hi~
在上一篇,我们成功搭建了本地知识库+大模型的完全体!
在知识星球收到很多朋友的打卡,有各种报错差点崩溃的,也有看到部署成功,开心得跳起来的!
除了自用,还有星球朋友学会搭建,成功接到商单(听说单子还不小)!
不管怎样,酸甜苦辣,总算把它部署了下来,动起手来,排错的过程,其实成长非常快的!只是,小胖最近给小朋友远程,好像变得有点emo!
做完这个系列,雄哥还有更迫切的三个重要事项跟进!
①医疗项目的落地 ②分层自治Agent ③NLP知识框架项目
所以会更得特别快,如果你搞不定,马上联系小胖吧!
今天继续!
跟着雄哥动手,由浅到深,把知识库搭建出来吧!
记得吧?整体项目是这样的!
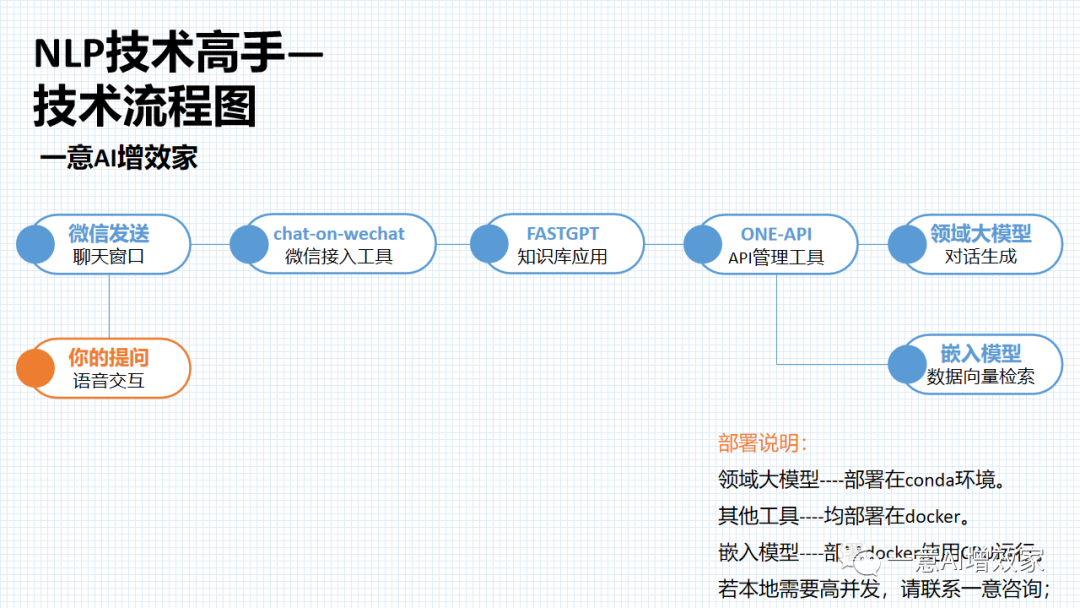
我们在纯本地的环境搭建,涉及垂类大模型+嵌入模型的部署、docker部署,都搞掂后!
使用知识库应用去搭建本地私有的知识库!
现在市场上已有大量的知识库/文档对话产品了,学会了这个部署,你基本了解到整个企业知识库部署的过程!内容如下:
day16:动手本地部署fastgpt知识库应用【已更新】
day17:动手本地部署ONE-API管理工具,与知识库打通!【已更新】
day18:与知识库对话!部署Qwen-7B/14B,用API接入知识库!【已更新】
day19:与知识库对话!部署ChatGLM3-6B,用API接入知识库!【已更新】
day20:本地部署M3e嵌入模型!接入知识库,完全体!大功告成!【已更新】
day21:快速上手!3分钟动手搭建私有的知识库!【已更新】
day22:进阶!三种数据处理办法,提高知识库性能!【本篇】
day23:进阶!知识库可视化高级编排!实现联网+外部API+插件!
day24:进阶!自定义内容,不该说的一句不说,只聊指定内容!
day25:按部门/学科,建立知识库并分发给对应部门使用
一边做一边看大家反馈,有不清楚的,雄哥再补充!
ok!人的专注力只有10分钟!那,话不多说!
