文章目录
1.卷积层2.池化层3.全连接层4.参数量计算
1.卷积层
我们以灰度图像为例进行讲解:让一个权重矩阵即卷积核(kernel)逐步在二维输入数据上“扫描”。卷积核“滑动”的同时,计算权重矩阵和扫描所得的数据矩阵的乘积,然后把结果汇总成一个输出像素。使用3x3卷积核,在未使用padding的情况下,卷积之后的图像尺寸为(width-2)*(height-2)。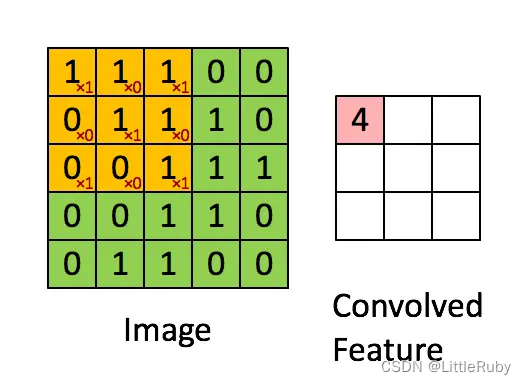
以下动图展示了in_channels=3、out_channels =2,kernel_size=3、stride=2、padding=1的卷积层运算过程。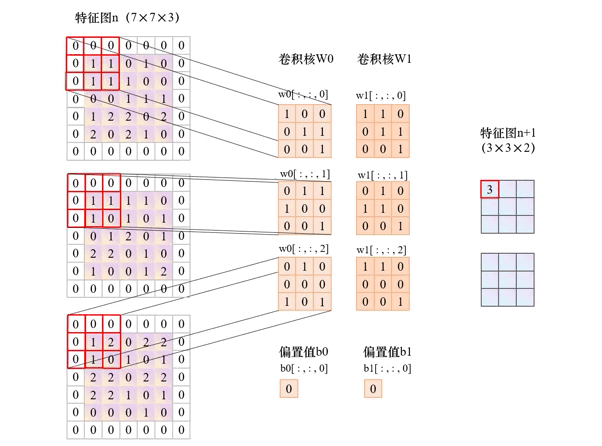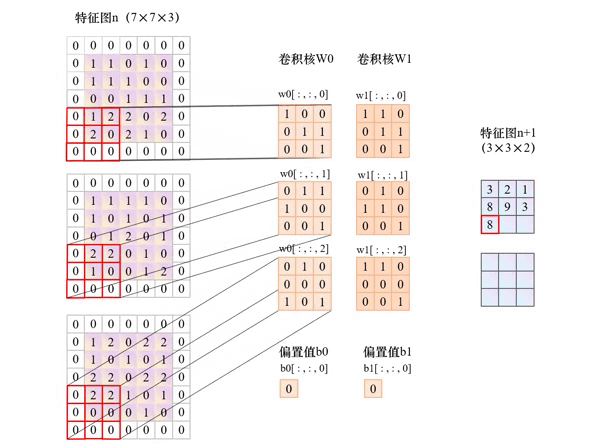