背景
随着后疫情时代的到来,在过去的2022年,全国的经济情况,想必是很多学者和研究对象都非常关心的事。而这些数据在国家统计局网站上都有相应的记录。通过分析这些数据,可以从某一个角度来验证和观察当下的经济情况。
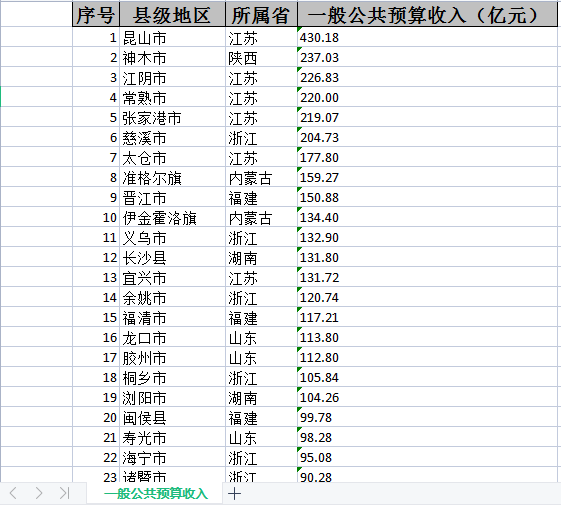
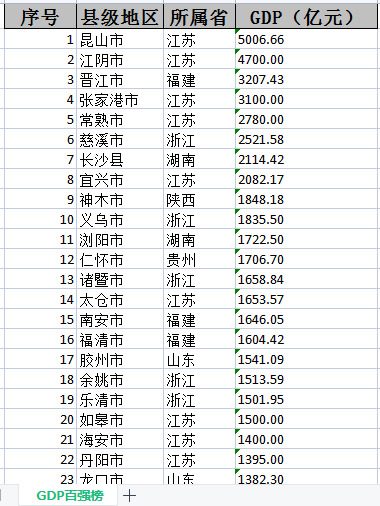
全国共计有1279个县级单位已经披露了2022年GDP和一般公共预算收入数据情况,企业预警通根据这些数据整理出中国百强县gdp排行榜和百强县一般公共预算收入排行榜。其中昆山市以5006.66亿元GDP蝉联榜单榜首,江阴市、晋江市位列百强县第二三位,长沙县是湖南省唯一进入全国前十的(Top7)。来源:2023中国县城GDP百强榜揭晓 2023中国百强县排行榜一览。
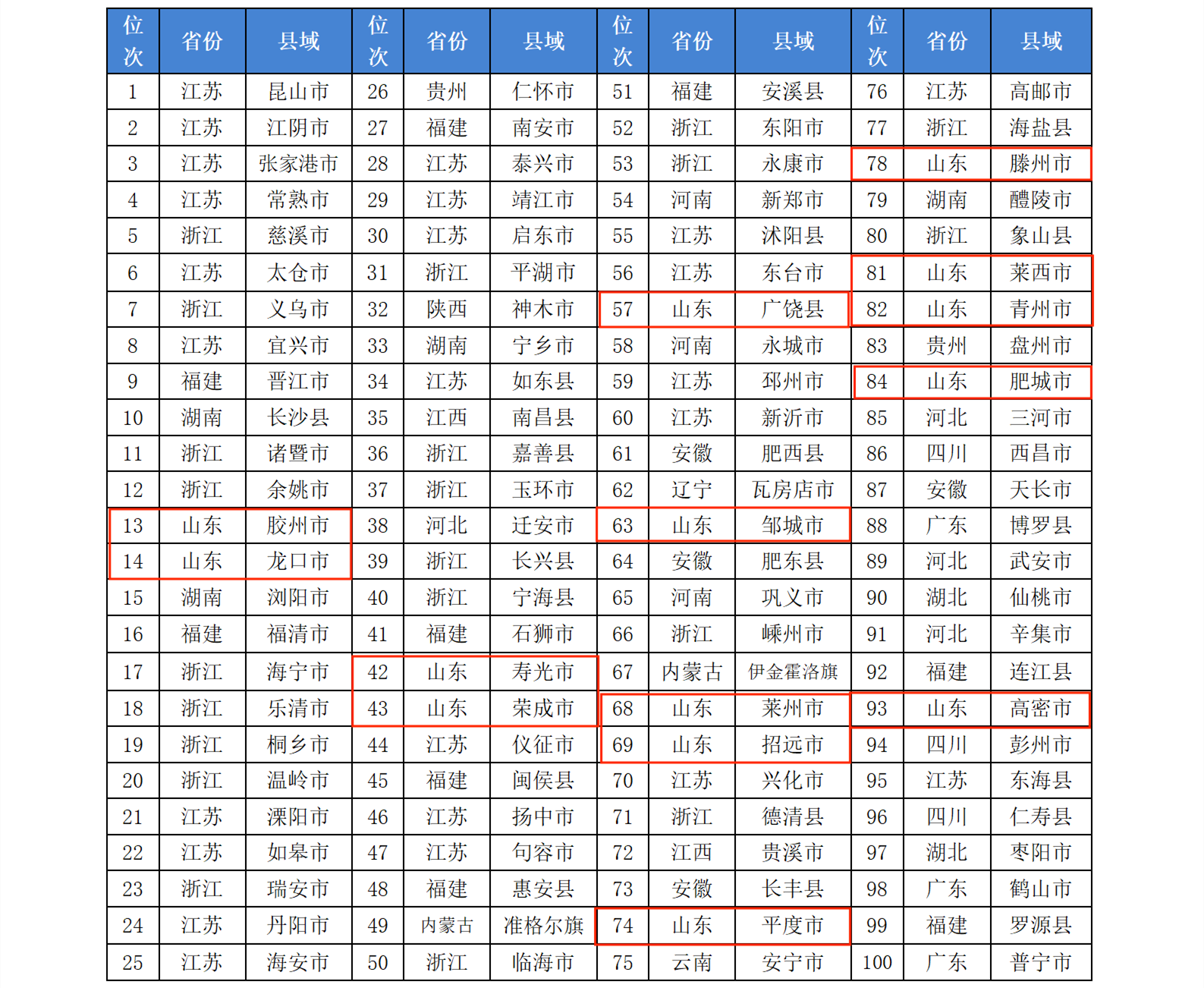
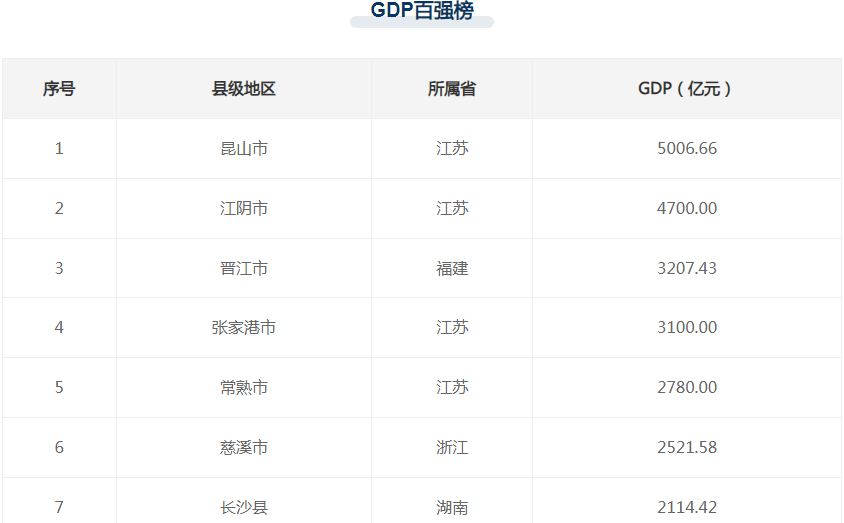
第一张图是以图片的形式发布的,第二种是采用Html的表格(table)形式展示的。在离线分析使用数据的时候非常不方便。作为程序猿,这一定难不倒您。我们可以采用网页抓取的技术对数据进行整理。本文将以Java语言为编程语言,讲解使用Jsoup对Web网页知识进行爬取,文中给出了详细的示例代码,希望对大家有帮助。
一、初识Jsoup抓取
1、网页结构分析
在使用Jsoup对页面进行抓取时,需要对网页的结构进行初步的分析,便于制定相对应的抓取策略。首先打开浏览器,输入目标网站的地址,同时打开F12进入调试,找到目标网页的元素。
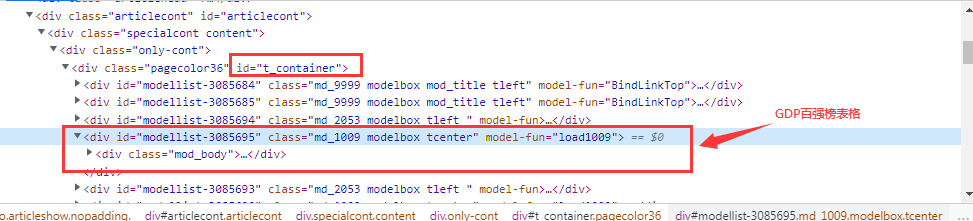
打开上面gdp百强榜表格中的div下table表格,找到如下的数据
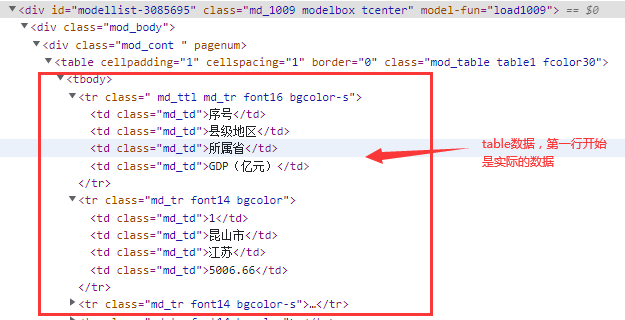
同理,对于一般公共预算收入的数据处理也是同样的处理办法,在此不再赘述。
