个人主页 : zxctscl
如有转载请先通知
文章目录
1. 冯诺依曼体系结构1.1 认识冯诺依曼体系结构1.2 存储金字塔 2. 操作系统2.1 概念2.2 结构2.3 操作系统的管理 3. 进程3.1 进程描述3.2 Linux下的PCB 4. task_struct本身内部属性4.1 启动4.2 进程的创建方式4.2.1 父子进程4.2.2 fork4.2.3 一次创建多个进程
1. 冯诺依曼体系结构
1.1 认识冯诺依曼体系结构
电脑里面的硬件不是随便就能构成计算机,这些硬件是按照一定的规则去组装电脑的。
计算机的核心工作就是通过一定的输入设备,把数据交给计算机cpu,而cpu经过一定的设备再显示出结果。
计算机的构成遵循冯诺依曼体系结构: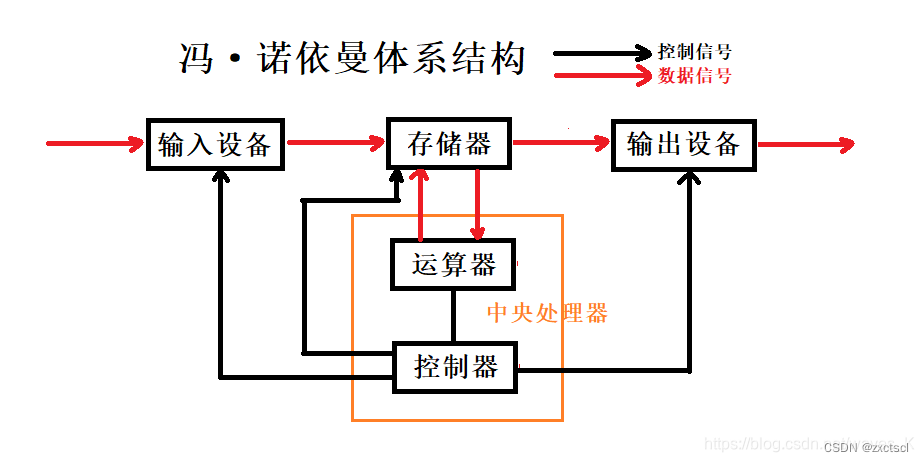
输入设备:键盘、鼠标、摄像头、话筒、磁盘、网卡…
输出设备:显示器、声卡、磁盘、网卡
中央处理器(CPU):运算器、控制器
存储器:内存
设备是互相连接的。
数据是要在计算机体系结构中进行流动的,流动的过程中,进行数据的加工处理。
从一个设备到另一个设备,本质是一种拷贝。
中央处理器的运算速度特别快,如果用户想要计算机处理数据,计算机就得在整个体系的各种设备之间拷贝各种数据,还CPU得进行运算。CPU处理速度很快所以它并不是影响计算机整体效率的矛盾。而是数据设备间拷贝的效率,决定了计算机整体的基本效率。
1.2 存储金字塔
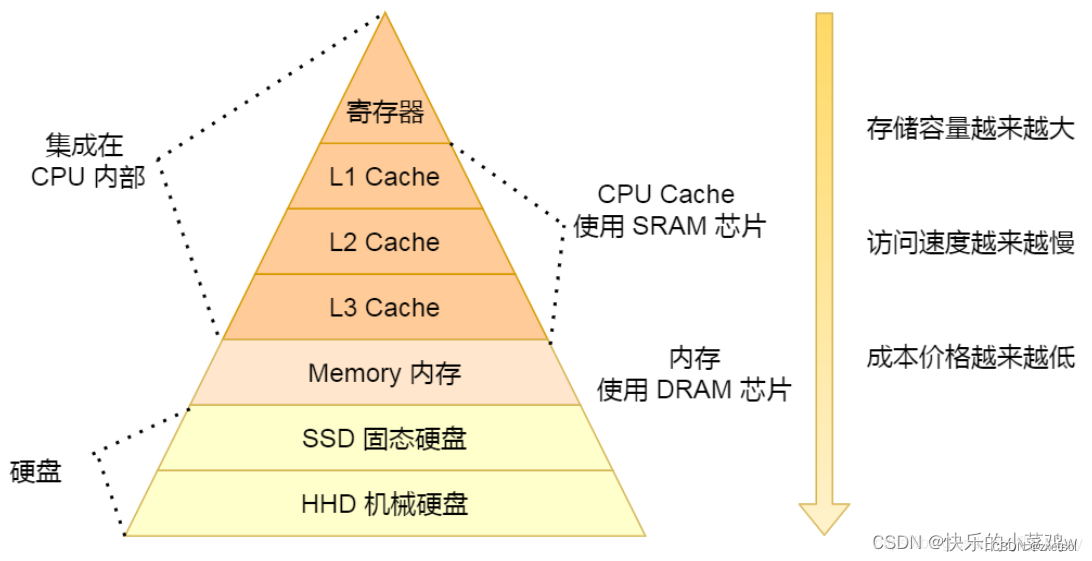
存储:距离CPU越近的,效率越高,成本越高
计算机为什么要有存储器?
如果没有存储器。
输入设备效率非常低,CPU非常快,它们两个的速度差非常大。根据木桶原理,输入设备拷贝数据到CPU非常慢,CPU的大部分时间就是在等待数据;同时CPU想要输出,从CPU里面数据拷贝到输出设备速度又非常慢,所以整个计算机的效率是输入输出设备的效率,就不能采取这样的方案。
所以就加了个内存,可以预先在内存里面加载大量的数据,从此CPU就在内存里面读数据,CPU在处理数据时,同时可以将输入设备的数据拷贝到内存里面。这样整体的效率取决于输入输出设备就变成了取决于存储器了。
存储器就相当于输入输出和CPU之间的一个巨大的缓存。
冯诺依曼体系结构不仅仅是提高了计算机的效率,还并没有将计算机的成本提高多少。
在硬件数据流动角度,在数据层面:
CPU不和外设直接打交道,CPU只和内存打交道。外设(输入和输出)的数据,不是直接给CPU的,而是先放入内存中。那么冯诺依曼体系结构能干什么?
