1 LightGBM算法基本原理
GBDT算法的基本思想是把上一轮的训练残差作为下一轮学习器训练的输入,即每一次的输入数据都依赖于上一次训练的输出结果。因此,这种训练迭代过程就需要多次对整个数据集进行遍历,当数据集样本较多或者维数过高时会增加算法运算的时间成本,并且消耗更高的内存资源。
而XGBoost算法作为GBDT的一种改进,在训练时是基于一种预排序的思想来寻找特征中的最佳分割点,这种训练方式同样也会导致内存空间消耗极大,例如算法不仅需要保存数据的特征值,还需要保存特征排序的结果;在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大,特别是当数据量级较大时,这种方式会消耗过多时间。
为了对这些问题进行优化,2017年微软公司提出了LightGBM算法(Light Gradient Boosting Machine),该算法也是基于GBDT算法的改进,,但相较于GBDT、XGBoost算法,LightGBM算法有效地解决了处理海量数据的问题,在实际应用中取得出色的效果。LightGBM算法主要包括以下几个特点:直方图算法(寻找最佳分裂点、直方图差加速)、Leaf-wise树生长策略、GOSS、EFB、支持类别型特征、高效并行以及Cache命中率优化等。
(1)直方图Histogram算法(减少大量计算与内存占用)
XGBoost算法在进行分裂时需要预先对每一个特征的原始数据进行预排序,而直方图Histogram算法则是对特征的原始数据进行“分桶#bin”,把数据划分到不同的离散区域中,再对离散数据进行遍历,寻找最优划分点。这里针对特征值划分的每一个“桶”有两层含义,一个是每个“桶”中样本的数量;另一个是每个“桶”中样本的梯度和(一阶梯度和的平方的均值等价于均方损失)。
可以看出,通过直方图算法可以让模型的复杂度变得更低,并且特征“分桶”后仅保存了的离散值,大大降低内存的占用率。其次,这种“分桶”的方式从某种角度来看相当于对模型增加了正则化,可以避免模型出现过拟合。
直方图算法形成直方图的过程如下图所示: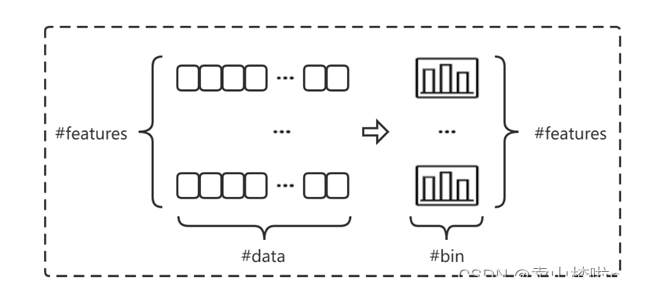
