前言
SCINet模型,精度仅次于NLinear的时间序列模型,在ETTh2数据集上单变量预测结果甚至比NLinear模型还要好。在这里还是建议大家去读一读论文,论文写的很规范,很值得学习,论文地址SCINet模型Github项目地址,下载项目文件,需要注意的是该项目仅支持在GPU上运行,如果没有GPU会报错。关于该模型的理论部分,本来准备自己写的,但是看到已经有很多很优秀的帖子了,这里给大家推荐几篇: SCINet学习记录SCONet论文阅读笔记 SCINet学习记录中有一副思维导图画的很好,这里搬运过来方便大家在阅读代码时对照模型架构。 由于理论部分已经有了,这里我仅对项目中各代码以及框架做注释说明,方便大家理解代码,后面如果有需要,可以再写一篇,对于自定义数据如何使用
由于理论部分已经有了,这里我仅对项目中各代码以及框架做注释说明,方便大家理解代码,后面如果有需要,可以再写一篇,对于自定义数据如何使用SCINet模型。 参数设定模块(run_ETTh)
因为作者在做对比实验时用了很多公共数据集,所以文件夹中有run_ETTh.py、run_financial.py、run_pems.py3个文件,分别对应3大主要公共数据集,这里选用ETTh数据集作为示范。所以首先打开run_ETTh.py文件ETTh数据集需要自行下载,如果是在Linux系统中可以直接运行项目文件下prepare_data.sh文件,下载全部数据集。如果是win系统,则需要自己下载.csv文件,并在项目文件夹下创建datasets文件夹,并将数据放入该文件夹。我下载了ETTh1.csv文件,后面的示范均在该数据集上进行 参数含义
下面是各参数含义(注释)
# 模型名称parser.add_argument('--model', type=str, required=False, default='SCINet', help='model of the experiment')### ------- dataset settings --------------# 数据名称parser.add_argument('--data', type=str, required=False, default='ETTh1', choices=['ETTh1', 'ETTh2', 'ETTm1'], help='name of dataset')# 数据路径parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')# 数据文件parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='location of the data file')# 预测方式(S:单变量预测,M:多变量预测)parser.add_argument('--features', type=str, default='M', choices=['S', 'M'], help='features S is univariate, M is multivariate')# 需要预测列的列名parser.add_argument('--target', type=str, default='OT', help='target feature')# 时间采样格式parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')# 模型存储路径parser.add_argument('--checkpoints', type=str, default='exp/ETT_checkpoints/', help='location of model checkpoints')# 是否翻转序列parser.add_argument('--inverse', type=bool, default =False, help='denorm the output data')# 时间特征编码方式parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')### ------- device settings --------------# 是否使用GPU(实测这个参数并没什么作用,即使填写False也无法使用CPU训练模型)parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')# 使用GPU设备IDparser.add_argument('--gpu', type=int, default=0, help='gpu')# 是否多GPU并行parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)# 选用GPU设备IDparser.add_argument('--devices', type=str, default='0',help='device ids of multile gpus') ### ------- input/output length settings --------------# 回视窗口大小parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of SCINet encoder, look back window')# 先验窗口大小parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')# 需要预测序列长度parser.add_argument('--pred_len', type=int, default=48, help='prediction sequence length, horizon')# 丢弃数据长度parser.add_argument('--concat_len', type=int, default=0)parser.add_argument('--single_step', type=int, default=0)parser.add_argument('--single_step_output_One', type=int, default=0)# 最后一层损失权重parser.add_argument('--lastWeight', type=float, default=1.0) ### ------- training settings --------------# 多文件并列parser.add_argument('--cols', type=str, nargs='+', help='file list')# 多线程训练(win系统下该参数置0)parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')# 实验次数parser.add_argument('--itr', type=int, default=0, help='experiments times')# 训练迭代次数parser.add_argument('--train_epochs', type=int, default=100, help='train epochs')# mini_batch_sizeparser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')# 早停策略检测轮数parser.add_argument('--patience', type=int, default=5, help='early stopping patience')# 学习率parser.add_argument('--lr', type=float, default=0.0001, help='optimizer learning rate')# 损失函数parser.add_argument('--loss', type=str, default='mae',help='loss function')# 学习率更新策略parser.add_argument('--lradj', type=int, default=1,help='adjust learning rate')# 是否使用半精度加快训练速度parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)# 是否保存结果(如果你想要保存预测结果,请将该参数改为True)parser.add_argument('--save', type=bool, default =False, help='save the output results')# 模型名称parser.add_argument('--model_name', type=str, default='SCINet')# 是否断续训练parser.add_argument('--resume', type=bool, default=False)# 是否评估模型parser.add_argument('--evaluate', type=bool, default=False)### ------- model settings --------------# 隐藏通道数parser.add_argument('--hidden-size', default=1, type=float, help='hidden channel of module')# 使用交互学习或基本学习策略parser.add_argument('--INN', default=1, type=int, help='use INN or basic strategy')# kernel sizeparser.add_argument('--kernel', default=5, type=int, help='kernel size, 3, 5, 7')# 是否扩张parser.add_argument('--dilation', default=1, type=int, help='dilation')# 回视窗口parser.add_argument('--window_size', default=12, type=int, help='input size')# dropout率parser.add_argument('--dropout', type=float, default=0.5, help='dropout')# 位置编码parser.add_argument('--positionalEcoding', type=bool, default=False)parser.add_argument('--groups', type=int, default=1)# SCINet blockparser.add_argument('--levels', type=int, default=3)# SCINet blocks层数parser.add_argument('--stacks', type=int, default=1, help='1 stack or 2 stacks')# 解码器层数parser.add_argument('--num_decoder_layer', type=int, default=1)parser.add_argument('--RIN', type=bool, default=False)parser.add_argument('--decompose', type=bool,default=False)数据文件参数
data_parser = {# data:数据文件名,T:预测列列名,M(多变量预测),S(单变量预测),MS(多特征预测单变量) 'ETTh1': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]}, 'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]}, 'ETTm1': {'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]}, 'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]}, 'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]}, 'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]}, 'Solar': {'data': 'solar_AL.csv', 'T': 'POWER_136', 'M': [137, 137, 137], 'S': [1, 1, 1], 'MS': [137, 137, 1]},}数据处理模块(etth_data_loader)
从run_ETTh.py文件中exp.train(setting),train方法进入exp_ETTh.py文件,在_get_data中找到ETTh1数据处理方法 data_dict = {'ETTh1':Dataset_ETT_hour, 'ETTh2':Dataset_ETT_hour, 'ETTm1':Dataset_ETT_minute, 'ETTm2':Dataset_ETT_minute, 'WTH':Dataset_Custom, 'ECL':Dataset_Custom, 'Solar':Dataset_Custom,}ETTh1数据处理方法为Dataset_ETT_hour,我们进入etth_data_loader.py文件,找到Dataset_ETT_hour类__init__主要用于传各类参数,这里不过多赘述,主要对__read_data__和__getitem__进行说明 def __read_data__(self): # 实例化归一化 self.scaler = StandardScaler() # 读取CSV文件 df_raw = pd.read_csv(os.path.join(self.root_path, self.data_path)) # [0,训练序列长度-回视窗口,全部序列长度-测试序列长度-回视窗口] border1s = [0, 12*30*24 - self.seq_len, 12*30*24+4*30*24 - self.seq_len] # [训练序列长度,全部序列长度-测试序列长度,全部序列长度] border2s = [12*30*24, 12*30*24+4*30*24, 12*30*24+8*30*24] # train:[0,训练数据长度] # val:[训练序列长度-回视窗口,全部序列长度-测试序列长度] # test:[全部序列长度-测试序列长度-回视窗口,全部序列长度] border1 = border1s[self.set_type] border2 = border2s[self.set_type] # 若采用多变量预测(M或MS) if self.features=='M' or self.features=='MS': # 取出特征列列名 cols_data = df_raw.columns[1:] # 取出特征列 df_data = df_raw[cols_data] # 若采用单变量预测 elif self.features=='S': # 取出预测列 df_data = df_raw[[self.target]] # 若需要进行归一化 if self.scale: # 取出[0,训练序列长度]区间数据 train_data = df_data[border1s[0]:border2s[0]] # 归一化 self.scaler.fit(train_data.values) data = self.scaler.transform(df_data.values) # data = self.scaler.fit_transform(df_data.values) # 否则将预测列变为数组 else: data = df_data.values # 取对应区间时间列 df_stamp = df_raw[['date']][border1:border2] # 将时间转换为标准格式 df_stamp['date'] = pd.to_datetime(df_stamp.date) # 构建时间特征 data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq) # 取对应数据区间(train、val、test) self.data_x = data[border1:border2] # 如果需要翻转时间序列 if self.inverse: self.data_y = df_data.values[border1:border2] # 否则取数据区间(train、val、test) else: self.data_y = data[border1:border2] self.data_stamp = data_stamptime_features函数,用来提取日期特征,比如't':['month','day','weekday','hour','minute'],表示提月,天,周,小时,分钟。