本教程以AutoDL-AI算力云为线上炼丹平台讲解操作案例,还有一些其他的常用线上炼丹平台(如阿里云、青椒云等)。提前打一针:这类平台其实是在线租用服务器主机,只需充值较少的money(一般几毛钱-2元多/小时)即可开始炼丹。既然我们有些同学的电脑配置达不到炼丹要求,那么就可以用这种方式进行炼丹,同学们可以根据需求自行选择。当然,电脑配置完全符合炼丹需求的同学,可以直接在自己电脑上本地训练即可。
想要赠送的炼丹7大助力礼包(素材图采集爬虫软件、本地炼丹软件包、lora分层自动统计数据表、SD-XL进阶教程等)+2000G赠送模型+以及想要系统的学习12节完整lora模型训练课程的同学可以移步至:
LORA基础及SDXL-lora进阶模型训练教程_哔哩哔哩_bilibili https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click完成以上12节学习课程后,直接私信老师获取炼丹大礼包即可。
https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click完成以上12节学习课程后,直接私信老师获取炼丹大礼包即可。
下面开始今天的讲解:
注册登录AutoDL平台。AutoDL平台网址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
填写自己的注册信息登录即可。
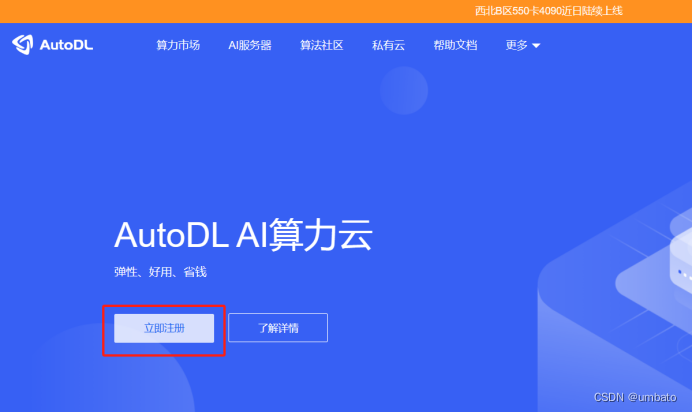
登录后,点选上方的“算力市场”,进入到如下页面:
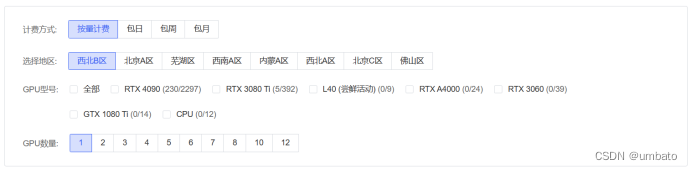
紧接着下面就可以选择需要租用的主机了,显示“1卡可租”即表示可以租用,显示灰色不可点选按钮,则需要租用下方的其他主机。另外,还可以同时租用多部主机。
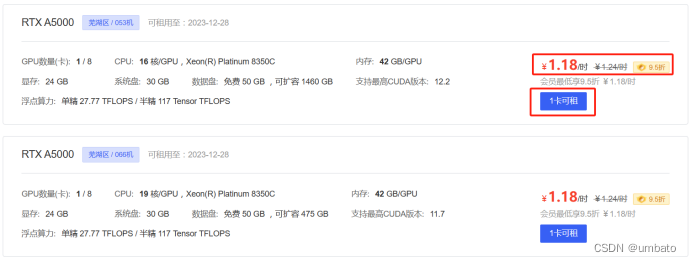
选择好需要租用的GPU型号主机后,会进入到下面图示界面,如果想要扩展数据盘存放更多的资料,就勾选需要扩容,然后输入要扩展的容量大小。需要提醒的是,不管租用的主机是否点选关机,按量计费实例的付费数据盘将按 0.0066元/日/GB在每日24点进行扣款(无论实例是否关机),也就是不管你用不用主机训练模型,扩展了数据盘都会每日扣费,可自行选择是否扩展数据盘。
接着选择“社区镜像”——点击下方的空白输入框——自动弹出镜像选择页面——选择“V1.7.2版本”:
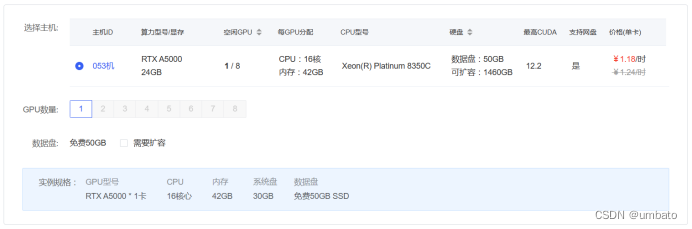

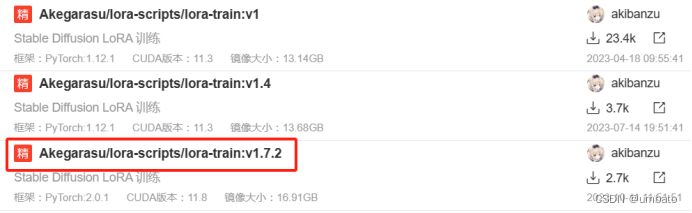
接着点击右下角的“立即创建”按钮,直接付费即可。
我们成功租用主机后,点击右上角的控制台,可以查看到租用的实例信息、个人信息、余额信息等。为什么下方图示会显示容器实例为2?


