本文目录
学习目标中间操作Filter(过滤)Map(转换)Sorted(排序)Distinct(去重)Limit(限制)Skip(跳过)Peek(展示) 终止操作forEach(循环)Collect(收集)Count(计数)Reduce(聚合)AnyMatch(任意匹配)AllMatch(全部匹配)NoneMatch(无匹配) 使用Stream流的优缺点:优点:缺点: 怎么用?
学习目标
看玩这篇将会:
1.了解stream流
2.学会使用stream流
3.掌握stream流的使用场景
每个方法通过举例子的形式学习!
Stream API主要提供了两种类型的操作:中间操作 和 终止操作。
中间操作
中间操作是返回一个新的流,并在返回的流中包含所有之前的操作结果。它们总是延迟计算,这意味着它们只会在终止操作时执行,这样可以最大限度地优化资源使用。
Filter(过滤)
filter()方法接受一个谓词(一个返回boolean值的函数),并返回一个流,其中仅包含通过该谓词的元素。建一个数组,帅选出长度大于4的元素
eg:public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); List<String> collect = names.stream().filter(item -> item.length() > 4).collect(Collectors.toList()); System.out.println(collect); }}
这段代码创建了一个包含4个字符串的List集合,然后使用Stream()方法将其转化为一个Stream流。接下来使用filter()方法筛选出长度大于4的字符串,返回一个新的包含符合条件元素的Stream流collect。最后使用collect()方法将筛选后的结果转换成一个List集合。
使用Stream流中的filter()方法可以对流中的元素进行筛选过滤。在这段代码中,lambda表达式item -> item.length() > 4指定了筛选判断条件,即只保留长度大于4的字符串。collect(Collectors.toList())则将筛选后的结果转换成一个List集合返回。
通过这段代码,开发人员可以对包含字符串的数据进行快速的筛选和过滤,并且返回结果是一个新的可操作的集合,方便后续进行处理或展示。
Map(转换)
map()方法可将一个流的元素转换为另一个流。它接受一个函数,该函数映射流中的每个元素到另一个元素。public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> collect = numbers.stream().map(n -> { n = n * 2; return n; }).collect(Collectors.toList()); for (Integer integer : collect) { System.out.println("integer = " + integer); } }}这段代码使用了 Java 8 中的 Stream API 实现了一种对数字列表中的每个元素进行乘以 2 的操作,并将操作后的结果保存到新的列表中。
首先创建了一个包含数字 1~5 的列表。
然后利用 stream() 方法将列表转换成 Stream 对象。
接下来调用 map() 方法对每个元素进行操作,这里使用了 lambda 表达式对每个元素进行了乘以 2 的操作。