本篇在win11系统完成,需要docker+WSL子系统(非wsl不稳定)!
星球的伙伴学完【7天精通docker】,可以直接上手!
还没来得及学的,可以在星球先学!
点击申请加入知识星球 https://t.zsxq.com/15XR5BKhd
https://t.zsxq.com/15XR5BKhd
如果你还没加星球,那你一定要加啦!
整个过程非常的简单!
① 知识库是如何与大模型一起工作的?
② 三种数据处理方法有什么不同
第一部分:知识库与大模型的关系
我们搭好了知识库,很多伙伴,还不是很清楚它是怎么工作的!
也有朋友问!为什么要搭建Qwen?为什么搭建m3e嵌入模型?
都有什么用?
我们要提升知识库的准确率+性能,必须要弄明白以上!
当然,如果你仔细学习过知识星球的langchain系列,直接跳过!
我们的整个过程,有对话、知识库训练两种方式!
看下图,非常清楚,就不介绍了!今天我们学知识库训练!
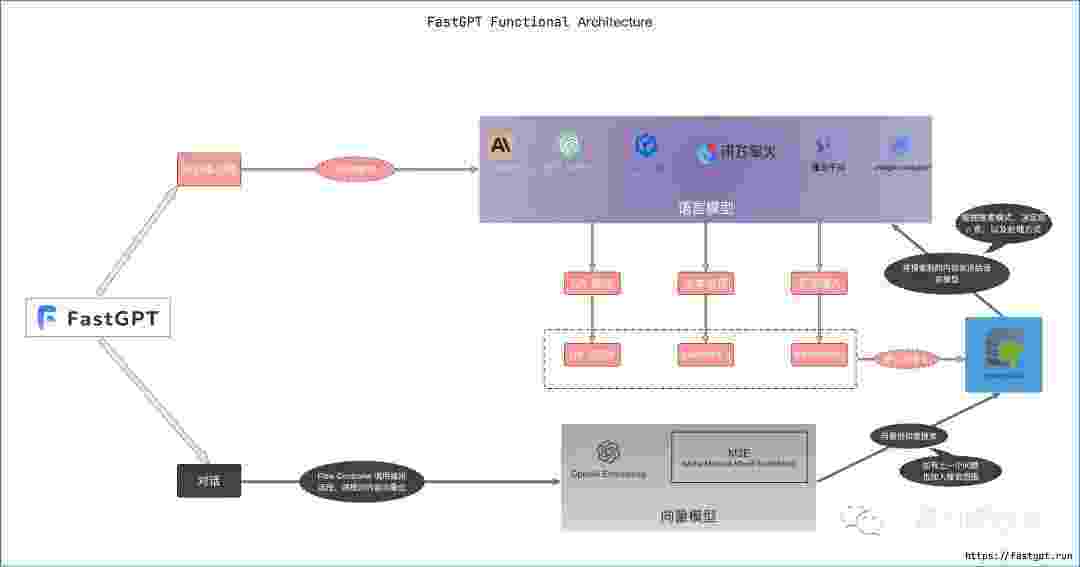
第二部分:三种数据处理方式
现在开始!把qwen大模型+docker启动!跟着雄哥动起手来!