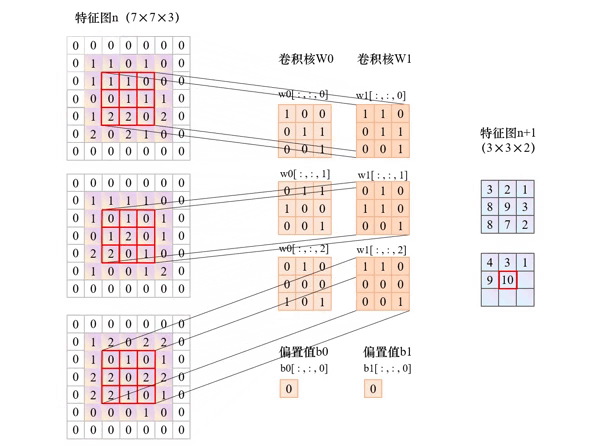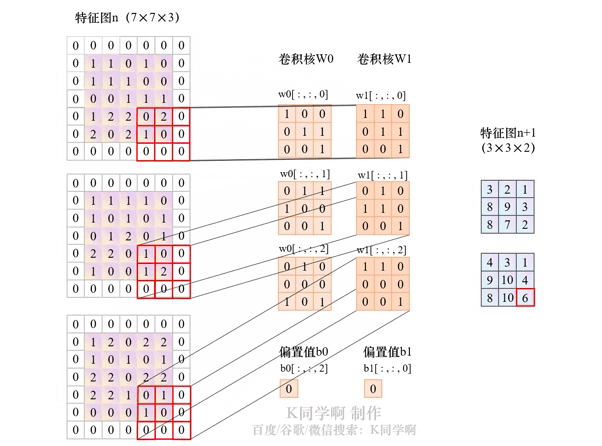
【卷积的计算公式】
输入图片的尺寸:一般用nn表示输入的image大小。
卷积核的大小:一般用ff表示卷积核的大小。
填充(Padding):一般用p来表示填充大小。
步长(Stride):一般用s来表示步长大小。
输出图片的尺寸:一般用o来表示。
如果已知 n,f,p,s,可以求得o
计算公式如下:
o = ⌊ n + 2 p − f s ⌋ + 1 o=\lfloor\frac{n+2p-f}{s} \quad \rfloor+1 o=⌊sn+2p−f⌋+1
其中" ⌊ ⌋ \lfloor \rfloor ⌊⌋"是向下取整符号,用于结果不是整数时进行向下取整。
输出图片大小为:o×o
