论文地址:https://arxiv.org/pdf/2403.05313
Github地址:https://github.com/CraftJarvis/RAT
Demo地址:https://huggingface.co/spaces/jeasinema/RAT
北京大学、加州大学洛杉矶分校和北京通用人工智能研究院的研究人员探索如何在信息检索的帮助下迭代修改思想链提高大型语言模型在长生成任务中的推理和生成能力,同时极大地减轻幻觉。特别是,所提出的方法——检索增强的思想(RAT):利用检索到的与任务查询相关的信息逐一修正每个思考步骤,在生成初始零样本CoT之后,将RAT应用于GPT-3.5、GPT-4和CodeLLaMA-7b大大提高了它们在各种长期范围内的性能生成任务;平均而言,代码生成的评分相对提高了13.63%,16.96%在数学推理方面,19.2%的人在创造性写作方面,42.78%的人在具体任务计划方面。
大语言模型(LLM)在各种自然语言推理任务上取得了丰硕的进展,尤其是当将大模型与复杂的提示策略相结合时,比如思维链(CoT)提示。然而,人们越来越担心LLM推理的事实正确性,经常会出现所谓的“幻觉”(hallucination)——模型会生成看似合理但实际上并不准确的信息,尤其是在长任务推理中。当涉及到零样本CoT提示时,这个问题变得更加重要。“let’s think step-by-step”和需要多步骤和上下文感知推理的长期生成任务,包括代码生成、任务规划、数学推理等。事实上有效的中间思想可能对成功完成这些任务至关重要。
为解决长任务推理问题,研究人员提出了各种方法旨在改进 LLM 的推理过程。一些较早的方法尝试将外部信息检索与模型生成的内容相结合,以确保模型输出的事实准确性。然而,这些方法通常无法动态地改进推理过程,导致产生的结果虽然有所改善,却仍然未能达到理想的上下文理解和准确性水平。
来自北京大学、加州大学洛杉矶分校和北京通用人工智能研究院的研究人员提出的 Retrieval Augmented Thoughts (RAT) 方法,直觉是幻觉在中间推理过程可以通过外部知识的帮助来缓解,RAT旨在直接解决 LLM 中的事实准确性问题,如图1所示:
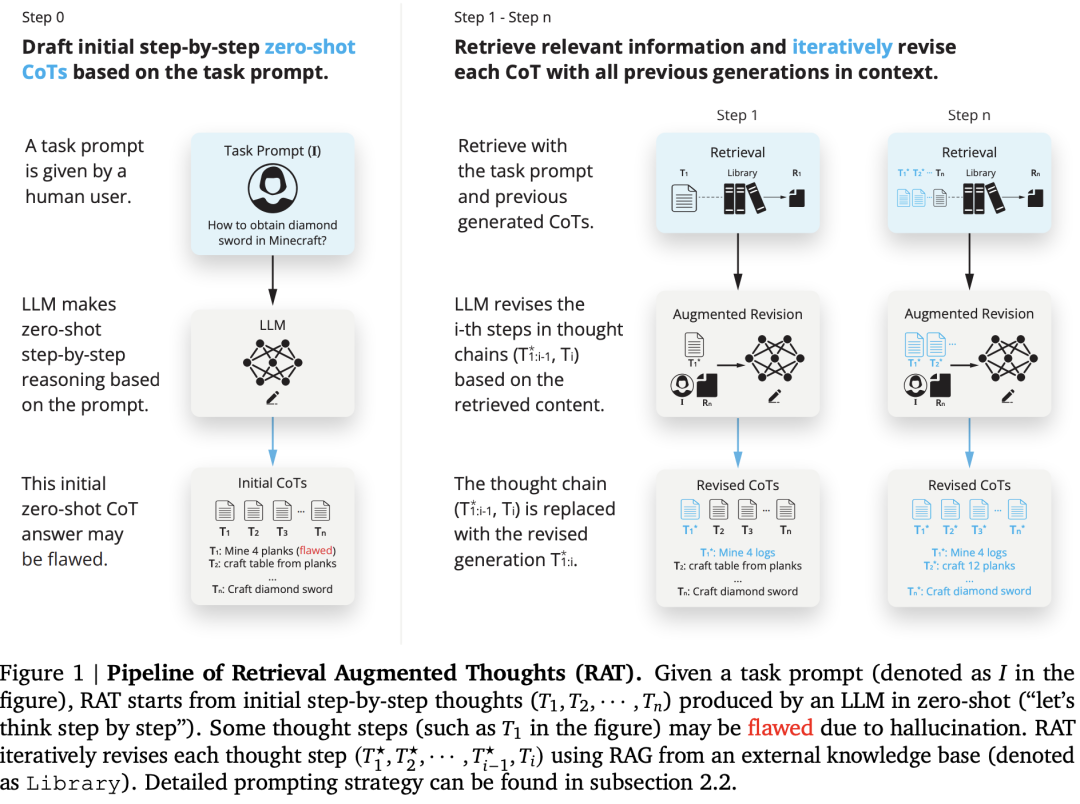
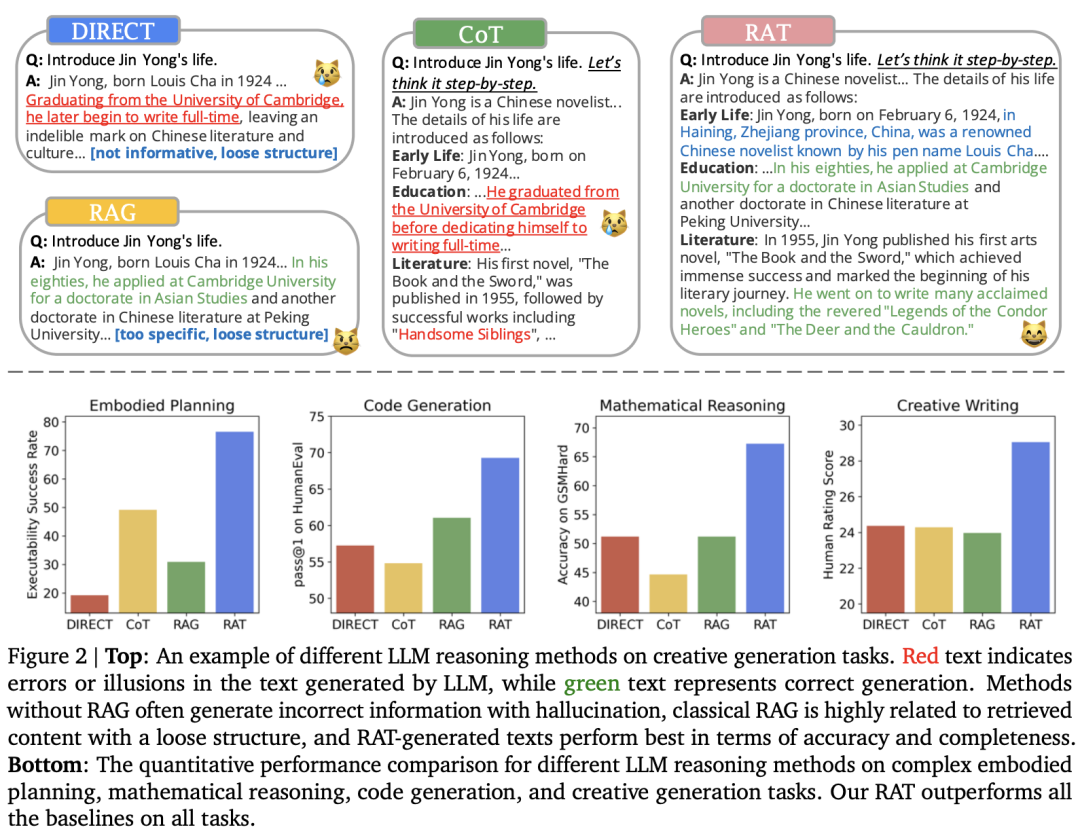
RAT 是一种着重于迭代修正模型生成思路的新方法。首先,LLM产生的初始零样本CoT以及原始任务提示将被用作查询,以检索可能有助于修改可能有缺陷的CoT的信息。其次,设计一种渐进的方法,而不是用完整的CoT进行检索和修改并立即产生最终响应,其中LLM在CoT(一系列子任务)之后逐步生成响应,并且只有当前思维步骤将根据任务提示检索到的信息、当前和过去的CoT进行修改。这种策略可以类比于人类的推理过程:在复杂的长期问题解决过程中,利用外部知识来调整我们的逐步思维。RAT和其他技术的对比,如图2所示:
论文在一系列具有挑战性的长期任务中评估RAT,包括代码生成、数学推理、具体任务规划和创造性写作,使用了几种不同规模的LLM:GPT-3.5、GPT-4、CodeLLaMA-7b。结果表明:与vanilla CoT提示和RAG方法相比,将RAT与这些LLM相结合具有强大的优势,在如下任务中达到SOTA性能水平:
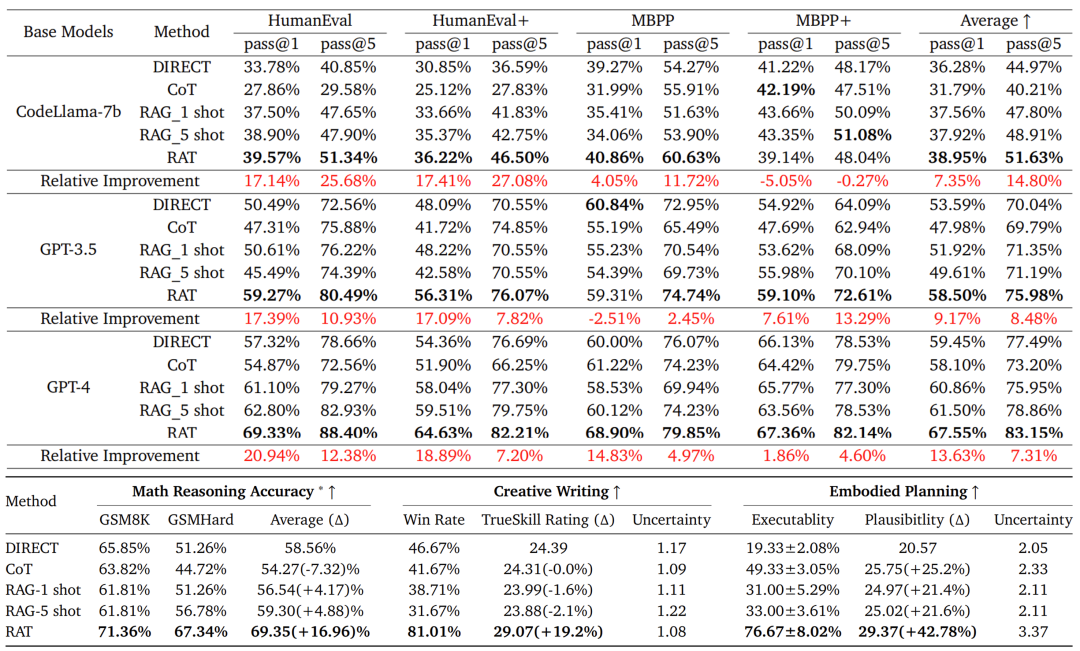
1)代码生成:HumanEval(+20.94%)、HumanEval+(+18.89%)、MBPP(+14.83%)、MBPP+(+1.86%);
2) 数学推理问题:GSM8K(+8.36%)和GSMHard(+31.37%);
3) Minecraft任务规划:(可执行性提高到2.96倍,合理性增加+51.94%);
4) 创造性写作:(超过人类得分+19.19%)。
消融实验研究进一步证实了RAT的两个关键成分所起的关键作用:1)使用RAG修正CoT和2)逐步修正和生成。这项工作揭示了LLM如何修改他们的推理在外部知识的帮助下,以零样本的方式进行过程,就像人类所做的那样。
RAT算法如下所示:

使用RAG修正CoT产生的每一个思维步骤提示,算法如图1和算法1所示。具体来说,给定任务提示I、 我们首先让LLM以zero-shot(“let’s think step-by-step”)逐步生成思考 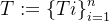 ,?? 代表第?步思考。在长生成任务中,? 可以是中间推理步骤,例如代码生成中带有注释的伪代码,创造性写作中的文章提纲等,或草稿响应本身,例如包含的子目标列表任务规划,如图1所示。
,?? 代表第?步思考。在长生成任务中,? 可以是中间推理步骤,例如代码生成中带有注释的伪代码,创造性写作中的文章提纲等,或草稿响应本身,例如包含的子目标列表任务规划,如图1所示。
由于? 可能有缺陷(例如,包含幻觉),因此需要继续使用RAG来修改生成思想步骤,然后根据这些思想生成最终响应。具体来说,假设已经修复了之前的思考步骤现在即将修订 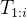 ,我们首先将文本
,我们首先将文本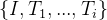 转换到查询中??,公式如下所示:
转换到查询中??,公式如下所示:
?? = ToQuery( 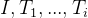 ),
),
其中ToQuery(·)可以是文本编码器,也可以是转换任务提示I,当前和过去的思维步骤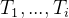 为检索系统处理的一个查询?? 。作者采用RAG使用??检索相关文件??,最后生成修改后的思考步骤提示
为检索系统处理的一个查询?? 。作者采用RAG使用??检索相关文件??,最后生成修改后的思考步骤提示
最后,根据实际任务,修订思维步骤 可以简单地用作最后模型的响应,例如具体任务规划。对于代码生成或创造性写作等任务,LLM将被进一步提示生成每个人的完整回应(代码、段落)逐步修正思想步骤。
在修正第?个思考步骤??,而不是仅使用当前步骤??,或完整的思想链 来生成RAG的查询,我们确保查询??由当前的思维步骤??以及之前修改的思维步骤
生成的。即我们使用RAG采用因果推理来修正思想,公式如下所示:
?? = ToQuery( ),
RAT算法实验效果如下所示: