目录
1 什么是C++多线程?
1.1 线程与进程
1.2 并发与并行
1.3 多线程
2 std::thread类
2.1 std::thread类构造函数
2.1 std::thread类成员函数
3 std::mutex类
3.1 类介绍
3.2 std::mutex成员函数
4 std::future异步线程
4.1 std::future异步线程理解
4.2 shared_future异步线程理解
5 原子类型automic
6 C++多线程高级知识
6.1 线程池基础知识
6.2 线程池所解决的问题
1 什么是C++多线程?
1.1 线程与进程
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,进程包含一个或者多个线程。进程可以理解为完成一件事的完整解决方案,而线程可以理解为这个解决方案中的的一个步骤,可能这个解决方案就这只有一个步骤,也可能这个解决方案有多个步骤。
1.2 并发与并行
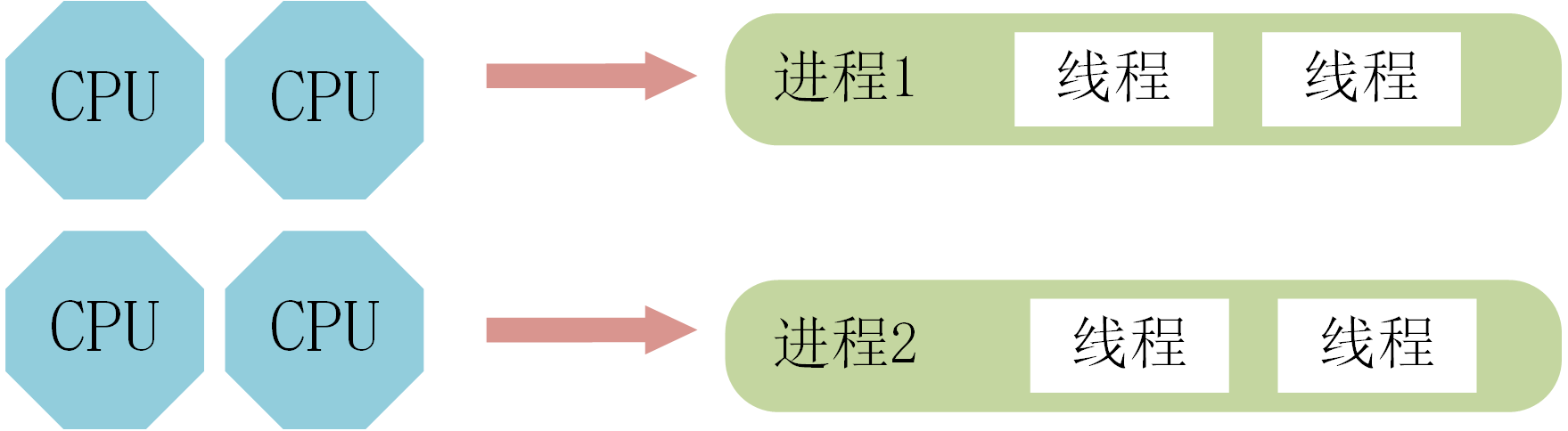
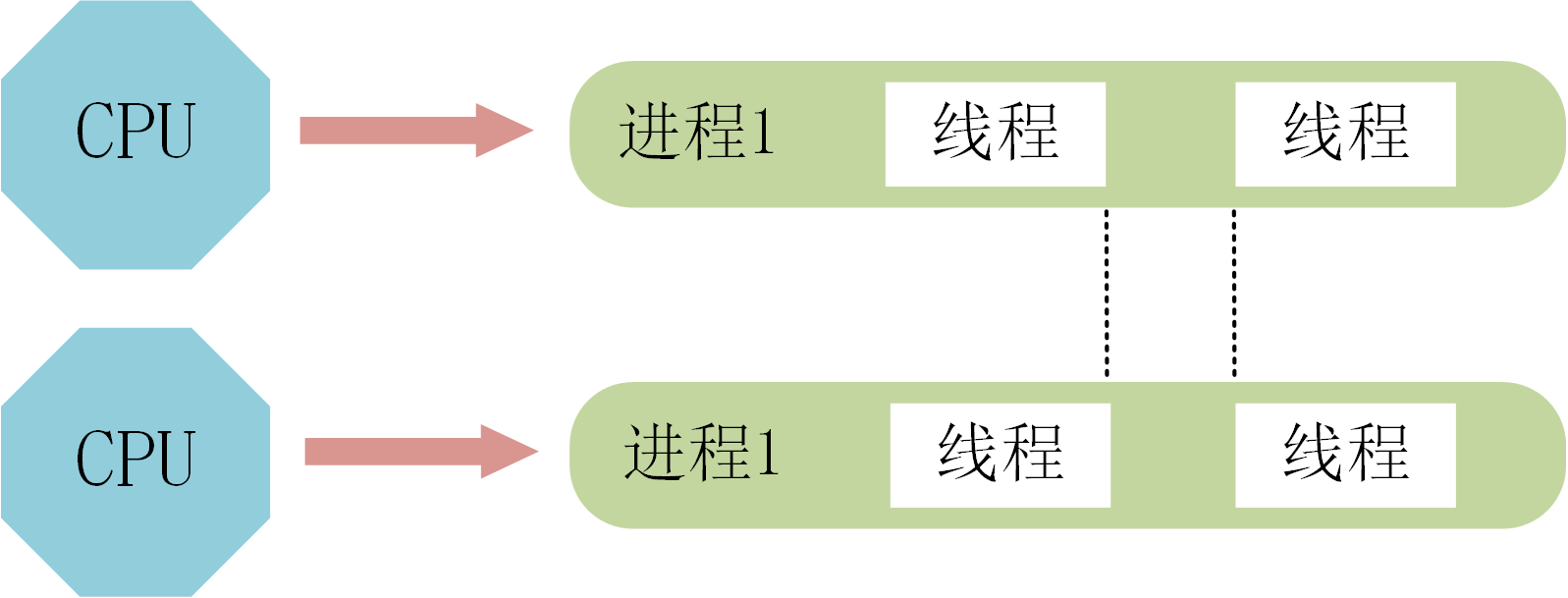
并发:是指两个或多个事件在同一时间间隔发生,并发是针对单核 CPU 提出的,在同一CPU上的多个事件。

并行:是指两个或者多个事件在同一时刻发生,并行则是针对多核 CPU 提出,在不同CPU上的多个事件
1.3 多线程
多线程是实现并发(并行)的手段,并发(并行)即多个线程同时执行,一般而言,多线程就是把执行一件事情的完整步骤拆分为多个子步骤,然后使得这多个步骤同时执行。
2 std::thread类
std::thread 在 <thread> 头文件中声明,因此使用 std::thread 时需要包含 <thread> 头文件。
2.1 std::thread类构造函数
| 默认构造函数 | thread() noexcept |
| 初始化构造函数 | template <class Fn, class... Args> |
| 拷贝构造函数 | thread (const thread&) = delete |
| move构造函数 | thread (thread&& x) noexcept |
#include <iostream>#include <utility>#include <thread>#include <chrono>#include <functional>#include <atomic>void f1(int n){ for (int i = 0; i < 5; ++i) { std::cout << "Thread 1 executing\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); } std::cout << "\t";}void f2(int& n){ for (int i = 0; i < 5; ++i) { std::cout << "Thread 2 executing\n"; ++n; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); }}int main(){ int n = 0; std::thread t1; // t1 is not a thread std::thread t2(f1, n + 1); // 值传递 std::thread t3(f2, std::ref(n)); // 引用传递 std::thread t4(std::move(t3)); // 移动构造函数 t2.join(); t4.join(); std::cout << "Final value of n is " << n << '\n';}2.1 std::thread类成员函数
(1)get_id:获取线程ID。返回一个类型为std::thread::id的对象。