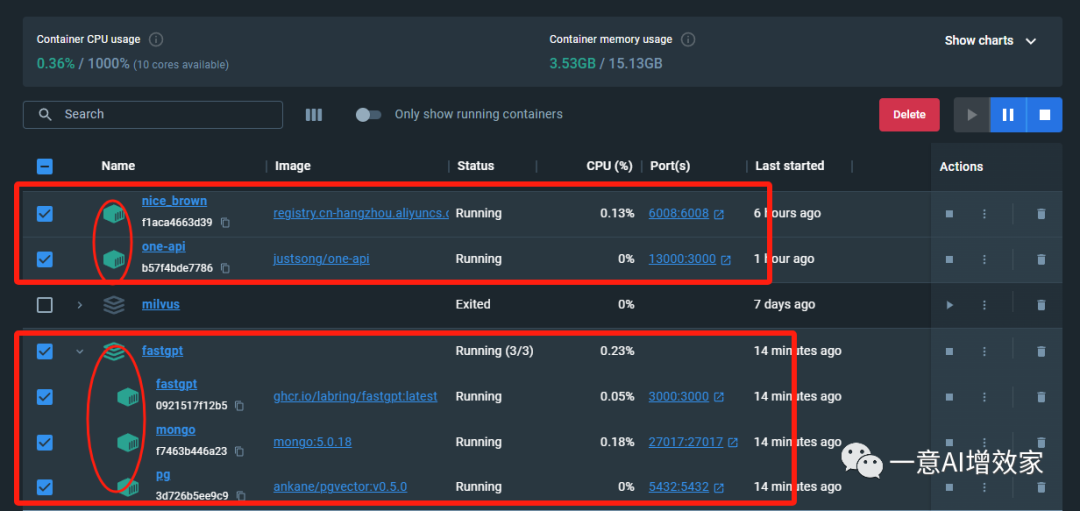
登录到fastgpt后台!具体登录方法我不说了,之前都说了N次!
先新建一个知识库吧!
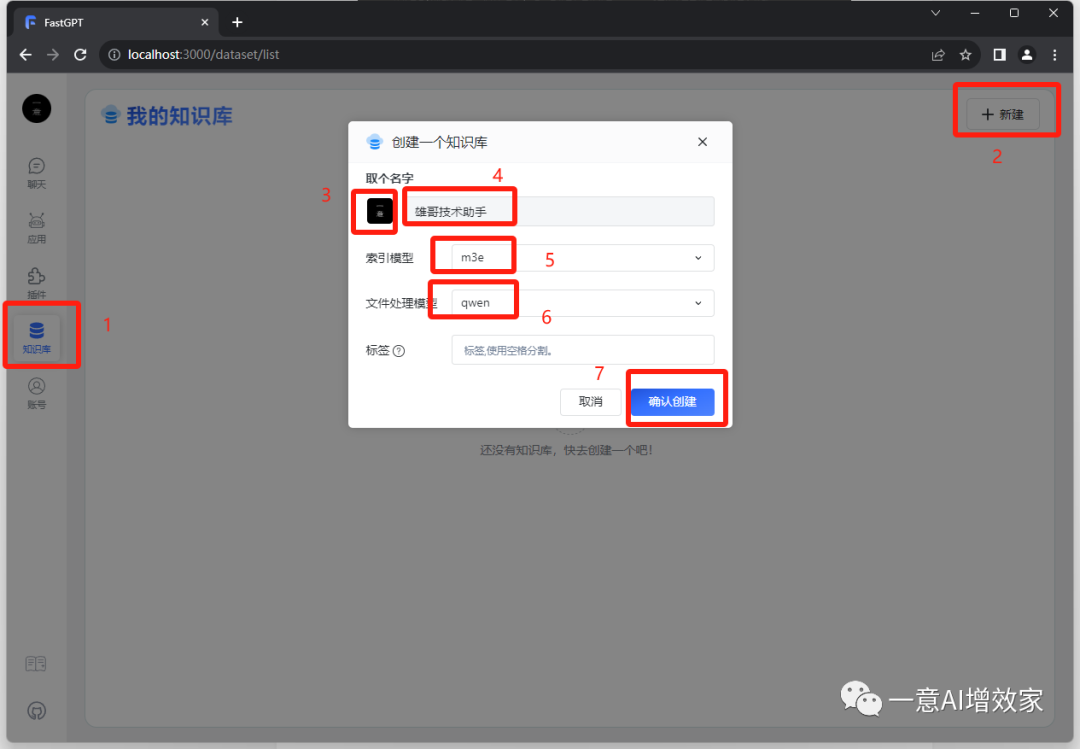
然后来到今天的主角!