可以打开timefeatures.py文件进行查阅同样的,对__getitem__进行说明 def __getitem__(self, index): # 起点 s_begin = index # 终点(起点 + 回视窗口) s_end = s_begin + self.seq_len # (终点 - 先验序列窗口) r_begin = s_end - self.label_len # (终点 + 预测序列长度) r_end = r_begin + self.label_len + self.pred_len # seq_x = [起点,起点 + 回视窗口] seq_x = self.data_x[s_begin:s_end] # 0 - 24 # seq_y = [终点 - 先验序列窗口,终点 + 预测序列长度] seq_y = self.data_y[r_begin:r_end] # 0 - 48 # 取对应时间特征 seq_x_mark = self.data_stamp[s_begin:s_end] seq_y_mark = self.data_stamp[r_begin:r_end] return seq_x, seq_y, seq_x_mark, seq_y_mark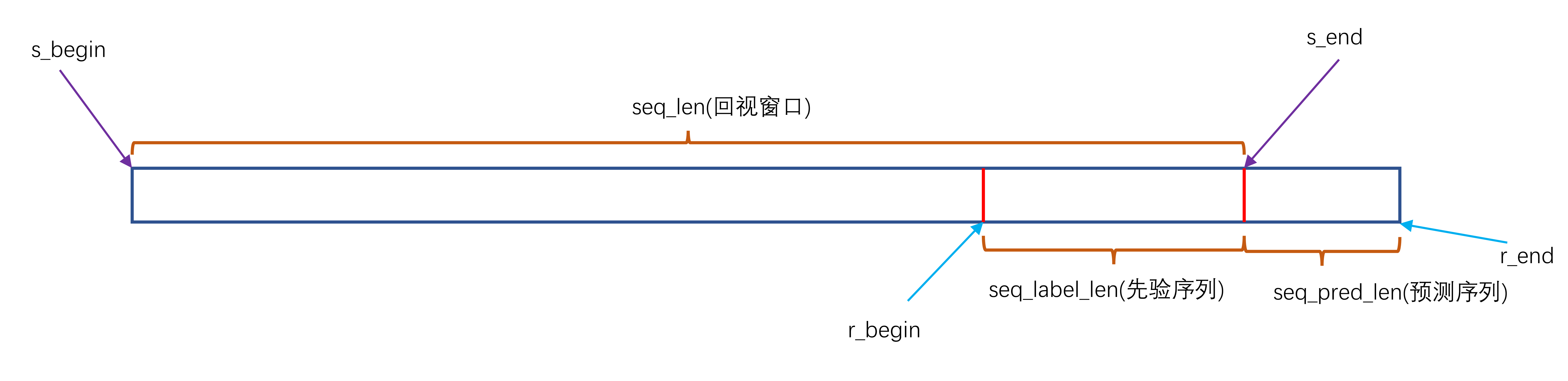
SCINet模型架构(SCINet)
打开model文件夹,找到SCINet类,先定位到main()函数,可以看到main()函数这里实例化了一个SCINet类,并将参数传入其中 if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--window_size', type=int, default=96) parser.add_argument('--horizon', type=int, default=12) parser.add_argument('--dropout', type=float, default=0.5) parser.add_argument('--groups', type=int, default=1) parser.add_argument('--hidden-size', default=1, type=int, help='hidden channel of module') parser.add_argument('--INN', default=1, type=int, help='use INN or basic strategy') parser.add_argument('--kernel', default=3, type=int, help='kernel size') parser.add_argument('--dilation', default=1, type=int, help='dilation') parser.add_argument('--positionalEcoding', type=bool, default=True) parser.add_argument('--single_step_output_One', type=int, default=0) args = parser.parse_args() # 实例化SCINet类 model = SCINet(output_len = args.horizon, input_len= args.window_size, input_dim = 9, hid_size = args.hidden_size, num_stacks = 1, num_levels = 3, concat_len = 0, groups = args.groups, kernel = args.kernel, dropout = args.dropout, single_step_output_One = args.single_step_output_One, positionalE = args.positionalEcoding, modified = True).cuda() x = torch.randn(32, 96, 9).cuda() y = model(x) print(y.shape)Splitting类(奇偶序列分离)
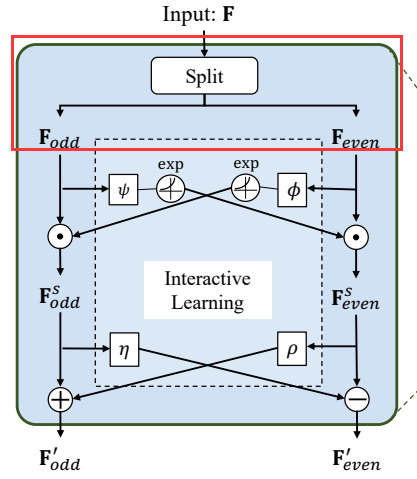
class Splitting(nn.Module): def __init__(self): super(Splitting, self).__init__() def even(self, x): # 将奇序列分离 return x[:, ::2, :] def odd(self, x): # 将偶序列分离 return x[:, 1::2, :] def forward(self, x): return (self.even(x), self.odd(x))Interactor类(下采样与交互学习)
这一部分将奇、偶序列分别使用不同分辨率的卷积捕捉时间信息,然后两序列分别进行加减运算,模型架构图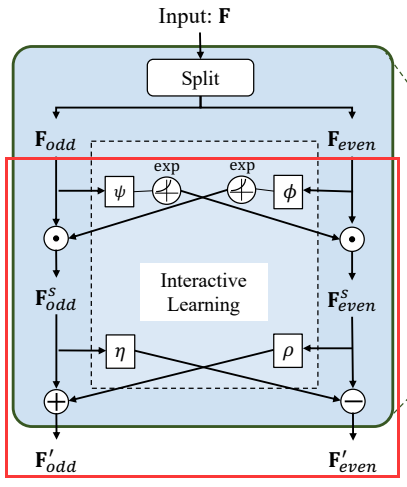
注释写的非常清楚,这一部分建议多琢磨
class Interactor(nn.Module): def __init__(self, in_planes, splitting=True, kernel = 5, dropout=0.5, groups = 1, hidden_size = 1, INN = True): super(Interactor, self).__init__() self.modified = INN self.kernel_size = kernel self.dilation = 1 self.dropout = dropout self.hidden_size = hidden_size self.groups = groups # 如果通道数为偶数 if self.kernel_size % 2 == 0: # 1 * (kernel -2) // 2 + 1 pad_l = self.dilation * (self.kernel_size - 2) // 2 + 1 #by default: stride==1 # 1 * kernel // 2 + 1 pad_r = self.dilation * (self.kernel_size) // 2 + 1 #by default: stride==1 # 如果kernel_size = 4, pda_l = 2,pad_r = 3 # 如果通道数为奇数 else: pad_l = self.dilation * (self.kernel_size - 1) // 2 + 1 # we fix the kernel size of the second layer as 3. pad_r = self.dilation * (self.kernel_size - 1) // 2 + 1 # 如果kernel_size = 3, pda_l = 2,pad_r = 2 self.splitting = splitting self.split = Splitting() modules_P = [] modules_U = [] modules_psi = [] modules_phi = [] prev_size = 1 size_hidden = self.hidden_size modules_P += [ # ReplicationPad1d用输入边界的反射来填充输入张量 nn.ReplicationPad1d((pad_l, pad_r)), # 1维卷积(in_channels,out_channels,kernel_size)-->(7,7,5) nn.Conv1d(in_planes * prev_size, int(in_planes * size_hidden), kernel_size=self.kernel_size, dilation=self.dilation, stride=1, groups= self.groups), # LeakyReLU激活层 nn.LeakyReLU(negative_slope=0.01, inplace=True), # Dropout层 