#include <iostream>#include <thread>#include <chrono>void foo(){ std::this_thread::sleep_for(std::chrono::seconds(1));}int main(){ std::thread t1(foo); std::thread::id t1_id = t1.get_id(); std::thread t2(foo); std::thread::id t2_id = t2.get_id(); std::cout << "t1's id: " << t1_id << '\n'; std::cout << "t2's id: " << t2_id << '\n'; t1.join(); t2.join();}(2)joinable:检查线程是否可被join。检查当前的线程对象是否表示了一个活动的执行线程。缺省构造的thread对象、已经完成join的thread对象、已经detach的thread对象都不是joinable。
#include <iostream>#include <thread>#include <chrono>void foo(){ std::this_thread::sleep_for(std::chrono::seconds(1));}int main(){ std::thread t; std::cout << "before starting, joinable: " << t.joinable() << '\n'; t = std::thread(foo); std::cout << "after starting, joinable: " << t.joinable() << '\n'; t.join();}(3)join:调用该函数会阻塞当前线程(主调线程)。阻塞调用者(caller)所在的线程(主调线程)直至被join的std::thread对象标识的线程(被调线程)执行结束。
#include <iostream>#include <thread>#include <chrono>void foo(){// simulate expensive operationstd::this_thread::sleep_for(std::chrono::seconds(1));}void bar(){// simulate expensive operationstd::this_thread::sleep_for(std::chrono::seconds(1));}int main(){std::cout << "starting first helper...\n";std::thread helper1(foo);std::cout << "starting second helper...\n";std::thread helper2(bar);std::cout << "waiting for helpers to finish..." << std::endl;helper1.join();helper2.join();std::cout << "done!\n";}(4)detach:将当前线程对象所代表的执行实例与该线程对象分离,使得线程的执行可以单独进行。一旦线程执行完毕,它所分配的资源将会被释放。
#include <iostream>#include <chrono>#include <thread> void independentThread() { std::cout << "Starting concurrent thread.\n"; std::this_thread::sleep_for(std::chrono::seconds(2)); std::cout << "Exiting concurrent thread.\n";} void threadCaller() { std::cout << "Starting thread caller.\n"; std::thread t(independentThread); t.detach(); std::this_thread::sleep_for(std::chrono::seconds(1)); std::cout << "Exiting thread caller.\n";} int main() { threadCaller(); std::this_thread::sleep_for(std::chrono::seconds(5));}join和detach区别
join()函数是一个等待线程完成函数,主线程需要等待子线程运行结束了才可以结束detach称为分离线程函数,使用detach()函数会让线程在后台运行,即说明主线程不会等待子线程运行结束才结束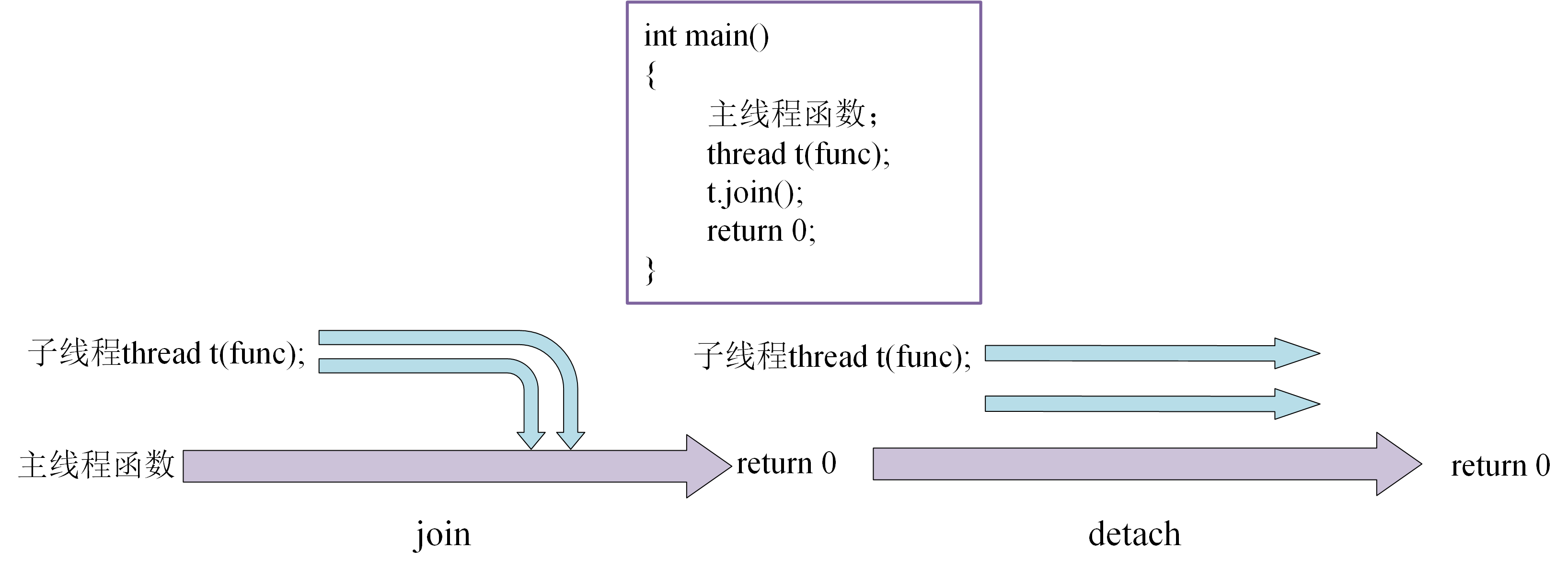
(5)native_handle:该函数返回与std::thread具体实现相关的线程句柄。native_handle_type是连接thread类和操作系统SDK API之间的桥梁,如在Linux g++(libstdc++)里,native_handle_type其实就是pthread里面的pthread_t类型,当thread类的功能不能满足我们的要求的时候(比如改变某个线程的优先级),可以通过thread类实例的native_handle()返回值作为参数来调用相关的pthread函数达到目录。
#include <thread>#include <iostream>#include <chrono>#include <cstring>#include <pthread.h>#include <mutex>std::mutex iomutex;void f(int num){ std::this_thread::sleep_for(std::chrono::seconds(1)); sched_param sch; int policy; pthread_getschedparam(pthread_self(), &policy, &sch); std::lock_guard<std::mutex> lk(iomutex); std::cout << "Thread " << num << " is executing at priority " << sch.sched_priority << '\n';}int main(){ std::thread t1(f, 1), t2(f, 2); sched_param sch; int policy; pthread_getschedparam(t1.native_handle(), &policy, &sch); sch.sched_priority = 20; if(pthread_setschedparam(t1.native_handle(), SCHED_FIFO, &sch)) { std::cout << "Failed to setschedparam: " << std::strerror(errno) << '\n'; } t1.join(); t2.join();}(6)swap:交换两个线程对象所代表的底层句柄。
#include <iostream>#include <thread>#include <chrono>void foo(){ std::this_thread::sleep_for(std::chrono::seconds(1));}void bar(){ std::this_thread::sleep_for(std::chrono::seconds(1));}int main(){ std::thread t1(foo); std::thread t2(bar); std::cout << "thread 1 id: " << t1.get_id() << std::endl; std::cout << "thread 2 id: " << t2.get_id() << std::endl; std::swap(t1, t2); std::cout << "after std::swap(t1, t2):" << std::endl; std::cout << "thread 1 id: " << t1.get_id() << std::endl; std::cout << "thread 2 id: " << t2.get_id() << std::endl; t1.swap(t2); std::cout << "after t1.swap(t2):" << std::endl; std::cout << "thread 1 id: " << t1.get_id() << std::endl; std::cout << "thread 2 id: " << t2.get_id() << std::endl; t1.join(); t2.join();}(7)operator=:将线程与当前 thread 对象关联。
