Python语言实现信度、效度检验及探索性因子分析
信效度检验1.信度检验1.1 引入需要读入文件的pandas库和计算Cronbach's a 系数的pingouin库,并读入文件1.2 计算Cronbach’s 系数 2.效度检验2.1 Bartlett's球状检验2.2 KMO检验 因子分析1.导入所需要的库包2.探索因子个数2.1.矩阵旋转前特征值、旋转前方差贡献率、旋转前方差累计贡献率2.2.画出碎石图,可视化 将特征值和因子个数的变化绘制成图形。2.3 建立因子分析模型 采用方差最大化因子旋转方式,并查看每个变量的公因子方差、旋转后的特征值、成分矩阵和因子方差2.4 可视化:热力图
信效度检验
关于问卷是否需要进行问卷信效度检验,前提时你的问卷含有量表题,量表题有两种量表:李克特量表和瑟斯顿量表 ,并且只有量表题才参与信效度检验。所以,信效度检验前需要对量表每一个选项的得分数据放到独立的一列数据中。如下图所示(Excel表)
1.信度检验
我们说量表的信度是指量表测量结果的一致性、稳定性、也称为量表的可靠性。如果在相同条件下,运用某量表对某一个概念在不同时间上重复多次进行测量,其测量的结果保持不变,就表明该量表是可信的或具有可靠性。在SPSS中对信度的检验也叫可靠性检验,一般对预调查数据进行,用信度检验Cronbach’s a 系数来衡量,一般认为Cronbach’s a 系数大于等于0.6表面信度检验没有问题。这里我通过Python语言的方法去实现计算。
1.1 引入需要读入文件的pandas库和计算Cronbach’s a 系数的pingouin库,并读入文件
import pandas as pdimport pingouin as pgzd_df = pd.read_excel('预调查量表题数据.xlsx',header = 0)1.2 计算Cronbach’s 系数
#Cronbach’s 系数result = pg.cronbach_alpha(data = zd_df)print(result)
2.效度检验
量表的效度是指量表准确地反映客观事物属性和特征的程度,也称为有效性。市场调查中效度可以理解为调查结果准确地反映调查中所要说明问题的程度。如果一个量表即具有较高的信度,也具有较高的效度,则这个量表就具有较高的内在质量。
在检验中,我们通常通过两个方法来衡量效度分别为为Bartlett’s球状检验和KMO检验
2.1 Bartlett’s球状检验
检验总体变量的相关矩阵是否是单位阵;检验各个变量是否各自独立。如果不是单位矩阵,说明原变量之间存在相关性,可以进行因子分析;反之,原变量之间不存在相关性,数据不适合进行主成分分析。
chi_square_value, p_value = calculate_bartlett_sphericity(zd_df)print("bartlett球状检验参数:\n卡方值为:{},p值为:{}".format(chi_square_value, p_value))
2.2 KMO检验
检验变量间相关性和偏相关性,取值在0~1之间;KOM统计量越接近1,变量相关性越强,偏相关性越弱,因子分析效果越好,通常取值从0.6开始进行因子分析
kmo_all, kmo_model = calculate_kmo(zd_df)print("KMO检验参数:\n", kmo_model)
因子分析