最后调用 collect() 方法将结果收集起来,并转换成 List。
public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); Map<Byte, Integer> collect = numbers.stream().collect(Collectors.toMap(Integer::byteValue, item -> item*2, (val1, val2) -> val2)); for (Map.Entry<Byte, Integer> byteIntegerEntry : collect.entrySet()) { Byte key = byteIntegerEntry.getKey(); System.out.println("key = " + key); System.out.println("Value = " + byteIntegerEntry.getValue()); } }}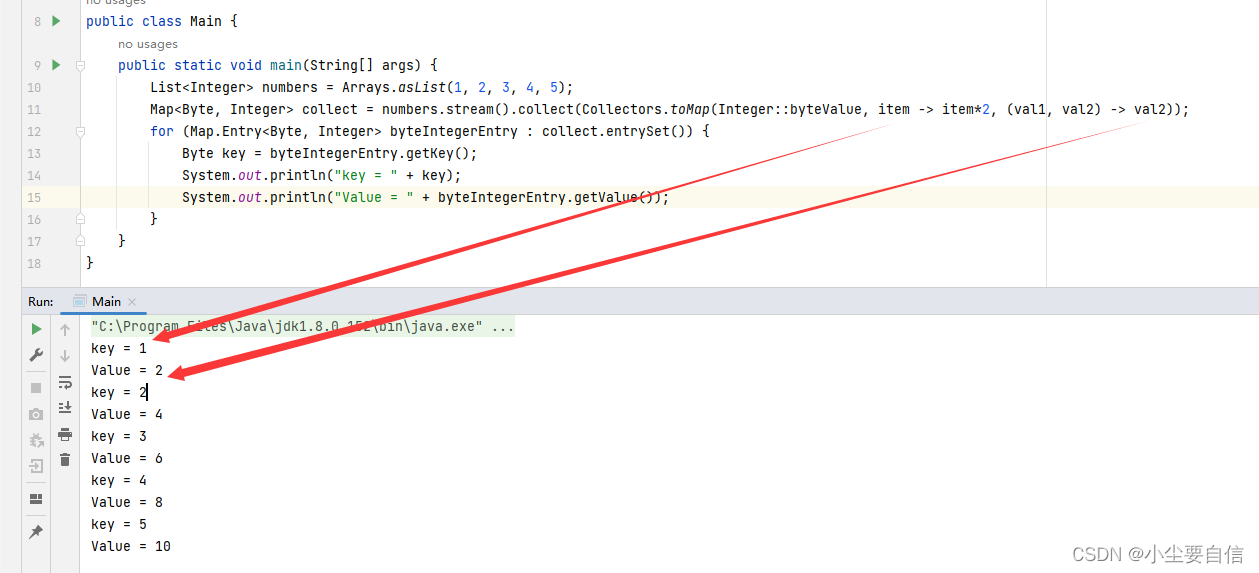
这段代码使用了 Java 8 中的 Stream API 实现了一种将数字列表转换成字节-整数键值对的方式。具体来说,代码中:
首先创建了一个包含数字 1~5 的列表。
然后利用 stream() 方法将列表转换成 Stream 对象。
接下来调用 collect(Collectors.toMap(…)) 方法将 Stream 转换成 Map<Byte, Integer>。
在 toMap 方法中,我们以每个整数的字节值为键,该整数乘以 2 为值,当遇到重复的键时取最后一个值。(这里实际上可以用任何能区分不同键的方式作为第一个参数,而不一定是 Integer::byteValue)
最后,在 for 循环中遍历了这个 Map 并打印出每个键值对的内容。
总的来说,通过 Stream API 可以方便地实现对集合数据进行筛选、映射、分组、统计等各种操作,相对于传统的循环遍历方式更为简洁、可读性更高,可以提高开发效率。
Sorted(排序)
sorted()方法可对流进行排序。它可以接受一个Comparator参数,也可以使用自然排序Ordering.natural()。默认排序是按升序排序。public class Main { public static void main(String[] args) { int[] numbers = { 5, 2, 8, 3, 7 }; int[] sortedNumbers = Arrays.stream(numbers).sorted().toArray(); System.out.println(Arrays.toString(sortedNumbers)); }}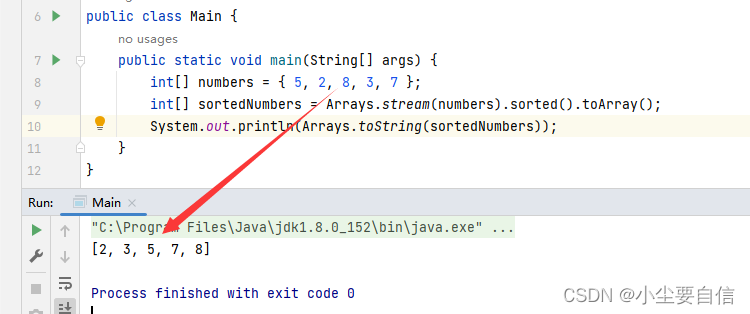
这段代码创建了一个包含整数的数组numbers,然后使用Arrays.stream()方法将其转化为一个IntStream流。接下来使用sorted()方法对流中的元素进行排序操作,返回一个新的排序后的IntStream流。最后,使用toArray()方法将排序后的结果转换为一个新的int类型数组sortedNumbers,并使用Arrays.toString()方法将结果输出到控制台。
使用Stream流可以简化代码,提高效率和可读性,方便开发人员对数据进行快速处理和排序。
