结合最新AI模型与Python技术处理和分析气候数据。介绍包括GPT-4等先进AI工具,旨在帮助大家掌握这些工具的功能及应用范围。内容覆盖使用GPT处理数据、生成论文摘要、文献综述、技术方法分析等实战案例,能够将AI技术广泛应用于科研工作。特别关注将GPT与Python结合应用于遥感降水数据处理、ERA5大气再分析数据的统计分析、干旱监测及风能和太阳能资源评估等大气科学关键场景。课程旨在提升课程参与者在数据分析、趋势预测和资源评估等方面的能力,激发创新思维,并通过实践操作深化对AI在气象数据分析中应用的理解。
1、掌握AI工具应用:熟练掌握如GPT-4等前沿AI工具在大气科学中的应用,包括数据获取、处理和分析。
2、提高编程技能:通过GPT的实践操作,提升学员使用Python编程技术处理气象数据的能力,包括使用相关库(如xarray、pandas)进行数据分析和可视化。
3、增强数据分析能力:能够独立进行气候数据的趋势分析、干旱监测、风能与太阳能资源评估等复杂数据分析,使其能够识别和解释气候变化模式。
原文链接 https://mp.weixin.qq.com/s?__biz=MzUyNzczMTI4Mg==&mid=2247684268&idx=1&sn=450ea15b3edbfa40dd85342d3e1f1749&chksm=fa774f91cd00c687ac24f48a98dc56e84f3f12575b815a29b0534233b7ad3c4f45e7b59b5d5f&token=1262054614&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzUyNzczMTI4Mg==&mid=2247684268&idx=1&sn=450ea15b3edbfa40dd85342d3e1f1749&chksm=fa774f91cd00c687ac24f48a98dc56e84f3f12575b815a29b0534233b7ad3c4f45e7b59b5d5f&token=1262054614&lang=zh_CN#rd
专题一、预备知识
1、AI领域常见工具模型
1.1.OpenAI模型-GPT-4
1.2.谷歌新模型-Gemini
1.3.Meta新模型-LLama
1.4.科大讯飞-星火认知
1.5.百度-文心一言
1.6.MoonshotAI-Kimi
2、POE平台及ChatGPT使用方法
2.1.POE使用方法
2.2.ChatGPT使用方法
3、提示词工程
3.1.提示词工程介绍
3.2.提示词工程讲解
3.3.提示词常见模板
4、Python简明教程
4.1.Python基本语法
4.2.Numpy使用
4.3.Pandas使用
4.4.Xarray使用
4.5.Matplotlib使用
专题二、科研辅助专题
1、GPT作为科研工具
1.1把GPT当作搜索引擎
1.2把GPT当作翻译软件

1.3把GPT当作润色工具

1.4用GPT提取整理文章数据
1.5用GPT数据处理
2.GPT作为科研助手生成
2.1用GPT分析结果
2.2用GPT总结生成论文摘要
2.3用GPT总结生成文献综述
2.4用GPT分析论文技术方法
2.5用GPT分析代码

2.6用GPT分析论文公式
2.7用GPT识别图片并分析
2.8 DIY:上传本地PDF资料
用GPT分析相关资料中提出问题。
用GPT总结评价(评阅、审稿意见)
3、GPT作为辅助工具下载数据
3.1使用GPT生成PERSIANN /GSMaP数据的下载代码
3.2使用GPT生成代码下载GSOD数据
3.3使用GPT生成代码下载NCEP/NCAR再分析数据

