龙年春意伊始,360人工智能研究院正式发布新的AI绘画模型:可控布局生成模型HiCo。与大家所熟悉的文生图模型相比,HiCo在普通的文本输入之上,提供了更为强大的画面布局控制能力:用户可以根据自己的构思,指定在画面不同的区域生成不同的指定内容,实现AI绘画的高可控性和创新玩法。与当前市面现有的模型相比,HiCo支持高达8+个区域的复杂可控布局生成,而且显著改善了不同区域画面的割裂感和因视角不一致问题导致的失调感,多区域布局生成结果更为自然和协调。此外非常重要的是,HiCo同时兼容英文SD社区和360人工智能研究院自研的BDM中文绘画模型(https://arxiv.org/abs/2309.00952),能够作为插件集成于现有的各种工作流。
背景介绍
在AI绘画领域中,众多研究者致力于增强AI绘画模型的可控性,他们不仅关注于模型对细节和风格的把握,还积极探索如何让模型更好地理解并模拟人类的创作思维,以便在保持艺术性的同时,提升绘画作品的实用性和个性化。
当前AI绘画的可控能力,主要引导信息包括如文本描述(Prompt-to-Prompt等)、特定类型图像(Controlnet等)、模型结构(CrossAttention等),可以达到形状、颜色、风格、布局等方面的图像可控生成。
目前市面上可控布局的图像生成模型有以下特点,一、只能进行有限粗粒度类别的图像布局可控;二、无法有效兼容开源社区能力,包括不同底模、不同LoRA等;三、可控生成能力无法有效结合概念注入能力。而360人工智能研究院自研的可控布局AI绘画模型HiCo (Hierarchical Controllable diffusion model for layout-to-image generation),可以实现不同粗细粒度文本描述的布局可控,且能够无缝迁移开源社区的各种能力,同时也具有概念的位置可控生成。
方法概述
基于扩散模型的图片可控生成方向经典论文Controlnet、IP-Adapter等,提出了可以通过外部引导条件如Canny、Depth、OpenPose等不同条件图来实现最终图片的可控生成。
人工智能研究院自研的可控布局生成模型HiCo借鉴上述文章中外部控制条件生成思想,通过图片布局的空间位置和文本描述,结合图片分层的原理来实现布局可控生成。我们模型的生成引导条件为用户输入的sub-boundingbox及对应的sub-caption,同时也可提供图片背景描述的global-caption。我们模型巧妙的避免了对文生图基础模型UNet部分的训练,仅训练一个轻量级的可插拔模块即可实现图片布局可控生成的目的,同时可以无缝兼容开源Stable Diffusion 1.5、XL模型社区生态,包括不同的底模、不同LoRA、LCM/LCM-LoRA快速生成等能力。
HiCo可控布局模型的工作原理,利用可训练的HiCo Net来生成不同指定区域内容及全局背景,主干UNet部分对不同HiCo Net输出结果和背景进行融合生成协调的图像。
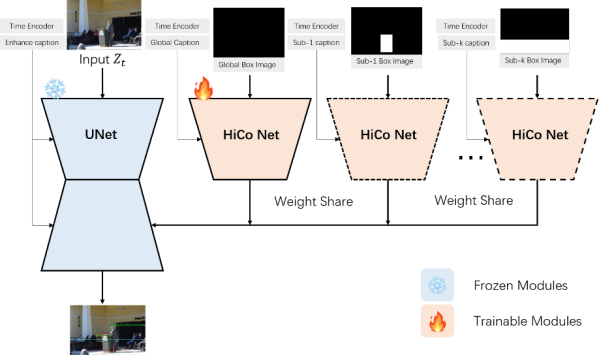
图1:分层布局可控生成模型HiCo结构
原始的Stable Diffusion模型的目标函数为:
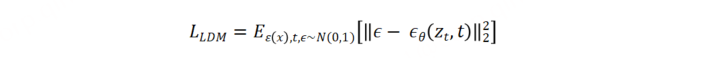
外部控制条件的扩散模型训练训练目标,给定输入图片Z0,通过渐进式扩散加噪到Zt,其中t为加噪步数,Ct为文本控制条件,Cf为特定控制条件,єθ为可学习的网络来预测不同阶段的噪声,其目标函数可以表示为:
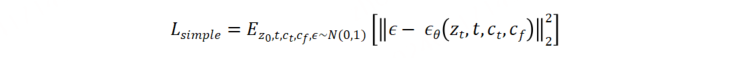
HiCo原理图可以看出相对于原生Stable Diffusion模型,新增额外的HiCo Net来生成全局背景和不同布局区域内容,由于增加了多个不同的控制条件,则训练目标为:

能力应用
我们将分别展示HiCo模型结合不同模型及插件的效果。下面是可控布局生成模型HiCo的多目标可控生成的效果展示。

图2-1:3个目标布局可控生成
其中左图为用户指定的3个不同区域以及不同区域内指定的生成内容,右图为最终的生成结果,中间图为将用户的布局输入overlay到生成图像上验证布局控制的效果

图2-2:5个目标布局可控生成
下面是可控布局生成模型HiCo的结合不同基础模型checkpoint的多目标可控生成的效果展示,对应的不同基础模型为midjourneyPapercut、realisticVision、disneyPixarCartoon、flat2DAnimerge。为了便于验证布局控制的效果,我们将用户输入的布局(区域框+区域prompt)overlay到最终的生成图像上进行展示。

图3:不同基模型可控布局生成效果
下面是可控布局生成模型HiCo的结合不同LoRA的多概念可控生成的效果展示,对应的不同LoRA为Blindbox_v3、Shrek。

图4:概念嵌入的布局可控生成效果
此外,HiCo还可以与LCM/LCM-lora等兼容,实现快速生成。下面是可控布局生成模型HiCo结合LCM/LCM-LoRA的可控快速生成的效果展示,对应的LCM步数为:4-steps、6-steps、8-steps。
 图5:不同steps的可控布局LCM快速生成效果
图5:不同steps的可控布局LCM快速生成效果
指标验证
我们基于GRIT-20M,人工修订后构建了GRIT-VAL评估集,用于定量评估HiCo的可控布局生成能力。GRIT-VAL包含300张以自然场景为主的图片,并携带有丰富的目标位置标注和详细文本描述标注。
在GRIT-VAL评估集上,对比英文SD基础模型、英文模型 + HiCo、中文BDM基础模型、中文BDM+ HiCo,我们评估了包括目标数量、目标语意及位置等在内的维度。其中中文模型的评测使用翻译将英文prompt翻译为中文后进行,翻译引入的误差造成中文BDM+HiCo的布局控制评分稍低于英文版本。
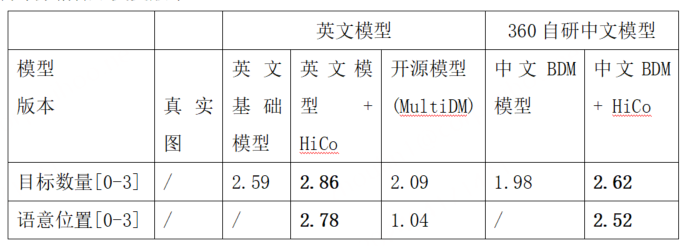

图6:GRIT细粒度无限制文本描述图片生效果
作为更多展示,以下也给出基于COCO的区域标注和粗粒度文本描述(只有类别名),使用HiCo模型(英文)得到的生成效果:

图7:COCO粗粒度有限制文本描述图片生效果
总结展望
360人工智能研究院本次发布的可控布局生成模型HiCo,在普通的文本输入之上,提供了更为强大的画面布局控制能力。HiCo主要在自然场景下不同粗细粒度的数据上训练,相关指标评估体现出HiCo模型的先进性。模型当前仍然存在进一步提升空间,尤其在图片内容编辑、多风格概念注入等能力上。基于HiCo模型,可以大幅提高AI绘图的可玩性。大家稍后就可以在360智绘(aigc.360.com)中实际体验把玩。