(8)hardware_concurrency:静态成员函数,返回当前计算机最大的硬件并发线程数目。基本上可以视为处理器的核心数目。
#include <iostream>#include <thread>int main() { unsigned int n = std::thread::hardware_concurrency(); std::cout << n << " concurrent threads are supported.\n";}(9)sleep_for: 线程休眠某个指定的时间片(time span),该线程才被重新唤醒,不过由于线程调度等原因,实际休眠时间可能比 sleep_duration 所表示的时间片更长。
#include <iostream>#include <chrono>#include <thread>int main(){std::cout << "Hello waiter" << std::endl;std::chrono::milliseconds dura(2000);std::this_thread::sleep_for(dura);std::cout << "Waited 2000 ms\n";}(10)sleep_until: 线程休眠至某个指定的时刻(time point),该线程才被重新唤醒。
template< class Clock, class Duration >void sleep_until( const std::chrono::time_point<Clock,Duration>& sleep_time );
3 std::mutex类
Mutex 又称互斥量,C++ 11中与 Mutex 相关的类(包括锁类型)和函数都声明在 <mutex> 头文件中,所以如果你需要使用 std::mutex,就必须包含 <mutex> 头文件。
如何理解:这样比喻,两个人要去银行的柜台办理业务,且银行只有一个柜台,A要办理业务,B也要办理业务,但是柜台同一时间只能给一个人办理,在办理业务时要坐到柜台位置(lock),用完后再离开柜台位置(unlock)。那么,这个柜台位置就是互斥量,互斥量保证了使用办理业务这一过程不被打断。
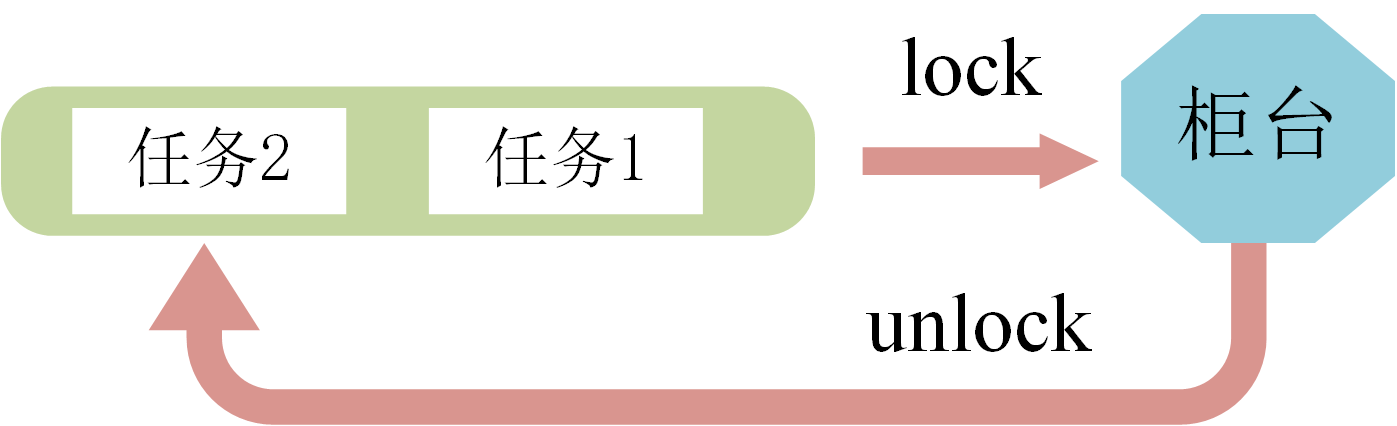
3.1 <mutex> 类介绍
(1)Mutex 系列类(四种)
| std::mutex | 最基本的 Mutex 类 |
| std::recursive_mutex | 递归 Mutex 类 |
| std::time_mutex | 定时 Mutex 类 |
| std::recursive_timed_mutex | 定时递归 Mutex 类 |
(2)Lock 类(两种)
| std::lock_guard | 与 Mutex RAII 相关,方便线程对互斥量上锁 |
| std::unique_lock | 与 Mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制 |
(3)函数
| std::try_lock | 尝试同时对多个互斥量上锁 |
| std::lock | 可以同时对多个互斥量上锁 |
| std::call_once | 如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。 |
3.2 std::mutex成员函数
下面以 std::mutex 为例介绍 C++11 中的互斥量用法。
std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。
(1)std::mutex 的成员函数
