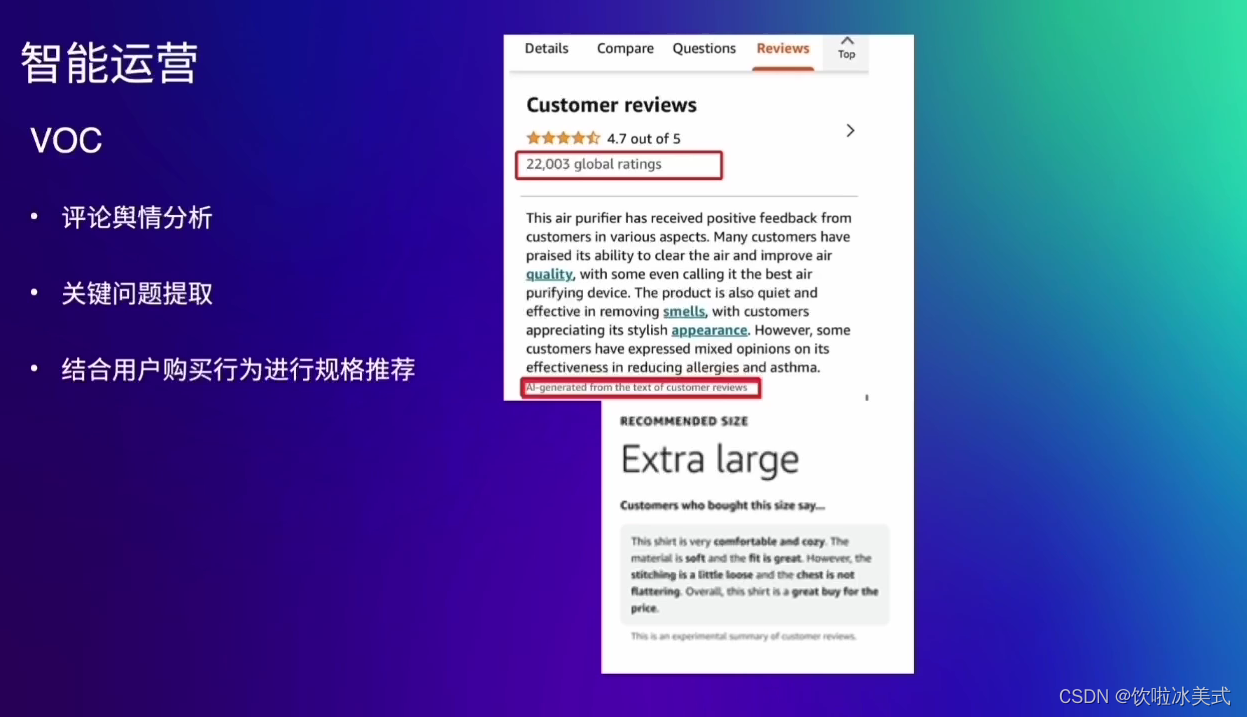
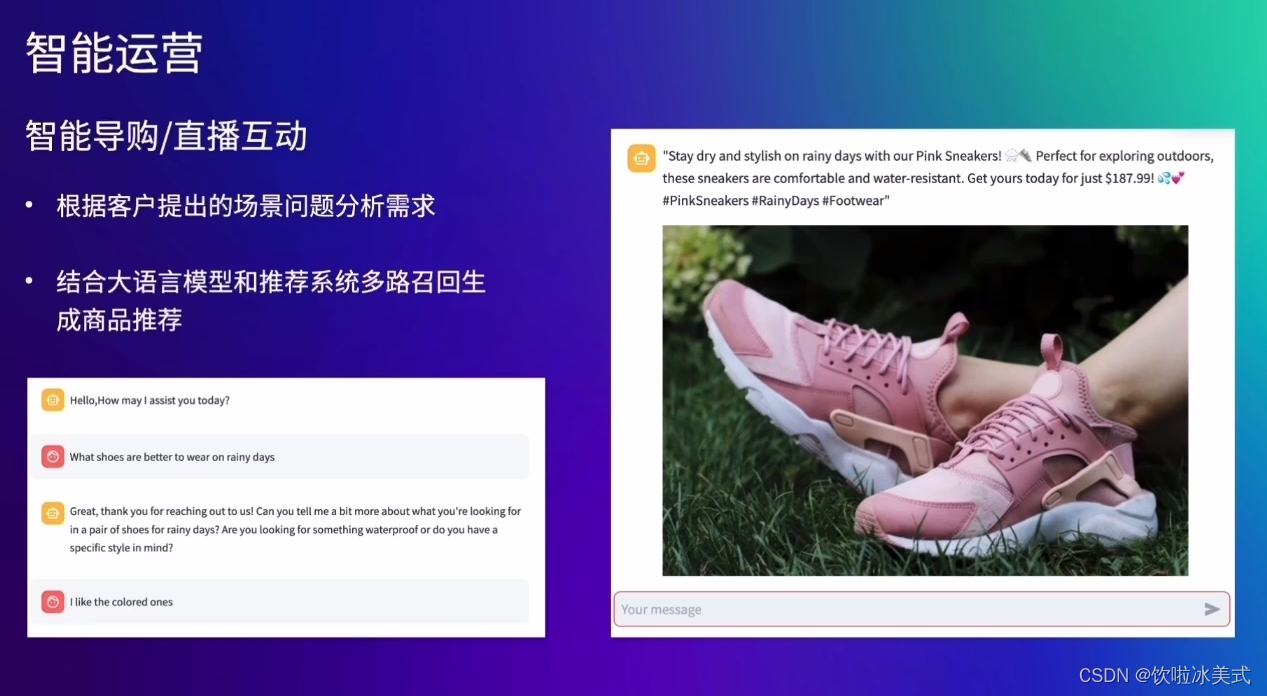