他们的区别,上一篇雄哥已经简单介绍过了!今天深化去讲他!
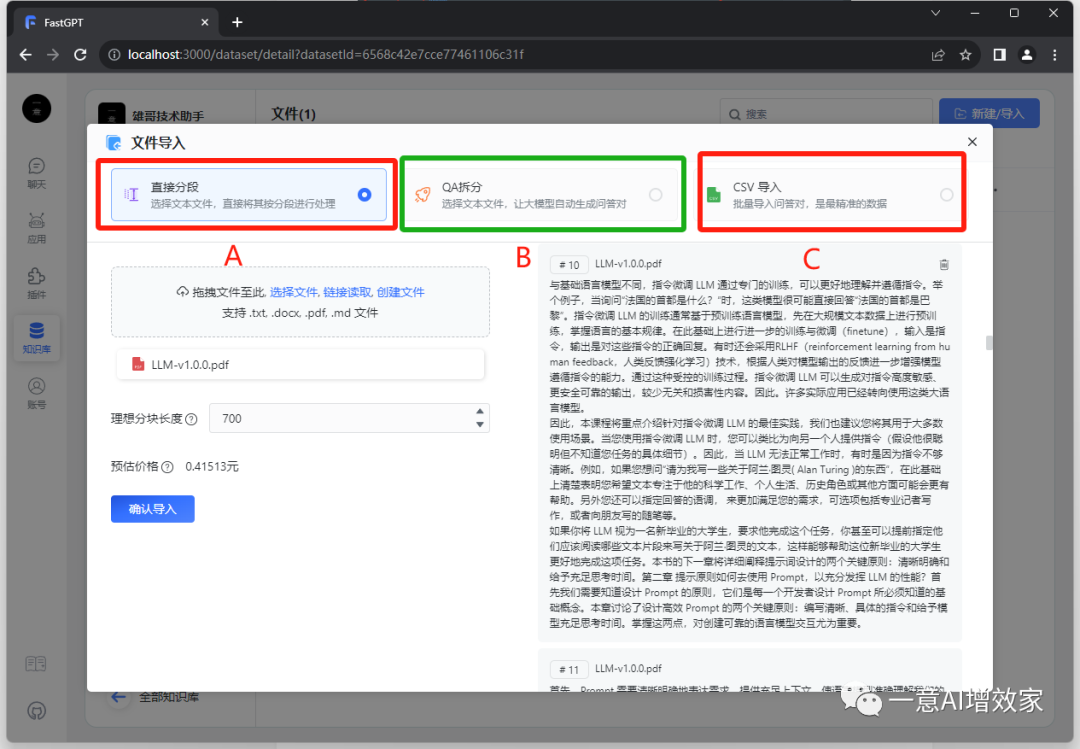
#A 直接分段
简单粗暴,你在下方填了多少字数,系统自动按照字数,把知识库切成同等大小!检索的时候,系统不会访问整个文档,而直接聚焦这一块,提升了检索效率!但是问题也很明显,就是把原来的数据切坏了!
这里默认700,是根据fastgpt的配置文件调的,当然可以调其他字数!但效果都知道的!
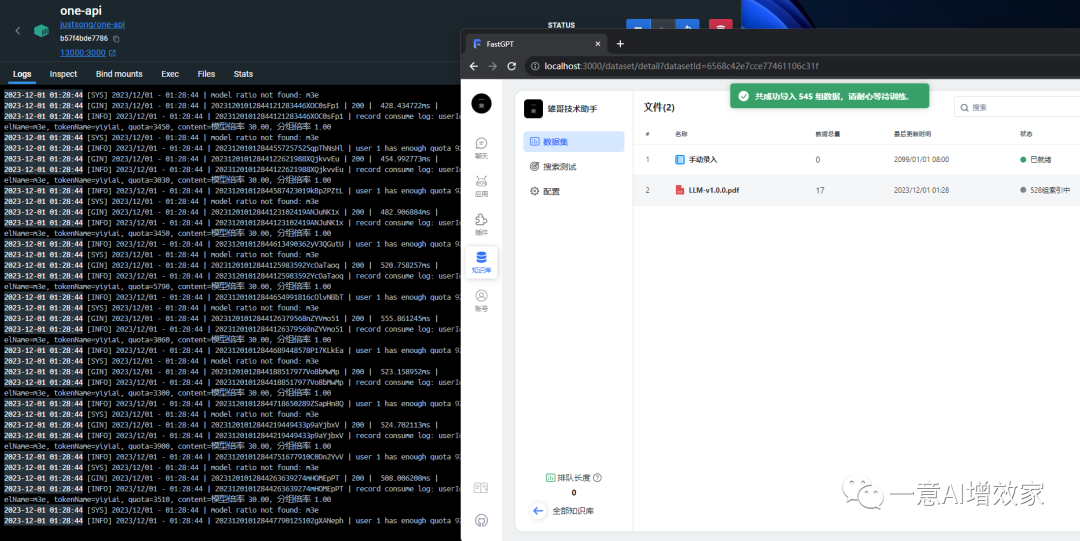
点确定导入后,你的显卡立即就会有反映!它会自动调用m3e嵌入模型做向量化处理!
来到one API的后台,它的处理非常快!
#B 对话QA拆分
看名字就知道了,就是用大模型,先对文本快进行一问一答的数据生成,然后再交给m3e做向量化处理,这比上面简单拆分多了一步!
这样的问答对处理,可以一定程度上地提高召回率,因为把用户可能的提问,都放到了向量数据中,便于模型检索!
但是!!
非常考验显卡性能+大模型的能力!待会看qwen-14B表现如何吧!
fastgpt默认有一段提示词预设,是程序的功能,你也可以根据自己的数据,更改提示词,这会影响大模型的结果,所以这就考验兄弟你的提示词工程功底了!
多少钱不用管它,这是本地模型,无所谓!
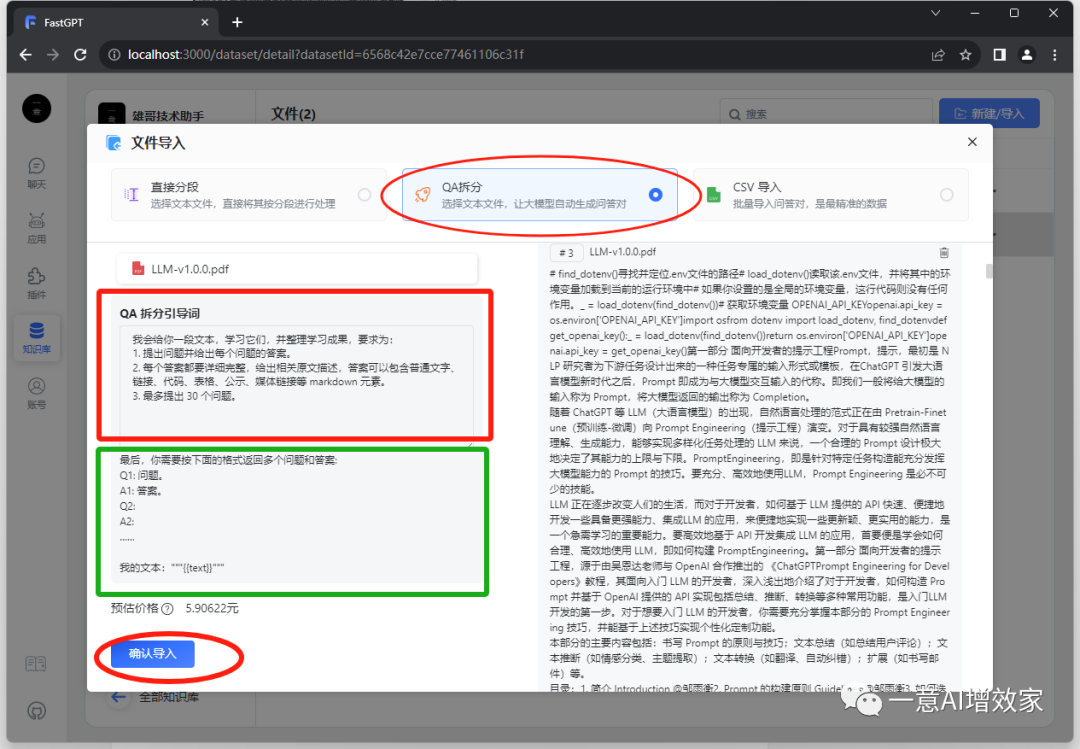