因为图示中租用了2个实例,点击上图中的租用新实例按钮,参照以上租用主机创建实例的方式再操作一遍即可。
每次训练Lora模型时,我们需要进入容器实例点选开机,才能训练。一旦训练结束或者不再需要连接主机时,
我们需要点选关机,否则会一直按时间扣费!
我们需要点选关机,否则会一直按时间扣费!
我们需要点选关机,否则会一直按时间扣费!
因此,如果我们关机后再次进入容器实例时,有可能这个主机正在被别人使用,需要等到释放,显示GPU充足,我们才能开机进行训练。为了避免这种情况,一般都会选择租用2个及以上容器实例,当一个实例被别人占用时,我们还可以开机另外一个进行模型训练,当然需要保持另外一个是关机状态。

我们接着往下看,如上图所示,点选开机后,稍微等待几秒钟,会出现”SSH登录”和“快捷工具”栏,我们点击“快捷工具”下方的“JupyterLab”选项,即可进入系统盘和数据盘界面,如下图所示:
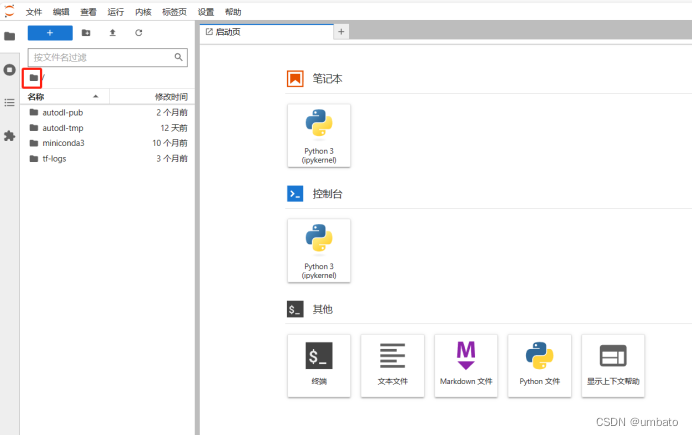
如果你的界面是第一次进入,此时不在这个系统界面,可以点选上图示例中红色框标注的文件夹符号,进入此页面(其实就是找到上一级文件夹)。
这里,要特别注意下面的操作:
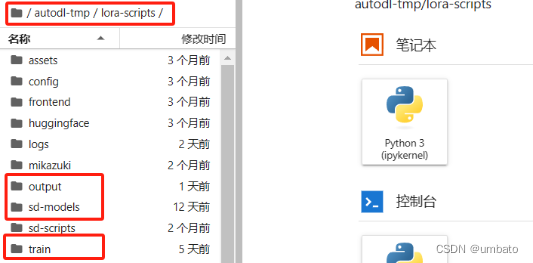
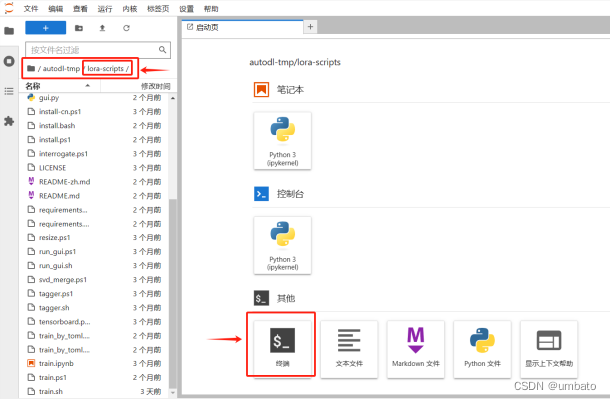
autodl-pub是指系统盘,可以看作我们电脑上的主机C盘。autodl-tmp是指数据盘,可以看作我们电脑上存放资料的D/E/F盘等。将autodl-pub系统盘中的”lora-scripts”文件夹整个剪切复制进autodl-tmp数据盘中,否则后期训练上传的大模型和数据集会占满系统盘,影响训练。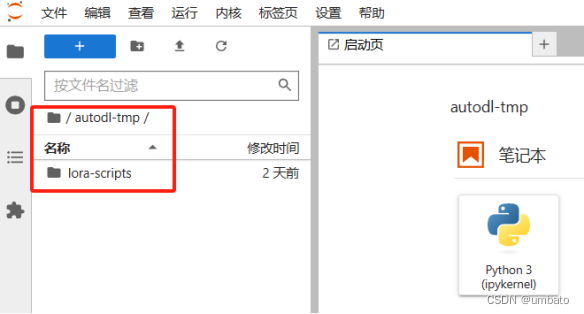
