简介
下一代网络爬虫是爬虫级 AI agents。
由于现代网页的复杂性,现代爬虫都倾向于使用高性能分布式 RPA,完全和真人一样访问网页,采集数据。由于 AI 的成熟,RPA 工具也在升级为 AI agents。因此,网页爬虫的发展趋势是爬虫级智能体(AI agents),或者我喜欢称为数字超人。
高性能分布式 RPA
互联网数据收集现在都使用高性能分布式 RPA。搭载 AI 的 RPA 也是 AI agents。爬虫级 RPA 可以完全和你本人一样操作浏览器,为你创建一个智能体军团,在网上自由冲浪,完整精确采集数据和知识。
商用级数据收集非常困难,步步维艰,但凡对数据质量、调度质量、采集性能、数据规模、综合成本有一些要求,都面临着成千上万个困难。
幸运的是,我们现在有了 AI + RPA 的成熟方案完整解决这些难题。
PulsarRPA 的性能非常高,成本非常低,一台普通机器每天访问十万几十万网页,采集数千万上亿数据点,毫无压力。
高性能分布式 RPA 在网页上执行了交互动作,保证了所有字段均完整呈现在页面上,每个页面会有 100~200 个高价值字段被提取出来。一台机器一天可以采集1700万到3400万个字段。
下面的视频,介绍了如何用 PulsarRPA 完整精确采集最复杂的网站数据,具备最严格的质量保证体系、满足最严苛的系统性能和总体成本要求。
PulsarRPA - 适用于网络爬虫和 AI agents 的高性能分布式 RPA https://blog.csdn.net/weixin_48738961/article/details/135700524PulsarRPA 是目前应用于大规模数据采集,唯一成熟的开源 RPA。
https://blog.csdn.net/weixin_48738961/article/details/135700524PulsarRPA 是目前应用于大规模数据采集,唯一成熟的开源 RPA。
商用级项目示例
作为 PulsarRPA 的一个真实商用项目示例,Exotic Amazon (国内镜像)是采集 amazon 全球网站的完整解决方案,开箱即用,满足最高标准的数据质量要求、最高标准的采集性能要求、最高标准的综合成本要求,包含亚马逊大多数数据类型,它将永久免费提供并开放源代码。
作为一款爬虫级 RPA,PulsarRPA 已经累计为各种客户采集近百亿网页。其中包括了最复杂的数据采集需求,譬如 amazon 全球 20 大站点的完整数据点,以及 google 全球站点的完整数据点。
智能体军团
在如此严苛的需求锤炼之后,PulsarRPA 已经非常成熟。目前我们的产品重心是真正意义上的 AI 爬虫。
AI 爬虫指的是一组智能体,也就是 AI agents,它能够像真人一样网上冲浪,阅读理解在线网页,并且可以完全自动地分析网页,输出结构化数据或者知识图谱。
Platon.ai 的高性能分布式浏览器,可以帮助大语言模型无障碍访问互联网,获得实时、干净的网页数据。
Platon.ai 基于机器学习技术采集的数据,可以支持各种各样的数据业务,譬如电商数据分析,大语言模型预训练、微调、提示词工程、检索增强生成(RAG)等。
无监督学习数据提取
互联网数据充满噪音,platon.ai 的技术帮助我们自动将互联网网页转变成干净的结构化数据。
在传统上,我们需要使用 PulsarRPA,或者 selenium 这样的浏览器自动化工具,花费大量时间,编写X-SQL、CSSPath、XPath、正则表达式等,来提取网页数据,将网页转变成可以直接分析的结构化数据。
使用 platon.ai 的 AI 爬虫 PulsarRPAPro,可以像真人一样无障碍网上冲浪,自动提取网页中的所有字段,输出结构化数据。
PulsarRPAPro-AI高速采集并自动提取网页数据-CSDN博客 https://blog.csdn.net/weixin_48738961/article/details/135701063执行 PulsarRPAPro 后,系统将打开入口页面,和网页进行交互,等待延迟加载的网页内容也完整呈现。
https://blog.csdn.net/weixin_48738961/article/details/135701063执行 PulsarRPAPro 后,系统将打开入口页面,和网页进行交互,等待延迟加载的网页内容也完整呈现。
在所有网页内容完整呈现后,PulsarRPAPro 智能地找到了所有商品链接,并逐一访问这些链接,浏览商品页面。
在网页上,凡人眼可见的数据,几乎都能够被完整、精确提取出来,譬如,标题、价格、折扣、优惠、配送等等关键字段。
和真人不同的是,PulsarRPAPro 访问速度非常快,访问的网页数量没有限制,单机每天访问十万、几十万网页,采集数千万、上亿数据点,毫无压力。
访问所有网页后,PulsarRPAPro 直接将网页上所有的数据转变为表格,并且保存为后续分析所需的格式。
监督学习数据提取
PulsarRPAPro 使用多种机器学习技术,来将网页内容提取工作人效提升 1000 倍以上,而人员技能要求也几乎降为零。
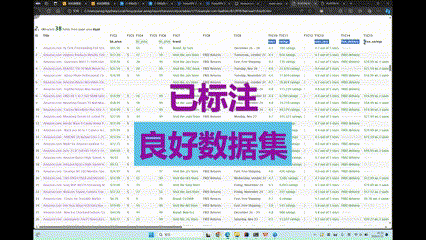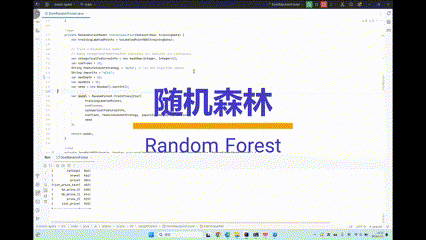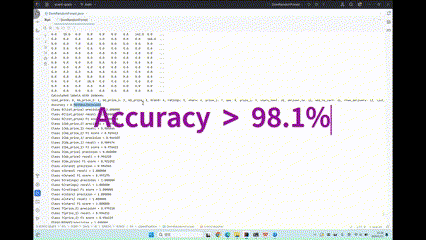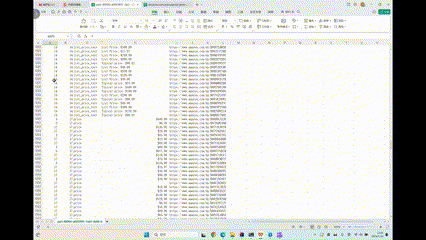
如果对数据质量有进一步要求,PulsarRPA 也开发了监督学习技术来提取网页,一次训练,永久有效。
PulsarRPAPro-基于监督学习算法高精度提取网页数据-CSDN博客文章浏览阅读125次,点赞2次,收藏3次。使用无监督学习+监督学习进行网页数据提取,我们将网页数据提取的人效提升了1000倍以上,提升了数据提取准确率,降低了人员技能要求,同时也不再需要频繁维护数据提取规则。https://blog.csdn.net/weixin_48738961/article/details/135702207由于我们能够无监督学习将网页转变成表格,我们只需要在这个表格上处理,简单剔除错误数据,并给每一列字段一个名字,这就形成了可以用于训练监督学习模型的大数据集。这个过程不需要任何专业知识,初中知识储备就可以胜任。
使用监督学习技术,绝大多数字段,准确率和召回率均超过99%。