Distinct(去重)
distinct()方法从流中返回所有不同的元素。在内部,它使用equals()方法来比较元素是否相同。因此,我们需要确保equals()方法已正确实现。public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 2, 1); List<Integer> collect = numbers.stream().distinct().collect(Collectors.toList()); System.out.println(collect); }}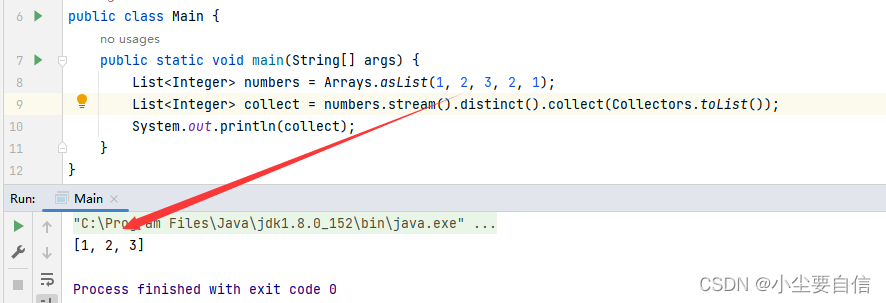
这段代码创建了一个包含整数的List集合numbers,其中包含了若干个重复的整数。接下来使用Stream()方法将其转化为一个Stream流。使用distinct()方法对流中的元素进行去重操作,返回一个新的不包含重复元素的Stream流collect。最后使用collect()方法将去重后的结果转换成一个List集合,并使用System.out.println()方法输出到控制台。
使用Stream流中的distinct()方法可以快速地对集合中的重复元素进行去重处理。在这段代码中,集合中的元素都是整数,使用distinct()方法去除了所有重复的整数,返回一个新的元素不重复且顺序不变的List集合。
运行该示例代码,输出结果为:[1, 2, 3],即去重后的不包含重复元素的整数List集合。
Limit(限制)
limit()方法可以将流限制为指定的元素数。public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> collect = numbers.stream().limit(3).collect(Collectors.toList()); System.out.println(collect); }}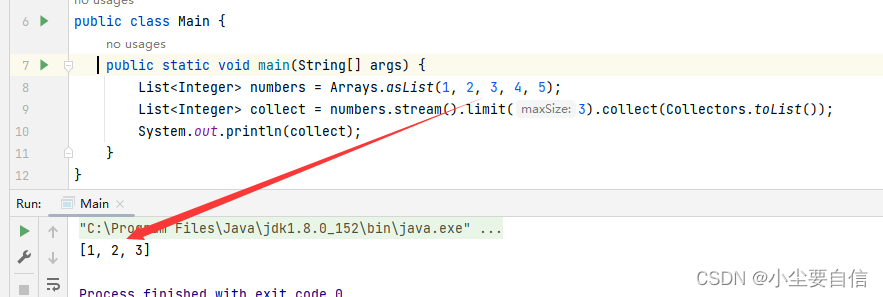
这段代码创建了一个包含整数的List集合numbers,其中包含了5个整数。接下来使用Stream()方法将其转化为一个Stream流。使用limit()方法对流中的元素进行限制操作,仅保留前3个元素,返回一个新的只包含前3个元素的Stream流collect。最后使用collect()方法将限制操作后的结果转化为一个新的List集合,并使用System.out.println()方法输出到控制台。
使用Stream流中的limit()方法可以快速地对集合中的元素进行截取操作,仅保留前N个元素。在这段代码中,集合中包含了5个整数,使用limit(3)方法仅保留了前3个整数,返回一个新的只包含前3个元素的List集合。
运行该示例代码,输出结果为:[1, 2, 3],即仅包含前3个元素的整数List集合。
Skip(跳过)
public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> collect = numbers.stream().skip(2).collect(Collectors.toList()); System.out.println(collect); }}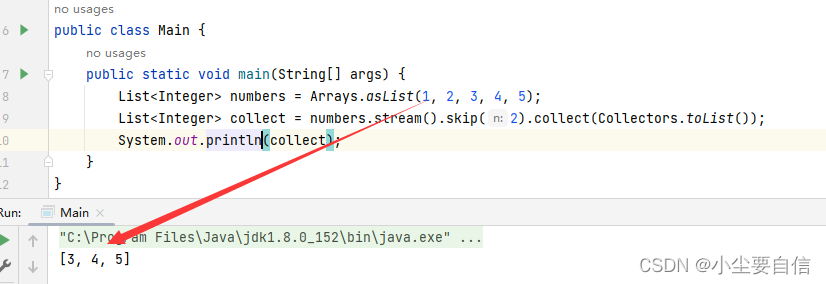
