在前面的文章中已经详细介绍了在本机上安装YOLOv5的教程,安装YOLOv5可参考前面的文章YOLOv5训练自己的数据集(超详细)https://blog.csdn.net/qq_40716944/article/details/118188085https://blog.csdn.net/qq_40716944/article/details/118188085
目录
一、数据集介绍
二、构建训练数据集
1、先构建数据集文件夹
2、数据集格式转换
3、训练集划分代码
4、生成yolo格式的标签
三、修改配置文件
1、数据配置文件
2、网络参数修改
3、trian.py修改
四、训练及测试
1、训练
2、测试
一、数据集介绍
本教程主要是利用YOLOv5算法实现对输电线路绝缘子缺陷进行检测识别。通过无人机搭载相机头云台对输电线路上的绝缘子进行数据采集,挑选出绝缘子上有故障的图片数据,共2000张左右图片,输电线路绝缘子缺陷数据集中的部分图片如下图所示。

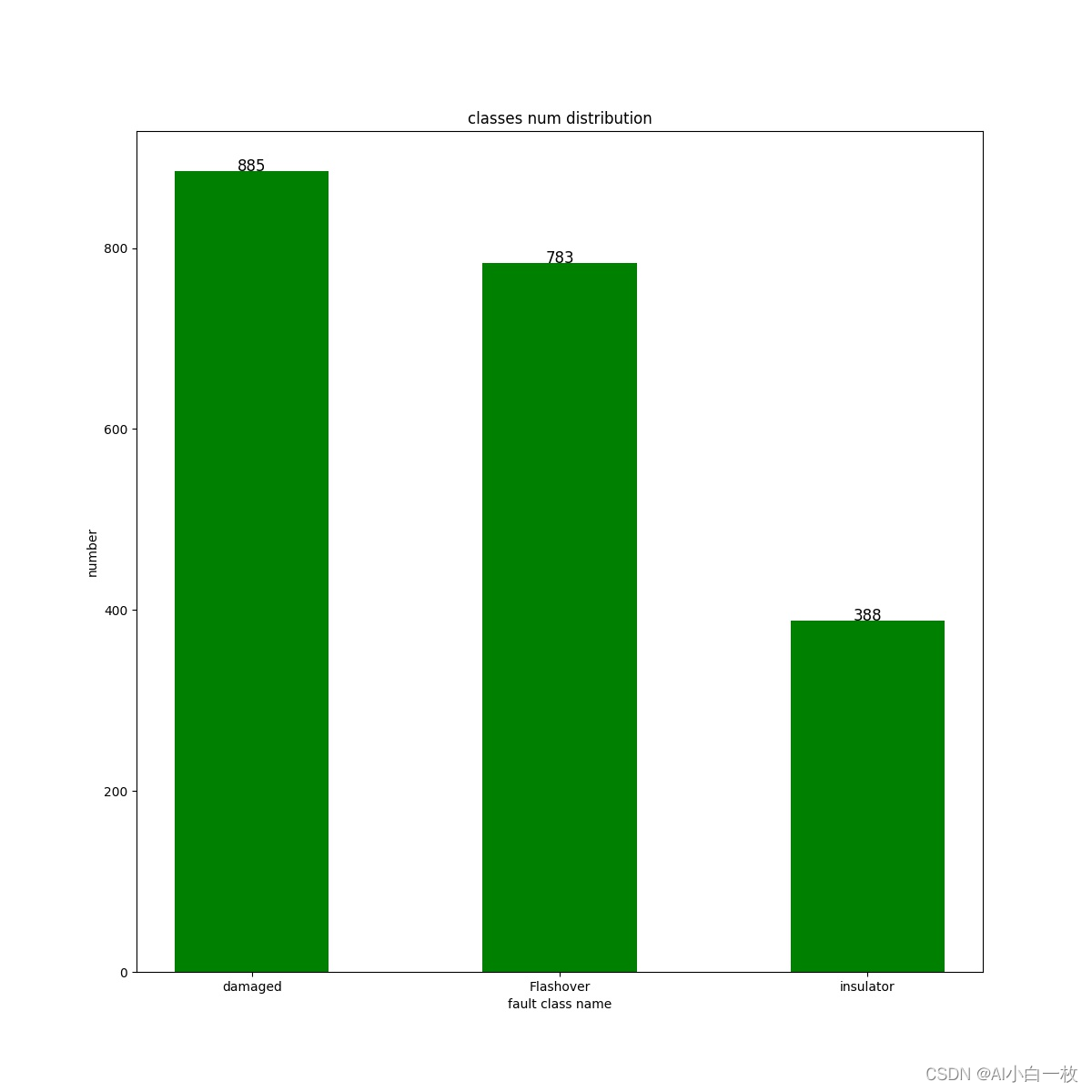
 对收集到的2000张左右绝缘子缺陷数据集进行数据标注, 标注了3种常见的绝缘子缺陷类型:insulator、damaged、Flashover,利用LabelImg标注软件对数据进行标注,对标注后的数据进行统计,3种缺陷的标签分布情况如下图所示。
对收集到的2000张左右绝缘子缺陷数据集进行数据标注, 标注了3种常见的绝缘子缺陷类型:insulator、damaged、Flashover,利用LabelImg标注软件对数据进行标注,对标注后的数据进行统计,3种缺陷的标签分布情况如下图所示。
二、构建训练数据集
1、先构建数据集文件夹
本人按照VOC格式创建数据集,具体格式如下:
├── data│ ├── xml 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应│ ├── images 存放.jpg 格式的图片文件│ ├── labels 存放label标注信息的txt文件,与图片一一对应│ ├── txt 存放原始标注信息,x1,y1,x2,y2,type├── dataSet(train,val,test建议按照8:1:1比例划分)│ ├── train.txt 写着用于训练的图片名称│ ├── val.txt 写着用于验证的图片名称│ ├── trainval.txt train与val的合集│ ├── test.txt 写着用于测试的图片名称2、数据集格式转换
原始的标注信息是保存成txt文件,txt文件里面的每一行都包含一个标注信息,格式为x1,y1,x2,y2,type,这里 (x1,y1) 和 (x2,y2) 是缺陷边界框的左上角和右下角,type是匹配后的整数 ID:0:insulator、1:damaged、2:Flashover。通过一下代码进行转换:
import osimport cv2import timefrom xml.dom import minidomname_dict = {'0': 'insulator', '1': 'damaged', '2': 'Flashover'}def transfer_to_xml(pic, txt, file_name,xml_save_path): if not os.path.exists(xml_save_path): os.makedirs(xml_save_path,exist_ok=True) img = cv2.imread(pic) img_w = img.shape[1] img_h = img.shape[0] img_d = img.shape[2] doc = minidom.Document() annotation = doc.createElement("annotation") doc.appendChild(annotation) folder = doc.createElement('folder') folder.appendChild(doc.createTextNode('visdrone')) annotation.appendChild(folder) filename = doc.createElement('filename') filename.appendChild(doc.createTextNode(file_name)) annotation.appendChild(filename) source = doc.createElement('source') database = doc.createElement('database') database.appendChild(doc.createTextNode("Unknown")) source.appendChild(database) annotation.appendChild(source) size = doc.createElement('size') width = doc.createElement('width') width.appendChild(doc.createTextNode(str(img_w))) size.appendChild(width) height = doc.createElement('height') height.appendChild(doc.createTextNode(str(img_h))) size.appendChild(height) depth = doc.createElement('depth') depth.appendChild(doc.createTextNode(str(img_d))) size.appendChild(depth) annotation.appendChild(size) segmented = doc.createElement('segmented') segmented.appendChild(doc.createTextNode("0")) annotation.appendChild(segmented) with open(txt, 'r') as f: lines = [f.readlines()] for line in lines: for boxes in line: box = boxes.strip('\n') box = box.split(" ") x_min = box[0] y_min = box[1] x_max = box[2] y_max = box[3] object_name = name_dict[box[4]] if object_name != "background": object = doc.createElement('object') nm = doc.createElement('name') nm.appendChild(doc.createTextNode(object_name)) object.appendChild(nm) pose = doc.createElement('pose') pose.appendChild(doc.createTextNode("Unspecified")) object.appendChild(pose) truncated = doc.createElement('truncated') truncated.appendChild(doc.createTextNode("1")) object.appendChild(truncated) difficult = doc.createElement('difficult') difficult.appendChild(doc.createTextNode("0")) object.appendChild(difficult) bndbox = doc.createElement('bndbox') xmin = doc.createElement('xmin') xmin.appendChild(doc.createTextNode(x_min)) bndbox.appendChild(xmin) ymin = doc.createElement('ymin') ymin.appendChild(doc.createTextNode(y_min)) bndbox.appendChild(ymin) xmax = doc.createElement('xmax') xmax.appendChild(doc.createTextNode(str(x_max))) bndbox.appendChild(xmax) ymax = doc.createElement('ymax') ymax.appendChild(doc.createTextNode(str(y_max))) bndbox.appendChild(ymax) object.appendChild(bndbox) annotation.appendChild(object) with open(os.path.join(xml_save_path, file_name + '.xml'), 'w') as x: x.write(doc.toprettyxml()) x.close() f.close()if __name__ == '__main__': t = time.time() print('Transfer .txt to .xml...ing....') txt_folder = 'data/power_transmission_line_datasets/txt' txt_file = os.listdir(txt_folder) img_folder = 'data/power_transmission_line_datasets/image' xml_save_path = 'data/power_transmission_line_datasets/xml/' for txt in txt_file: txt_full_path = os.path.join(txt_folder, txt) img_full_path = os.path.join(img_folder, txt.split('.')[0] + '.jpg') try: transfer_to_xml(img_full_path, txt_full_path, txt.split('.')[0],xml_save_path) except Exception as e: print(e) print("Transfer .txt to .XML sucessed. costed: {:.3f}s...".format(time.time() - t))3、训练集划分代码
主要是将数据集分类成训练数据集和测试数据集,默认train,val,test按照比例进行随机分类,运行后dataSet文件夹中会出现四个文件,主要是生成的训练数据集和测试数据集的图片名称,如下图。同时data目录下也会出现这四个文件,内容是训练数据集和测试数据集的图片路径。
import osimport randomtrainval_percent = 0.9train_percent = 0.9xmlfilepath = 'data/power_transmission_line_datasets/xml/'txtsavepath = 'data/power_transmission_line_datasets/dataSet/'total_xml = os.listdir(xmlfilepath)num = len(total_xml)list = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list, tv)train = random.sample(trainval, tr)ftrainval = open('data/power_transmission_line_datasets/dataSet/trainval.txt', 'w')ftest = open('data/power_transmission_line_datasets/dataSet/test.txt', 'w')ftrain = open('data/power_transmission_line_datasets/dataSet/train.txt', 'w')fval = open('data/power_transmission_line_datasets/dataSet/val.txt', 'w')for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name)ftrainval.close()ftrain.close()fval.close()ftest.close()4、生成yolo格式的标签