值得注意的是,直方图算法是使用了bin代替原始数据,相当于增加了正则化,这也意味着有更多的细节特征会被丢弃,相似的数据可能被划分到相同的桶中,所以bin的数量选择决定了正则化的程度,bin越少惩罚越严重,过拟合的风险就越低。
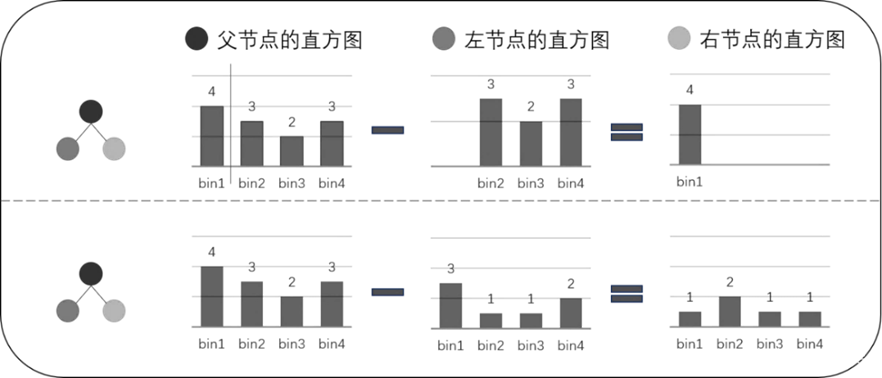
另外,在LightGBM直方图算法中还包括一种直方图作差优化,即LightGBM在得到一个叶子的直方图后,能够通过直方图作差的方式用极小的代价得到其兄弟叶子的直方图,如上图所示,当得到某个叶子的直方图和父节点直方图后,另一个兄弟叶子直方图也能够很快得到,利用这种方式,LightGBM算法速度得到进一步提升。
(2)带深度限制的Leaf-wise的叶子生长策略(减少大量计算、避免过拟合)
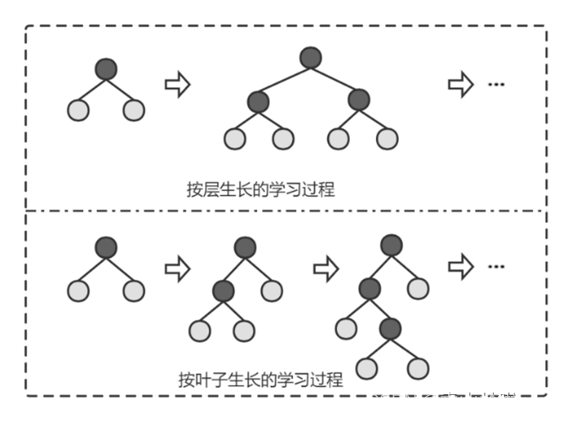
GBDT与XGBoost模型在叶子生长策略上均采用按层level-wise分裂的方式,这种方式在分裂时会针对同一层的每一个节点,即每次迭代都要遍历整个数据集中的全部数据,这种方式虽然可以使每一层的叶子节点并行完成,并控制模型的复杂度,但也会产生许多不必要搜索或分裂,从而消耗更多的运行内存,增加计算成本。
而LightGBM算法对其进行了改进,使用了按叶子节点leaf-wise分裂的生长方式,即每次是对所有叶子中分裂增益最大的叶子节点进行分裂,其他叶子节点则不会分裂。这种分裂方式比按层分裂会带来更小的误差,并且加快算法的学习速度,但由于没有对其他叶子进行分裂,会使得分裂结果不够细化,并且在每层中只对一个叶子不断进行分裂将增大树的深度,造成模型过拟合[25]。因此,LightGBM算法在按叶子节点生长过程中会限制树的深度来避免过拟合。
(3)单边梯度采样技术 (减少样本角度)
在梯度提升算法中,每个样本都有不同梯度值,样本的梯度可以反映对模型的贡献程度,通常样本的梯度越大贡献给模型的信息增益越多,而样本的梯度越小,在模型中表现的会越好。
举个例子来说,这里的大梯度样本可以理解为“练习本中的综合性难题”,小梯度样本可以理解为“练习本中的简单题”,对于“简单题”平时做的再多再好,而“难题”却做的很少,在真正的“考试”时还是会表现不好。但并不意味着小梯度样本(“简单题”)就可以直接剔除不用参与训练,因为若直接剔除小梯度样本,数据的分布会发生改变,从而影响模型的预测效果。