这段代码创建了一个包含整数的List集合numbers,其中包含了5个整数。接下来使用Stream()方法将其转化为一个Stream流。使用skip()方法对流中的元素进行跳过操作,跳过前2个元素,返回一个新的不包含前2个元素的Stream流collect。最后使用collect()方法将跳过操作后的结果转化为一个新的List集合,并使用System.out.println()方法输出到控制台。
使用Stream流中的skip()方法可以快速地对集合中的元素进行跳过操作,跳过前N个元素。在这段代码中,集合中包含了5个整数,使用skip(2)方法跳过前2个元素,返回一个新的不包含前2个元素的List集合。
运行该示例代码,输出结果为:[3, 4, 5],即不包含前2个元素的整数List集合。
Peek(展示)
peek()方法可以用于在Stream流中获取元素同时执行一些操作,如打印、调试、观察等。通常会与其他的方法联合使用。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); List<String> filteredNames = names.stream() .peek(System.out::println) .filter(name -> name.startsWith("C")) .peek(name -> System.out.println("Filtered value: " + name)) .collect(Collectors.toList()); System.out.println("-----------------------------------------------------------------"); System.out.println(filteredNames); }}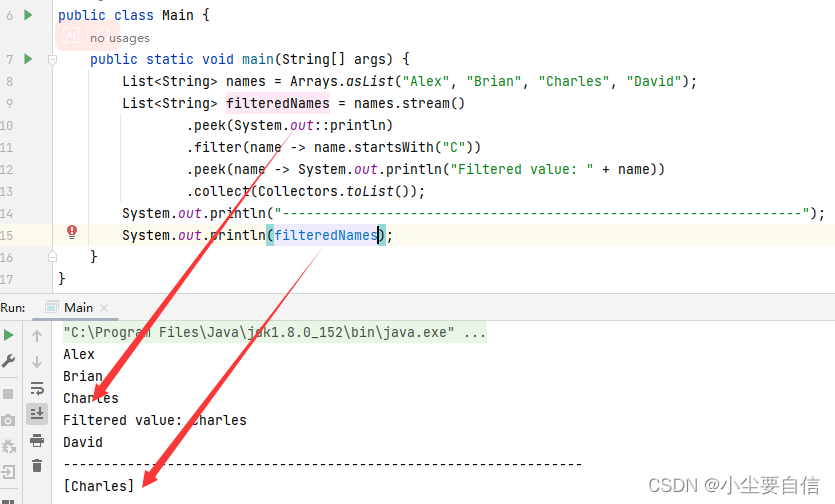
代码中创建了一个列表 names 包含四个字符串元素,然后使用流式操作处理这个列表。首先使用 peek() 方法将每个元素打印到控制台,然后使用 filter() 方法过滤掉不符合条件的元素,即不以字母 C 开头的字符串。接下来再次使用 peek() 方法将符合条件的字符串打印到控制台,以便验证过滤操作的效果。最后使用 collect() 方法将符合条件的字符串收集到一个新的列表 filteredNames 中,并输出该列表。
注意到,控制台上先输出了列表中的四个字符串,但只有以字母 C 开头的字符串 Charles 才符合筛选条件,因此仅仅 Charles 被保存在了 filteredNames 列表中。第二个 peek() 方法也被用来打印筛选出的元素 Charles。
终止操作
终止操作返回一个结果或副作用(例如:显示控制台输出),并将流关闭。
forEach(循环)
forEach()方法可将给定的方法应用于流中的每个元素。该方法是一种消费流的方式,不会返回值。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); names.stream().forEach(System.out::println); }}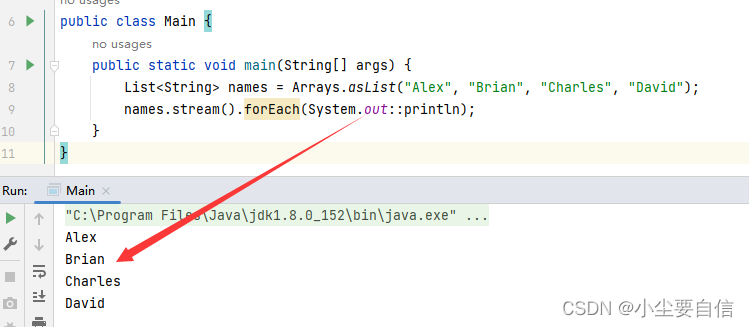
这段代码创建了一个包含四个字符串元素的列表 names,使用流式操作将每个元素打印到控制台。具体来说,它使用 forEach() 方法遍历列表中的所有元素,并对每个元素执行打印操作。