最后如上图所示,“lora-scripts”文件夹就放置在了autodl-tmp数据盘中。




train.sh配置文件的训练参数设置
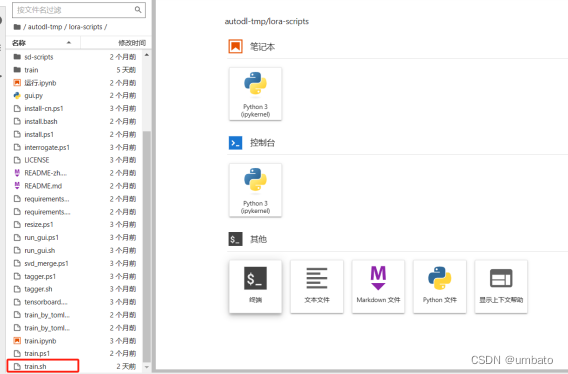

等),如果是训练二次元模型,需要选择二次元底模(如anything-v5-PrtRE、revAnimated_v122等)。关于底模的选择,可以是SD系列的基础大模型,也可以是别人训练好的大模型,但是如果使用别人训练好的大模型作为底模进行训练的话,有可能出现只擅长此大模型下绘图,而在其他大模型下绘图效果较差或者不适用的情况,除非你就是需要一个配合某个大模型出图的Lora模型,那就无所谓了。大家可以根据需求自行选择。
总结:
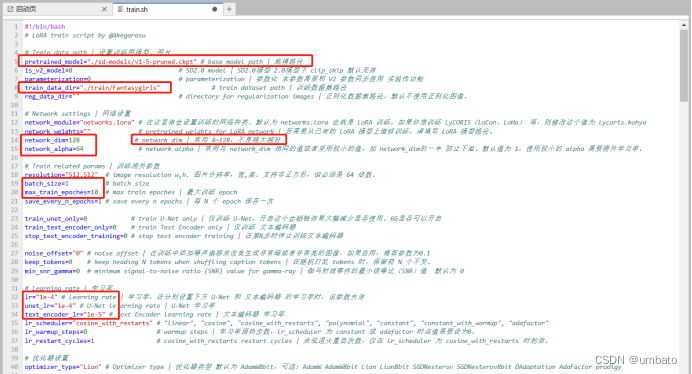
针对需要泛化性比较好的模型训练,可以选择SD原始基础底模系列。针对和某个大模型配合使用的模型训练,可以选择需要配合使用的那个大模型作为底模。 Train_data_dir=“./train/Fantasygirls”:训练数据集路径名称。重点注意一下这里,我们之前将所有的素材图和Tag标签文本放在了“train”文件夹——“Fantasygirls”文件夹——“30_Fantasygirls”文件夹内,但是这里我们只需要将路径名称写到“Fantasygirls”文件夹这一层即可,即标注每张图片训练次数文件夹的上一层文件夹。如果将路径名称直接写到“30_Fantasygirls”文件夹这一层,训练时会报错!
Network_dim=128:训练网络维度,常用建议最大设置128,其他还有64、32。但是并不是设置越大越好,如果学习内容比较复杂,可以设置128甚至更高,但还需根据实际情况选择。网络维度越大,学习细节越多,学习速度越慢,学习时间越长,但是容易出现图片过拟合的情况。
网络维度越大,模型体积越大,比如设置为32,对应Lora模型最终体积可能出到44M大小,设置为128,可能会出到144M大小。
net_work_alpha=64:一般设置为训练网络维度的一半或者相同数值即可,常用就是设置为训练网络维度值的一半。比如Network_dim=128,那么net_work_alpha=64。batch_size=1:批次处理值,可以理解为每次训练同时选取的素材数,建议不超过3。比如总训练步数有1万步,那么batch_size=1,就还是训练1万步,batch_size=2,总训练步数就变成了5千步。网络维度和其他参数的具体释义可以参考12节系统lora模型训练教程中的专门讲解:
LORA基础及SDXL-lora进阶模型训练教程_哔哩哔哩_bilibili https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click
总结:
(1)batch_size值越小,学习越精细,学习速度越慢,但是收敛越慢也越难。收敛可以简单的理解为,模型训练过程中最终趋于稳定的一个阈值或者状态。
(2)batch_size值越大,学习跨度越大,学习速度越快,但是学习也越不仔细,而且由于同时处理的任务数变大,所以对电脑计算配置要求变高,可能会导致始终找不到最优值,最终模型泛化性越差。
(batch_size变大会将训练步数减少,可能会提前到达一个拟合点,如果继续用较小的学习率,可能始终找不到最佳收敛点,导致过拟合。因此学习率也需要对应增大,以适应提前结束学习。)
max_train_epochs=10:总训练轮次数值,10即表示总共训练10轮。设置过大,容易过拟合,导致最终模型失去泛化性,一般建议5-20轮即可。1r=“1e-4”:学习率值,可以理解为学习的速度,速度太快可能会不仔细,速度太慢又可能耗费时间,建议初次训练保持默认即可。当设置了以下unet_1r和text_encoder_1r两个参数时,此值失效。unet_1r=“1e-4”:U-Net学习率,同上。1e-4=0.0001,即1*10的-4次方。建议初次训练保持默认即可。batch_size和学习率的关系需要注意一下:
当你需要调节batch_size的值时,对应的学习率也应该调节,一般是batch_size的值乘以N倍时,对应的学习率也应该乘以N倍。但是并不是绝对,还是要根据素材数量、质量等实际情况修改调节学习率参数值。比如原来是batch_size=1,unet_1r=“1e-4”,现在要调节为batch_size=2,unet_1r=“2e-4”去做训练时,出现了“Loss=NAN”,那就不合适,需要调节学习率或调整数据集。
text_encoder_1r=“1e-5”:文本编码器学习率。1e-5=0.00001,即1*10的-5次方。建议初次训练保持默认即可。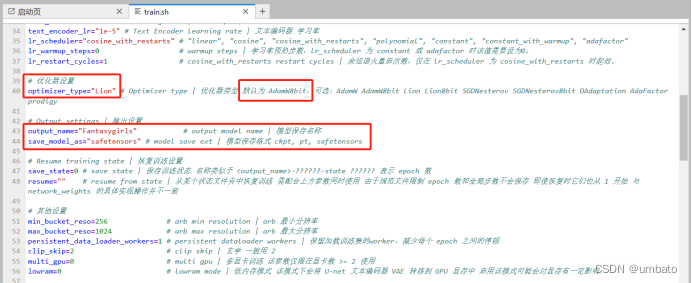
开始训练
以上预训练工作准备完成之后,我们就可以开始训练属于自己的Lora模型了。

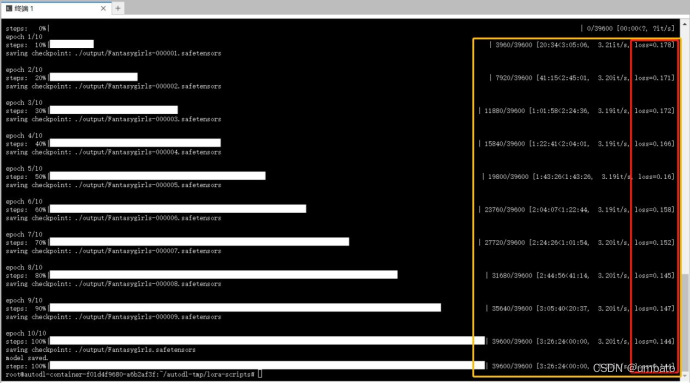
至此,我们在线上云端训练Lora模型的操作,就全部完成了。训练后的每一轮模型都会自动存放在output文件夹中,直接将所有模型全选下载至本地需要存放的文件夹中即可。
最重要的一点,训练完成后,如果不再需要在线系统继续运作,一定要选择关机!一定要选择关机!一定要选择关机!否则会一直扣光你充值的钱!
4、模型训练过程中的注意事项
1、训练底模可能会报错
我们训练Lora模型前,会提前上传训练用的大模型底模至sd-models文件夹中备用,可以上传一个,也可以选择需要的一次性全部上传。建议选择两三个常用的底模大模型上传即可,比如一个SD1.5系列底模、一个真人大模型、一个二次元大模型。上传过多的话,可能有些很长时间都用不到,还一直占用数据盘内存。
如果训练过程中提示大模型底模出错,可以查看train.sh配置文件中的底模路径(其他路径设置也要检查)是否填写正确。如果检查后路径填写正确但是依然报错,可以选择本地的此底模重新再上传一次,一般都能解决。
总结:
A、检查train.sh配置文件底模路径是否正确。
B、重新上传大模型底模。
2、文件名可能会报错
文件夹和文件夹内的文件,一般以英文字母或英文字母加下划线的形式命名。不允许有空格以及特殊字符出现(比如*、#等),否则会报错。
注意以上两点,然后按照教程操作,就可以直接训练Lora模型了。
3、训练核心数据但是,就目前为止,不建议直接开始训练,还是要学习完12节系统lora模型课程之后,再进行训练操作,因为后续的课程中有一期是直接带领大家去训练出一个人物和一个画风的模型,包括了训练数据的参考标准总结和经验,这也是帮你省钱省时间省精力的精髓。
在课程前言我们也提到过,如果你直接开始训练,可能会不停的调整训练参数,比如素材图质量、数量、训练轮次等,一轮又一轮,一次又一次的不停调试,观察每一次的Loss损失函数值和其他数据,那么这就是一个耗费时间和精力以及金钱的过程。就像现在,这段文字我告诉你,只需三五秒钟的时间,但是实际过程中,你可能要花费三五天的时间甚至一个星期才能调整到自己满意的一个数据状态。因此,如果有了后续的一期数据总结教程作为参考标准,那么参考这个数据总结标准,你就可以直接调整参数进行训练,尽可能一次性的完成达标训练了。这也是为什么很多人在网上看了很多lora模型训练教程,到了自己实操时依然训练不好的原因。实际上你只是跟着其他人学会了如何去训练lora模型的整体大概流程,而训练数据总结的一个核心参考标准并没有给到你。但是参考标准也只是参考标准,每个人训练的模型都是千差万别的,要学会在参考标准的基础上,举一反三,总结自己的训练经验,才能更加深入的了解、训练和运用模型。
想要赠送的炼丹7大助力礼包(素材图采集爬虫软件、本地炼丹软件包、lora分层自动统计数据表、SD-XL进阶教程等)+2000G赠送模型+以及想要系统的学习12节完整lora模型训练课程的同学可以移步至:
LORA基础及SDXL-lora进阶模型训练教程_哔哩哔哩_bilibili https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/cheese/play/ss11227?query_from=0&search_id=12779842912835973476&search_query=lora%E8%AE%AD%E7%BB%83&csource=common_hpsearch_null_null&spm_id_from=333.337.search-card.all.click