未来演化
在下一步,PulsarRPA 将引入大语言模型,提供自然语言交互界面,优化从数据采集、UI 操作、自主决策、数据标注、数据导出等各个环节的用户体验,并提供一定自主决策能力。
代码示例
大多数抓取尝试可以从几乎一行代码开始
fun main() = PulsarContexts.createSession().scrapeOutPages( "https://www.amazon.com/", "-outLink a[href~=/dp/]", listOf("#title", "#acrCustomerReviewText"))上面的代码从一组产品页面中抓取由 css 选择器 #title 和 #acrCustomerReviewText 指定的字段。 示例代码可以在这里找到:kotlin,java,国内镜像:kotlin,java。
大多数生产环境数据采集项目可以从以下代码片段开始
fun main() { val context = PulsarContexts.create() val parseHandler = { _: WebPage, document: Document -> // use the document // ... // and then extract further hyperlinks context.submitAll(document.selectHyperlinks("a[href~=/dp/]")) } val urls = LinkExtractors.fromResource("seeds10.txt") .map { ParsableHyperlink("$it -refresh", parseHandler) } context.submitAll(urls).await()}示例代码:kotlin,java,国内镜像:kotlin,java。
最复杂的数据采集项目可以使用 RPA 模式
最复杂的数据采集项目往往需要和网页进行复杂交互,为此我们提供了简洁强大的 API。以下是一个典型的 RPA 代码片段,它是从顶级电子商务网站收集数据所必需的:
val options = session.options(args)val event = options.event.browseEventevent.onBrowserLaunched.addLast { page, driver -> // warp up the browser to avoid being blocked by the website, // or choose the global settings, such as your location. warnUpBrowser(page, driver)}event.onWillFetch.addLast { page, driver -> // have to visit a referrer page before we can visit the desired page waitForReferrer(page, driver) // websites may prevent us from opening too many pages at a time, so we should open links one by one. waitForPreviousPage(page, driver)}event.onWillCheckDocumentState.addLast { page, driver -> // wait for a special fields to appear on the page driver.waitForSelector("body h1[itemprop=name]") // close the mask layer, it might be promotions, ads, or something else. driver.click(".mask-layer-close-button")}// visit the URL and trigger eventssession.load(url, options)示例代码: kotlin,国内镜像。
Web 数据抽取难题可以使用机器学习来解决
使用无监督学习+监督学习进行网页数据提取,我们将网页数据提取的人效提升了1000倍以上,提升了数据提取准确率,降低了人员技能要求,同时也不再需要频繁维护数据提取规则。
Web 数据抽取难题也可以用 X-SQL 来解决
除了使用机器学习手段提取人眼可见数据外,一些人眼不可见数据、页面源代码中的数据、其他流经浏览器的数据,也可以使用 X-SQL 来提取。
现在,我们在大型数据采集项目中,所有提取规则都是用 X-SQL 编写的,数据类型转换、数据清理等工作也由强大的 X-SQL 内联处理。编写 X-SQL 做数据采集项目的体验,就像传统的 CRUD 项目一样简单高效。一个很好的例子是 x-asin.sql(国内镜像),它从每个产品页面中提取 70 多个字段。
select dom_first_text(dom, '#productTitle') as title, dom_first_text(dom, '#bylineInfo') as brand, dom_first_text(dom, '#price tr td:matches(^Price) ~ td, #corePrice_desktop tr td:matches(^Price) ~ td') as price, dom_first_text(dom, '#acrCustomerReviewText') as ratings, str_first_float(dom_first_text(dom, '#reviewsMedley .AverageCustomerReviews span:contains(out of)'), 0.0) as score from load_and_select('https://www.amazon.com/dp/B09V3KXJPB -i 1s -njr 3', 'body');示例代码: Exotic Amazon’s X-SQLs.
如需了解更多,可以看项目主页,国内镜像 或者 专栏文章 或者在线教程。