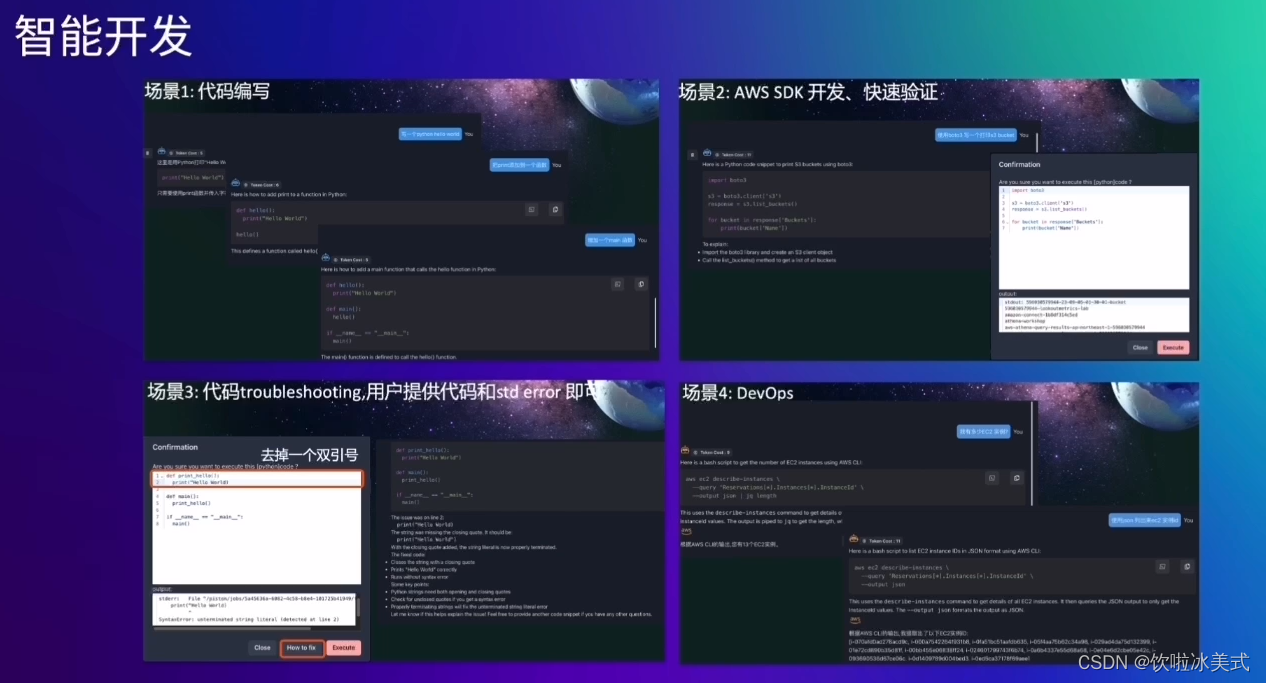
什么是Foundation Models?