程序运行,要先加载到内存。
程序=代码+数据。程序的数据要被CPU访问。
程序没有被加载在内存的时候在磁盘里面,就是一个二进制文件。磁盘就是外设,CPU不能直接从外设直接读取代码和数据,只能通过内存来读取,这个就是冯诺依曼体系结构规定了必须这么做。
对冯诺依曼的理解,不能停留在概念上,要深入到对软件数据流理解上,解释一下,从你登录上qq开始和某位朋友聊天开始,数据的流动过程。 从你打开窗口,开始给他发消息,到他的到消息之后的数据流动过程。
我这边是电脑,朋友那边也是电脑,本质上就是两台冯诺依曼体系。
我是通过键盘输入了一个消息假设是“你好”,那么“你好”必须得在内存里,就是我们在电脑上登录的时候QQ已经加载到内存里了。而“你好”要发到朋友那里就得先经过加密,加密就得通过CPU,然后再到输出设备,而要实现消息传输就需要网络,能和网络打交道的就是输出设备里面的网卡。数据经过网路就能到达朋友那边。
到朋友电脑那边,被朋友收到的输入设备肯定也是网卡,然后这个数据就传到内存里,而QQ要做解密的操作,所以数据得加载到CPU中,消息解密得到“你好”,再写到内存中,然后再把消息刷新到输出设备显示器上。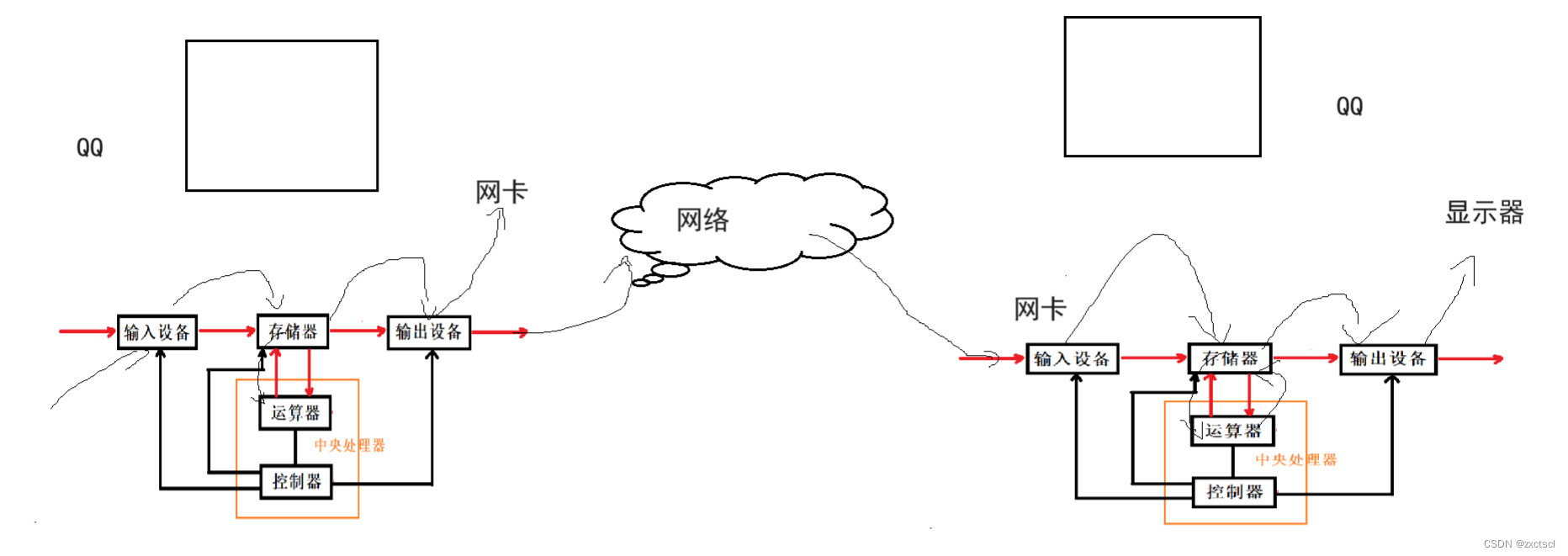
2. 操作系统
2.1 概念
操作系统是一款进行软硬件资源管理的软件
操作系统广义的认识:操作系统的内核+操作系统的外壳周边程序,这里的外壳周边程序指的是给用户提供使用操作系统的方式。
操作系统狭义的认识:只是操作系统的内核。
2.2 结构