nn.Dropout(self.dropout), # 1维卷积(in_channels,out_channels,kernel_size)-->(7,7,3) nn.Conv1d(int(in_planes * size_hidden), in_planes, kernel_size=3, stride=1, groups= self.groups), # Tanh激活层 nn.Tanh() ] modules_U += [ # ReplicationPad1d用输入边界的反射来填充输入张量 nn.ReplicationPad1d((pad_l, pad_r)), # 1维卷积(in_channels, out_channels,kernel_size)-->(7,7,5) nn.Conv1d(in_planes * prev_size, int(in_planes * size_hidden), kernel_size=self.kernel_size, dilation=self.dilation, stride=1, groups= self.groups), # LeakyReLu激活层 nn.LeakyReLU(negative_slope=0.01, inplace=True), # Dropout层 nn.Dropout(self.dropout), # 1维卷积(in_channels, out_channels,kernel_size)-->(7,7,3) nn.Conv1d(int(in_planes * size_hidden), in_planes, kernel_size=3, stride=1, groups= self.groups), # Tanh激活层 nn.Tanh() ] modules_phi += [ # ReplicationPad1d用输入边界的反射来填充输入张量 nn.ReplicationPad1d((pad_l, pad_r)), # 1维卷积(in_channels, out_channels,kernel_size)-->(7,7,5) nn.Conv1d(in_planes * prev_size, int(in_planes * size_hidden), kernel_size=self.kernel_size, dilation=self.dilation, stride=1, groups= self.groups), # LeakyReLU激活层 nn.LeakyReLU(negative_slope=0.01, inplace=True), # Dropout层 nn.Dropout(self.dropout), # 1维卷积(in_channels, out_channels,kernel_size)-->(7,7,3) nn.Conv1d(int(in_planes * size_hidden), in_planes, kernel_size=3, stride=1, groups= self.groups), # Tanh激活层 nn.Tanh() ] modules_psi += [ # ReplicationPad1d用输入边界的反射来填充输入张量 nn.ReplicationPad1d((pad_l, pad_r)), # 一维卷积(in_channels, out_channels,kernel_size)-->(7,7,5) nn.Conv1d(in_planes * prev_size, int(in_planes * size_hidden), kernel_size=self.kernel_size, dilation=self.dilation, stride=1, groups= self.groups), # LeakyReLU激活层 nn.LeakyReLU(negative_slope=0.01, inplace=True), # Dropout层 nn.Dropout(self.dropout), # 1维卷积(in_channels, out_channels,kernel_size)-->(7,7,3) nn.Conv1d(int(in_planes * size_hidden), in_planes, kernel_size=3, stride=1, groups= self.groups), # Tanh激活层 nn.Tanh() ] self.phi = nn.Sequential(*modules_phi) self.psi = nn.Sequential(*modules_psi) self.P = nn.Sequential(*modules_P) self.U = nn.Sequential(*modules_U) def forward(self, x): # 将奇偶序列分隔 if self.splitting: (x_even, x_odd) = self.split(x) else: (x_even, x_odd) = x # 如果INN不为0 if self.modified: # 交换奇、偶序列维度[B,L,D] --> [B,D,L] x_even = x_even.permute(0, 2, 1) x_odd = x_odd.permute(0, 2, 1) # mul()函数矩阵点乘,计算经过phi层的指数值 d = x_odd.mul(torch.exp(self.phi(x_even))) c = x_even.mul(torch.exp(self.psi(x_odd))) # 更新奇序列(奇序列 + 经过U层的偶序列) x_even_update = c + self.U(d) # 更新偶序列(偶序列 - 经过P层的奇序列) x_odd_update = d - self.P(c) return (x_even_update, x_odd_update) else: # 不计算指数值 x_even = x_even.permute(0, 2, 1) x_odd = x_odd.permute(0, 2, 1) d = x_odd - self.P(x_even) c = x_even + self.U(d) return (c, d)InteractorLevel类
该类主要实例化Interactor类,并得到奇、偶序列特征 class InteractorLevel(nn.Module): def __init__(self, in_planes, kernel, dropout, groups , hidden_size, INN): super(InteractorLevel, self).__init__() self.level = Interactor(in_planes = in_planes, splitting=True, kernel = kernel, dropout=dropout, groups = groups, hidden_size = hidden_size, INN = INN) def forward(self, x): (x_even_update, x_odd_update) = self.level(x) return (x_even_update, x_odd_update)LevelSCINet类
该类主要实例化InteractorLevel类,并将得到的奇、偶序列特征进行维度交换方便SCINet_Tree框架运算 class LevelSCINet(nn.Module): def __init__(self,in_planes, kernel_size, dropout, groups, hidden_size, INN): super(LevelSCINet, self).__init__() self.interact = InteractorLevel(in_planes= in_planes, kernel = kernel_size, dropout = dropout, groups =groups , hidden_size = hidden_size, INN = INN) def forward(self, x): (x_even_update, x_odd_update) = self.interact(x) # 交换奇、偶序列维度[B,D,L] --> [B,T,D] return x_even_update.permute(0, 2, 1), x_odd_update.permute(0, 2, 1)SCINet_Tree类