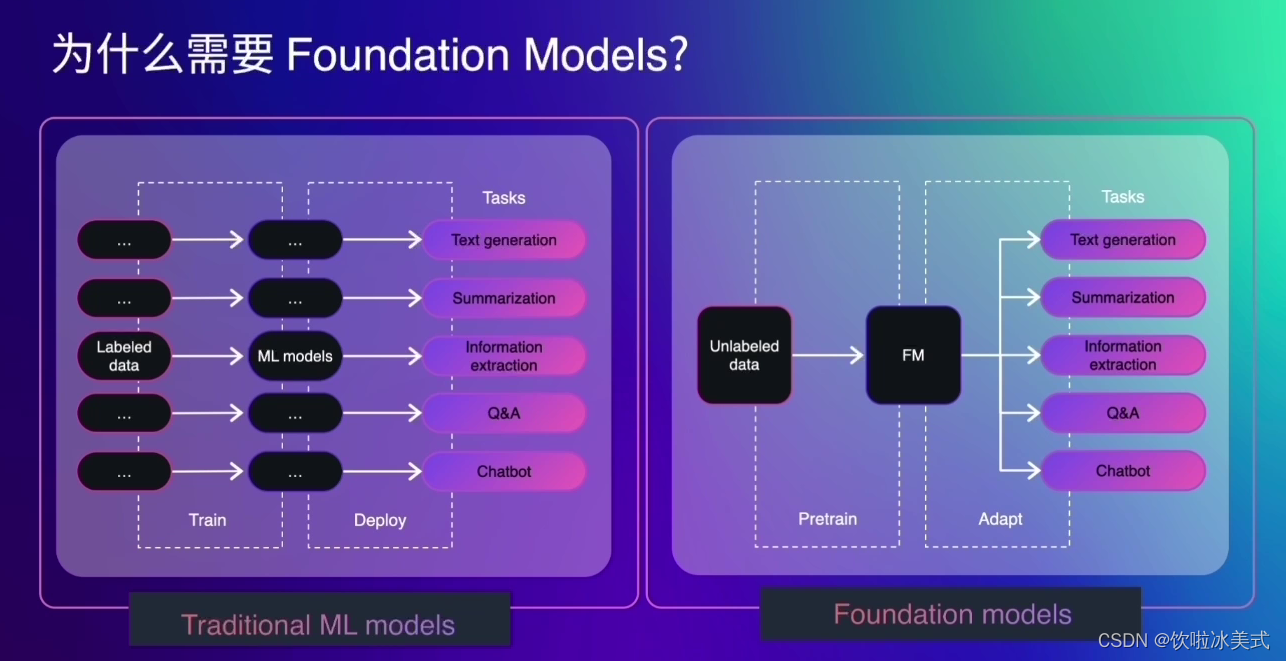
Foundation Models和我们以往传统的机器学习模型,也就是Traditional ML Models之间的区别。我们可以看到以往的机器学习模型,通常针对每一个不同的任务,我们需要一个单独的模型。这个过程之中我们还需要收集数据进行对应的训练。而Foundation Models通常一个模型就可以完成以前不同模型需要完成的多个任务,很多时候通过调整提示词就可以达到优化模型效果的作用。
文字方向

公开可获得的模型:Llama、Falcom、Mystro
闭源的:Anthropic旗下的Claude模型、Cohere旗下的Command模型