如果操作系统要直接把硬件管理好,前提是得有通信,所以操作系统得访问到硬件,可、是每一种硬件的物理特性是不一样的,如果直接由操作系统来直接访问下面的这些硬件,如果硬件的物理特性发生了变化,还得去改操作系统。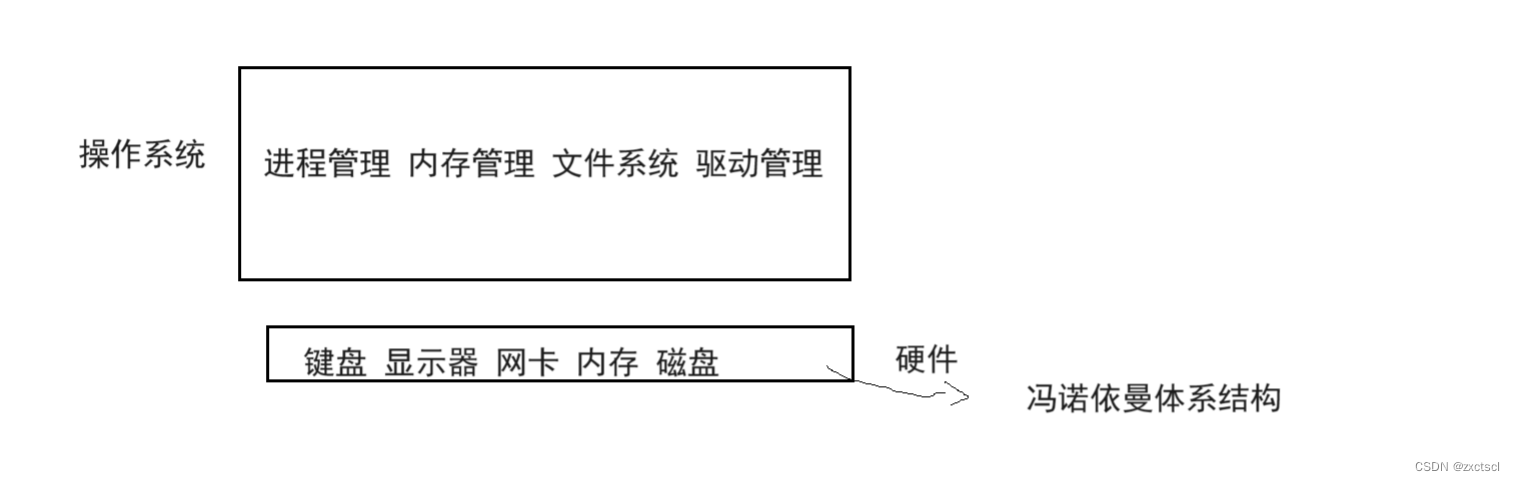
所以就不能操作系统就不能直接管理硬件,这里就在它们两个之间多了一个软件层: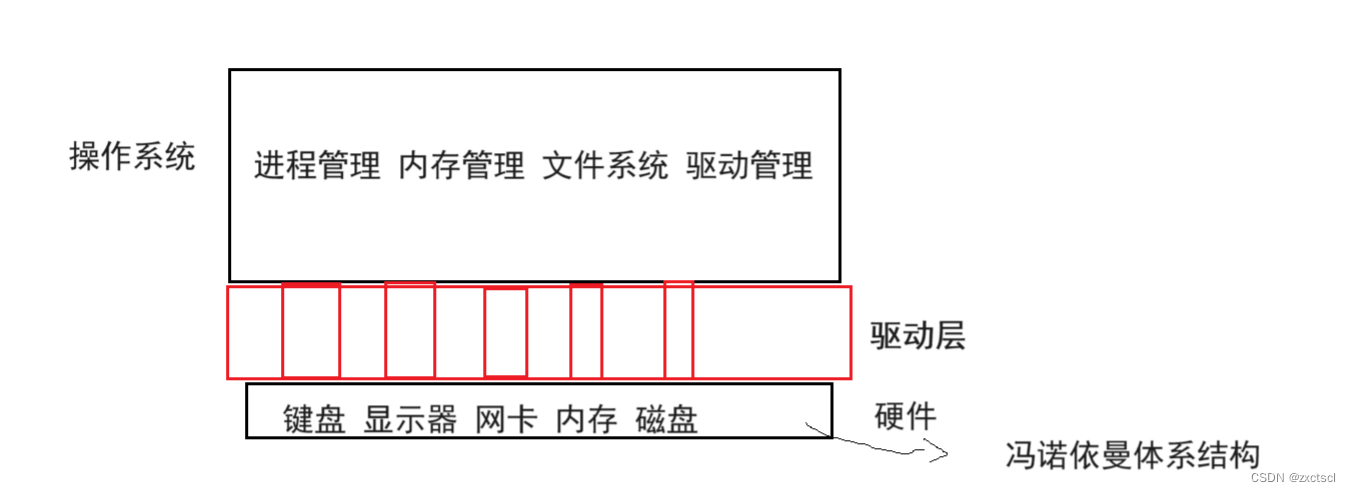
每一种硬件都有自己对应的驱动程序,驱动器层主要负责向操作系统提供一些通信接口,让操作系统直接提供驱动层访问到硬件。一般这里的驱动层的软件代码都是由厂商自定义的。
这个结构就叫做:体系结构的层状划分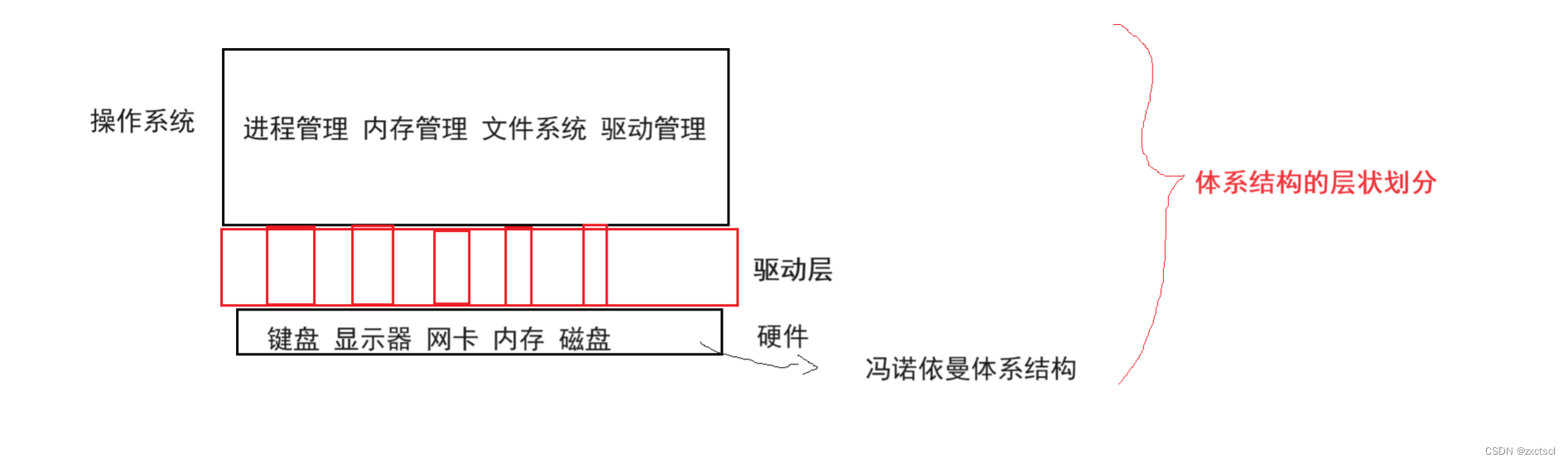
为什么要有操作系统?
对软硬件资源进行管理(手段),为用户提供一个良好(稳定的、安全的、高效的)的运行环境
2.3 操作系统的管理
日常生活中我们做事情离不开决策和执行。
举个例子:在学校里面,学生是被管理者,校长就是真正意义上的管理者,但是校长并不是直接来管理学生,而是通过辅导员,可能到毕业有的学生都没有见过校长。所以说一个学校被管理好,不需要管理者和被管理者直接接触。
那么是如何管理的?
拿到学生的数据才是目的,管理学生,本质就是对学生数据进行管理。
对于任何管理都是:先描述,在组织
凡是要对待特定的对象进行管理也是先描述,在组织

作为用户是不能直接绕过操作系统来直接访问底层硬件,任何要访问硬件的操作必须通过操作系统来做。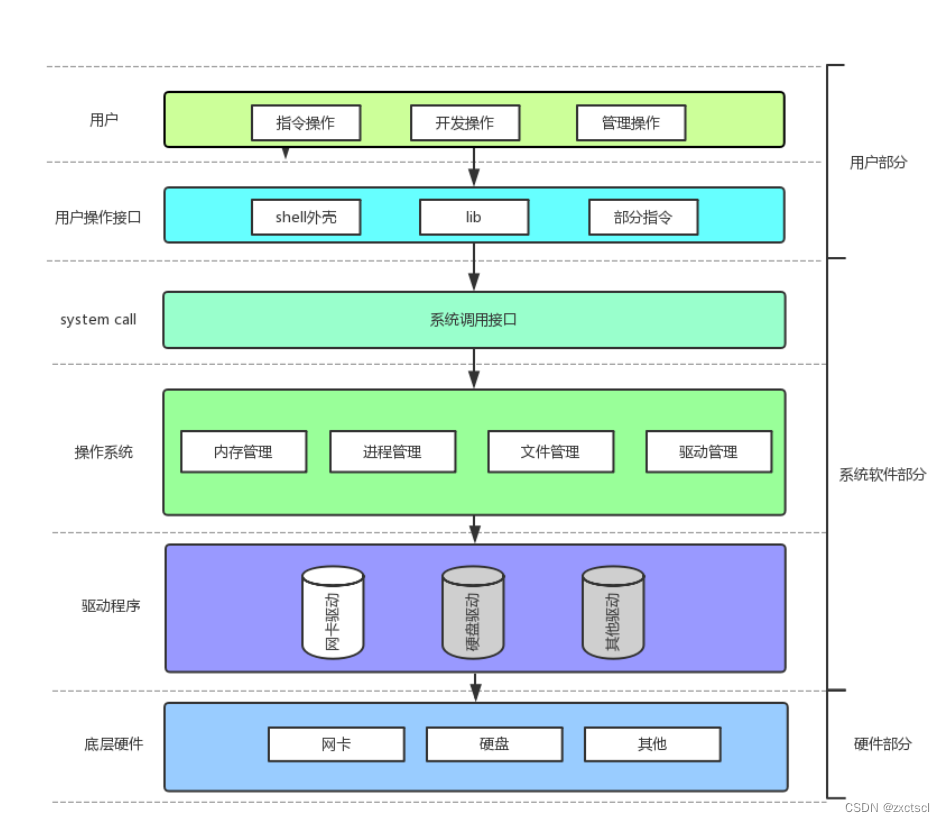
如果用户想要访问操作系统里面某一部分软硬件资源的数据,怎么怎么访问?
举个例子:在银行如果想要存钱,不可能允许用户直接进入仓库里面直接存钱,而又必须给用户提供对应的业务,所以银行就提供了柜台来提供业务,用户通过柜台来存取钱。
和银行的方式一样,操作系统为用户提供一个软件层,叫做系统调用。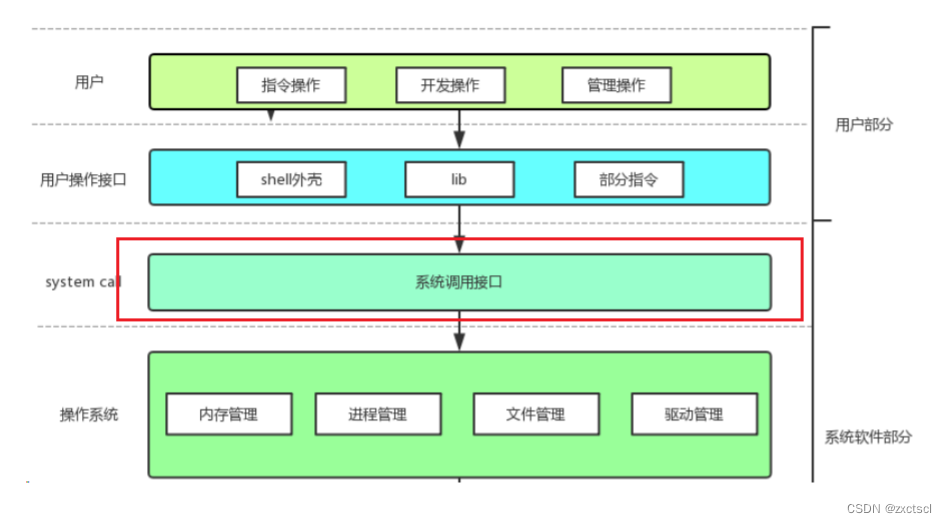
用户要访问操作系统,必须使用系统调用的方式,使用操作系统。
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
3. 进程
3.1 进程描述
概念:程序的一个执行实例,正在执行的程序等。
把可执行程序的代码和数据加载到内存里,不是进程,只是进程对应的代码和数据。
某一个进程都会有一个struct PCB,它里面包含进程对应的所有属性,还有内存指针。
一个进程一个PCB。把所有进程用struct PCB* next指针连接,管理起来,所以对进程的管理,就变成了对链表的增删改查。
进程=PCB+自己的代码和数据
所以对进程的管理就转化为对PCB的管理,不是直接对程序进行管理。
为什么要有PCB?
操作系统要对进程管理,就得先描述,在组织。
3.2 Linux下的PCB
进程=PCB+自己的代码和数据
在Linux下PCB具体的数据结构叫struct task struct,就是进程控制块。
PCB是Linux下的统称
struct task struct是具体的称呼。
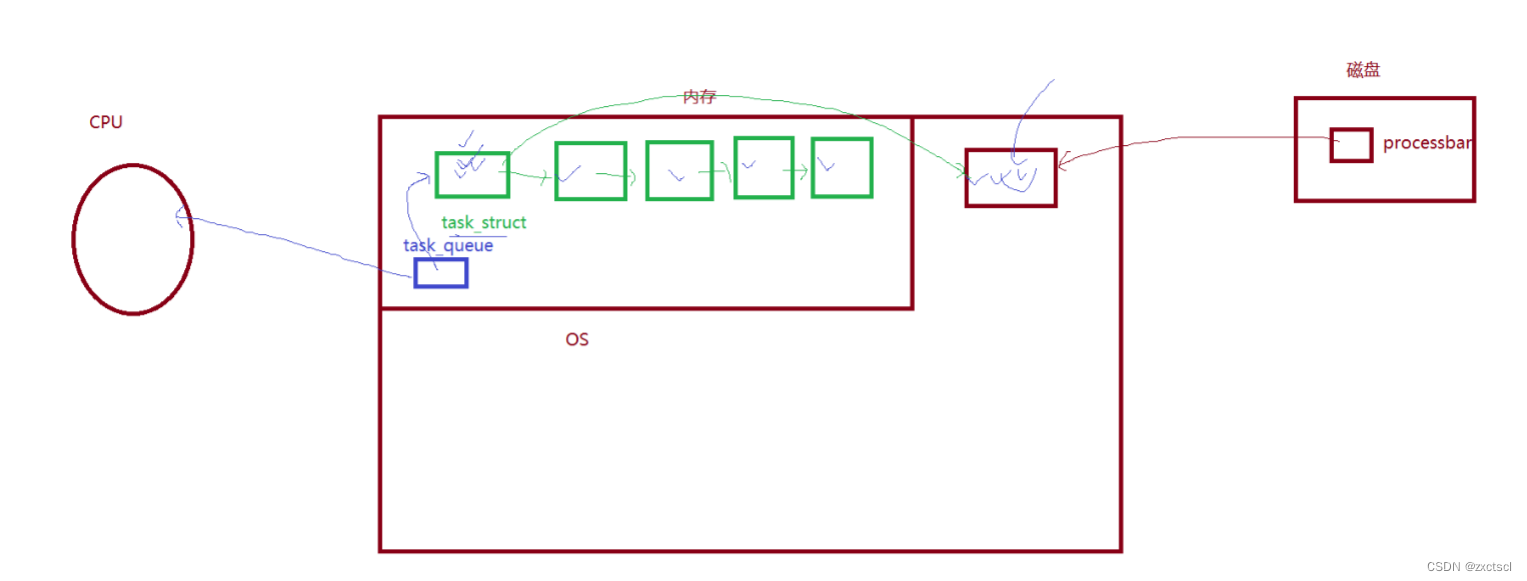
操作系统为了管理程序的代码和数据,会创建进程控制块task_struct,包含了进程的所有属性,并且执行自己的代码和数据。在操作系统中可能会同时存在很多进程控制块,所以用链表把它们链接起来。CPU想要调度进程,在操作系统里面维护一个队列数据结构task_queue。将来CPU要调度的时候,就在task_queue里面选择进程去调度。想要让进程运行起来,就会让进程在操作系统里面排队,是task_struct去进行排队。
所以操作系统调度运行进程,本质就是让进程控制块task_struct进行排队。
所以可以把进程理解为:
进程=内核task_struct结构体+程序的代码和数据
如何理解进程的动态运行?
只要我们进程的task_struct将来在不同的队列中,进程就可以访问不同的资源。
4. task_struct本身内部属性
4.1 启动
先用C语言简单的写一个测试代码:
Makefile:
1 myprocess:myprocess.c 2 gcc -o $@ $^ 3 .PHONY:clean 4 clean: 5 rm -f myprocessmyprocess.c:
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main() 5 { 6 while(1) 7 { 8 printf("I am a process!\n"); 9 sleep(1); 10 } 11 }make编译一下:
这里形成的myprocess就是可执行程序,编译形成二进制可执行文件,是文件,就在Linux的磁盘中存放。
./myprocess把它运行起来,此时它已然变成了一个进程:

所有系统提供的命令都是executable, x86-64下的可执行程序:
所以:./XXX本质就是让系统创建进程并运行,我们自己写的代码形成的可执行==系统命令==可执行文件。在Linux中运行的大部分执行操作,本质都是运行进程
查看系统当前所对应进程的详细详细:
ps axj就能查看到系统中所有启动的进程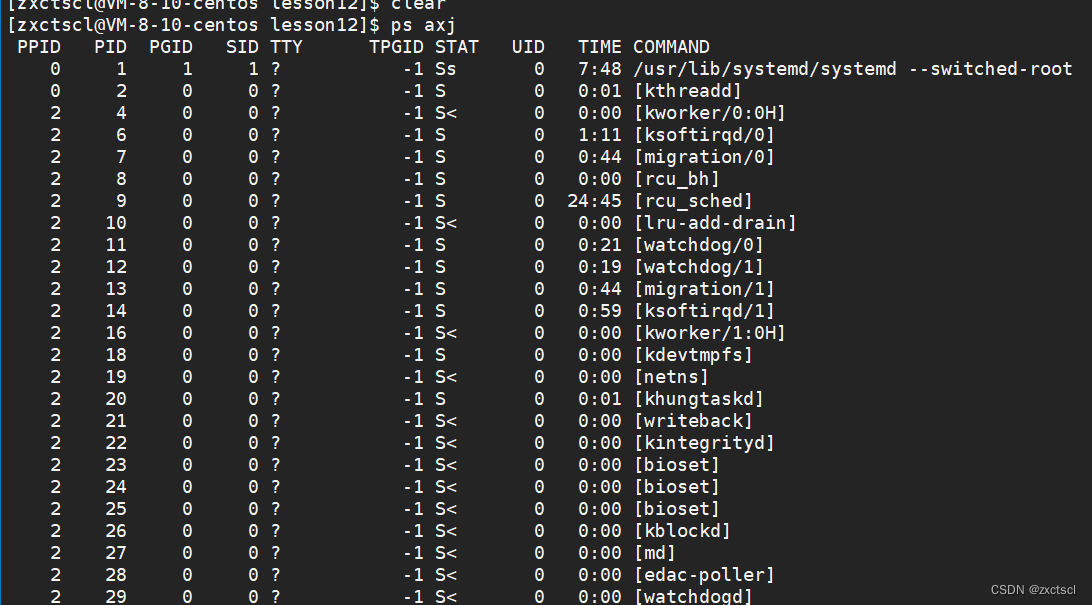
要想只查看到myprocess,就得使用命令:
ps axj | grep myprocess此时就出来了:
为什么会出现grep?
grep在过滤时,确实找到了myprocess,但是grep启动也变成了一个进程,事宜查的时候出来myprocess被查到了,grep本身也被查到了。
使用命令:
ps axj | head -1就可以知道第一行每一个部分的属性信息。
想要属性信息和上面的查询进程对应起来,就用&&把两条命令连接起来:
ps axj | head -1 && ps axj | grep myprocess这样就可以了:
每一个进程的都要有自己唯一的标识符,叫做进程pid
也就是说在task_struct本身内部有一个unsigned int pid。
一个进程怎么知道自己的pid?
task_struct是操作系统的内核数据结构,用户不能直接去访问来找到自己的pid信息,所以操作系统必须得提供系统调用,系统提供的是getpid: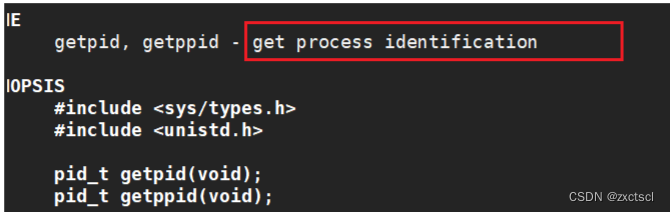
那么在代码里面加上查询pid的信息:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 int main() 7 { 8 pid_t id=getpid(); 9 10 while(1) 11 { 12 printf("I am a process,pid:%d\n",id); 13 sleep(1); 14 } 15 }编译运行之后:就看见
用系统来查一下,发现pid是一样的:

进程一直跑,可以用ctrl+c来终止进程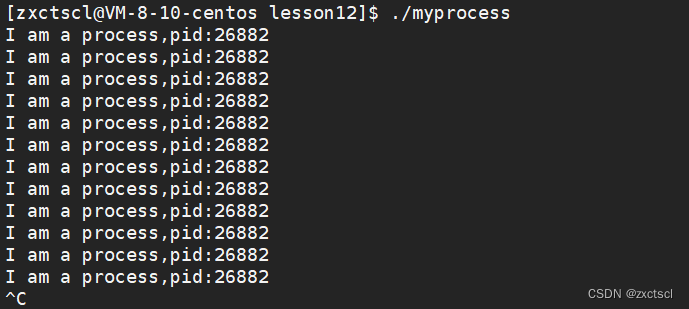
ctrl+c就是在用户层面终止进程
还有其他方法干掉进程吗?
用命令:kill -9+pid
来看个例子:
kill -9+pid可以直接杀掉进程
4.2 进程的创建方式
4.2.1 父子进程
pid_t getppid(void)获得当前进程的父进程id
在代码里面加上获取父进程ip的代码:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 int main() 7 { 8 pid_t id=getpid(); 9 pid_t parent=getppid(); 10 while(1) 11 { 12 printf("I am a process,pid:%d,ppid:%d\n",id,parent); 13 sleep(1); 14 } 15 }此时就能够查到ppid: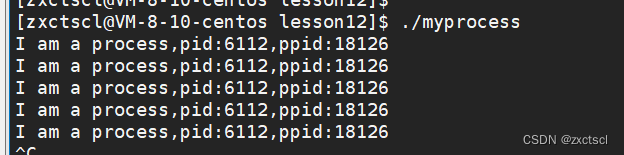
为了方便观察写了一个shell命令,每个一秒钟来周期性执行一下中间的命令:
while :;do ps axj | head -1 && ps axj | grep myprocess;sleep 1;done这样每个一秒就能查到当前进程的情况: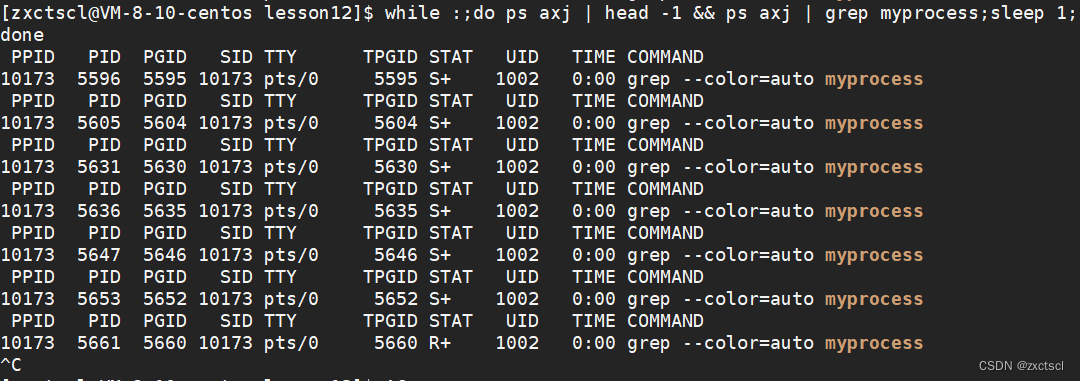
发现每一次启动进程的时候它的pid都不一样,但是它的父进程id都是一样的: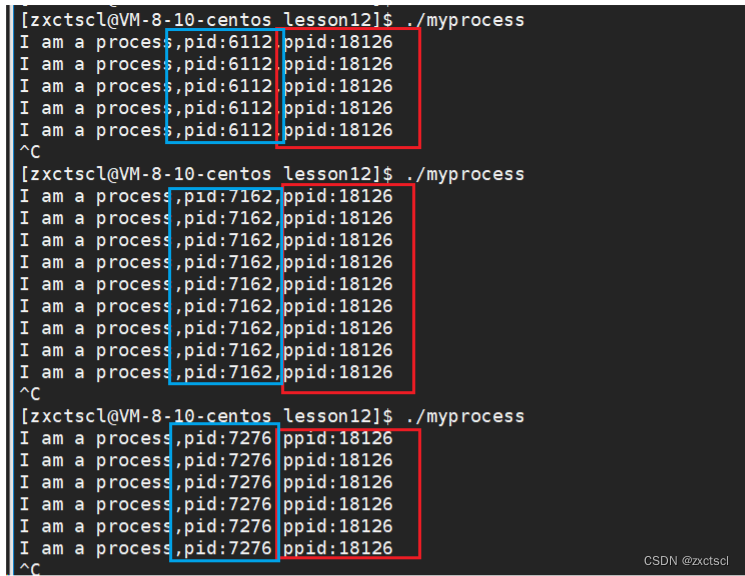
进程每次启动,对应的pid都是不一样的,是正常的。
查一下ppid:发现有bash
bash就是父进程,就是命令行解释器。
4.2.2 fork
创建进程,就得提供系统调用,用到的是fork: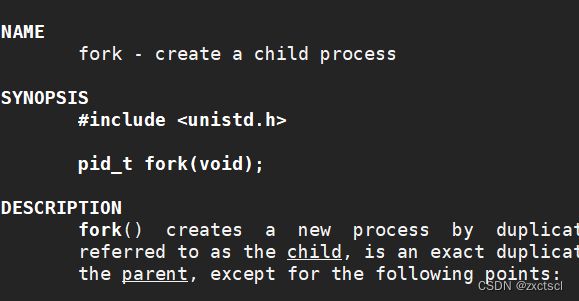
来简单先使用一下fork:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 int main() 7 { 8 printf("process is running,only me!\n"); 9 fork(); 10 printf("hello world\n"); 11 sleep(1); 12 13 }fork()执行完之后应该有两个执行流,默认各自执行后面的代码。
为了方便查看把含grep的信息去掉
while :;do ps axj | head -1 && ps axj | grep myprocess | grep -v grep;sleep 1;done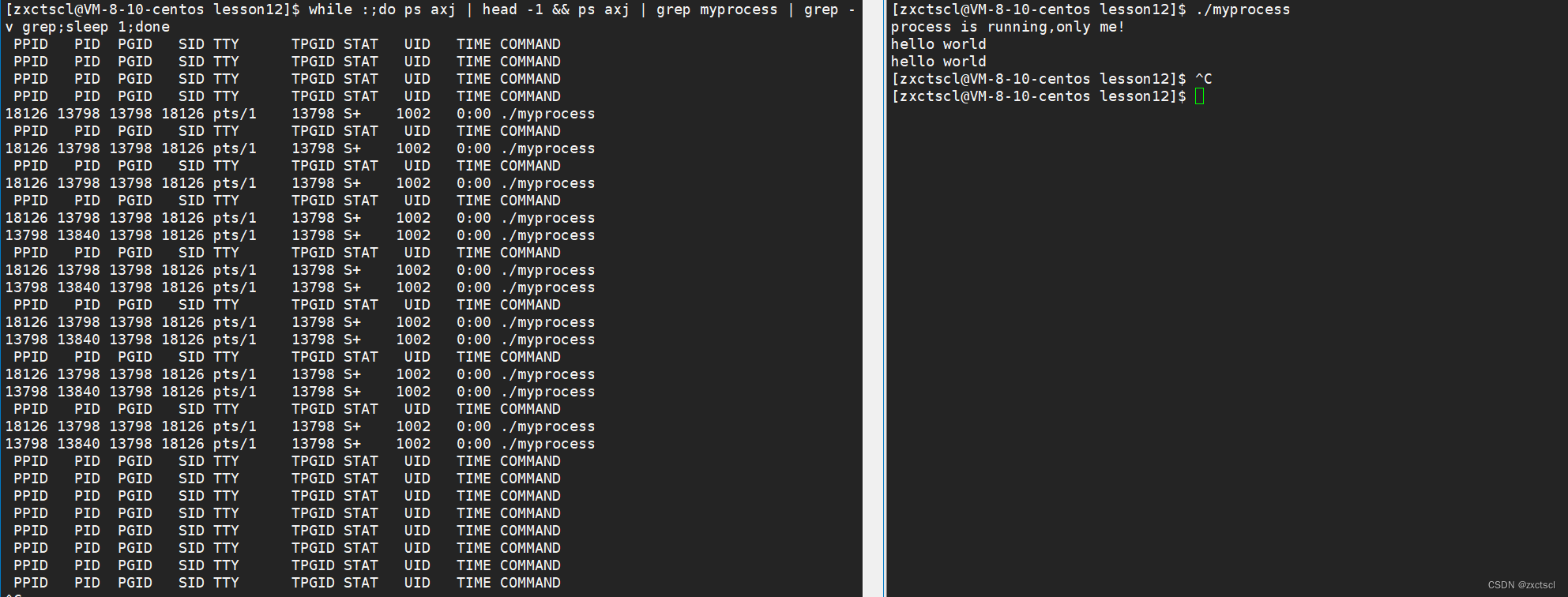
13840的父进程id是13798,他们两个是父子关系: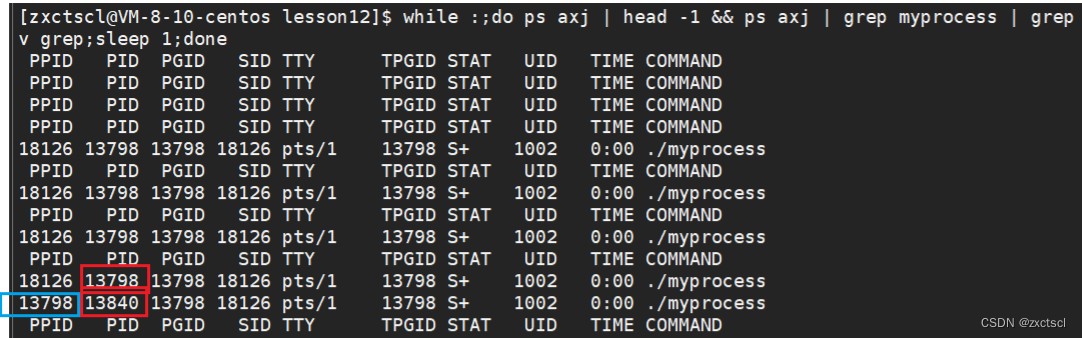
fork之后,父子代码共享
创建一个进程,本质就是系统中多一个进程,多一个进程,就是多一个内核task_struct,多了的进程有自己的代码和数据。
父进程的代码和数据是从磁盘来的,子进程的代码和数据默认情况下,继承父进程的代码和数据。

将代码重新修改,让代码在调用过程中显示出进程对应的pid和ppid:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 int main() 7 { 8 printf("process is running,only me!,pid:%d\n",getpid()); 9 sleep(3); 10 fork(); 11 printf("hello world,pid:%d,ppid:%d\n",getpid(),getppid()); 12 sleep(5); 13 14 }从显示结果来看,创建了子进程: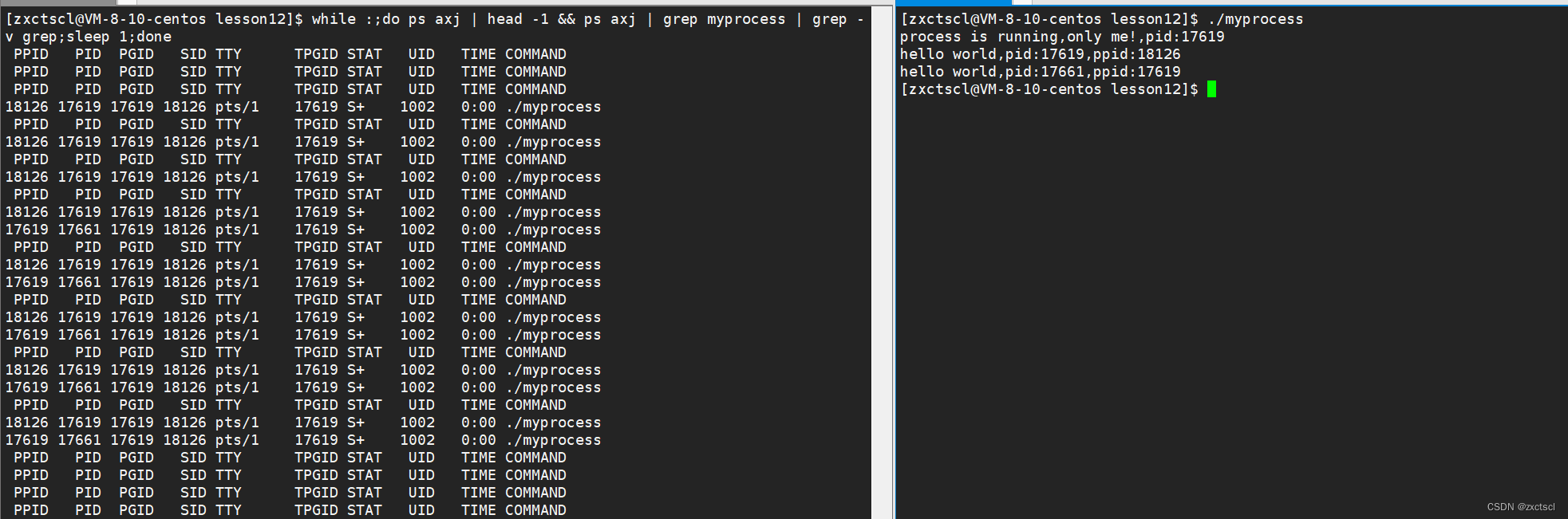

为什么要创建子进程?