这就是论文中提到的二叉树结构,可以更有效的捕捉时间序列的长短期依赖,网络框架图: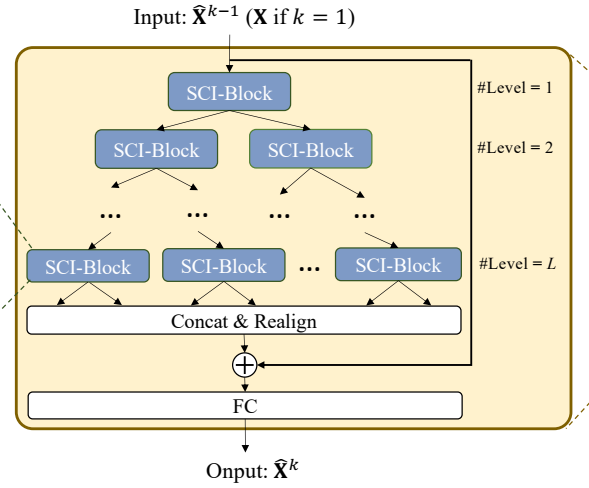
这部分框架为SCINet的核心框架,建议认真阅读
class SCINet_Tree(nn.Module): def __init__(self, in_planes, current_level, kernel_size, dropout, groups, hidden_size, INN): super().__init__() self.current_level = current_level self.workingblock = LevelSCINet( in_planes = in_planes, kernel_size = kernel_size, dropout = dropout, groups= groups, hidden_size = hidden_size, INN = INN) # 如果current_level不为0 if current_level!=0: self.SCINet_Tree_odd=SCINet_Tree(in_planes, current_level-1, kernel_size, dropout, groups, hidden_size, INN) self.SCINet_Tree_even=SCINet_Tree(in_planes, current_level-1, kernel_size, dropout, groups, hidden_size, INN) def zip_up_the_pants(self, even, odd): # 交换奇数据下标(B,L,D) --> (L,B,D) even = even.permute(1, 0, 2) odd = odd.permute(1, 0, 2) #L, B, D # 取序列长度 even_len = even.shape[0] odd_len = odd.shape[0] # 取奇、偶数据序列长度小值 mlen = min((odd_len, even_len)) _ = [] for i in range(mlen): # 在第1维度前增加1个维度 # _.shape:[12],even.shape:[12,32,7],odd.shape:[12,32,7] _.append(even[i].unsqueeze(0)) _.append(odd[i].unsqueeze(0)) # 如果偶序列长度 < 奇序列长度 if odd_len < even_len: _.append(even[-1].unsqueeze(0)) # 将张量按照第1维度拼接 return torch.cat(_,0).permute(1,0,2) #B, L, D def forward(self, x): # 取得更新后的奇、偶序列 x_even_update, x_odd_update= self.workingblock(x) # We recursively reordered these sub-series. You can run the ./utils/recursive_demo.py to emulate this procedure. if self.current_level == 0: return self.zip_up_the_pants(x_even_update, x_odd_update) else: return self.zip_up_the_pants(self.SCINet_Tree_even(x_even_update), self.SCINet_Tree_odd(x_odd_update))EncoderTree类(编码器)
实例化SCINet_Tree类,编码器,让输入进入SCINet_Tree模块 class EncoderTree(nn.Module): def __init__(self, in_planes, num_levels, kernel_size, dropout, groups, hidden_size, INN): super().__init__() self.levels=num_levels self.SCINet_Tree = SCINet_Tree( in_planes = in_planes, current_level = num_levels-1, kernel_size = kernel_size, dropout =dropout , groups = groups, hidden_size = hidden_size, INN = INN) def forward(self, x): # 编码器,让输入进入SCINet_Tree模块 x= self.SCINet_Tree(x) return xSCINet类(堆叠模型整体架构)
在该类中实现了整个模型的搭建,当然也包含架构图的最后一张,stacked堆叠、解码器、RIN激活等等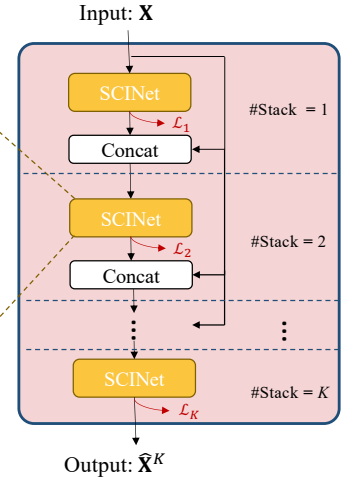
class SCINet(nn.Module): def __init__(self, output_len, input_len, input_dim = 9, hid_size = 1, num_stacks = 1, num_levels = 3, num_decoder_layer = 1, concat_len = 0, groups = 1, kernel = 5, dropout = 0.5, single_step_output_One = 0, input_len_seg = 0, positionalE = False, modified = True, RIN=False): super(SCINet, self).__init__() self.input_dim = input_dim self.input_len = input_len self.output_len = output_len self.hidden_size = hid_size self.num_levels = num_levels self.groups = groups self.modified = modified self.kernel_size = kernel self.dropout = dropout self.single_step_output_One = single_step_output_One self.concat_len = concat_len self.pe = positionalE self.RIN=RIN self.num_decoder_layer = num_decoder_layer self.blocks1 = EncoderTree( in_planes=self.input_dim, num_levels = self.num_levels, kernel_size = self.kernel_size, dropout = self.dropout, groups = self.groups, hidden_size = self.hidden_size, INN = modified) if num_stacks == 2: # we only implement two stacks at most. self.blocks2 = EncoderTree( in_planes=self.input_dim, num_levels = self.num_levels, kernel_size = self.kernel_size, dropout = self.dropout, groups = self.groups, hidden_size = self.hidden_size, INN = modified) self.stacks = num_stacks for m in self.modules(): # 如果m为2维卷积层 if isinstance(m, nn.Conv2d): # 初始化权重 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() elif isinstance(m, nn.Linear): m.bias.data.zero_() self.projection1 = nn.Conv1d(self.input_len, self.output_len, kernel_size=1, stride=1, bias=False) self.div_projection = nn.ModuleList() self.overlap_len = self.input_len//4 self.div_len = self.input_len//6 # 若解码层大于1 if self.num_decoder_layer > 1: # pro1层变为线性层 self.projection1 = nn.Linear(self.input_len, self.output_len) # 循环range(解码层-1) for layer_idx in range(self.num_decoder_layer-1): # 创建子模块列表 div_projection = nn.ModuleList() for i in range(6): # 计算全连接层输出维度 # 若input_len = 96 --> div_len = 16,overlap_len = 24 # len = 24 --> 24 --> 24 --> 24 --> 24 --> 16 lens = min(i*self.div_len+self.overlap_len,self.input_len) - i*self.div_len # (24,16) --> (24,16) --> (24,16) --> (24,16) --> (24,16) --> (16,16) div_projection.append(nn.Linear(lens, self.div_len)) self.div_projection.append(div_projection) if self.single_step_output_One: # only output the N_th timestep. if self.stacks == 2: if self.concat_len: self.projection2 = nn.Conv1d(self.concat_len + self.output_len, 1, kernel_size = 1, bias = False) else: self.projection2 = nn.Conv1d(self.input_len + self.output_len, 1, kernel_size = 1, bias = False) else: # output the N timesteps. if self.stacks == 2: if self.concat_len: self.projection2 = nn.Conv1d(self.concat_len + self.output_len, self.output_len, kernel_size = 1, bias = False) else: self.projection2 = nn.Conv1d(self.input_len + self.output_len, self.output_len, kernel_size = 1, bias = False) # For positional encoding self.pe_hidden_size = input_dim if self.pe_hidden_size % 2 == 1: self.pe_hidden_size += 1 num_timescales = self.pe_hidden_size // 2 max_timescale = 10000.0 min_timescale = 1.0 log_timescale_increment = ( math.log(float(max_timescale) / float(min_timescale)) / max(num_timescales - 1, 1)) temp = torch.arange(num_timescales, dtype=torch.float32) inv_timescales = min_timescale * torch.exp( torch.arange(num_timescales, dtype=torch.float32) * -log_timescale_increment) self.register_buffer('inv_timescales', inv_timescales) ### RIN Parameters ### if self.RIN: self.affine_weight = nn.Parameter(torch.ones(1, 1, input_dim)) self.affine_bias = nn.Parameter(torch.zeros(1, 1, input_dim)) def get_position_encoding(self, x): # 取数据第2个维度 max_length = x.size()[1] # 位置编码 position = torch.arange(max_length, dtype=torch.float32, device=x.device) # 在第2个维度前面再添加一个维度 temp1 = position.unsqueeze(1) # 5 1 temp2 = self.inv_timescales.unsqueeze(0) # 1 256 # 矩阵乘法 scaled_time = position.unsqueeze(1) * self.inv_timescales.unsqueeze(0) # 5 256 # 拼接sin(特征)和cos(特征) signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=1) #[T, C] # pad操作 signal = F.pad(signal, (0, 0, 0, self.pe_hidden_size % 2)) # 改变数组维度,并使其称为视图 signal = signal.view(1, max_length, self.pe_hidden_size) return signal def forward(self, x): # 判断输出序列长度合理性 assert self.input_len % (np.power(2, self.num_levels)) == 0 # 如果需要位置编码 if self.pe: pe = self.get_position_encoding(x) if pe.shape[2] > x.shape[2]: x += pe[:, :, :-1] else: x += self.get_position_encoding(x) # 若使用RIN激活 if self.RIN: print('/// RIN ACTIVATED ///\r',end='') means = x.mean(1, keepdim=True).detach() #mean x = x - means #var stdev = torch.sqrt(torch.var(x, dim=1, keepdim=True, unbiased=False) + 1e-5) x /= stdev # affine # print(x.shape,self.affine_weight.shape,self.affine_bias.shape) x = x * self.affine_weight + self.affine_bias # 第一层stack res1 = x # 进入编码器 x = self.blocks1(x) # 相加操作 x += res1 # 如果解码层为1 if self.num_decoder_layer == 1: # 经过1维卷积层Conv1d(input_len, output_len, kernel_size = 1),得到结果 x = self.projection1(x) else: # 交换维度(B,L,D) --> (B,D,L) x = x.permute(0,2,1) for div_projection in self.div_projection: # 创建与x相同的全0矩阵 output = torch.zeros(x.shape,dtype=x.dtype).cuda() # 取出下标和对应层 for i, div_layer in enumerate(div_projection): # 