3.4使用GPT生成代码下载GFS预报数据
专题三、可视化专题——基于GPT实现
1、绘制常见统计图
2、绘制风场图、风羽图、风矢图、流线图
3、通过GPT绘制双Y轴
4、风玫瑰图
5、.填充图
6、绘制添加子图
7、绘制期刊常见图
专题四、站点数据处理
使用GPT处理/生成相应代码,实现下列目标:
1、读取数据
1.1读取多种来源原始数据(ISD、GSDO)
2、缺失值处理
2.1缺失值统计
2.2常见统计方法缺失值填补
2.3机器学习方法填补数据
3、数据质量控制
3.1基于统计阈值的异常检测
3.2基于机器学习的异常检测(Isolation Forest等方法)
3.3多变量数据的异常检测(服务于自动气象站数据)
3.4基于时间序列方法均一化检验(服务于长时间气候变化评估)
4、时间序列的趋势
4.1移动平均法
4.2分解法(STL, Seasonal and Trend decomposition using loess)
4.3Sen’s斜率
5、时间序列的突变检验
5.1 MK (Mann-Kendall): Mann-Kendall趋势检验(用于分析数据集中的趋势变化)
5.2 Pettitt: Pettitt检验(非参数检验方法,用于检测时间序列中的单一变化点)
5.3 BUT (Buishand U Test): Buishand U型统计检验
5.4 SNHT (Standard Normal Homogeneity Test): 标准正态同质性检验(常用于气候数据的同质性检测)
5.5 BG (Buishand Range Test): Buishand范围检验
6、时间序列周期分析
6.1功率谱方法提取周期(提取气温、降水等周期)
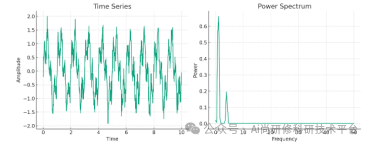
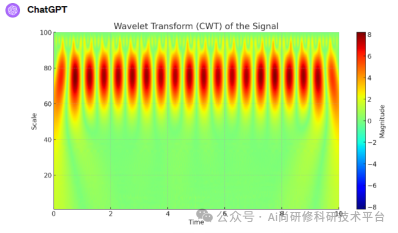
6.2小波分析方法提取周期
6.3 EMD经验模态分解
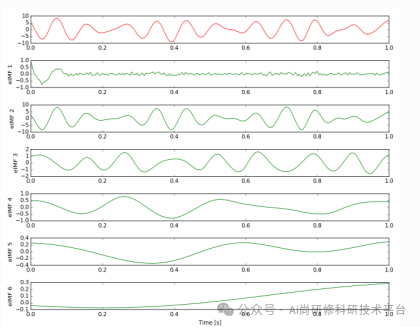
6.4 EEMD集成经验模态分解
7、时间尺度上的统计
7.1不同时间尺度上的统计
8、回归分析
8.1线性回归(Linear Regression):简单线性回归、多元线性回归等
8.2多项式回归(Polynomial Regression):
8.3非参数回归(Non-parametric Regression):
9、相关分析
9.1常见的相关系数(Pearson Correlation Coefficient、Spearman's Rank Correlation Coefficient)
9.2偏相关分析(Partial Correlation)

9.3典型相关分析(Canonical Correlation Analysis, CCA)

10、站点数据的空间化:
10.1克里格插值
10.2临近点插值
10.3反距插值
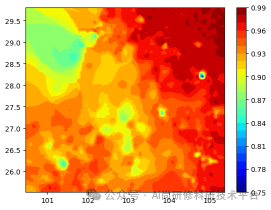
10.4 基于高程模型的外推

专题五、WRF专题——基于GPT和Python实现
1、静态数据的替换
1.1使用Python生成WPS的静态数据
A替换反照率和LAI数据
GPT生成转化GLASS(The Global Land Surface Satellite (GLASS) Product suite)替换默认粗分辨率数据。
B替换土地利用
GPT将多分类的ECI CCI土地利用数据分类进行整合,使之能够用于WPS系统;GPT生成转化代码,将数据转化为WPS可读取的二进制格式。
使用Python更改WRF初始场
GPT生成代码修改WRF初始场文件,并替换土地利用、地表反照率等静态数据。
2、生成WRF配置文件
2.1在指定的地区推荐WRF namelist.input文件相关参数
2.2补全相关参数信息
3、WRF的后处理
3.1站点插值
3.2能见度计算
3.3垂直高度变量插值
3.4降水相态辨识
3.5水汽通量
4、WRF的评估
4.1格点尺度评估
4.2点尺度评估
4.3模态评估
专题六、遥感降水专题——基于GPT和Python实现
1、将PERSSIAN/GSMaP数据转化为netCDF格式
2、合并数据
3、时间域统计并可视化
4、空间域统计并可视化
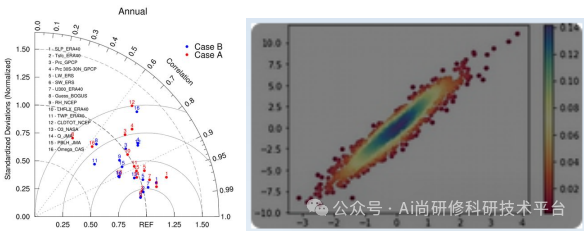
5、常见统计评估指标
生成统计指标空间图
生成泰勒图
生成卫星降雨散点密度图

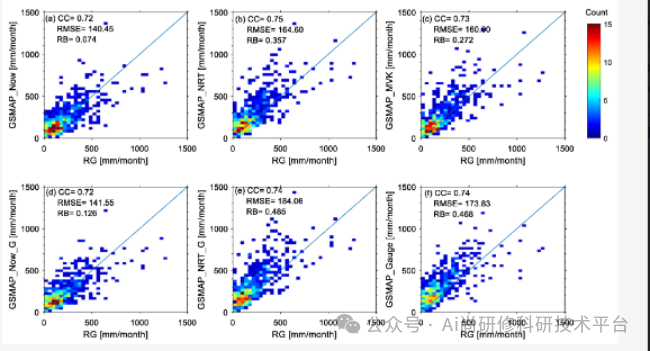
专题七、再分析数据专题——基于GPT和Python实现
1、ERA5再分析数据
1.1 ERA5数据的下载
1.2 ERA5数据预处理
1.3多时间尺度统计
1.4干旱监测
计算标准化降水蒸散指数(SPEI)或标准化降水指数(SPI)作为干旱监测的指标。
根据土壤湿度和降水量数据,使用时间序列分析和阈值判断来评估干旱风险等级。
1.5极端指数计算
连续干旱天数
夏日指数
R99极端降水指数等
1.6趋势分析
滑动平均
累积距平
趋势分析代码
时间序列分析
2、多套再分析数据的气候趋势分析
2.1对比NCEP/NCAR、ERA5、CRU等均值
2.2趋势分析
3、风能资源评估
3.1计算研究区域内多年的平均风速
3.2计算风速的季节性变化和年际变异性
3.3计算空气密度
3.4计算盛行风
3.5计算风功率
3.6计算weibull分布
3.7基于站点和WRF模式的分析
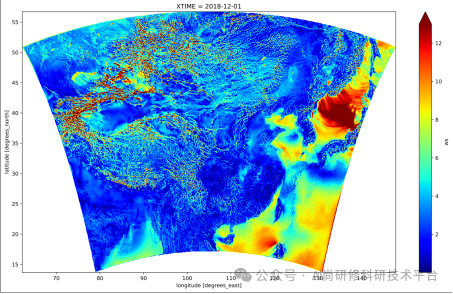
3.8基于ERA5计算风功率
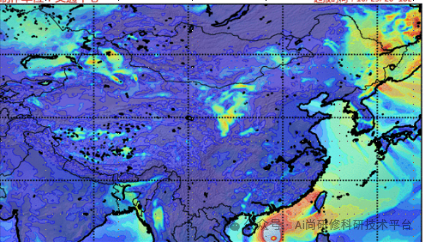
4、太阳能资源评估
4.1计算每天的平均太阳辐射量
4.2分析日、月和季节性气候态时空格局
4.3计算趋势
专题八、CMIP6未来气候专题——基于GPT和Python实现
1、数据预处理:
1.1使用NetCDF工具(xarray)读取数据
1.2裁剪时间范围和空间范围
2、计算区域平均温度:
2.1对于全球平均温度加权平均
2.2对于特定区域,直接计算平均值
3、趋势分析:
3.1使用统计方法(如线性回归)分析温度随时间的变化趋势
4.可视化:
4.1绘制时间序列图显示温度趋势
4.2使用地图可视化工具(basemap)展示空间分布的变化
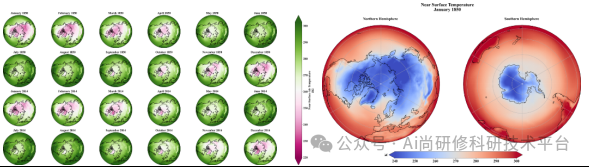
专题九、基于机器学习方法判断天气晴雨——基于GPT和Python实现机器学习操作流程 1、预处理
1.1缺失值处理:使用适当的策略填充或删除数据中的缺失值
1.2数据探索:通过统计摘要、可视化方法(如直方图、箱线图)来理解数据的分布、异常值情况和变量之间的关系
1.3数据标准化/归一化
1.4数据类型转换:将分类变量转换为数值型,使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)
2、数据采样
2.1均衡采样:对不平衡的数据集进行重采样,确保各类别样本数量大致相同
2.2分层抽样:确保训练集和测试集中各类别样本的比例与原数据集相同,使用分层采样技术。
2.3交叉验证分割:采用交叉验证的方法来进行更可靠的模型评估,如K折交叉验证,保证每个样本被用于训练和验证。
2.4时间序列分割:对于时间序列数据,使用时间顺序分割数据,确保训练集中的数据点时间上早于测试集中的数据点。
3、特征工程
3.1特征选择:使用统计测试、模型系数或树模型的特征重要性来选择最有信息量的特征
3.2降维:使用主成分分析(PCA)、线性判别分析(LDA)等方法减少特征的维度
3.3多项式特征:生成特征的多项式组合,如平方项、交互项,以捕捉特征之间的非线性关系
4、模型建模与堆叠
4.1单模型训练:如决策树、SVM、随机森林。
4.2模型堆叠:使用mlxtend库或自定义方法实现模型堆叠,结合不同模型的预测结果作为新的特征,训练一个新的模型。
4.3调参:使用网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)等方法优化模型参数。
4.4集成学习:除了堆叠,还可以探索其他集成方法,如Bagging和Boosting,以提高模型的稳定性和准确性。
5、模型评估
5.1性能指标:根据问题类型(分类或回归)选择合适的评估指标,如准确度、召回率、F1分数、AUC值、均方误差
5.2模型解释性:使用SHAP对模型的预测进行解释,提高模型的可解释性
原文链接 https://mp.weixin.qq.com/s?__biz=MzUyNzczMTI4Mg==&mid=2247684268&idx=1&sn=450ea15b3edbfa40dd85342d3e1f1749&chksm=fa774f91cd00c687ac24f48a98dc56e84f3f12575b815a29b0534233b7ad3c4f45e7b59b5d5f&token=1262054614&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzUyNzczMTI4Mg==&mid=2247684268&idx=1&sn=450ea15b3edbfa40dd85342d3e1f1749&chksm=fa774f91cd00c687ac24f48a98dc56e84f3f12575b815a29b0534233b7ad3c4f45e7b59b5d5f&token=1262054614&lang=zh_CN#rd