主要是将图片数据集标注后的xml文件中的标注信息读取出来并写入txt文件,运行后在label文件夹中出现所有图片数据集的标注信息。
# xml解析包import xml.etree.ElementTree as ETimport pickleimport os# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表from os import listdir, getcwdfrom os.path import joinsets = ['train', 'test', 'val']classes = ["insulator","damaged","Flashover"]# 进行归一化操作def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax) dw = 1./size[0] # 1/w dh = 1./size[1] # 1/h x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标 y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标 w = box[1] - box[0] # 物体实际像素宽度 h = box[3] - box[2] # 物体实际像素高度 x = x*dw # 物体中心点x的坐标比(相当于 x/原图w) w = w*dw # 物体宽度的宽度比(相当于 w/原图w) y = y*dh # 物体中心点y的坐标比(相当于 y/原图h) h = h*dh # 物体宽度的宽度比(相当于 h/原图h) return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]def convert_annotation(image_id): ''' 将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息, 通过对其解析,然后进行归一化最终读到label文件中去,也就是说 一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去 labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bounding的信息也有多个 ''' # 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件 in_file = open('data/power_transmission_line_datasets/xml/%s.xml' % (image_id), encoding='utf-8') # 准备在对应的image_id 中写入对应的label,分别为 # <object-class> <x> <y> <width> <height> out_file = open('data/power_transmission_line_datasets/label/%s.txt' % (image_id), 'w', encoding='utf-8') # 解析xml文件 tree = ET.parse(in_file) # 获得对应的键值对 root = tree.getroot() # 获得图片的尺寸大小 size = root.find('size') # 如果xml内的标记为空,增加判断条件 if size != None: # 获得宽 w = int(size.find('width').text) # 获得高 h = int(size.find('height').text) # 