前言:
随着自动驾驶技术的不断发展,汽车目标检测成为了研究的热点。本文将介绍公开+自定义的yolov5汽车目标检测数据集以及用linux操作系统训练yolov5。
先展示一下推理结果:

GPU在13.2ms每帧,基本满足项目需要。
一、数据集简介
前段时间跟朋友一起整理了一个汽车目标的数据集,主要包括UA-DETRAC车辆检测数据集和自定义数据集。
1.UA-DETRAC车辆检测数据集
UA-DETRAC车辆检测数据集是一个具有挑战性的真实世界多目标检测和多目标跟踪基准。该数据集是由北京智能车联科技有限公司(简称“智车科技”)开发并维护的,旨在为自动驾驶和智能交通领域的研究人员提供一个真实、丰富且具有挑战性的测试平台。
该数据集包括在中国北京和天津的24个不同地点使用Cannon EOS 550D相机拍摄的10小时视频。这些视频主要拍摄于道路过街天桥(京津冀场景),覆盖了各种复杂的道路条件和交通场景。为了确保数据集的真实性和多样性,研究人员需要手动标注8250个车辆和121万目标对象外框。这一过程需要对每个目标进行详细的分类和边界框标注,以确保模型能够在各种实际场景中表现出良好的性能。
UA-DETRAC数据集包含了大量的车辆和行人目标,涵盖了多种类型和大小的目标。这使得研究人员能够在训练和评估自动驾驶算法时,更好地理解和处理现实世界中的复杂交通场景。此外,该数据集还提供了一些辅助数据,如语义分割图、车道线标注等,以帮助研究人员更全面地理解场景信息,从而提高模型的性能。
官方网站:https://detrac-db.rit.albany.edu/

2.自定义数据集
采集道路视频,并对视频进行抽帧,得到:

再使用labelimg标注工具对目标进行标注,得到标签的txt格式文件。
二.模型训练
由于作者使用的是linux服务器字符操作界面对yolov5进行训练,这方面的资料比较少,作者将详细介绍。
1.准备工作
(1).yolov5代码库
yolov5的代码库:https://github.com/ultralytics/yolov5/tree/v5.0
首先打开上述官网,点击右上角"Code"(或克隆),点击"ZIP"下载压缩包。
(2).安装anaconda
可观看此视频(来自b站): https://b23.tv/YPCL0Ks
输入`conda`后,返回结果如下,说明安装成功
(3).配置各种环境
首先创建运行yolov5的虚拟环境,conda命令为:
conda create -n <你自己定义一个名字>
进入环境:
conda activate <你自己定义的环境的名字>
其次,配置yolov5的依赖环境,使用pip安装即可,安装命令如下:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #由于默认下载源过慢,因此我们使用清华源(也可以用其他源)
只需要在创建的虚拟环境中执行上述命令,我们的依赖环境便安装完成。下面进行开发环境的安装。由于GPU训练过慢,因此我们安装CUDA和cuDNN,调用GPU进行训练。另外,我们还需要安装Pytorch,因为yolov5的实现依赖于Pytorch提供的深度学习计算能力与优化工具,同时yolov5也提供了Pytorch接口方便用户使用。这里我们选择用conda安装,一条命令即可。操作如下:
首先在操作界面输入:
nvidia-smi
可以看到驱动版本,最高支持的CUDA版本是12.2版本,得到显卡的最高支持CUDA版本,我们就可以开始依据这个信息安装环境了。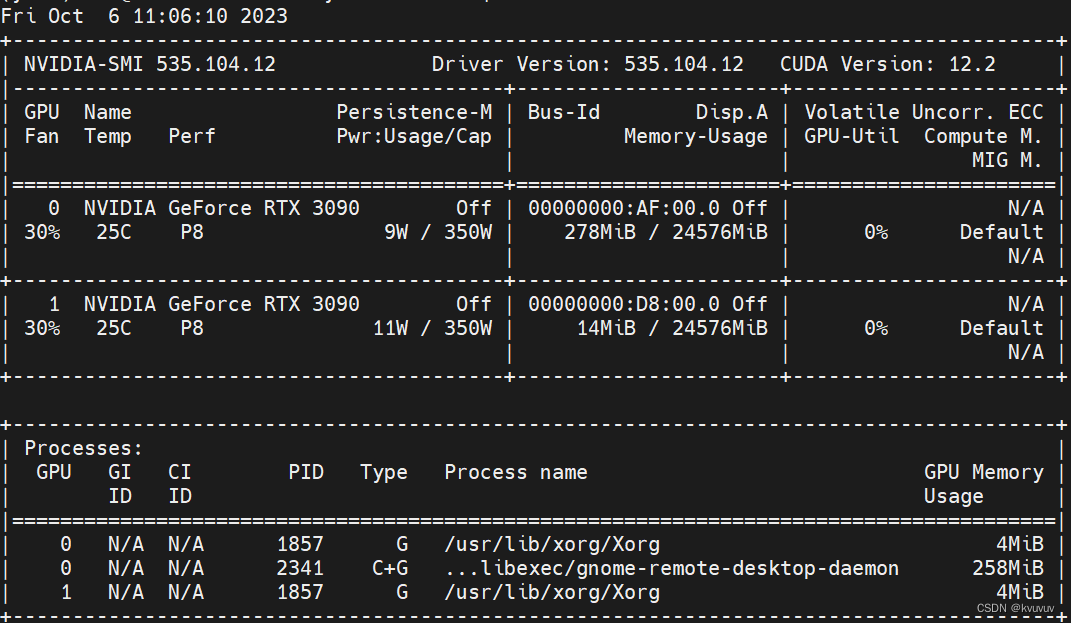
然后,进入Pytorch官网:https://pytorch.org/
找到你要安装的版本、所用系统以及要使用操作工具(操作工具我们选择conda)
我的下载命令是:
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
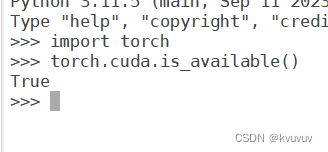
静等安装完成后,我们要验证能否使用:
在操作界面输入"Python"启动Python解释器并进入交互式模式,紧接着输入"import torch"回车,再输入"torch.cuda.is_available()"回车,返回"True",则说明安装成功并可以使用。
如果安装错了可以用这个命令进行卸载:
pip uninstall torch torchvision torchaudio
(4).准备数据集
作者的数据集(含图片和txt标签)链接:
链接:https://pan.baidu.com/s/1eCnfjV993Kn2ys-QRNoGtw
提取码:8cm1
一共近700张图片,约8000个目标:UA-DETRAC车辆检测数据集+自定义数据集。

当然,如果您有自己的数据集也可以用,但是要注意源代码只支持txt格式的标签文件,因此需要将VOC数据或其他格式,因此需要转一下格式,以便正常训练。下面是txt标签文件的格式。

(5).准备配置数据文件(.yaml)
以下是作者的配置文件:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# 数据路径
path: "/data3/wth/yolov5-master/data/" # dataset root dir
# 注意数据路径分隔符使用【/】,不是【\】
# 项目不要出现含有中文字符的目录文件或路径
train:"images/train"
val: "images/val"
#也可以将图片路径汇总到一个txt文件中,将train或val的路径修改为"images/train.txt"即可(例子)
test: # test images (optional)
# 设置类别个数,和要训练的类别名称,ID号从0开始递增
nc: 1# number of classes
names: { 'car': 0 }
#1.作者仅设置一个标签目标,若多个目标可仿照如下设置:
#nc: 4 # number of classes
#names: { 'car': 0, 'bus': 1, 'van': 2,'others': 3 }
# 2.若合并几个类别进行训练,比如将'[car','bus','van']看作一类,others看作另一类,则
#nc: 2 # number of classes
#names: { 'car': 0, 'bus': 0, 'van': 0,'others': 1 }
# 3.若合并所有类别为一个大类,进行训练: unique表示合并所有类为单独一个类别
#nc: 1 # number of classes
#names: { "unique": 0 }
将yaml放到yolov5的源代码库中。
2.开始训练
进入环境:
conda activate yolo#我的环境的名字
进入yolov5-master的目录:
cd yolov5-master
训练命令:
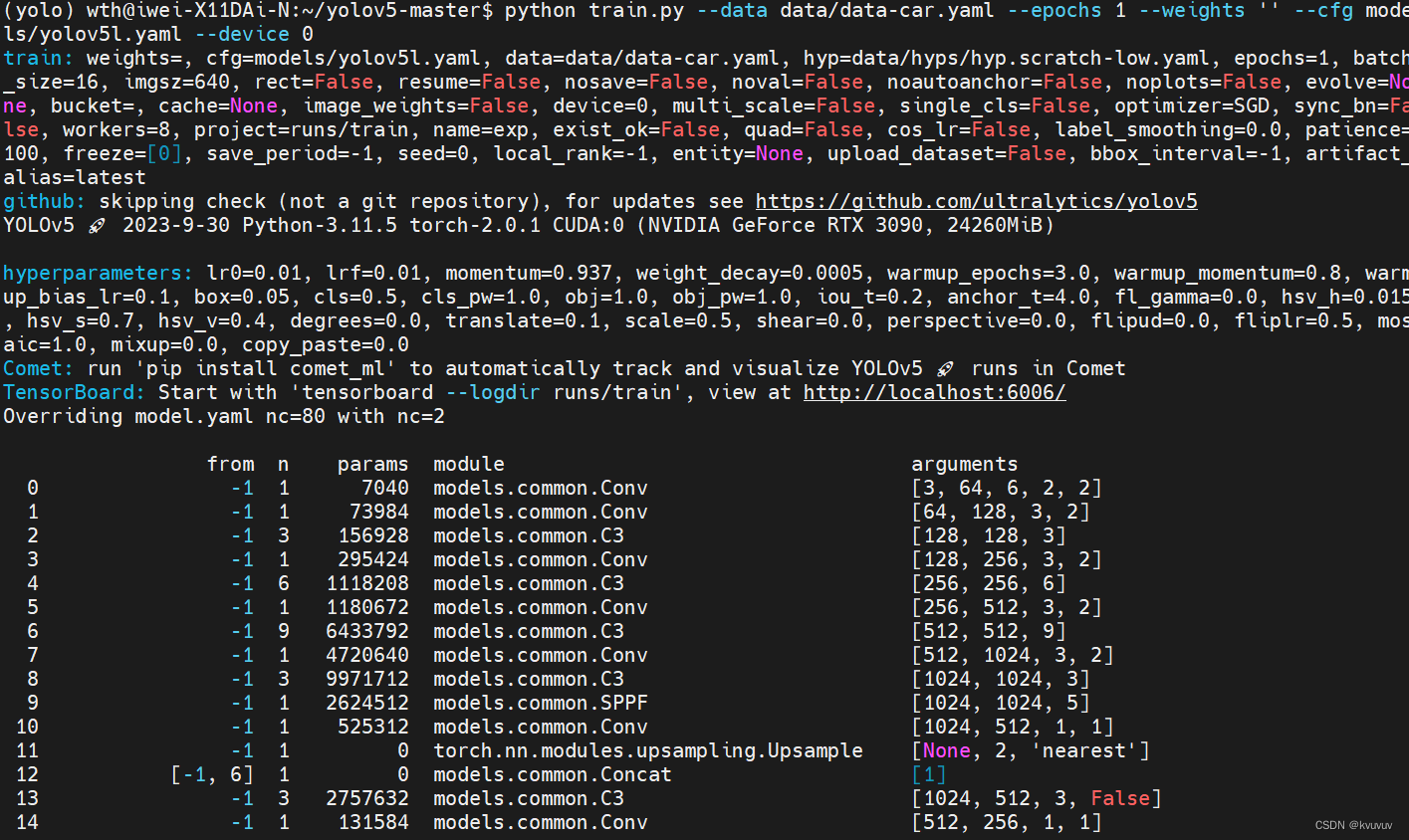
python train.py --img 640 --batch 160--epochs 300 --data data/car.yaml --cfg models/yolov5l.yaml --weights '' --device 0
下面是上述训练命令各个参数的含义:
- `--img`: 输入图像的大小,这里设置为640。
- `--batch`: 每个批次的样本数量,这里设置为16。
- `--epochs`: 训练的总轮数(iterations),这里设置为300。
- `--data`: 数据集配置文件的路径,这里使用上述提及的数据集,对应的配置文件为`car.yaml`。
- `--cfg`: 模型配置文件的路径,这里使用yolov5l模型的配置文件,对应的文件路径为`models/yolov5l.yaml`。
- `--weights`: 预训练权重文件的路径,这里不使用预权重文件。
-`--device`:使用的显卡的编号,这里使用的是编号为0的显卡。
这些参数都是用来配置训练过程的,可以根据实际需求进行调整。
命令执行后可以看到以下画面
❗若中途不小心退出,可以在上述训练命令的基础上在末尾加上`--resume`参数并将`--weights ''`更替为`--weights runs/train/exp/weights/last.pt`。
训练结束后我们可以看到权重文件保存的位置在本文件夹的runs/train/exp14/weights路径下。

在此文件夹中还包括模型训练后的各种信息:
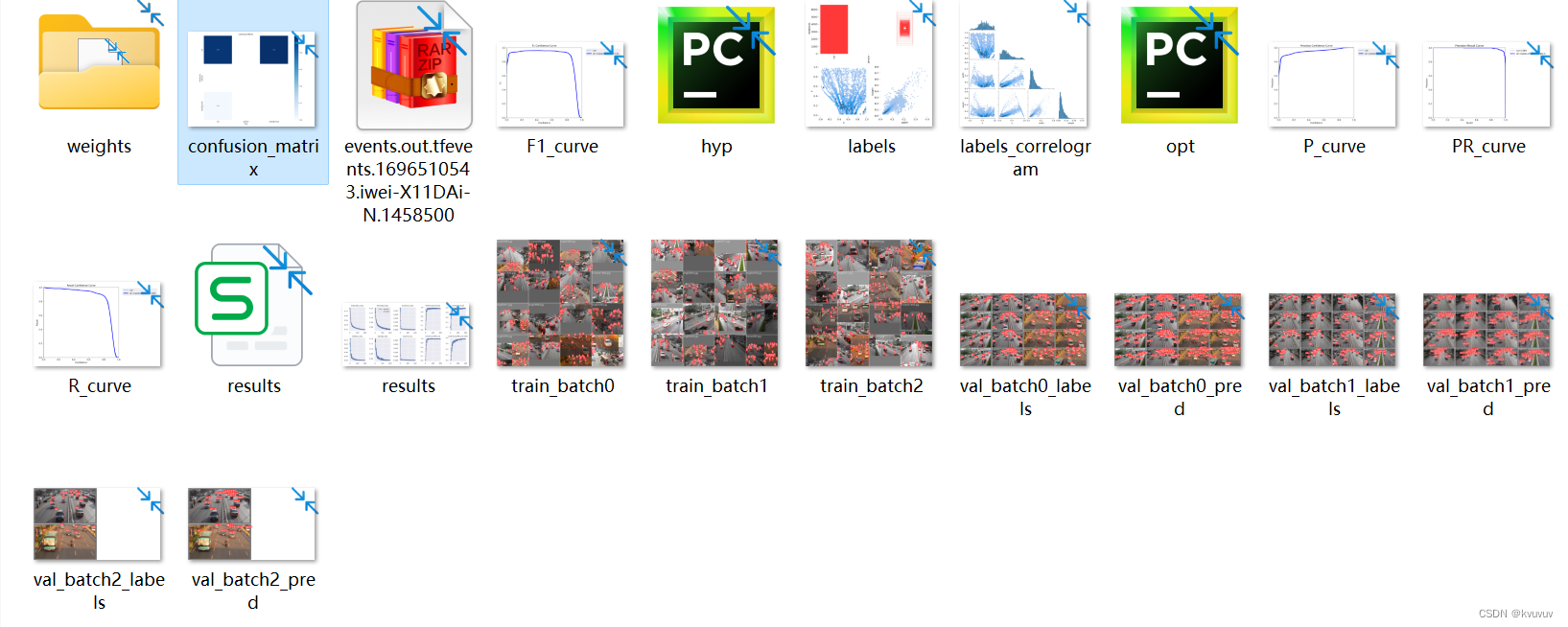
1.F1-curve显示了模型在不同阈值下的精确率和召回率之间的关系。 在F1-curve中,横轴表示召回率,纵轴表示精确率。当精确率和召回率都很高时,F1-score也会很高。
2.P-curve显示了模型在不同阈值下的精确率和召回率之间的关系。 在P-curve中,横轴表示召回率,纵轴表示精确率。当精确率和召回率都很高时,P-score也会很高。
3.PR-curve显示了模型在不同阈值下的精确率和召回率之间的关系。 在PR-curve中,横轴表示召回率,纵轴表示精确率。当精确率和召回率都很高时,P-score也会很高。
4.R-curve显示了模型在不同阈值下的召回率和精确率之间的关系。 TPR曲线显示了模型在不同阈值下的真正例率和假正例率之间的关系。
3.进行推理

我们用最好的best.pt权重文件进行推理,推理命令如下:
python detect.py --source data/detect.mp4 --weights runs/train/exp7/weights/best.pt
我们可以看到结果:

作者训练得到的模型以及各种模型信息压缩包:
链接:https://pan.baidu.com/s/1wjnOCCxX0-SqwvAZQYqrxw?pwd=2654
提取码:2654
好了,基本上就完成了,如果想继续提高识别的精确度还需要使用到yolov5的实现原理以及相关参数的设定技巧。
最后觉得有帮助的,请给我个一键三连,栓Q!
参考博文:
作者:AI吃大瓜.深度学习目标检测