模型兼顾多语种的能力: Misto AI兼顾西语和英语,同时有独特的Moe结构,也就是我们常说的Mixture OF Experts的结构,使得它在模型参数级相当的情况下推理速度更快
百川模型,智谱旗下的Chad GLM模型
视觉方向

跟SD相关的插件,比如熟知的Web UI以及现在被大家广泛认可的Comfy UI
Comfy UI目前设计师门都在用,它可以以json的形式非常轻便的导出,便于各个部门之间去进行协作,它在进行部署时,也有非常轻便非常敏捷的优势
文字生成视频
stable Video diffusion以及Animative这两者都可以做到,在不需要大型训练的情况下,将文字转成视频
Heygen
文字生成3D
通过Luma AI旗下的文字生成3D模型,结合自己的头显设备。
Meshy
文字转声音,声音转文字。
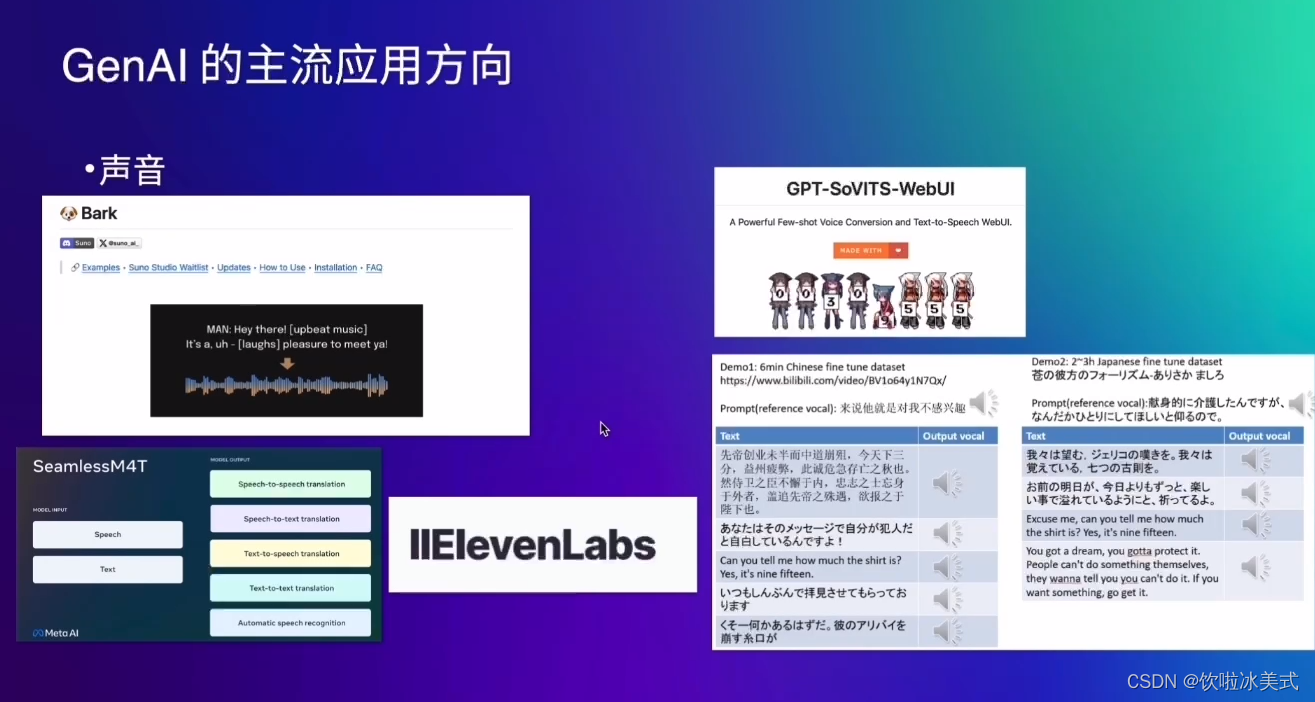