如果你创建知识库的时候不是选qwen,那你没有这个功能,要先勾选才行!看回第一步!显存不够的用glm3-6b!
当然!你也可以用OpenAI KEY的!这样的话,数据处理更准确!
点确定导入!我们来到qwen的部署界面,看到也已经开始工作了!
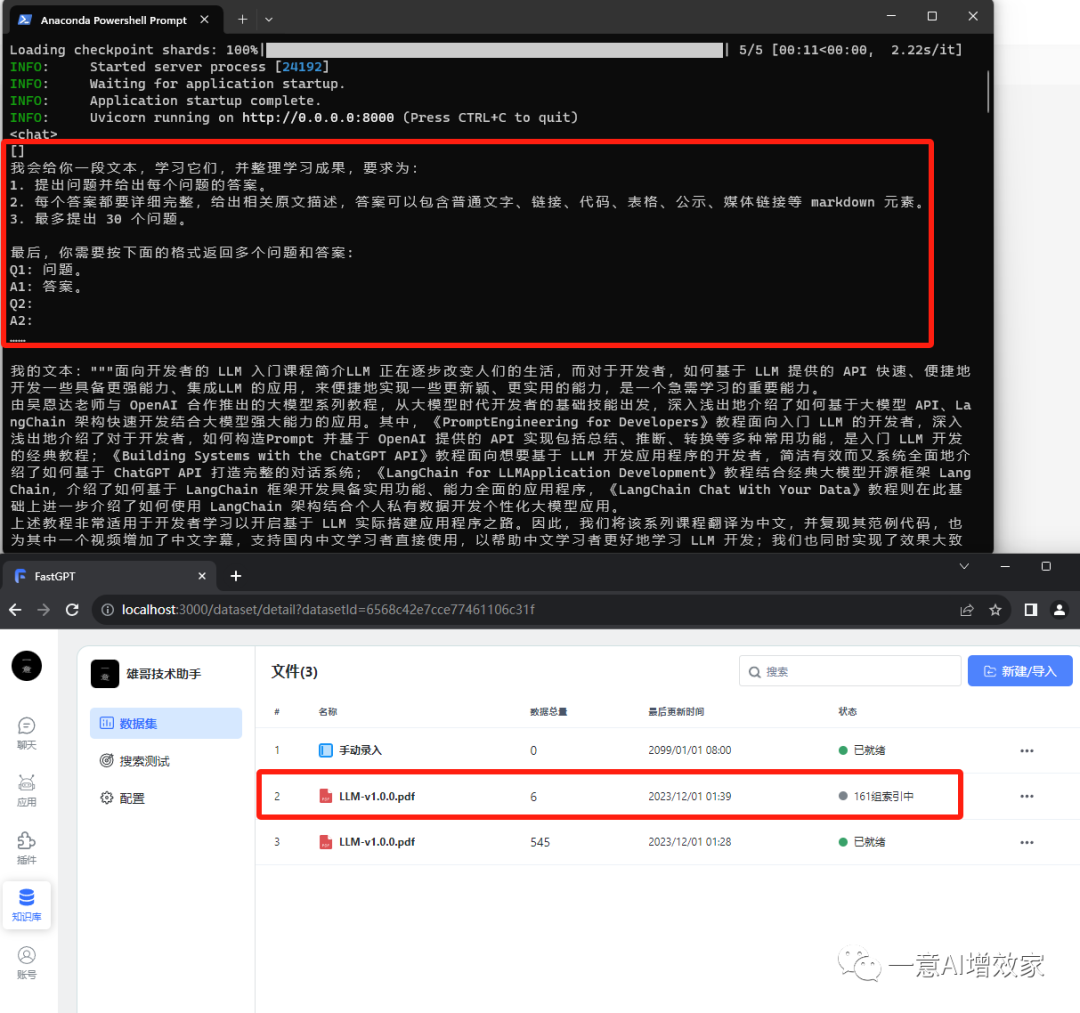
#C csv模板导入
上面三种数据处理方法,都有种囫囵吞枣!因为本身的数据处理是非结构化的!例如:
“通过一个实例理解基于字符分割和基于 Token 分割的区别可以看出token长度和字符长度不一样,token通常为4个字符五、分割Markdown文档5.1 分割一个自定义 Markdown 文档分块的目的是把具有上下文的文本放在一起,我们可以通过使用指定分隔符来进行分隔,但有些类型的文档(例如 Markdown )本身就具有可用于分割的结构(如标题)”