遍历目标obj for obj in root.iter('object'): # 获得difficult difficult = obj.find('difficult').text # 获得类别 =string 类型 cls = obj.find('name').text # 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过 if cls not in classes or int(difficult) == 1: continue # 通过类别名称找到id cls_id = classes.index(cls) # 找到bndbox 对象 xmlbox = obj.find('bndbox') # 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax'] b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) print(image_id, cls, b) # 带入进行归一化操作 # w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax'] bb = convert((w, h), b) # bb 对应的是归一化后的(x,y,w,h) # 生成 calss x y w h 在label文件中 out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')# 返回当前工作目录wd = getcwd()print(wd)for image_set in sets: ''' 对所有的文件数据集进行遍历 做了两个工作: 1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位 2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去 最后再通过直接读取文件,就能找到对应的label 信息 ''' # 先找labels文件夹如果不存在则创建 if not os.path.exists('data/power_transmission_line_datasets/labels/'): os.makedirs('data/power_transmission_line_datasets/labels/') # 读取在ImageSets/Main 中的train、test..等文件的内容 # 包含对应的文件名称 image_ids = open('data/power_transmission_line_datasets/dataSet/%s.txt' % (image_set)).read().strip().split() list_file = open('data/power_transmission_line_datasets/%s.txt' % (image_set), 'w') # 将对应的文件_id以及全路径写进去并换行 for image_id in image_ids: list_file.write('data/power_transmission_line_datasets/image/%s.jpg\n' % (image_id)) # 调用 year = 年份 image_id = 对应的文件名_id convert_annotation(image_id) # 关闭文件 list_file.close()label文件夹中某文件内容如下:
1 0.5128302845528456 0.1638719512195122 0.012957317073170733 0.018292682926829271 0.5325203252032521 0.16482469512195122 0.012195121951219513 0.017911585365853661 0.5572916666666667 0.20579268292682928 0.011941056910569106 