因子分析是指研究从变量群中提取共性因子的统计技术。最早由英国心理学家C.E.斯皮尔曼提出。他发现学生的各科成绩之间存在着一定的相关性,一科成绩好的学生,往往其他各科成绩也比较好,从而推想是否存在某些潜在的共性因子,或称某些一般智力条件影响着学生的学习成绩。因子分析可在许多变量中找出隐藏的具有代表性的因子。将相同本质的变量归入一个因子,可减少变量的数目,还可检验变量间关系的假设。
因子分析的主要目的是用来描述隐藏在一组测量到的变量中的一些更基本的,但又无法直接测量到的隐性变量
因子分析有探索性因子分析和证实性因子分析之分。本次是探索性因子分析
探索性因子分析不事先假定因子与测度项之间的关系,而让数据“自己说话”。主成分分析和共因子分析是其中的典型方法。验证性因子分析假定因子与测度项的关系是部分知道的,即哪个测度项对应于哪个因子,虽然我们尚且不知道具体的系数。
1.导入所需要的库包
import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib as mplfrom factor_analyzer import FactorAnalyzerfrom factor_analyzer.factor_analyzer import calculate_kmofrom factor_analyzer.factor_analyzer import calculate_bartlett_sphericityimport scipy.cluster.hierarchy as shc2.探索因子个数
2.1.矩阵旋转前特征值、旋转前方差贡献率、旋转前方差累计贡献率
Load_Matrix = FactorAnalyzer(rotation=None, n_factors=len(zd_df.T), method='principal')Load_Matrix.fit(zd_df)f_contribution_var = Load_Matrix.get_factor_variance()matrices_var = pd.DataFrame()matrices_var["旋转前特征值"] = f_contribution_var[0]matrices_var["旋转前方差贡献率"] = f_contribution_var[1]matrices_var["旋转前方差累计贡献率"] = f_contribution_var[2]matrices_var结果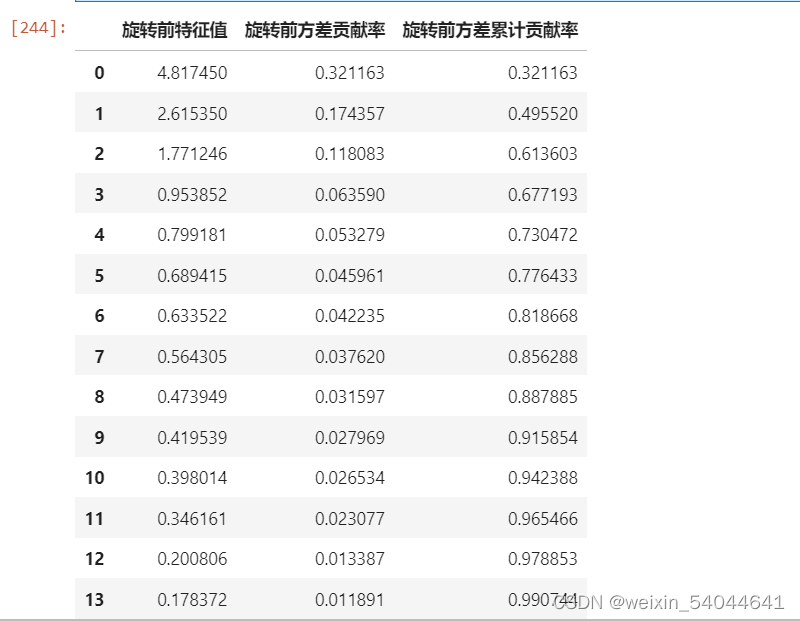
总结:一般情况我们选择旋转前特征值大于1的因子,即这个探索因子个数为3,此时方差累计贡献率为0.61,通常讲方差累计贡献率需要在70%及以上,才是可以接受的结果,不然意味着问卷量表设置不够好,会影响我们因子的探索
2.2.画出碎石图,可视化 将特征值和因子个数的变化绘制成图形。
#同样的数据绘制散点图和折线图plt.scatter(range(1, zd_df.shape[1] + 1), featValue)plt.plot(range(1, zd_df.shape[1] + 1), featValue) plt.title("Scree Plot")plt.xlabel("Factors")plt.ylabel("Eigenvalue") mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题plt.grid() # 显示网格plt.show() # 显示图形