二、Java开发Jsoup抓取
1、引用Jsoup相关依赖包
这里我们采用Maven的jar进行包的依赖处理管理。因此先定义Pom.xml,关键代码如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.yelang</groupId><artifactId>jsoupdemo</artifactId><version>0.0.1-SNAPSHOT</version><dependencies><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.0.5</version></dependency></dependencies></project>2、 信息实体类的处理
对比发现两个表格处理具体的指标不一样,前面的排名和县名称,所在省份名称都是一样的。因此我们采用面向对象的设计方法对信息处理的类进行开发。相应的类图如下所示:
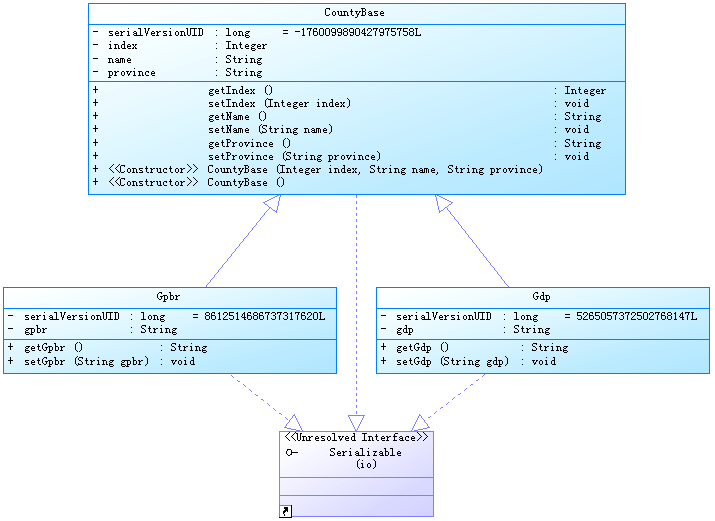
3、数据采集实体
package com.yelang.entity;import java.io.Serializable;import com.alibaba.excel.annotation.ExcelProperty;public class CountyBase implements Serializable {private static final long serialVersionUID = -1760099890427975758L;@ExcelProperty(value= {"序号"},index = 1)private Integer index;@ExcelProperty(value= {"县级地区"},index = 2)private String name;@ExcelProperty(value= {"所属省"},index = 3)private String province;public Integer getIndex() {return index;}public void setIndex(Integer index) {this.index = index;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getProvince() {return province;}public void setProvince(String province) {this.province = province;}public CountyBase(Integer index, String name, String province) {super();this.index = index;this.name = name;this.province = province;}public CountyBase() {super();}}在上面的代码中,将排序、县级地区、省作为父类抽象出来,设计两个子类:GDP类和一般公共收入类。这里需要注意的是,由于这里我们需要将采集的数据保存到本地的Excel表格中,这里我们采用EasyExcel作为技术生成组件。@ExcelProperty这个属性中,我们定义了写入的Excel表头以及具体的排序。
package com.yelang.entity;import java.io.Serializable;import com.alibaba.excel.annotation.ExcelProperty;public class Gdp extends CountyBase implements Serializable {private static final long serialVersionUID = 5265057372502768147L;@ExcelProperty(value= {"GDP(亿元)"},index = 4)private String gdp;public String getGdp() {return gdp;}public void setGdp(String gdp) {this.gdp = gdp;}public Gdp(Integer index, String name, String province, String gdp) {super(index,name,province);this.gdp = gdp;}public Gdp(Integer index, String name, String province) {super(index, name, province);}}package com.yelang.entity;import java.io.Serializable;import com.alibaba.excel.annotation.ExcelProperty;public class Gpbr extends CountyBase implements Serializable {private static final long serialVersionUID = 8612514686737317620L;@ExcelProperty(value= {"一般公共预算收入(亿元)"},index = 4)private String gpbr;// General public budget revenuepublic String getGpbr() {return gpbr;}public void setGpbr(String gpbr) {this.gpbr = gpbr;}public Gpbr(Integer index, String name, String province, String gpbr) {super(index, name, province);this.gpbr = gpbr;}public Gpbr(Integer index, String name, String province) {super(index, name, province);}}4、实际爬取
