虚拟机Ubuntu22.04 Hadoop集群安装和搭建(全面详细的过程)
环境配置安装安装JDK安装Hadoop 三台虚拟机设置克隆三台虚拟机设置静态IP修改虚拟机hostssh免密登录关闭防火墙 Hadoop配置core-site.xmlhdfs-site.xmlyarn-site.xmlmapred-site.xmlworkers设置hadoop集群用户权限xsync分发给其他虚拟机格式化namenode配置 启动集群测试ref
环境配置安装
| 项目 | Value |
|---|---|
| linux | ubuntu22.04.3 |
| java | 1.8_202 |
| hadoop | 3.2.4 |
| vmware workstation | 16.2.3 |
安装JDK
在vmware workstation安装好ubuntu系统后,下载jdk包。
Java 的官网下载链接:https://www.oracle.com/java/technologies/downloads/
Java 华为云镜像:https://repo.huaweicloud.com/java/jdk/
下载后解压到自定义文件夹
sudo tar -zxvf jdk-8u202-linux-x64.tar.gz -C /opt设置环境变量:
sudo gedit /etc/profile添加java路径
export JAVA_HOME=/opt/jdk1.8.0_202export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=$PATH:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin激活环境后,查看java版本
source /etc/profile # 激活环境java -version # 查看java版本java version "1.8.0_202"Java(TM) SE Runtime Environment (build 1.8.0_202-b08)Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)配置软链接
sudo ln -s /opt/jdk1.8.0_202/bin/java /bin/javajava 安装完成
安装Hadoop
下载后解压到自定义文件夹
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt为 hadoop 配置 java 环境,打开hadoop安装目录的etc/hadoop/hadoop-env.sh文件
sudo gedit /opt/hadoop-3.2.4/etc/hadoop/hadoop-env.sh找到 JAVA_HOME, 写入自己的路径
export JAVA_HOME=/opt/jdk1.8.0_202打开hadoop安装目录,查看是否安装成功
/opt/hadoop-3.2.4/bin/hadoop versionHadoop 3.2.4Source code repository Unknown -r 7e5d9983b388e372fe640f21f048f2f2ae6e9ebaCompiled by ubuntu on 2022-07-12T11:58ZCompiled with protoc 2.5.0From source with checksum ee031c16fe785bbb35252c749418712This command was run using /opt/hadoop-3.2.4/share/hadoop/common/hadoop-common-3.2.4.jar三台虚拟机设置
克隆三台虚拟机
打开vmware的library面板
右键需要复制的虚拟机,选择 management->clone

一直下一步,等待完成,一直复制两台虚拟机hadoop101,hadoop102。
设置静态IP
三台虚拟机之间通过ip通信,所以要固定三台机器静态ip,以便相互访问
查看虚拟机的虚拟网卡,查看NAT模式配置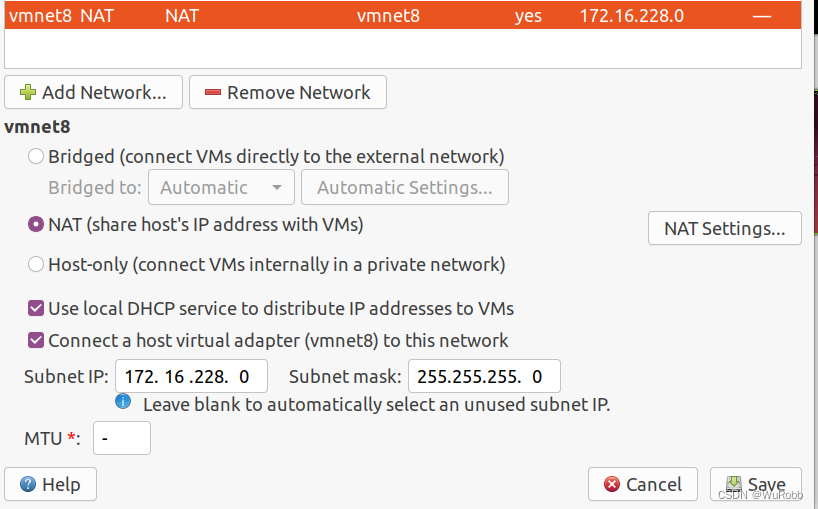
查看NAT Settings
记录网关地址Gateway IP
打开网卡配置文件
sudo gedit /etc/netplan/01-network-manager-all.yaml自定义设置addresses和routes
# Let NetworkManager manage all devices on this network: renderer: NetworkManager ethernets: ens33: addresses: # 根据自己的IP地址更改下边的IP即可 - 172.16.228.100/24 nameservers: # 域名解析器 addresses: [4.2.2.2, 8.8.8.8] routes: - to: default # 网关,上一步记录的Gateway IP via: 172.16.228.2 version: 2 # 备用# 根据自己的IP地址更改下边的IP即可# IP地址# IPADDR=172.16.228.101# 网关# GATEWAY=172.16.228.2# 域名解析器# DNS1=4.2.2.2# DNS2=8.8.8.8保存重启网络服务
sudo netplan apply查看ip,设置完成
其余两台虚拟机也设置好静态ip,并将三个ip记录。
修改虚拟机host
修改hostname和hosts便于通信
sudo gedit /etc/hostname将三台虚拟机hostname分别设置为hadoop100、hadoop101、hadoop102
sudo gedit /etc/hosts在后面添加各自设置的静态ip
172.16.228.100 hadoop100172.16.228.101 hadoop101172.16.228.102 hadoop102分别在三台虚拟机测试能否ping通
ping hadoop100ping hadoop101ping hadoop102ssh免密登录
为三台机器添加ssh密钥,实现远程无密码访问
sudo apt-get install openssh-server #安装服务,一路回车 sudo /etc/init.d/ssh restart #启动服务 sudo ufw disable #关闭防火墙 在节点生成SSH公钥,并分发给其他机器
ssh localhostcd ~/.ssh rm ./id_rsa* ssh-keygen -t rsa 生成密钥

分发给节点,根据提示输入虚拟机密码
ssh-copy-id hadoop100
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh hadoop100 测试是否分发成功。
关闭防火墙
systemctl stop firewalld.service Hadoop配置
打开hadoop安装目录,进入/etc/hadoop路径,找到配置文件,并按照如下配置
| hadoop100 | hadoop101 | hadoop102 | |
|---|---|---|---|
| HDFS | DataNode NameNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager |
core-site.xml
<configuration><!-- 指定Name Node的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop100:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-3.2.4/data</value></property><property><!-- 指定hadoop客户端用户名 --><name>hadoop.http.staticuser.user</name><value>hadoop</value></property></configuration>hdfs-site.xml
<configuration> <property> <name>dfs.namenode.http-address</name> <value>hadoop100:9870</value> </property> <!-- 2nn web端访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop102:9868</value> </property></configuration>yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> <description>resourcemanager</description> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME </value> </property> <!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property> <!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://hadoop100:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为 7 天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- mapreduce 运行环境,路径可在终端输入 hadoop classpath 找到--><property> <name>yarn.app.mapreduce.am.env</name> <value> HADOOP_MAPRED_HOME=/opt/hadoop-3.2.4/etc/hadoop:/opt/hadoop-3.2.4/share/hadoop/common/lib/*:/opt/hadoop-3.2.4/share/hadoop/common/*:/opt/hadoop-3.2.4/share/hadoop/hdfs:/opt/hadoop-3.2.4/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.4/share/hadoop/hdfs/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/*:/opt/hadoop-3.2.4/share/hadoop/yarn:/opt/hadoop-3.2.4/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.4/share/hadoop/yarn/* </value></property><property> <name>mapreduce.map.env</name> <value> HADOOP_MAPRED_HOME=/opt/hadoop-3.2.4/etc/hadoop:/opt/hadoop-3.2.4/share/hadoop/common/lib/*:/opt/hadoop-3.2.4/share/hadoop/common/*:/opt/hadoop-3.2.4/share/hadoop/hdfs:/opt/hadoop-3.2.4/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.4/share/hadoop/hdfs/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/*:/opt/hadoop-3.2.4/share/hadoop/yarn:/opt/hadoop-3.2.4/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.4/share/hadoop/yarn/* </value></property><property> <name>mapreduce.reduce.env</name> <value> HADOOP_MAPRED_HOME=/opt/hadoop-3.2.4/etc/hadoop:/opt/hadoop-3.2.4/share/hadoop/common/lib/*:/opt/hadoop-3.2.4/share/hadoop/common/*:/opt/hadoop-3.2.4/share/hadoop/hdfs:/opt/hadoop-3.2.4/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.4/share/hadoop/hdfs/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.4/share/hadoop/mapreduce/*:/opt/hadoop-3.2.4/share/hadoop/yarn:/opt/hadoop-3.2.4/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.4/share/hadoop/yarn/* </value></property></configuration>workers