其中,四个字符串元素按顺序打印到了控制台上。注意到,使用 forEach() 方法时并没有指定任何条件或谓词,因此它会对列表中的所有元素进行操作,以达到遍历、打印等目的。
Collect(收集)
collect()方法可以将流中的元素收集到一个集合中。一般与其他方法配合使用。public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> evenNumbers = numbers.stream().filter(n -> n % 2 == 0).collect(Collectors.toList()); System.out.println(evenNumbers); }}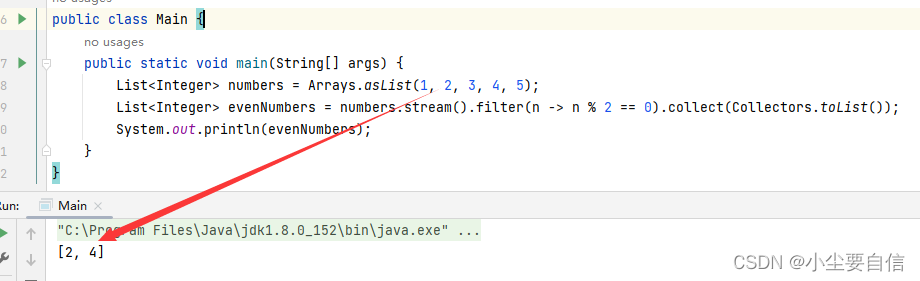
这段代码创建了一个包含整数的列表 numbers,使用流式操作筛选出所有偶数,然后将它们收集到一个新的列表 evenNumbers 中,并打印输出。具体来说,它使用了 filter() 方法过滤掉所有奇数元素,只保留所有偶数元素,并使用 collect() 方法将它们收集到一个新的列表 evenNumbers 中。
注意到,只有偶数元素被保留在了新列表 evenNumbers 中,而奇数元素全部被过滤掉了。而且,在筛选偶数元素时,使用了 lambda 表达式 n -> n % 2 == 0,其中 % 表示取模操作,判断当前数是否为偶数。如果 n % 2 的结果是 0,就把 n 这个数保留下来,否则就过滤掉。
Count(计数)
count()方法可以返回流中的元素数。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); long count = names.stream().count(); System.out.println(count); }}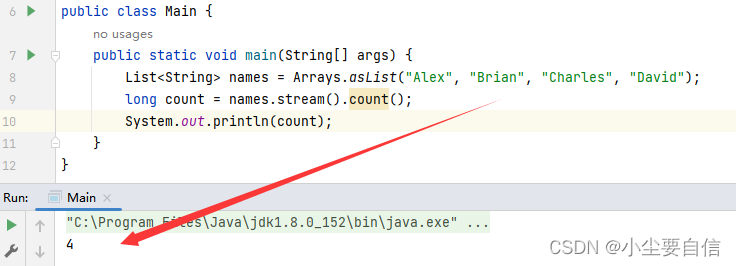
这段代码创建了一个包含四个字符串元素的列表 names,使用流式操作计算出它包含的元素数量(即列表大小),并将该数量打印到控制台。具体来说,它使用了 count() 方法统计列表中元素的个数。
注意到,count() 方法返回的是一个 long 类型的值,表示列表中元素的个数。因为列表 names 包含了四个元素,所以 count() 方法返回值为 4,最终被打印输出到了控制台。
Reduce(聚合)
reduce()方法可以将流元素聚合为单个结果。它接受一个BinaryOperator参数作为累加器。public class Main { public static void main(String[] args) { List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b); System.out.println(sum); }}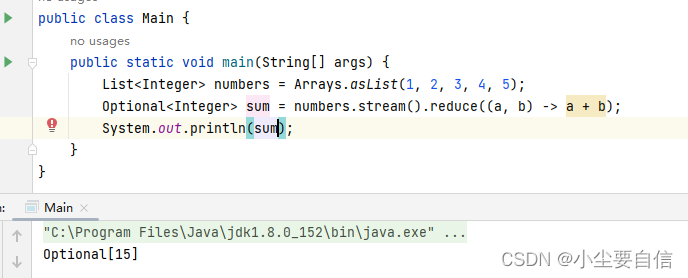
这段代码创建了一个包含整数的列表 numbers,使用流式操作将它们累加起来得到总和,并将结果打印输出。具体来说,它使用了 reduce() 方法对列表中的所有元素进行累加操作。reduce() 方法接收一个 BinaryOperator 函数作为参数,用于指定如何处理相邻的两个元素并返回一个新的结果值。