总结:碎石检验是根据碎石图来决定因素数的方法。Kaiser提出,可通过直接观察特征值的变化来决定因素数。但某一个特征值较前一特征值出现较大的下降,而这个特征值值较小,其后面的的特征值变化不大,说明添加相应于该特征值的因素只能增加很少的信息,所以前几个特征值就是因抽取的公共因子数。
2.3 建立因子分析模型 采用方差最大化因子旋转方式,并查看每个变量的公因子方差、旋转后的特征值、成分矩阵和因子方差
#因子旋转#选择方式:varimax 方差最大化#选择固定因子为4fa_four = FactorAnalyzer(3,rotation='varimax')fa_four.fit(zd_df)#查看每个变量的公因子方差数据pd.DataFrame(fa_four.get_communalities(), index=zd_df.columns)print("每个变量的公因子方差数据:\n", pd.DataFrame(fa_four.get_communalities(), index=zd_df.columns)) #查看旋转后的特征值pd.DataFrame(fa_four.get_eigenvalues())print("旋转后的特征值:\n", pd.DataFrame(fa_four.get_eigenvalues())) #查看成分矩阵#变量个数*因子个数pd.DataFrame(fa_four.loadings_, index=zd_df.columns)print("成分矩阵:\n", pd.DataFrame(fa_four.loadings_, index=zd_df.columns)) #查看因子方差fa_four.get_factor_variance()print("因子方差:\n", fa_four.get_factor_variance())结果;

2.4 可视化:热力图
为了更直观的观察每个隐藏变量和哪些特征的关系比较大,进行可视化展示,为了方便取上面相关系数绝对值。利用热力图将稀疏矩阵绘制出来。
#隐藏变量可视化df1 = pd.DataFrame(np.abs(fa_four.loadings_), index=zd_df.columns)print("隐藏变量可视化:\n", df1)#绘图plt.figure(figsize=(9, 9))ax = sns.heatmap(df1, annot=True, cmap="BuPu")#设置y轴字体大小ax.yaxis.set_tick_params(labelsize=15)plt.title("Factor Analysis", fontsize="xx-large")# 设置y轴标签plt.ylabel("Sepal Width", fontsize="xx-large")# 显示图片plt.show()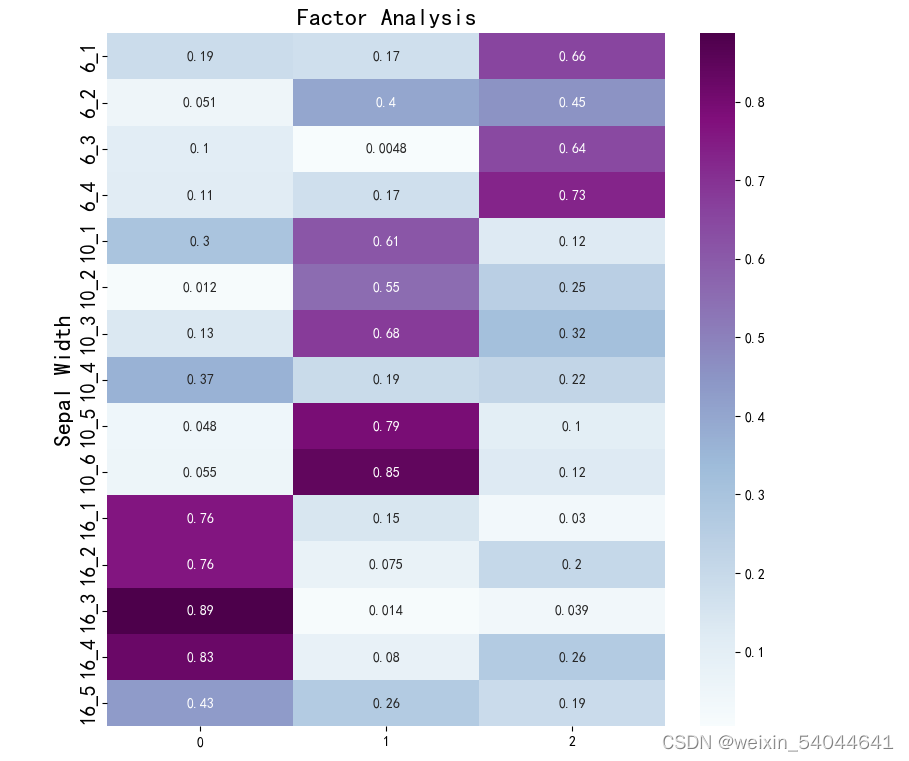
#由于采用较为合适的4个因子,可以将原始数据转换成4个新的特征df2 = pd.DataFrame(fa_four.transform(zd_df))print("转换后数据:\n", df2)结果: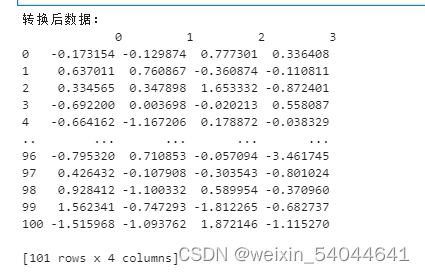
本次参考:https://blog.csdn.net/m0_64336780/article/details/127382936