构造函数,std::mutex不允许拷贝构造,也不允许 move 拷贝,最初产生的 mutex 对象是处于 unlocked 状态的。lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:(1)如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。(2)如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。(3)如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。unlock(), 解锁,释放对互斥量的所有权。try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,(1)如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。(2)如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。(3)如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。下面给出一个与 std::mutex 的小例子:
#include<iostream>#include<thread>#include<mutex>using namespace std;mutex m;//实例化m对象,不要理解为定义变量void proc1(int a){ m.lock(); cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl; m.unlock();}void proc2(int a){ m.lock(); cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl; m.unlock();}int main(){ int a = 0; thread t1(proc1, a); thread t2(proc2, a); t1.join(); t2.join(); return 0;}对比输出:
加了lock()和unlock()相当于银行只有一个柜台,没有加lock()和unlock()相当于银行有多个柜台,互不干扰。
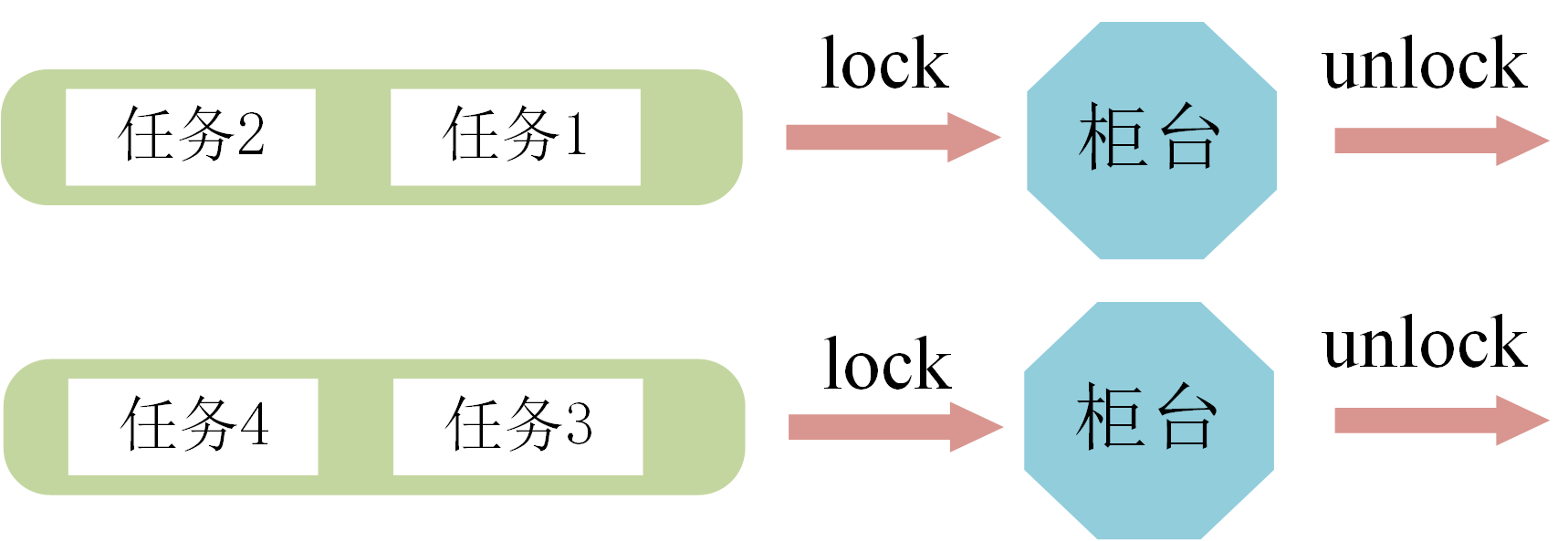
// 加了lock()和unlock()proc1函数正在改写a原始a为0现在a为2proc2函数正在改写a原始a为0现在a为1// 没有加lock()和unlock()proc2函数正在改写aproc1函数正在改写a原始a为原始a为00现在a为1现在a为2(2)std::recursive_mutex 介绍
std::recursive_mutex 与 std::mutex 一样,也是一种可以被上锁的对象,但是和 std::mutex 不同的是,std::recursive_mutex 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
(3)std::time_mutex 介绍
std::time_mutex 比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until()。
try_lock_for 函数接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until 函数则接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
下面的小例子说明了 std::time_mutex 的用法:
#include <iostream> // std::cout#include <chrono> // std::chrono::milliseconds#include <thread> // std::thread#include <mutex> // std::timed_mutexstd::timed_mutex mtx;void fireworks() {// waiting to get a lock: each thread prints "-" every 200ms:while (!mtx.try_lock_for(std::chrono::milliseconds(200))) {std::cout << "-";}// got a lock! - wait for 1s, then this thread prints "*"std::this_thread::sleep_for(std::chrono::milliseconds(1000));std::cout << "*\n";mtx.unlock();}int main (){ std::thread threads[10]; // spawn 10 threads: for (int i=0; i<10; ++i) threads[i] = std::thread(fireworks); for (auto& th : threads) th.join(); return 0;}(4)std::recursive_timed_mutex 介绍
和 std:recursive_mutex 与 std::mutex 的关系一样,std::recursive_timed_mutex 的特性也可以从 std::timed_mutex 推导出来。
(5)std::lock_guard 介绍
原理:内部构造时相当于执行了lock,析构时相当于执行unlock。,在其析构函数中进行解锁。最终的结果就是:创建即加锁,作用域结束自动解锁。从而使用lock_guard()就可以替代lock()与unlock()。例子:
#include<iostream>#include<thread>#include<mutex>using namespace std;mutex m;//实例化m对象,不要理解为定义变量void proc1(int a){ lock_guard<mutex> g1(m);//用此语句替换了m.lock();lock_guard传入一个参数时,该参数为互斥量,此时调用了lock_guard的构造函数,申请锁定m cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl;}//此时不需要写m.unlock(),g1出了作用域被释放,自动调用析构函数,于是m被解锁void proc2(int a){ { lock_guard<mutex> g2(m); cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl; }//通过使用{}来调整作用域范围,可使得m在合适的地方被解锁 cout << "作用域外的内容3" << endl; cout << "作用域外的内容4" << endl; cout << "作用域外的内容5" << endl;}int main(){ int a = 0; thread t1(proc1, a); thread t2(proc2, a); t1.join(); t2.join(); return 0;}输出:
proc1函数正在改写a原始a为0现在a为2proc2函数正在改写a原始a为0现在a为1作用域外的内容3作用域外的内容4作用域外的内容5lock_gurad也可以传入两个参数,第一个参数为adopt_lock标识时,表示不再构造函数中不再进行互斥量锁定,因此此时需要提前手动锁定。
#include<iostream>#include<thread>#include<mutex>using namespace std;mutex m;//实例化m对象,不要理解为定义变量void proc1(int a){ m.lock();//手动锁定 lock_guard<mutex> g1(m, adopt_lock); cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl;}//自动解锁void proc2(int a){ lock_guard<mutex> g2(m);//自动锁定 cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl;}//自动解锁int main(){ int a = 0; thread t1(proc1, a); thread t2(proc2, a); t1.join(); t2.join(); return 0;}
(6)std::unique_lock 介绍
unique_lock类似于lock_guard,只是unique_lock用法更加丰富,同时支持lock_guard()的原有功能。使用lock_guard后不能手动lock()与手动unlock();使用unique_lock后可以手动lock()与手动unlock();unique_lock的第二个参数,除了可以是adopt_lock,还可以是try_to_lock与defer_lock。