下面是处理GDP数据的转换代码,如果不熟悉Jsoup可以先熟悉下相关语法,如果有类似Jquery的开发经验,对于Jsoup上手非常快。
static void grabGdp() {String target = "https://www.maigoo.com/news/665462.html";try { Document doc = Jsoup.connect(target) .ignoreContentType(true) .userAgent(FetchCsdnCookie.ua[1]) .timeout(300000) .header("referer","https://www.maigoo.com") .get(); Elements elements = doc.select("#t_container > div:eq(3) table tr"); List<Gdp> list = new ArrayList<Gdp>(); for(int i = 1;i<elements.size();i++) { Element tr = elements.get(i);//获取表头 Elements tds = tr.select("td"); Integer index = Integer.valueOf(tds.get(0).text()); String name = tds.get(1).text(); String province = tds.get(2).text(); String gdp = tds.get(3).text(); Gdp county = new Gdp(index, name, province, gdp); list.add(county); } String fileName = "E:/gdptest/2023全国百强县GDP排行榜 .xlsx"; EasyExcel.write(fileName, Gdp.class).sheet("GDP百强榜").doWrite(list); System.out.println("完成...");} catch (Exception e) {System.out.println(e.getMessage());System.out.println("发生异常,继续下一轮循环");}}这里需要注意的是在jsoup中如何进行网页的元素定位及抓取。在上面这里,我们使用类似jquery的Dom获取方法。
Elements elements = doc.select("#t_container > div:eq(3) table tr");通过这一行去获取表格下的每一个tr,然后再循环每个td就可以获取对应的数据。
三、过程分析及结果
1、采集过程分析
这里采用对源程序进行debug的方法对网页进行抽丝剥茧的分析。使用jsou进行网页模拟访问
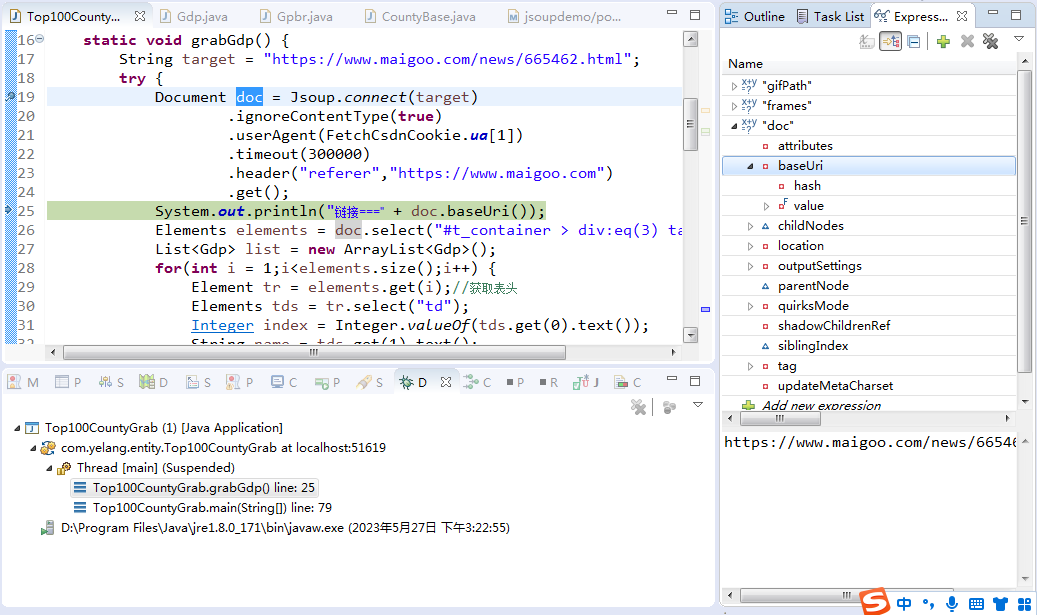
采用select(xxx)的方法获取页面元素,
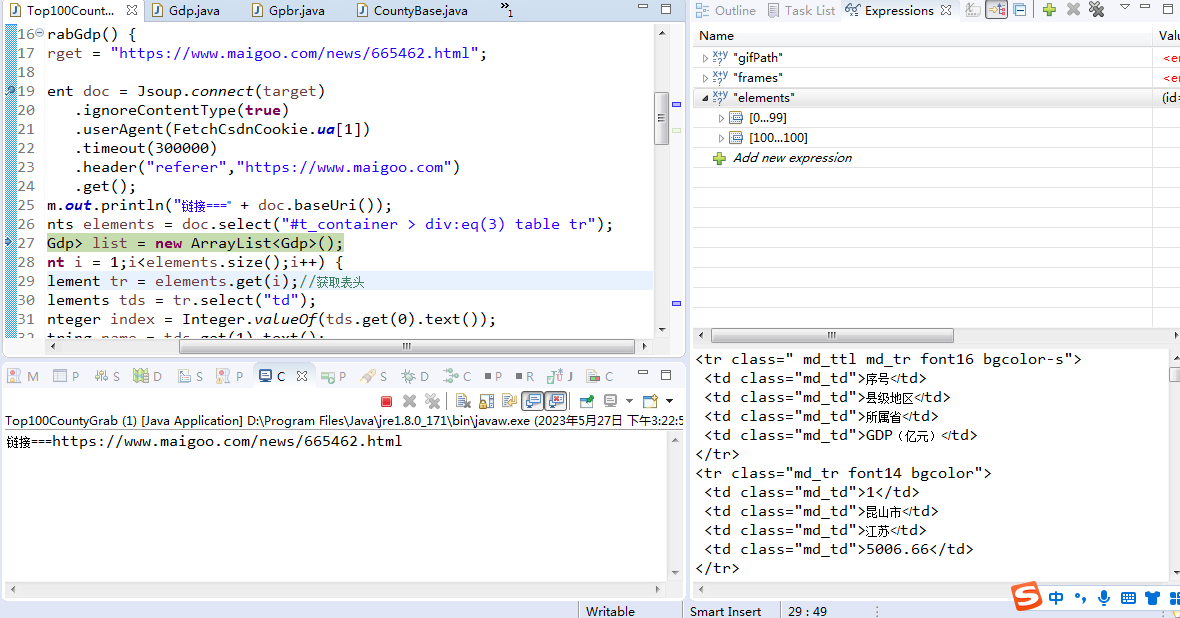
获取tr下的td单元格数据,
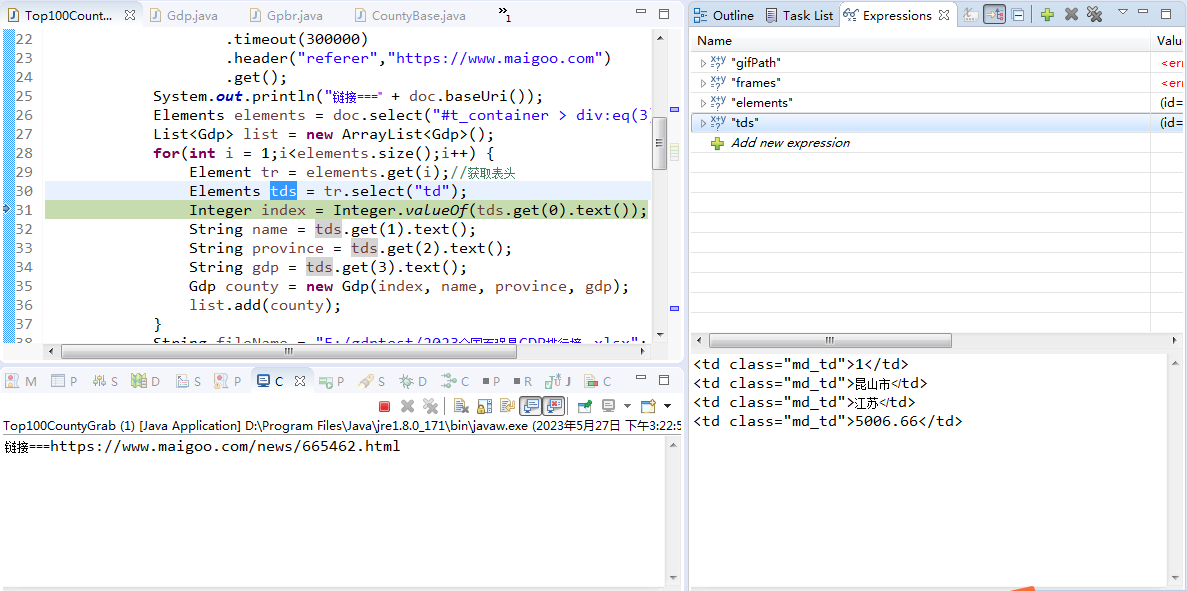
2、运行结果
上述代码运行完成后,在目的磁盘可以看到以下两个文件,
打开上述两个excel文件可以看到想要采集的数据已经采集完毕,数据的顺序也是完全按照网页上的顺序来进行生成的。
总结
以上就是本文的主要内容。本文将以Java语言为编程语言,详细讲解了如何使用Jsoup对Web网页知识进行爬取,结合EasyExcel将网页表格转换成Excel表格,同时文中给出了详细的示例代码。由于行文仓促,难免有误,欢迎批评指正交流。