0.018292682926829271 0.42238313008130085 0.4026295731707317 0.009908536585365856 0.0133384146341463411 0.41450711382113825 0.7050304878048781 0.009908536585365856 0.016006097560975611 0.005970528455284553 0.405297256097561 0.011432926829268294 0.017149390243902440 0.6451981707317074 0.8746189024390244 0.12372967479674798 0.129573170731707320 0.6006097560975611 0.5482088414634146 0.12804878048780488 0.129192073170731720 0.5552591463414634 0.1953125 0.1323678861788618 0.129954268292682950 0.3654725609756098 0.05811737804878049 0.11864837398373985 0.068978658536585370 0.1899136178861789 0.5483993902439025 0.13185975609756098 0.13643292682926830 0.02870934959349594 0.40415396341463417 0.05691056910569106 0.062118902439024390 0.04128556910569106 0.7789634146341464 0.08155487804878049 0.074695121951219510 0.2170985772357724 0.936547256097561 0.12982723577235775 0.126905487804878060 0.44804369918699194 0.7155106707317074 0.11153455284552846 0.0781250 0.41133130081300817 0.4005335365853659 0.11077235772357724 0.07393292682926829三、修改配置文件
1、数据配置文件
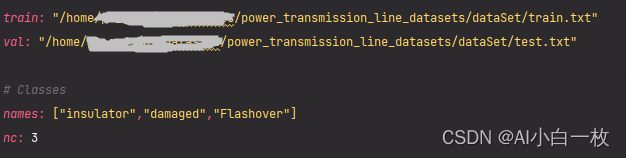
首先需要在/yolov5-6.1/data文件夹中,新建一个power_transmission_line_datasets.yaml文件,内容设置如下:
2、网络参数修改
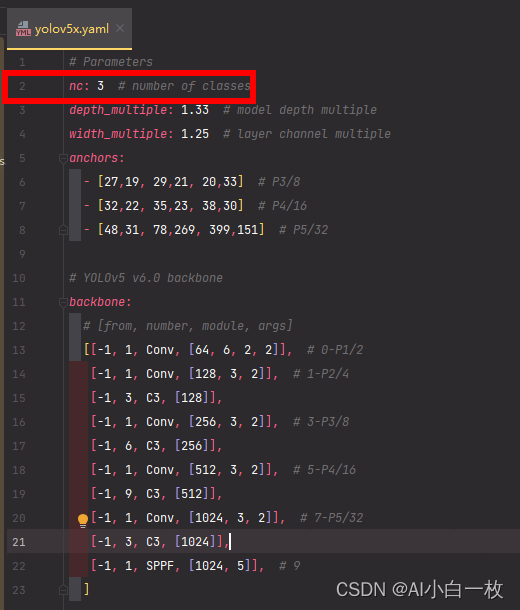
对yolov5-6.1/model文件夹中,对yolov5x.yaml(根据自己选择的模型而定)文件内容修改。
3、trian.py修改
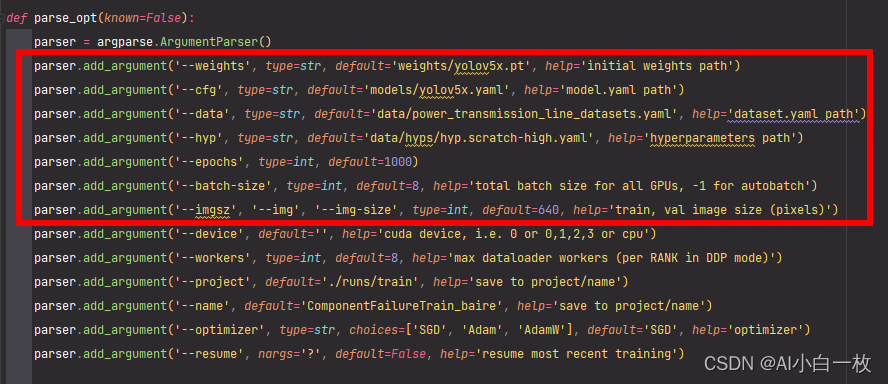
主要用到的几个参数:–weights,–cfg,–data,–epochs,–batch-size,–img-size,–project,-workers
重点注意:–weights,–cfg,–data,其他的默认即可(batch_size,workers根据自己电脑属性进行设置)。
四、训练及测试
1、训练
在完成上述所有的操作之后,就可以进行训练,在命令窗口输入python train.py即可以进行训练。

可以看出,输入数据在送入yolov5训练时是成批次的,且采用了多种数据增强方法,如下图所示。

2、测试
在训练完成后可以利用测试集对训练后的模型进行测试,利用val.py文件进行测试,主要修改一下地方:
测试完成后会输出map、precision、recall等指标,具体如下图所示:

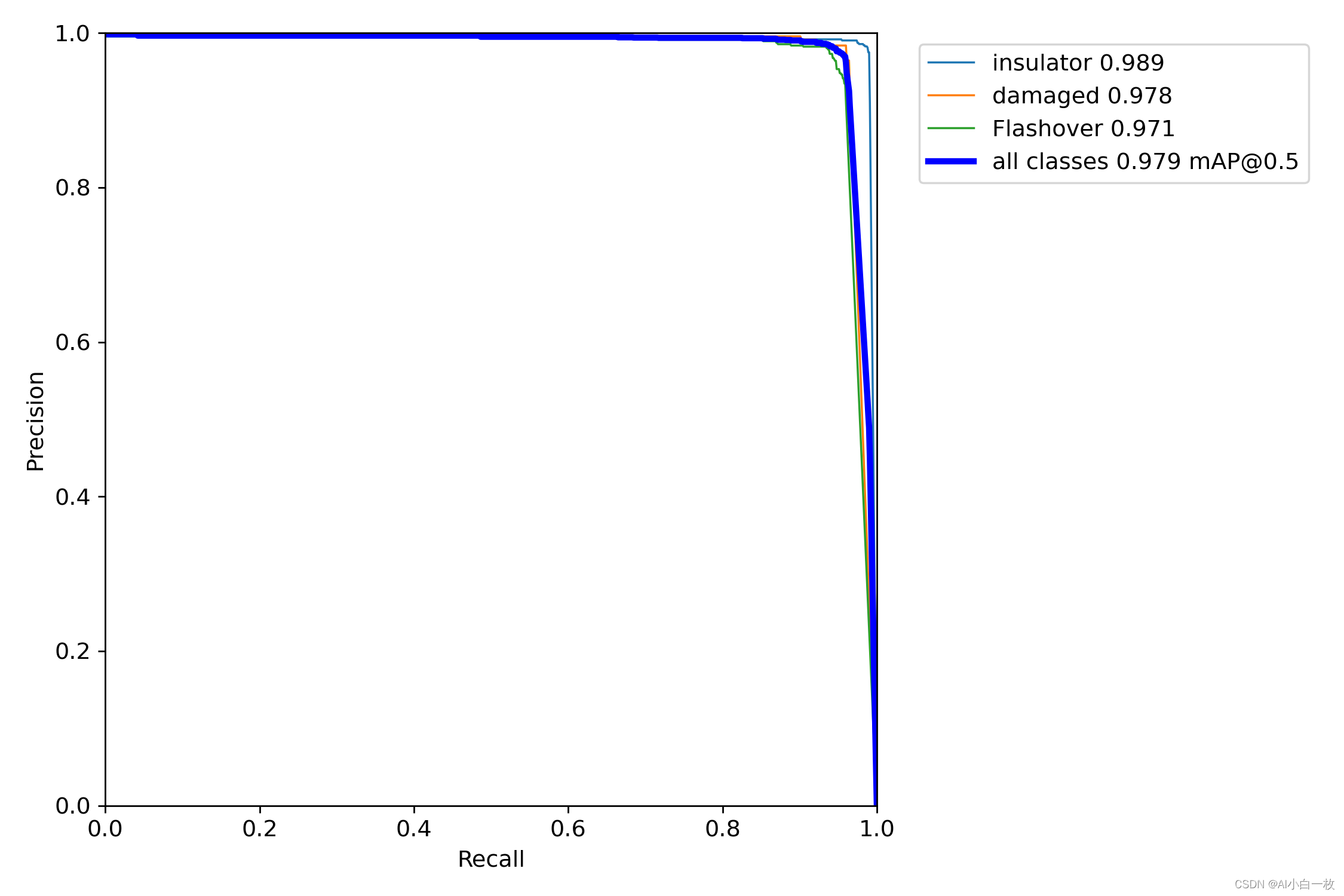
P-R曲线如下图所示:
同时也可以利用detect.py文件对测试集进行测试,将检测后的框绘制在图像上,部分测试结果如下图所示:


