更新时间;2024-3-24
【2024泰迪杯】C 题:竞赛论文的辅助自动评阅 Python 代码实现
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛 C 题:竞赛论文的辅助自动评阅
1 题目
一、问题背景
近年来我国各领域各层次学科竞赛百花齐放,层出不穷,学生参与度也越来越高。随着参赛队伍的增加,评阅论文的工作量急剧增加,这对评阅论文的人力要求也越来越大。因此引入机器辅助评阅成为竞赛主办方的现实需求。
在学术界,建立基于 AI 的学术论文自动评审模型已得到了许多研究者的关注。论文的自动评阅涉及多种传统的自然语言处理技术如文本分类、信息抽取、论辩挖掘等。近年来,随着深度学习和自然语言处理技术的不断发展,特别是以 GPT 为代表的大语言模型的出现,进一步促进了论文自动评阅技术的发展,使得利用 AI 进行文本的自动评阅变得越来越可行,逐步从实验室走向学校和更多组织机构,成为当前的技术热点。但是在特定领域实现论文自动评阅仍然存在很多挑战,需要利用预训练的大语言模型适配具体的应用场景来解决问题。
二、解决问题
1、构造论文质量特征
每个指标的分数范围为 0-10 分。
(1) 论文的完整性评价
对照赛题,比对竞赛论文中相关问题的章节或段落,对论文的完整性进行评价。评估竞赛论文是否能完整解答赛题,并给出评价论文完整性的技术手段和评分标准。
(2) 论文有无实质性工作
对照赛题评阅要点,查找竞赛论文中相关问题的章节或段落,考察论文是否就赛题问题做出了相关的研究。需给出相关的技术方法和评价标准。
(3) 摘要质量
摘要与内容的一致性评价。评价摘要是否如实反映正文的中心思想,即衡量内容摘要与正文的相关性、一致性。需给出摘要质量评价指标及其依据。
(4) 写作水平评价
评价文字流畅性、写作规范(图、表、摘要)性和论文逻辑性。在传统论文评分(essay scoring)技术基础上,从文本通顺、立意分析、篇章结构、论证挖掘等维度进行探索,挖掘文本蕴含的论点论据、论证关系、结构信息,结合论证挖掘角度评估论文一致性、逻辑性,综合给出论文写作水平的评分。
2、竞赛论文辅助评分
根据上面构造的各项评分指标建立论文的整体评分模型,根据提供的论文集,按照十分制给出每篇论文的综合评分,将结果保存到 result.xlsx 文件中。综合评分结果要求满足如下限制条件:
8-10 分的不超过 3%;
6-7 分的不少于 10%,6-10 分不超过 15%;
4-5 分不少于 20%,4-10 分不超过 35%;
其他的为 0-3 分。
一般而言,在综合评分中论文的完整性和写作水平的分数占比之和不超过 40%。
注 1 若使用预训练的大语言模型完成赛题任务,需要给出实现过程,如提问时使用的提示词及如何进一步利用提问结果。
注 2 自 2022 年底 ChatGPT 发布以来,大语言模型的能力突飞猛进,可考虑将大语言模型技术应用于本次竞赛。一方面可考虑使用 ChatGPT、讯飞星火、文心一言、智谱清言等国内外大模型接口,基于大语言模型设计算法和构建合适的提示词等,辅助完成本赛题的任务。另一方面也可考虑微调训练开源大语言模型,例如 ChatGLM、Qwen、Baichuan 等系列开源大语言模型,设计训练任务,让知识赋能大语言模型以更好地解决问题。
三、附件说明
附件 1 为竞赛论文集,附件 2 为赛题和参考评阅标准,附件 3 为 result.xlsx 的结果模板。
表 1 result.xlsx 样例
| 论文编号 | 完整性 | 实质性 | 摘要 | 写作水平 | 综合评分 |
|---|---|---|---|---|---|
| C001 | …… | …… | …… | …… | …… |
2 问题分析
2.1 问题一
论文的完整性评价。
使用文本分析技术,如 PdfMiner是一个功能强大的PDF处理工具,可以根据实际需要进一步对提取的文本内容进行分析,识别论文结构中与赛题相关的章节或段落,比如问题陈述、模型建立、模型求解、结果分析等。评估论文结构的逻辑完整性和条理性,查看论文是否按照标准的学术论文结构进行组织,并对每个部分的逻辑顺序进行评估。2.2 问题二
评估论文是否就赛题问题做出了相关的研究,则使用自然语言处理的方法,抽取论文每个段落的关键词,与赛题给出的关键词进行对比评分。
首先使用自然语言处理的方法,如分词、词性标注和句法分析,将论文分成段落或句子。 然后采用主题建模方法,如Latent Dirichlet Allocation (LDA)或其它话题模型,从文本中识别与赛题相关的主题或话题,以确定哪些部分涉及与赛题相关的内容。结合语义分析技术,如词向量模型或深度学习模型,量化评估问题陈述部分是否包含了关键信息,例如问题的关键词、目标和约束条件。2.3 问题三
衡量论文摘要与正文的相关性和一致性,并对摘要进行质量评价打分,可以借助文本相似度、主题模型、关键词抽取和语义分析等方法。
(1)文本相似度分析
利用词袋模型、TF-IDF、Word2Vec或BERT等方法,计算论文摘要与正文之间的相似度。可以采用余弦相似度或Jaccard相似度等指标。如果摘要与正文内容相关性高,相似度分数会相应增加。(2)主题模型分析
使用主题模型如Latent Dirichlet Allocation (LDA)或潜在语义分析(LSA),比较摘要中的主题与正文中的主题,以评估摘要是否涵盖了论文的核心主题。。
(3)关键词抽取与比对
使用关键词抽取技术,比较摘要中提取的关键词和正文中的关键词,检查它们的一致性和覆盖度。分析摘要中提取的关键词是否在正文中有对应的论述。
(4)语义分析与信息覆盖度
利用自然语言处理技术,分析摘要中涉及的信息在正文中的覆盖程度,包括实体识别、概念匹配等。分析摘要中涉及的重要信息在正文中的覆盖情况。
2.4 问题四
评价文字流畅性、写作规范和论文逻辑性,涉及到文本通顺、立意分析、篇章结构、论证挖掘等多个维度。传统论文评分技术结合了自然语言处理和机器学习技术进行综合评估,下面是一些技术细节、评价指标及其依据:
(1)文本通顺性评价
使用使用句法分析器,如StanfordNLP、Spacy等,对句子进行语法分析,识别句子中的主语、谓语、宾语等成分,以及句法结构关系。检测句子内部的语法结构是否合理。应用词义消歧、语义角色标注等技术,检测句子之间的逻辑衔接和连贯性;
(2)写作规范性评价:
使用Python的库NLTK或spaCy,来对论文中的图表标注进行文本解析和识别。结合正则表达式和规则匹配,检测图表标题、标签、图表内容等是否符合规范格式。可以使用正则表达式来匹配特定格式的图表标题和标签。
(3)立意分析评价:
应用聚类分析和关键词抽取,分析文本中表达的核心观点和立意。
(4)篇章结构
使用词性标注和文本匹配技术,识别文本中的桥接词或过渡性词语,以评估段落间的连接和衔接情况,来表示篇章之间的逻辑关系。
(5)论证挖掘评价
利用ChatGPT、讯飞星火、文心一言等大模型分析论文中的论点、论据、论证关系,评估其合理性和逻辑性。
3 Python代码实现
3.1 问题一
使用PdfMiner提取PDF文档中的章节和段落信息,并打分
import refrom pdfminer.high_level import extract_text# 读取PDF文件内容def extract_pdf_text(pdf_path): return extract_text(pdf_path)# 识别标题结构def recognize_structure(text, titles): recognized_titles = [title for title in titles if re.search(title, text, re.IGNORECASE)] return recognized_titles# 评估结构的逻辑完整性和条理性def evaluate_structure(recognized_titles, expected_titles): if recognized_titles == expected_titles: logic_score = 1 else: logic_score = round(len(recognized_titles) / len(expected_titles),1) return logic_scorepdf_path = "data/B20104870036.pdf" expected_titles = ["摘要", "目录", "问题重述", "假设条件", "符号说明", "模型建立", "模型求解", "模型检验", "结果分析", "结论", "参考文献", "附录"]text = extract_pdf_text(pdf_path)recognized_titles = recognize_structure(text, expected_titles)score = evaluate_structure(recognized_titles, expected_titles)# 0到1之间,如果要十分制,乘以10即可print(f"论文结构的逻辑完整性和条理性得分: {score:.2f}")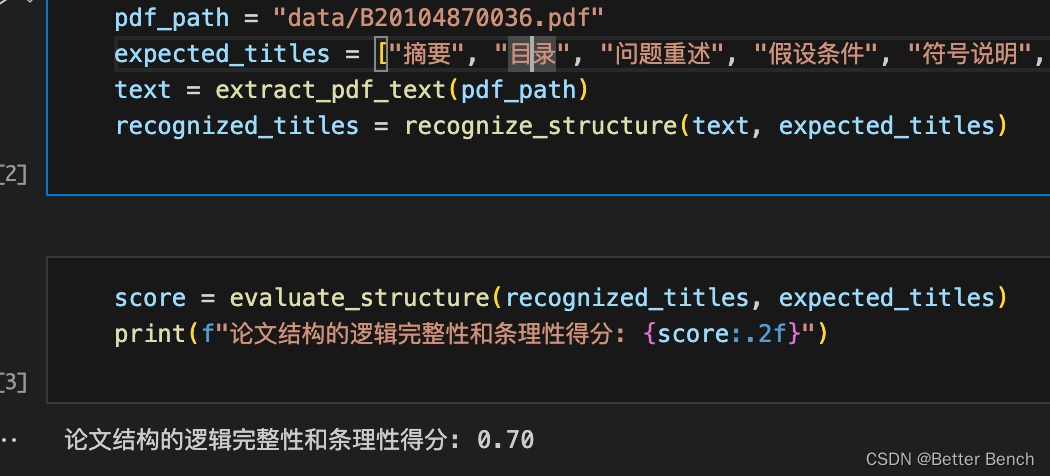
3.2 问题二
import refrom pdfminer.high_level import extract_textimport spacyimport gensimimport numpy as npimport jiebafrom gensim.parsing.preprocessing import STOPWORDSimport os# 加载中文模块nlp = spacy.load("zh_core_web_sm")# 读取PDF文件内容def extract_pdf_text(pdf_path): return extract_text(pdf_path)# 将文本分成段落或句子def segment_text(text): ...略 return segments# 从文本中提取赛题相关的关键词def extract_keywords(segments,stop_keywords): ...略 return keywords# 从文本中识别与赛题相关的主题或话题def evaluate_problem_statement(topics, keywords): # 输出每个主题的关键词 topic_words = [] for topic in topics: topic_num = topic[0] topic_keywords = [word[0] for word in topic[1]] topic_words.extend(topic_keywords) print(f"主题{topic_num+1}的关键词:{topic_keywords}") topic_coverage = len(set(keywords) & set(topic_words)) / len(keywords) return round(topic_coverage,2) problem_pdf_path = "data/2020华为杯B题题目.pdf" # 赛题题目paper_pdf_path = "data/B20104870036.pdf" # 论文# 读取文件内容problem_text = extract_pdf_text(problem_pdf_path)paper_text = extract_pdf_text(paper_pdf_path)# 将文本分成段落或句子problem_segments = segment_text(problem_text)# 使用哈工大中文停用词库chinese_stopwords = [line.strip() for line in open('data/hit_stopwords.txt', encoding='utf-8').readlines()]# 去除中文停用词和符号filtered_paper_text = [word for word in jieba.cut(paper_text) if word not in chinese_stopwords and word.strip()]# 从文本中提取赛题相关的关键词problem_keywords = extract_keywords(problem_segments,chinese_stopwords)dict_file = 'data/custom_dict.txt'if not os.path.exists(dict_file): # 将自定义词典列表写入文件 with open(dict_file, 'w', encoding='utf-8') as f: for word in problem_keywords: f.write(word + ' 10 n' + '\n') # 把题目中的关键词,加入自定义词典jieba.load_userdict(dict_file)# 创建并训练LDA主题模型num_topic = 10paper_dictionary = gensim.corpora.Dictionary([paper_segment.lower().split() for paper_segment in filtered_paper_text])paper_bow_corpus = [paper_dictionary.doc2bow(segment.lower().split()) for segment in filtered_paper_text]lda_model = gensim.models.LdaModel(paper_bow_corpus, id2word=paper_dictionary, num_topics=num_topic, passes=10)# 获取主题关键词topics = lda_model.show_topics(num_topics=num_topic, num_words=20, formatted=False)# 从文本中识别与赛题相关的主题或话题# 0到1之间,如果要十分制,乘以10即可problem_statement_score = evaluate_problem_statement(topics, problem_keywords)print(f"论文相关性得分: {problem_statement_score}")
3.3 三、四
请下载完整资料
4 完整资料