主要是想要子进程执行和父进程不一样的代码。
fork:如果fork成功就返回子进程的pid给父进程,返回0给子进程;失败了就返回-1:
fork会返回两次,每次的返回值不一样。
想要父子进程执行不同的代码,把代码修改一下:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 int main() 7 { 8 printf("process is running,only me!,pid:%d\n",getpid()); 9 sleep(3); 10 pid_t id=fork(); 11 if(id==-1)return 1; 12 else if(id==0) 13 { 14 //child 15 while(1) 16 { 17 printf("id:%d,I am child process,pid:%d,ppid:%d\n",id,getpid(),getppid()); 18 sleep(1); 19 } 20 } 21 else 22 { 23 //parent 24 while(1) 25 { 26 printf("id:%d,I am parent process,pid:%d,ppid:%d\n",id,getpid(),getppid()); 27 sleep(2); 28 } 29 } 30 31 32 }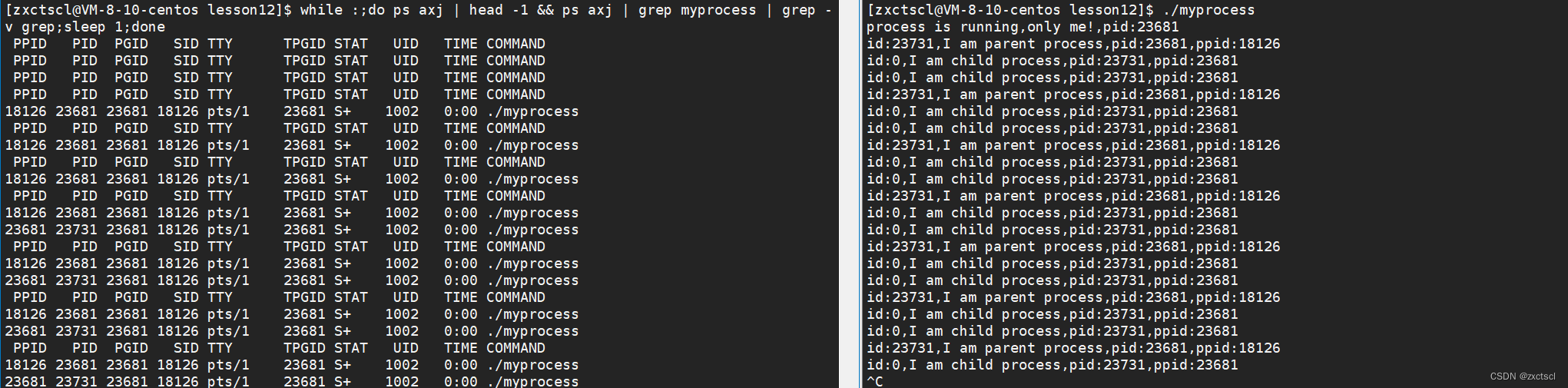

输出消息中返回值是0,就是子进程,刚好匹配:
fork之后的代码父子进程是共享的,只不过等于id=0是给子进程的,id=子进程pid是给父进程的。
只是做了判断,子进程才进入到满足条件的代码中;而父进程进入父进程有关代码中,从而实现了父子进程同时跑。
在之前学习的代码都是单进程,不可能有多个if里面的代码同时运行。
而这里是多进程,就会出现多个满足if条件的代码同时执行。
那么为什么同一个id,既是等于0又是大于0?
这个和虚拟地址空间有关系。进程具有独立性,而父子进程各自独立,所以它们有各自的pid,而代码是只读的,不能修改。而数据在父子进程上是分开的。
fork会有两个返回值,返回两次。
fork是操作系统提供的,当一个函数执行到return时候,函数的核心工作已经做完了。
那么说明fork的时候子进程就已经存在了。父进程运行一次执行一次return;子进程运行一次执行一次return。那么就会return两次。

单独kill掉父进程或者子进程,不会影响另一个的运行。
4.2.3 一次创建多个进程