非结构化的数据,会降低知识库召回率,加上粗暴拆分,再减分!
知识星球的langchain系列,雄哥介绍了几种拆分方法,大家一定要根据自己的数据,选择最合适的方法,去拆分文档!
所以我们要把这些数据变成结构化!
CSV就是其中一种,我们打开一个CSV文件!
这些数据,是人工、或者公司现有的数据库产生!内容质量非常高的!
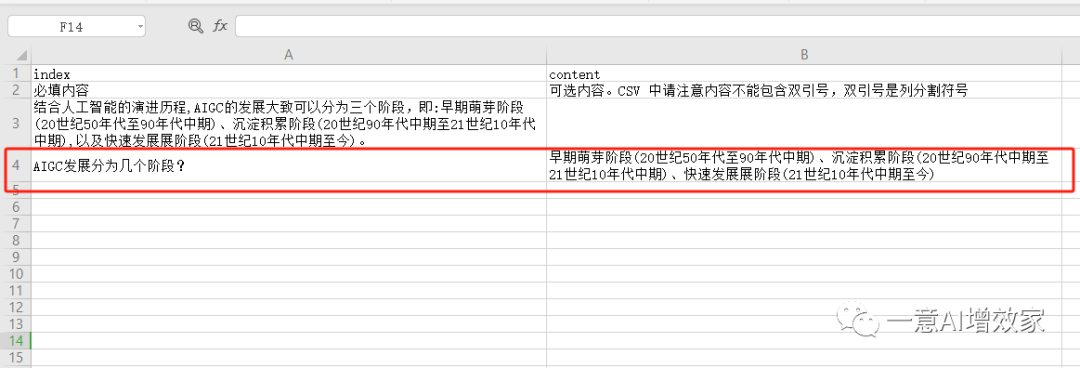
AIGC发展分为几个阶段?
早期萌芽阶段(20世纪50年代至90年代中期)、沉淀积累阶段(20世纪90年代中期至21世纪10年代中期)、快速发展展阶段(21世纪10年代中期至今)
这就是一个APP!不会坏!大不了重新安装!所以!动起手来!
下一篇,跟着雄哥学习高级编排,彻底把知识库玩透!
目前知识星球组织了自主Agent的内测项目,如果你感兴趣的话,快加入吧!