注意到,reduce() 方法返回的是一个 Optional 类型的值,表示结果可能存在也可能不存在(例如当列表为空时)。由于列表 numbers 包含 1 到 5 共五个元素,因此 reduce() 方法的操作过程如下:
1 + 2 = 3
3 + 3 = 6
6 + 4 = 10
10 + 5 = 15
最终得到的结果 15 被包装成 Optional 类型的对象并打印输出到控制台。
AnyMatch(任意匹配)
anyMatch()方法如果至少有一个元素与给定的谓词匹配,则返回true。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); boolean anyStartsWithB = names.stream().anyMatch(name -> name.startsWith("B")); System.out.println(anyStartsWithB); }}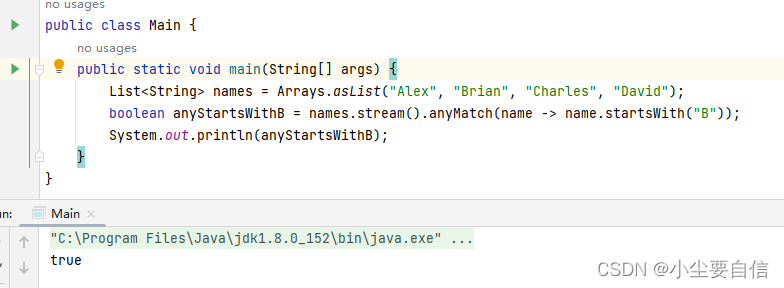
这段代码创建了一个包含四个字符串元素的列表 names,使用流式操作检查其中是否有任意一个元素以字母 “B” 开头,并将检查结果(布尔值)打印输出。具体来说,它使用了 anyMatch() 方法匹配列表中的所有元素,并依次对每个元素执行指定的谓词操作(这里是以 “B” 开头),只要有一个元素符合条件,就返回 true,否则返回 false。
注意到,列表 names 中包含了一个以字母 “B” 开头的元素 “Brian”,因此 anyMatch() 方法返回 true,最终被打印输出到了控制台。
AllMatch(全部匹配)
allMatch()方法如果所有元素都与给定谓词匹配,则返回true。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); boolean allStartsWithB = names.stream().allMatch(name -> name.startsWith("B")); System.out.println(allStartsWithB); }}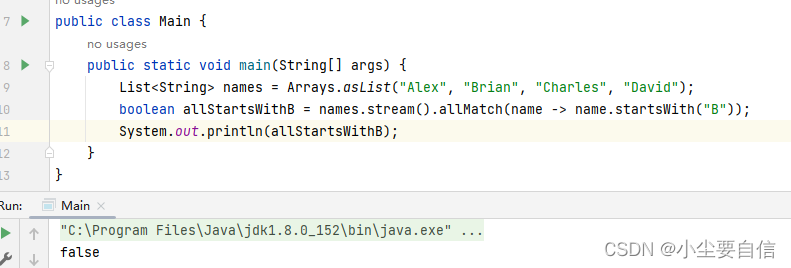
这段代码创建了一个包含四个字符串元素的列表 names,使用流式操作检查其中是否所有元素都以字母 “B” 开头,并将检查结果(布尔值)打印输出。具体来说,它使用了 allMatch() 方法匹配列表中的所有元素,并依次对每个元素执行指定的谓词操作(这里是以 “B” 开头),只有当所有元素都符合条件时,才返回 true,否则返回 false。
注意到,虽然列表 names 中包含了一个以字母 “B” 开头的元素 “Brian”,但是它不是所有元素都以 “B” 开头,因此 allMatch() 方法返回 false,最终被打印输出到了控制台。
NoneMatch(无匹配)
noneMatch()方法,如果没有任何元素与给定谓词匹配,则返回true。public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alex", "Brian", "Charles", "David"); boolean noneStartsWithB = names.stream().noneMatch(name -> name.startsWith("E")); System.out.println(noneStartsWithB); }}
这段代码创建了一个包含四个字符串元素的列表 names,使用流式操作检查其中是否没有任意一个元素以字母 “E” 开头,并将检查结果(布尔值)打印输出。具体来说,它使用了 noneMatch() 方法匹配列表中的所有元素,并依次对每个元素执行指定的谓词操作(这里是以 “E” 开头),只有当所有元素都不符合条件时,才返回 true,否则返回 false。
注意到,列表 names 中不包含任何一个以字母 “E” 开头的元素,因此 noneMatch() 方法返回 true,最终被打印输出到了控制台。
以上就是Java Stream流的基础知识和操作方式。Stream API可以使Java程序员编写出高效,干净,紧凑的代码,使得代码易于阅读和维护。建议初学者多加练习,掌握基本操作。中级和高级程序员则需要深入研究Stream API的实现原理和运作机制,进一步提高代码的质量和效率。
使用Stream流的优缺点:
优点:
Stream流可以帮助简化代码,减少样板代码,从而提高代码质量和可读性。
Stream流充分利用了现代多核处理器的优势,在多线程场景下可以获得更好的性能表现。
Stream流提供了丰富的操作方法,可以轻松地处理各种集合和数组的数据,从而降低程序员的编码难度和心理负担。
Stream流可以帮助开发人员更容易地写出函数式风格的代码,使代码更加健壮可维护。
缺点:
Stream流有时候会让代码变得复杂,反而降低了可读性,因此在某些简单的情况下可能不需要使用Stream流。
Stream流可能会对程序的性能产生一定影响,尤其是在大型数据集或者复杂的业务逻辑的情况下,程序员需要根据具体的情况进行测试和分析,选择最优解。
Stream流可能会造成资源浪费,例如创建中间操作的临时对象,这些对象将占用存储空间,导致效率降低。
在实际开发中,应该根据具体情况来决定是否使用Stream流。一般建议在数据集较大或者需要进行复杂的数据处理操作时使用Stream流,而在一些简单的操作中则可以直接使用循环和传统的集合操作方法。此外,如果代码可读性受到影响,也可以考虑使用传统的集合操作方法来实现代码。
怎么用?
当处理的数据来源于数据库,并需要对其进行某些复杂的过滤或排序时,使用SQL可能更加适合。因为数据库查询语言的操作速度通常会比Java程序快得多,而且可以通过数据库索引进一步提高性能。
但是,如果你需要在本地内存中处理已经读入程序或已经存在于集合中的小型数据集,那么使用Stream流是一个很好的选择。如需使用Java语言过滤和处理数据,Stream流提供了很多方便且易于理解的操作方法,例如:filter()、map()、reduce()等,这些操作可以帮助开发人员轻松地对数据集进行过滤和转换,并支持代码的并行化执行,提高运行效率。
总之,具体要看数据规模和使用场景。对于大规模的数据处理,SQL通常更有优势。而对于小规模的内存数据,Stream流是更灵活和可操作的方式。
好书分享

618,清华社 IT BOOK 多得图书活动开始啦!活动时间为 2023 年 6 月 7 日至 6 月 18 日,清华
社为您精选多款高分好书,涵盖了 C++、Java、Python、前端、后端、数据库、算法与机器学习等多
个 IT 开发领域,适合不同层次的读者。全场 5 折,扫码领券更有优惠哦!快来查看详情 !
图书链接:项目驱动零起点学Java