赋值对应维度 div_x = x[:,:,i*self.div_len:min(i*self.div_len+self.overlap_len,self.input_len)] output[:,:,i*self.div_len:(i+1)*self.div_len] = div_layer(div_x) x = output # 经过1维卷积层Conv1d(input_len, output_len, kernel_size = 1),得到结果 x = self.projection1(x) # 交换维度(B,L,D) --> (B,D,L) x = x.permute(0,2,1) # 如果stacks为1 if self.stacks == 1: # 反转RIN激活 if self.RIN: # x - 偏置 x = x - self.affine_bias # x / 权值 x = x / (self.affine_weight + 1e-10) # x * 标准差 x = x * stdev # x + 平均值 x = x + means return x # 若stacks为2 elif self.stacks == 2: # 赋值中间层输出 MidOutPut = x # 若concat_len不为0 if self.concat_len: # 将res1(部分)和x在沿1维度进行拼接 x = torch.cat((res1[:, -self.concat_len:,:], x), dim=1) else: # 将res1(部分)和x在沿1维度进行拼接 x = torch.cat((res1, x), dim=1) # 第2层stacks res2 = x # 进入编码层 x = self.blocks2(x) # 加法操作 x += res2 # 进入1维卷积Conv1d(output_len, output_len, kernel_size = 1) x = self.projection2(x) # 反转RIN激活 if self.RIN: MidOutPut = MidOutPut - self.affine_bias MidOutPut = MidOutPut / (self.affine_weight + 1e-10) MidOutPut = MidOutPut * stdev MidOutPut = MidOutPut + means # 反转RIN激活 if self.RIN: x = x - self.affine_bias x = x / (self.affine_weight + 1e-10) x = x * stdev x = x + means # 输出结果以及中间层特征输出 return x, MidOutPutdef get_variable(x): x = Variable(x) return x.cuda() if torch.cuda.is_available() else x模型训练(exp_ETTh)
这里我主要注释一下train函数,valid和test函数都差不多,只是有些操作不需要删减了而已。 def train(self, setting): # 取得训练、验证、测试数据及数据加载器 train_data, train_loader = self._get_data(flag = 'train') valid_data, valid_loader = self._get_data(flag = 'val') test_data, test_loader = self._get_data(flag = 'test') path = os.path.join(self.args.checkpoints, setting) # 创建模型保存路径 if not os.path.exists(path): os.makedirs(path) # 绘制模型训练信息曲线 writer = SummaryWriter('event/run_ETTh/{}'.format(self.args.model_name)) # 获取当前时间 time_now = time.time() # 取训练步数 train_steps = len(train_loader) # 设置早停参数 early_stopping = EarlyStopping(patience=self.args.patience, verbose=True) # 选择优化器 model_optim = self._select_optimizer() # 选择损失函数 criterion = self._select_criterion(self.args.loss) # 如果多GPU并行 if self.args.use_amp: scaler = torch.cuda.amp.GradScaler() # 如果断点续传训练 if self.args.resume: self.model, lr, epoch_start = load_model(self.model, path, model_name=self.args.data, horizon=self.args.horizon) else: epoch_start = 0 for epoch in range(epoch_start, self.args.train_epochs): iter_count = 0 train_loss = [] self.model.train() epoch_time = time.time() for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(train_loader): iter_count += 1 model_optim.zero_grad() # 得到预测值、反归一化预测值、中间层输出、反归一化中间层输出、真实值、反归一化真实值 pred, pred_scale, mid, mid_scale, true, true_scale = self._process_one_batch_SCINet( train_data, batch_x, batch_y) # stacks为1 if self.args.stacks == 1: # loss损失为mae(真实值+预测值) loss = criterion(pred, true) # stacks为2 elif self.args.stacks == 2: # loss损失为mae(真实值,预测值) + mae(中间层输出,预测值) loss = criterion(pred, true) + criterion(mid, true) else: print('Error!') # 将loss信息记录到train_loss列表中 train_loss.append(loss.item()) # 100个训练步数输出一次训练、验证、测试损失信息 if (i+1) % 100==0: print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item())) speed = (time.time()-time_now)/iter_count left_time = speed*((self.args.train_epochs - epoch)*train_steps - i) print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time)) iter_count = 0 time_now = time.time() # 如果有分布式计算 if self.args.use_amp: print('use amp') scaler.scale(loss).backward() scaler.step(model_optim) scaler.update() else: # 反向传播 loss.backward() # 更新优化器 model_optim.step() # 打印关键信息 print("Epoch: {} cost time: {}".format(epoch+1, time.time()-epoch_time)) train_loss = np.average(train_loss) print('--------start to validate-----------') valid_loss = self.valid(valid_data, valid_loader, criterion) print('--------start