声音的克隆
比如我念一段文章,AI就可以学习我的声音去念更多的文章,这个我们叫声音克隆
speach to speach同声传译
在说话的同时可以转成另外的语言。这个过程有两个难点:
第一个难点是:我的两种不同语言的对话翻译是一步到位的。
第二点是:我翻译之后的语音和我翻译之前的语音长度要保持一致。
达到这两点之后,我们将会对声音匹配视频产生更多的应用场景的联想。
Bark
github上找到GPT Sovitus Web UI
Meta旗下发布的Seamless M4T 模型
IIElevenLabs
Heygen

比如COG VLM
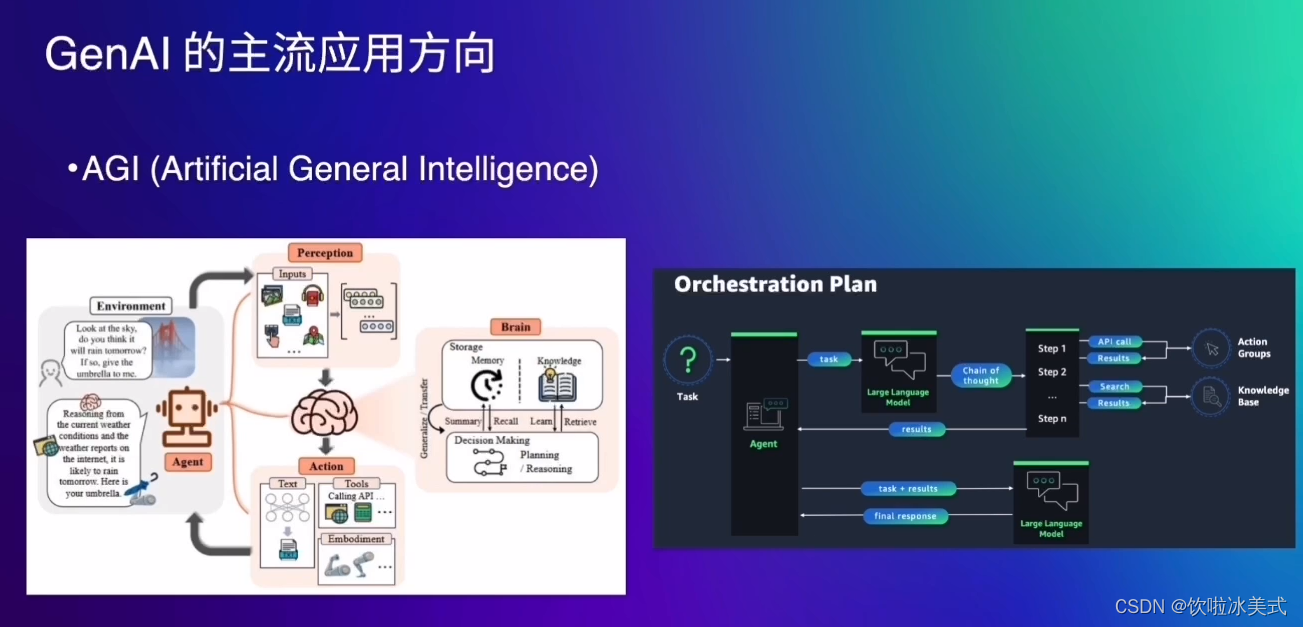
AI 智能体
常见AGI的流程:
当一个任务传递给大模型之后,首先他会哦通过chain of salt的形式去拆解任务,并识别出第一步应该做什么。它会思考是否要进行网络上的搜索,或者调用配备好的知识库,还是通过之前已有的先验知识进行回答。
应用场景
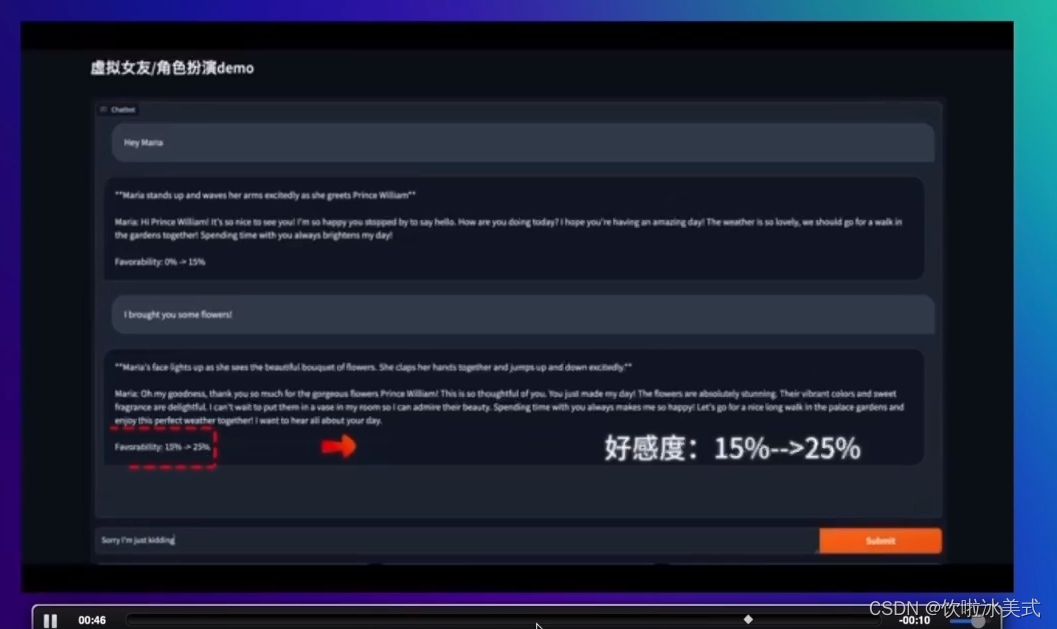
智能体与我们进行多模态的交流。通过json格式去训练微调模型,让模型学会不同的语言风格,比如温柔的,幽默的、讽刺的。

每次说一句话,好感度的提升或下降。适用于游戏剧情类
要拥有模型级服务,就是我们常说的MAS服务
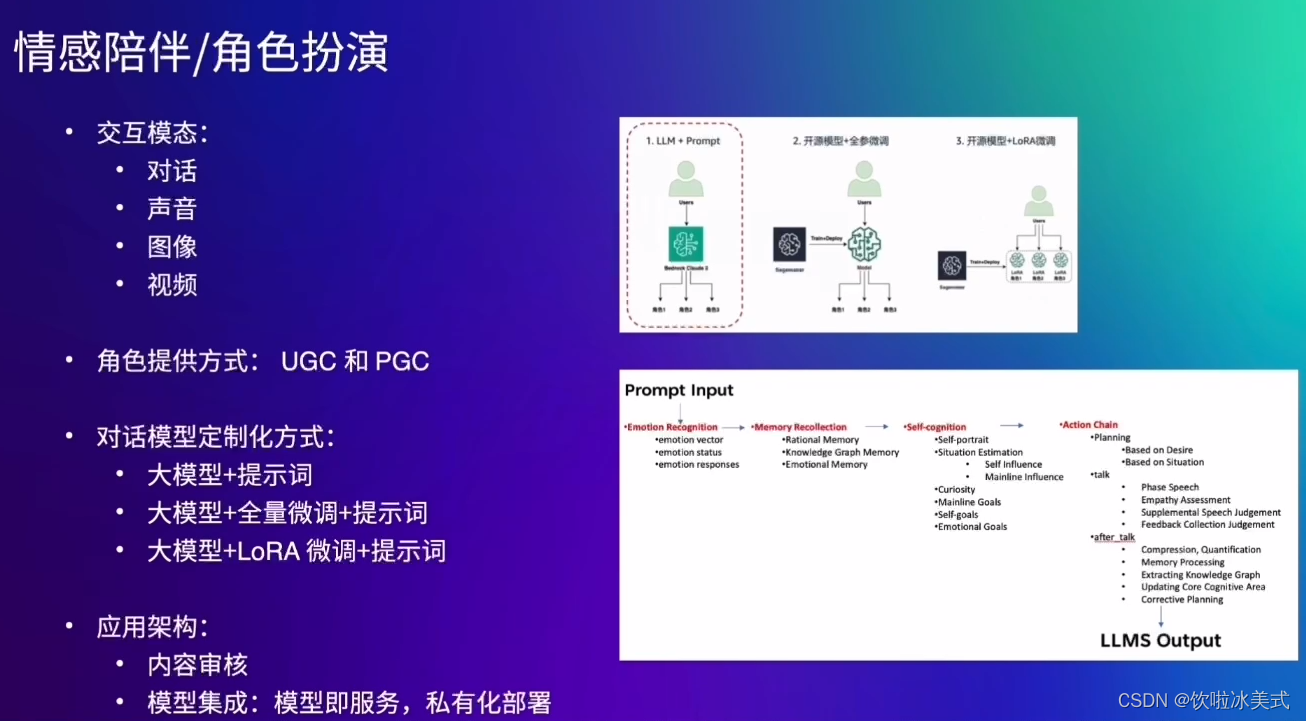
还有就是增加长短期记忆的模块,多以向量数据库为实现的底座。
最后就是增加行动的能力,为大模型增加规划、反思和工具调用的接口。
优点是快速的进行自然语言查询,而不需要Seq编码