hadoop100hadoop101hadoop102设置hadoop集群用户权限
sudo gedit /etc/profile添加
export HDFS_NAMENODE_USER=hadoopexport HDFS_DATANODE_USER=hadoopexport HDFS_SECONDARYNAMENODE_USER=hadoopexport YARN_RESOURCEMANAGER_USER=hadoopexport YARN_NODEMANAGER_USER=hadoop更新配置
source /etc/profilexsync分发给其他虚拟机
cd /opt/jdk1.8.0_202/bin # 该目录创建xsync脚本,可自定义到系统任何环境目录中sudo gedit xsync编写脚本
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]then echo Not Enough Arguement! exit;fi#2. 遍历集群所有机器for host in hadoop100 hadoop101 hadoop102do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi donedone设置执行权限
sudo chmod -R 777 xsync分发hadoop配置,只分发配置文件,其余文件不同虚拟机有自己id不要修改。
xsync /opt/hadoop-3.2.4/etc/hadoop格式化namenode配置
namenode节点会产生node id,需要在namenode机器上格式化配置,这里是hadoop100。
/opt/hadoop-3.2.4/bin/hdfs namenode -format 启动集群
在hadoop100上启动dfs
hadoop@hadoop100:~$ /opt/hadoop-3.2.4/sbin/start-dfs.sh
在hadoop101上启动yarn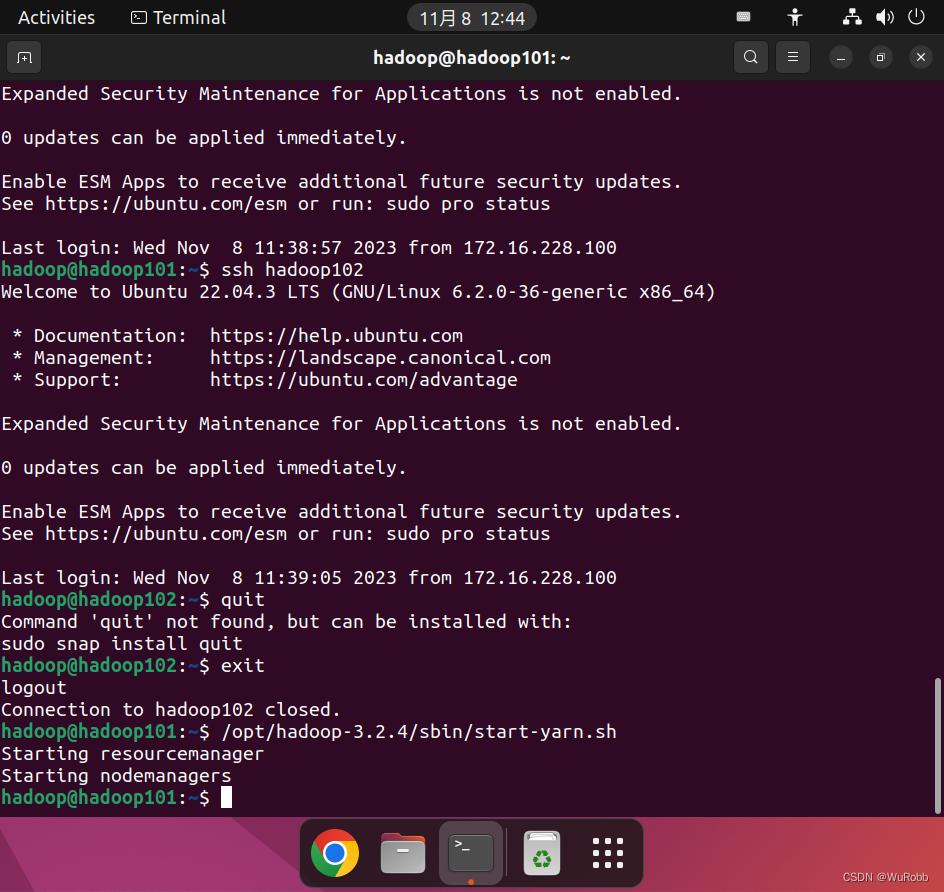
分别 在三台机器输入上查看hadoop进程
jpshadoop100
hadoop101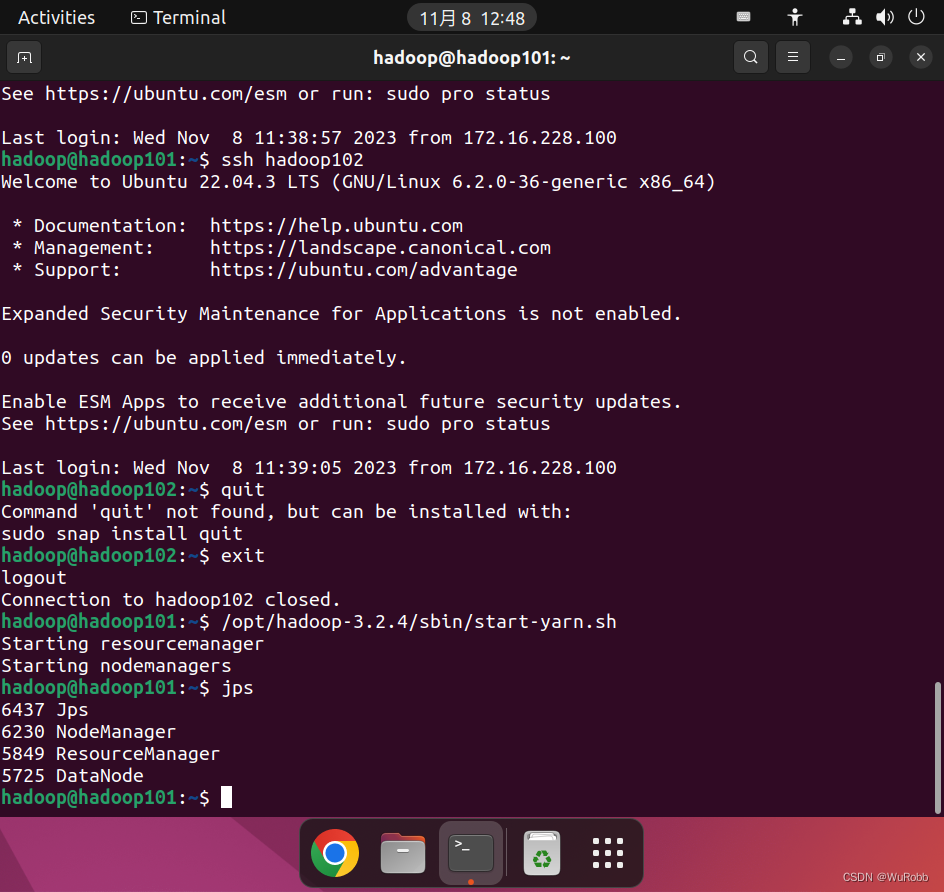
hadoop102
配置完成
测试
在hadoop100上打开hadoop:9870
hadoop100上传文件到集群
hadoop@hadoop100:~$ /opt/hadoop-3.2.4/bin/hadoop fs -mkdir /hadoop100_test查看hdfs 网址看到文件夹已经上传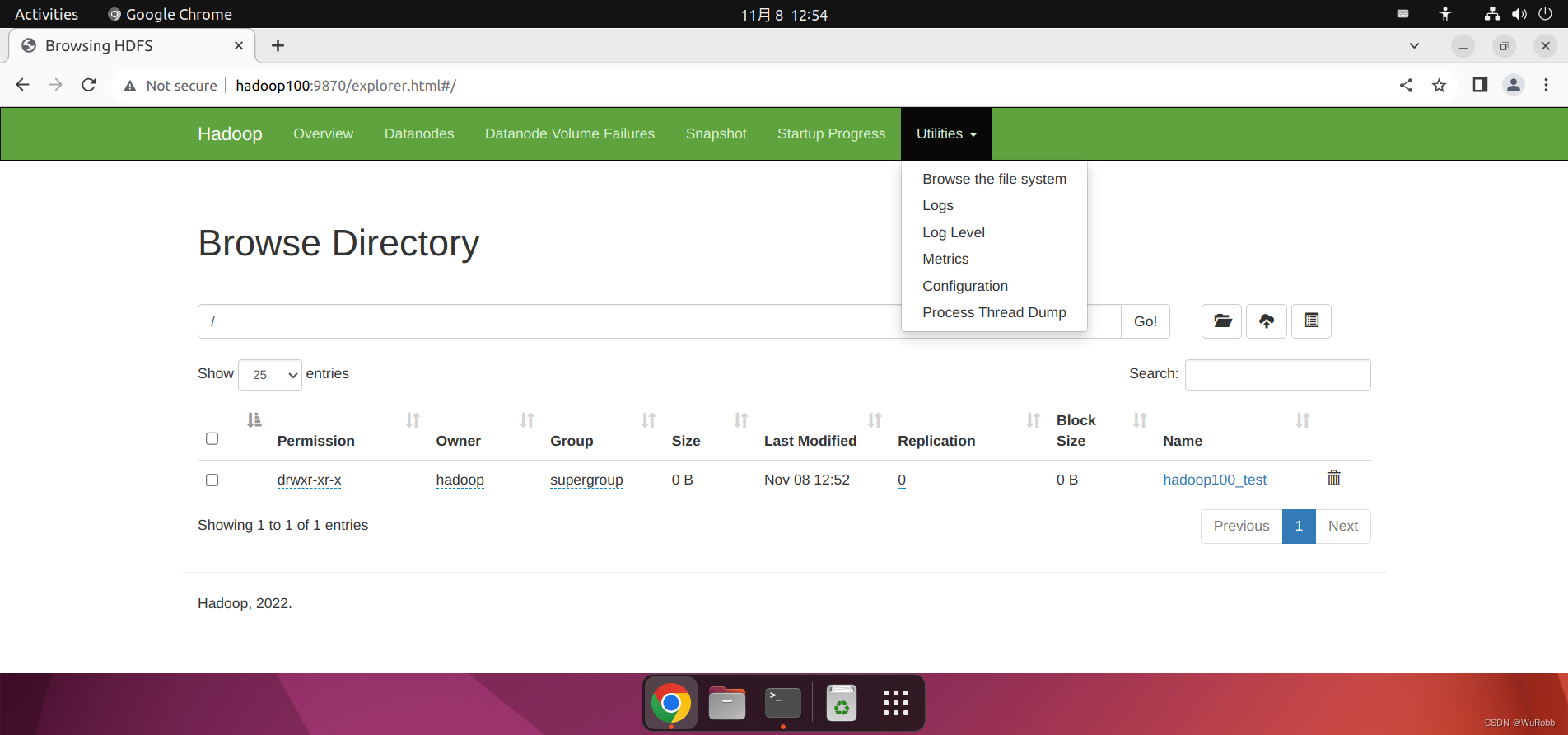
ref
尚硅谷大数据教程:https://www.bilibili.com/video/BV1Qp4y1n7EN