try_to_lock:尝试去锁定,得保证锁处于unlock的状态,然后尝试现在能不能获得锁;尝试用mutx的lock()去锁定这个mutex,但如果没有锁定成功,会立即返回,不会阻塞在那里。defer_lock: 初始化了一个没有加锁的mutex。| lock_guard | unique_lock | |
|---|---|---|
| 手动lock与手动unlock | 不支持 | 支持 |
| 参数 | 支持adopt_lock | 支持adopt_lock/try_to_lock/defer_lock |
#include<iostream>#include<thread>#include<mutex>using namespace std;mutex m;void proc1(int a){ unique_lock<mutex> g1(m, defer_lock); //始化了一个没有加锁的mutex g1.lock(); //手动加锁,注意,不是m.lock() cout << "proc1函数正在改写a" << endl; cout << "proc1函数a为" << a << endl; cout << "proc1函数a+2为" << a + 2 << endl; g1.unlock(); //临时解锁 cout << "尝试自动解锁" << endl; g1.lock(); cout << "运行后自动解锁" << endl;} //自动解锁void proc2(int a){ unique_lock<mutex> g2(m, try_to_lock); //尝试加锁,但如果没有锁定成功,会立即返回,不会阻塞在那里 cout << "proc2函数正在改写a" << endl; cout << "proc2函数a为" << a << endl; cout << "proc2函数a+1为" << a + 1 << endl;} //自动解锁int main(){ int a = 0; thread t1(proc1, a); thread t2(proc2, a); t1.join(); t2.join(); return 0;}unique_lock所有权的转移
mutex m;{ unique_lock<mutex> g2(m,defer_lock); unique_lock<mutex> g3(move(g2));//所有权转移,此时由g3来管理互斥量m g3.lock(); g3.unlock(); g3.lock();}
4 std::future异步线程
4.1 std::future异步线程理解
需要#include<future>,async是一个函数模板,用来启动一个异步任务,它返回一个future类模板对象,future对象起到了占位的作用,刚实例化的future是没有储存值的,但在调用future对象的get()成员函数时,主线程会被阻塞直到异步线程执行结束,并把返回结果传递给future,即通过FutureObject.get()获取函数返回值。
如何理解:相当于你去银行业务(主线程),把资料交给了柜台,柜台人员去给你办理(async创建子线程),柜台人员给了你一个单据(future对象),说你的业务正在给你办(子线程正在运行),等段时间你再过来凭这个单据取结果。过了段时间,你去柜台取结果,但是结果还没出来(子线程还没return),你就在柜台人员等着(阻塞),直到你拿到结果(get())你才离开(不再阻塞)。
#include <iostream>#include <thread>#include <mutex>#include<future>#include<Windows.h>using namespace std;double t1(const double a, const double b){double c = a + b;Sleep(3000);//假设t1函数是个复杂的计算过程,需要消耗3秒return c;}int main(){double a = 2.3;double b = 6.7;future<double> fu = async(t1, a, b);//创建异步线程线程,并将线程的执行结果用fu占位;cout << "正在办理业务" << endl;cout << "马上为您办理好,请您耐心等待" << endl;cout << "计算结果:" << fu.get() << endl;//阻塞主线程,直至异步线程return,future对象的get()方法只能调用一次。return 0;}输出:
正在办理业务马上为您办理好,请您耐心等待计算结果:94.2 shared_future异步线程理解
future与shard_future的用途都是为了占位,但是两者有些许差别。future的get()成员函数是转移数据所有权;shared_future的get()成员函数是复制数据。
future对象的get()只能调用一次;无法实现多个线程等待同一个异步线程,一旦其中一个线程获取了异步线程的返回值,其他线程就无法再次获取。shared_future对象的get()可以调用多次;可以实现多个线程等待同一个异步线程,每个线程都可以获取异步线程的返回值。
5 原子类型automic
互斥量的加锁一般是针对一个代码段,而原子操作针对的一般都是一个变量。automic是一个模板类,使用该模板类实例化的对象,提供了一些保证原子性的成员函数来实现共享数据的常用操作。
在以前,定义了一个共享的变量(int i=0),多个线程会操作这个变量,那么每次操作这个变量时,都是用lock加锁,操作完毕使用unlock解锁,以保证线程之间不会冲突;现在,实例化了一个类对象(automic i=0)来代替以前的那个变量,每次操作这个对象时,就不用lock与unlock,这个对象自身就具有原子性,以保证线程之间不会冲突。
automic对象提供了常见的原子操作(通过调用成员函数实现对数据的原子操作):
store是原子写操作,load是原子读操作。exchange是于两个数值进行交换的原子操作。即使使用了automic,也要注意执行的操作是否支持原子性。一般atomic原子操作,针对++,–,+=,-=,&=,|=,^=是支持的。#include <atomic>#include <thread>#include <iostream>using namespace std;atomic_int64_t total = 0; //atomic_int64_t相当于int64_t,但是本身就拥有原子性//线程函数,用于累加void threadFunc(int64_t endNum) {for (int64_t i = 1; i <= endNum; ++i){total += i;}}int main() {int64_t endNum = 100;thread t1(threadFunc, endNum);thread t2(threadFunc, endNum);t1.join();t2.join();cout << "total=" << total << endl; //10100}
6 C++多线程高级知识
6.1 线程池基础知识
不采用线程池时:创建线程 -> 由该线程执行任务 -> 任务执行完毕后销毁线程。即使需要使用到大量线程,每个线程都要按照这个流程来创建、执行与销毁。
虽然创建与销毁线程消耗的时间远小于线程执行的时间,但是对于需要频繁创建大量线程的任务,创建与销毁线程所占用的时间与CPU资源也会有很大占比。
为了减少创建与销毁线程所带来的时间消耗与资源消耗,因此采用线程池的策略:
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。接收到任务后,线程池选择一个空闲线程来执行此任务。任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。6.2 线程池所解决的问题
(1) 需要频繁创建与销毁大量线程的情况下,减少了创建与销毁线程带来的时间开销和CPU资源占用。(省时省力)
(2) 实时性要求较高的情况下,由于大量线程预先就创建好了,接到任务就能马上从线程池中调用线程来处理任务,略过了创建线程这一步骤,提高了实时性。(实时)
参考文章(本文是篇文章的学习汇总,参考链接如下)
(1)https://www.cnblogs.com/zizbee/p/13520823.html
(2)C++ thread_碎步の流年的博客-CSDN博客
(3)<thread> 函数
(4)std::mutex 用法详解_std:mutex_faihung的博客-CSDN博客