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 #include<unistd.h> 5 6 void RunChild() 7 { 8 while(1) 9 { 10 printf("I am child process,pid:%d,ppid:%d\n",getpid(),getppid()); 11 } 12 } 13 int main() 14 { 15 const int num=5; 16 int i; 17 for(i=0;i<num;i++) 18 { 19 pid_t id=fork(); 20 if(id==0) 21 { 22 RunChild(); 23 } 24 sleep(1); 25 } 26 27 while(1) 28 { 29 printf("I am parent,pid:%d,ppid:%d\n",getpid(),getppid()); 30 } 31}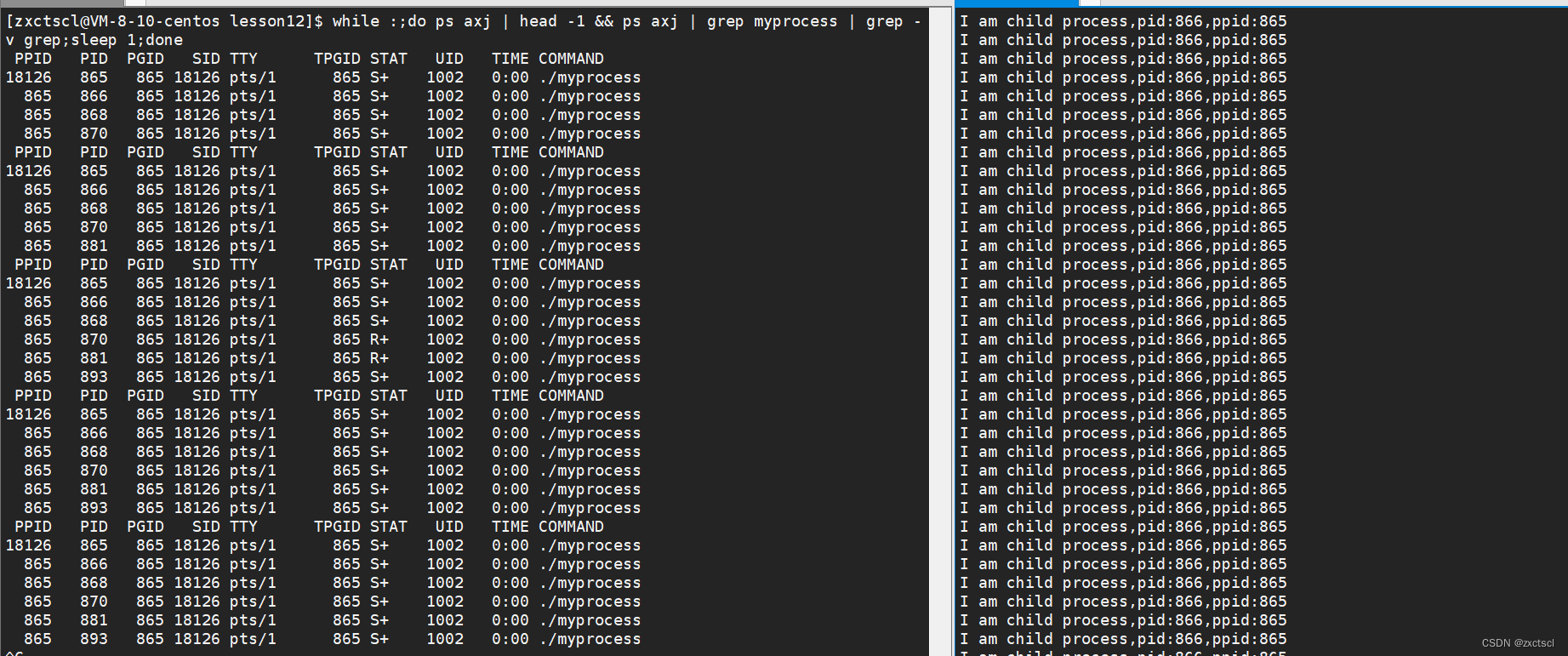
task_ struct内容分类:

查看进程:
进程的信息可以通过/proc系统文件夹查看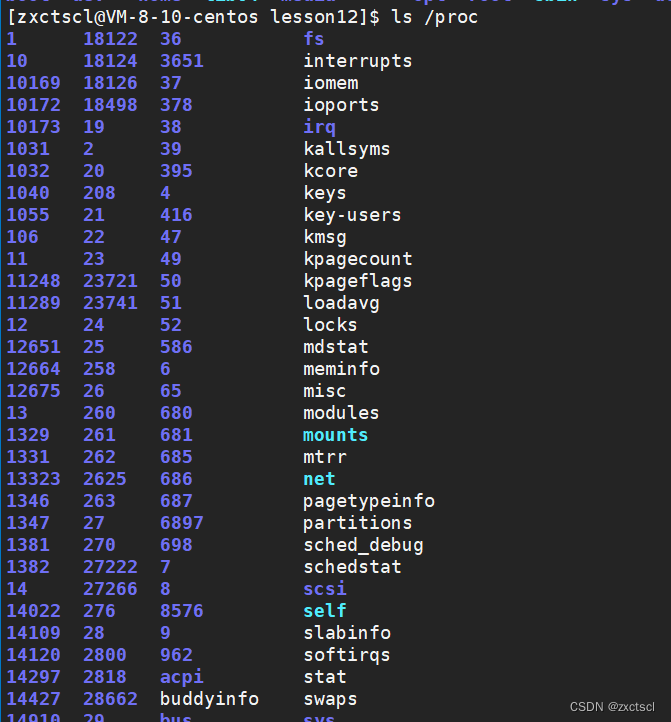

进程的pcb中会记录自己对应的可执行程序的路径。
每个进程在启动的时候,会记录自己当前在那个路径下启动,进程的当前路径
cwd:进程的当前路径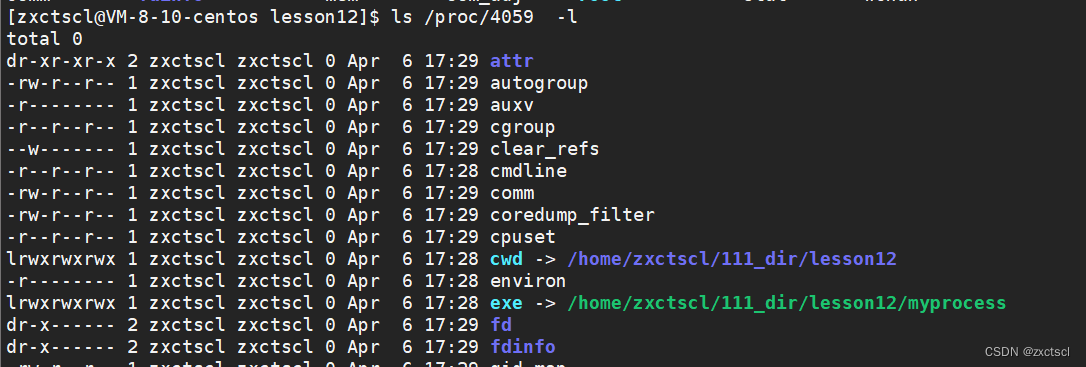
用pwd来验证一下:
哪个进程调用chdir函数,哪个进程就修改当前路径。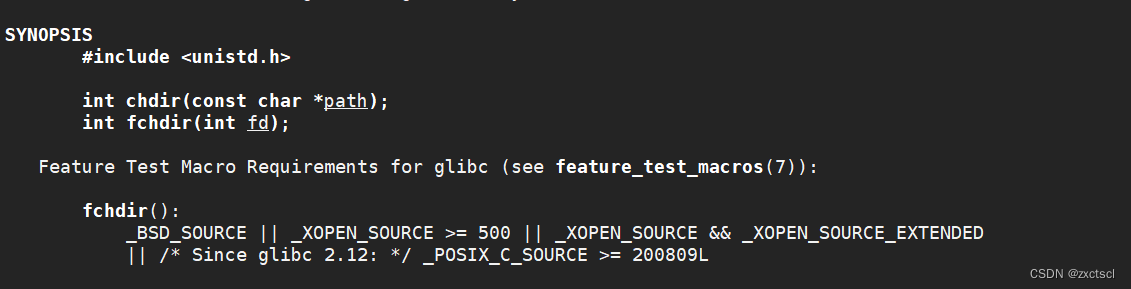
当前路径是:
用代码来改变一下当前创建文件的路径。
1 #include<stdio.h> 2 #include<sys/types.h> 3 #include<unistd.h> 4 5 6 int main() 7 { 8 chdir("/home/zxctscl/111_dir"); 9 FILE *fp=fopen("log.txt","w"); 10 (void)fp; 11 fclose(fp); 12 13 while(1) 14 { 15 printf("I am a process, pid:%d\n",getpid()); 16 sleep(1); 17 } 18 19 return 0; 20 }运行时候发现代码路径确实改变了:
当前进程的目录确实改变了: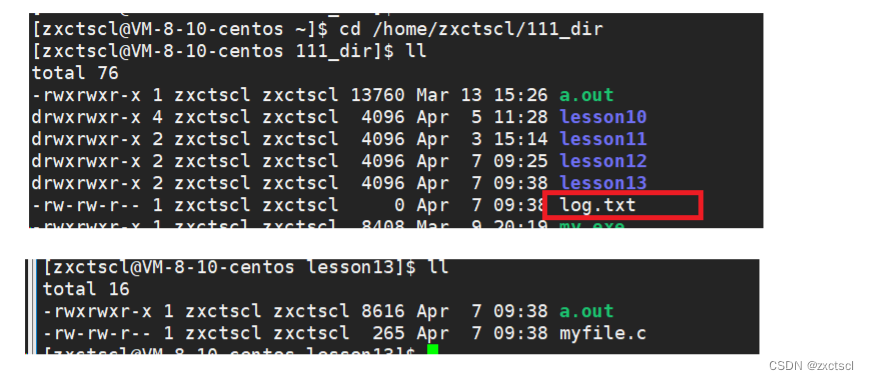
有问题请指出,大家一起进步!!!