to test-----------') test_loss = self.valid(test_data, test_loader, criterion) print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} valid Loss: {3:.7f} Test Loss: {4:.7f}".format( epoch + 1, train_steps, train_loss, valid_loss, test_loss)) # 记录训练、测试、验证集损失下降情况 writer.add_scalar('train_loss', train_loss, global_step=epoch) writer.add_scalar('valid_loss', valid_loss, global_step=epoch) writer.add_scalar('test_loss', test_loss, global_step=epoch) # 测算早停策略 early_stopping(valid_loss, self.model, path) # 若达到早停标准 if early_stopping.early_stop: print("Early stopping") break # 更新学习率 lr = adjust_learning_rate(model_optim, epoch+1, self.args) # 保存模型 save_model(epoch, lr, self.model, path, model_name=self.args.data, horizon=self.args.pred_len) # 保存表现最好模型 best_model_path = path+'/'+'checkpoint.pth' # 加载表现最好模型 self.model.load_state_dict(torch.load(best_model_path)) # 返回模型 return self.model结果展示
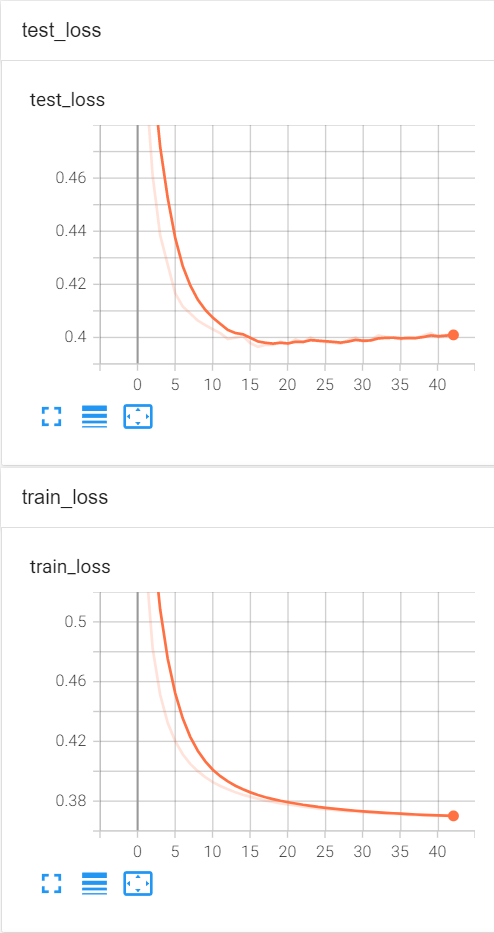
我用kaggle上的GPU(P100)跑的,时间很短,跑这个ETTh这个数据集需要40分钟左右>>>>>>>start training : SCINet_ETTh1_ftM_sl96_ll48_pl48_lr0.0001_bs32_hid1_s1_l3_dp0.5_invFalse_itr0>>>>>>>>>>>>>>>>>>>>>>>>>>train 8497val 2833test 2833iters: 100, epoch: 41 | loss: 0.3506456speed: 0.2028s/iter; left time: 3204.9921siters: 200, epoch: 41 | loss: 0.3641948speed: 0.0906s/iter; left time: 1422.0832sEpoch: 41 cost time: 24.570287466049194--------start to validate-----------normed mse:0.5108, mae:0.4747, rmse:0.7147, mape:5.9908, mspe:25702.7811, corr:0.7920denormed mse:7.2514, mae:1.5723, rmse:2.6928, mape:inf, mspe:inf, corr:0.7920--------start to test-----------normed mse:0.3664, mae:0.4001, rmse:0.6053, mape:7.6782, mspe:30989.9618, corr:0.7178denormed mse:8.2571, mae:1.5634, rmse:2.8735, mape:inf, mspe:inf, corr:0.7178Epoch: 41, Steps: 265 | Train Loss: 0.3702444 valid Loss: 0.4746509 Test Loss: 0.4000920iters: 100, epoch: 42 | loss: 0.3643743speed: 0.2015s/iter; left time: 3130.5999siters: 200, epoch: 42 | loss: 0.3464577speed: 0.1015s/iter; left time: 1566.1000sEpoch: 42 cost time: 25.76799440383911--------start to validate-----------normed mse:0.5101, mae:0.4743, rmse:0.7142, mape:5.9707, mspe:25459.9669, corr:0.7923denormed mse:7.2425, mae:1.5713, rmse:2.6912, mape:inf, mspe:inf, corr:0.7923--------start to test-----------normed mse:0.3670, mae:0.4010, rmse:0.6058, mape:7.6564, mspe:30790.0708, corr:0.7179denormed mse:8.2969, mae:1.5701, rmse:2.8804, mape:inf, mspe:inf, corr:0.7179Epoch: 42, Steps: 265 | Train Loss: 0.3700826 valid Loss: 0.4743312 Test Loss: 0.4009686iters: 100, epoch: 43 | loss: 0.3849421speed: 0.2019s/iter; left time: 3083.0659siters: 200, epoch: 43 | loss: 0.3757646speed: 0.0981s/iter; left time: 1487.8231sEpoch: 43 cost time: 25.635279893875122--------start to validate-----------normed mse:0.5105, mae:0.4744, rmse:0.7145, mape:5.9568, mspe:25381.2960, corr:0.7922denormed mse:7.2566, mae:1.5721, rmse:2.6938, mape:inf, mspe:inf, corr:0.7922--------start to test-----------normed mse:0.3674, mae:0.4014, rmse:0.6061, mape:7.6480, mspe:30700.9283, corr:0.7180denormed mse:8.3153, mae:1.5732, rmse:2.8836, mape:inf, mspe:inf, corr:0.7180Epoch: 43, Steps: 265 | Train Loss: 0.3698175 valid Loss: 0.4744163 Test Loss: 0.4013726Early stopping>>>>>>>testing : SCINet_ETTh1_ftM_sl96_ll48_pl48_lr0.0001_bs32_hid1_s1_l3_dp0.5_invFalse_itr0<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<test 2833normed mse:0.3660, mae:0.3998, rmse:0.6050, mape:7.7062, mspe:31254.7139, corr:0.7174TTTT denormed mse:8.2374, mae:1.5608, rmse:2.8701, mape:inf, mspe:inf, corr:0.7174Final mean normed mse:0.3660,mae:0.3998,denormed mse:8.2374,mae:1.5608exp文件夹中存放模型文件,后缀名为.pht;event文件夹中有tensorboard记录的loss文件,这里展示一下