因此,LightGBM算法引入了单边梯度采样技术(Gradient-based One-Side Sampling,GOSS),其基本思想就是从减少样本的角度出发,利用样本的梯度大小信息作为样本重要性的考量,保留所有梯度大的样本点(“保留所有难题”),对于梯度小的样本点(“简单题”)按比例进行随机采样,这样既学习了小梯度样本的信息,也学习了大梯度样本的信息(“平时难题都做,简单题做一部分,在面临真正的考试时才可能稳定发挥,甚至超水平发挥”),在不改变原始数据分布的同时,减小了样本数量,提升了模型的训练速度。
(4)互斥特征捆绑(减少特征角度)
高维度的数据通常是非常稀疏的,并且特征之间存在互斥性(例如通过one-hot编码后生成的几个特征不会同时为0),这种数据对模型的效果和运行速度都有一定的影响。
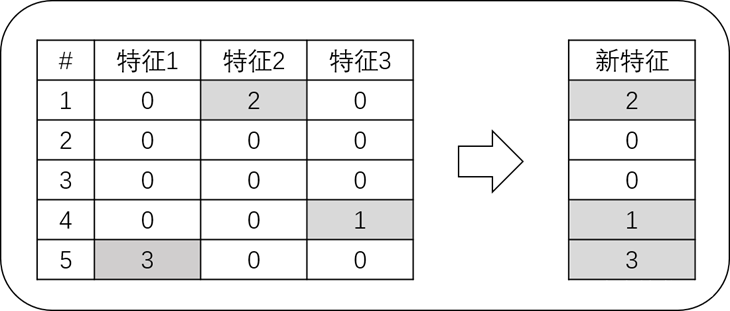
通过互斥特征捆绑算法(Exclusive Feature Bundling,EFB)可以解决高维度数据稀疏性问题,如下图中,设特征1、特征2以及特征3互为互斥的稀疏特征,通过EFB算法,将三个特征捆绑为一个稠密的新特征,然后用这一个新特征替代原来的三个特征,从而实现不损失信息的情况下减少特征维度,避免不必要0值的计算,提升梯度增强算法的速度。
总的来说,LightGBM是一个性能高度优化的GBDT 算法,也可以看成是针对XGBoost的优化算法,可以将LightGBM的优化用公式表达,如下式:LightGBM = XGBoost + Histogram + GOSS + EFB
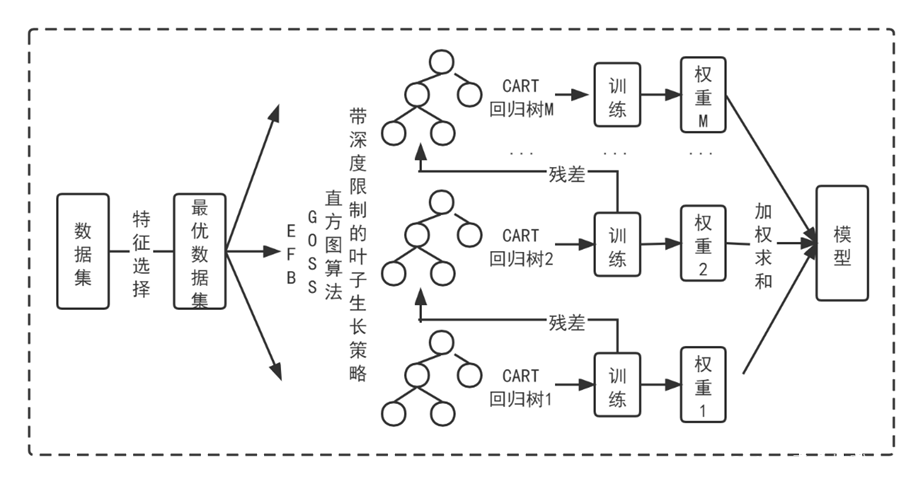
2 LightGBM算法参数
LightGBM算法的参数比较复杂,可以大体上分为核心参数、学习控制参数、IO参数、目标参数、度量参数等,一般需要进行调节的是核心参数、学习控制参数和度量参数,下表给出了一些常用的重要参数的默认值和释义:
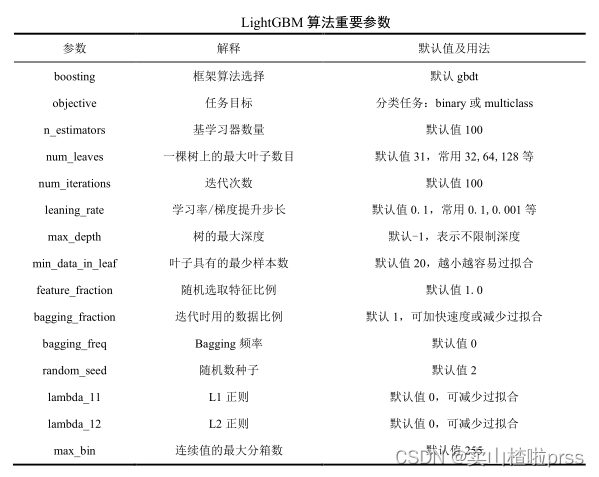
对于LightGBM算法来说,不同的参数对模型的影响不同,参数的选择要注意避免模型过拟合或欠拟合。
参考文献:
基于E-LightGBM算法的5G套餐潜在客户识别研究[D],2022