最近接到一个任务:用AI审核视频,帮助发现视频中的问题,提高运营审核的生产力。
这应该属于计算机视觉(Computer Vision)的领域。
计算机视觉的主要目标是:复刻人类视觉的强大能力。
计算机视觉要解决的主要问题是:给出一张图片,计算机视觉系统必须识别出图像中的对象及其特征,如形状、纹理、颜色、大小、空间排列等,从而尽可能完整地描述该图像。
计算机视觉,跟图像处理、机器视觉是什么区分的呢?
图像处理
图像处理旨在处理原始图像以应用某种变换。其目标通常是改进图像或将其作为某项特定任务的输入,而计算机视觉的目标是描述和解释图像。例如,降噪、对比度或旋转操作这些典型的图像处理组件可以在像素层面执行,无需对图像整体具备全面的了解。
机器视觉
机器视觉是计算机视觉用于执行某些(生产线)动作的特例。在化工行业中,机器视觉系统可以检查生产线上的容器(是否干净、空置、无损)或检查成品是否恰当封装,从而帮助产品制造。
计算机视觉
计算机视觉可以解决更复杂的问题,如人脸识别、详细的图像分析(可帮助实现视觉搜索,如 Google Images),或者生物识别方法。
计算机视觉的常见任务有:
图像分类,目标检测,实例分割,如下图(分别对应classification、detection、segmentation)

当然,还有其他任务,例如:目标识别,目标追踪,语义分割等。
计算机视觉的一些商用案例,如下:
Google的图片搜索Facebook的人脸识别特斯拉的自动驾驶(Autopilot)微软 InnerEye ,从恶性肿瘤的 3D 图像中准确识别出肿瘤。这是一项伟大的案例,值得一张配图来演示:
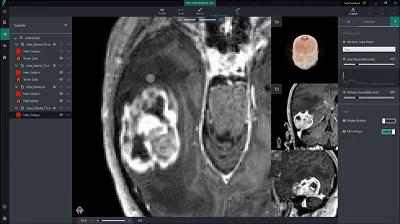
回到视频审核任务,该怎么做呢?
可以把视频逐帧切图,然后做图像分类,目标检测似乎更好,可以直接指出问题所在。
图像分类
常用算法:KNN、SVM、BP 神经网络、CNN 和迁移学习
常用数据集:ImageNet、MNIST、Caltech 101
目标检测
目前常用的目标检测算法有R-CNN(速度慢,过程繁琐,训练所需空间大)、Faster R-CNN(比前者更准确、快速、简便,但还是不够快,不够简洁)和基于YOLO的目标检测的算法(速度快,泛化能力强,但精度低,小目标和邻近目标检测效果差,比Fast R-CNN定位误差大一些)
常用数据集:PASCAL VOL、MS COCO、ImageNet
看来,选择YOLO没错。
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。
物体检测,目标检测,应该都是翻译自object classification,不同译法而已。
YOLOv8是YOLO 的最新版本,由Ultralytics 提供。YOLOv8 YOLOv8 支持全方位的视觉 AI 任务,包括分类、检测、分割、追踪、姿势估计和OBB(定向边框对象检测)。这种多功能性使用户能够在各种应用和领域中利用YOLOv8 的功能。

最后的OBB(定向边框对象检测)是什么?
定向物体检测比物体检测更进一步,它引入了一个额外的角度来更准确地定位图像中的物体。
定向物体检测器的输出结果是一组旋转的边界框,这些边界框精确地包围了图像中的物体,同时还包括每个边界框的类标签和置信度分数。
请看下图就一目了然了。

好了,今天就到这里。
后面我们还有两篇,分别是:
《YOLOv8入门篇--YOLOv8的安装和使用》
《YOLOv8进阶篇--先训练模型,然后检测视频》