步长为2,卷积核为3*3,p=0的卷积情况如下: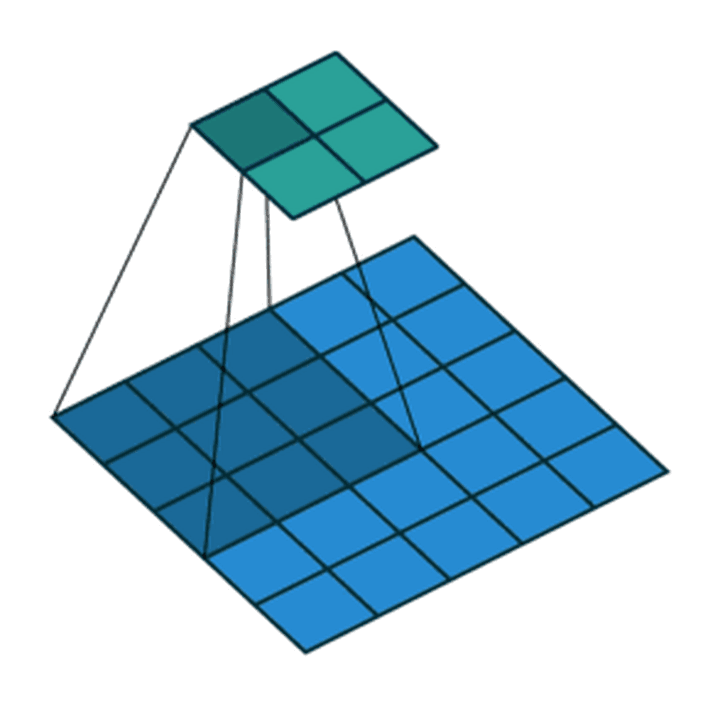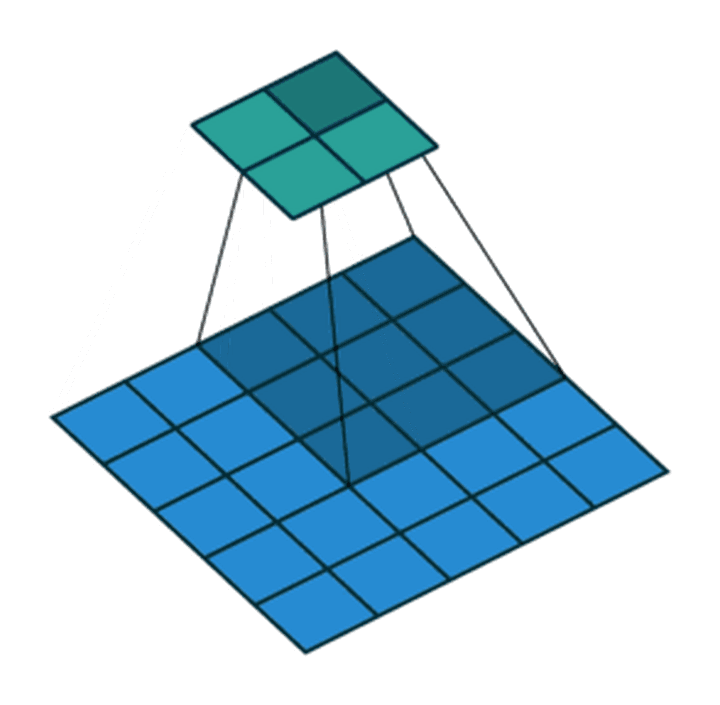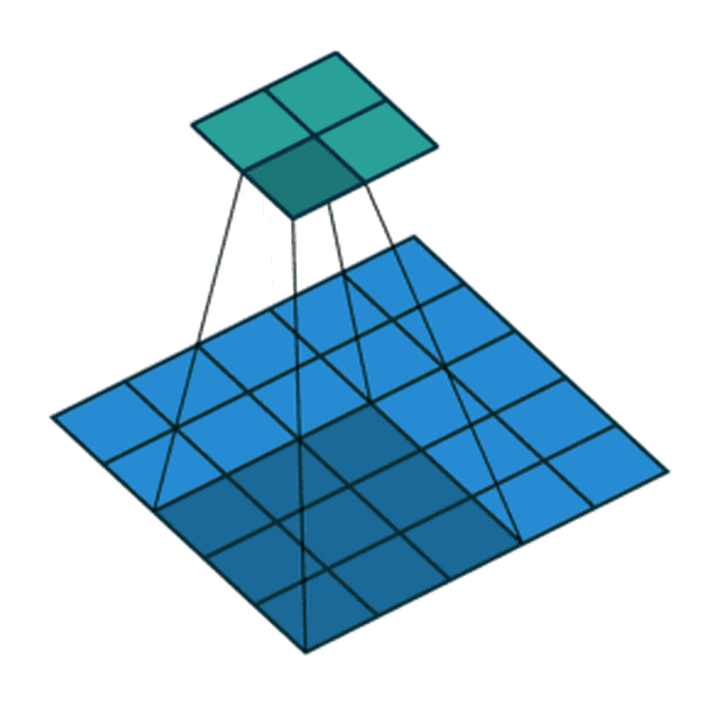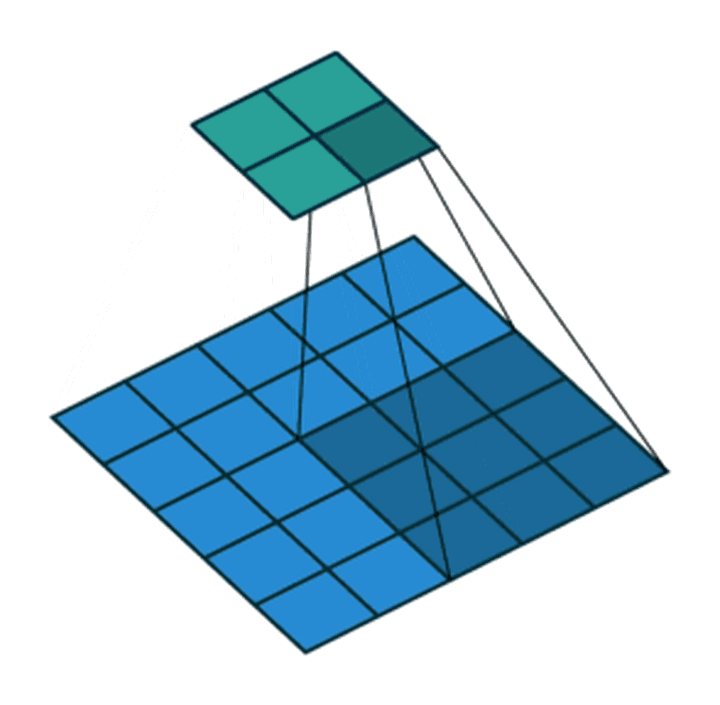
当卷积函数中padding='same’时,会动态调整 p 值,确保 o=n ,即保证输入与输出一致。例如:输入是 28281 输出也为 28281 。
步长为1,卷积核为3*3,padding='same’的卷积情况如下:
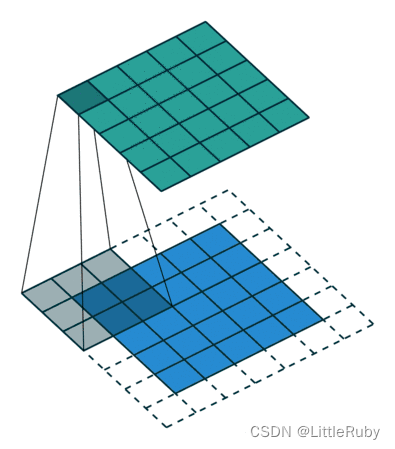
?实例:
7∗7 的 input,3∗3 的 kernel,无填充(padding=0),步长为1,则 o= (7−3)/1 +1也即 output size 为 5∗5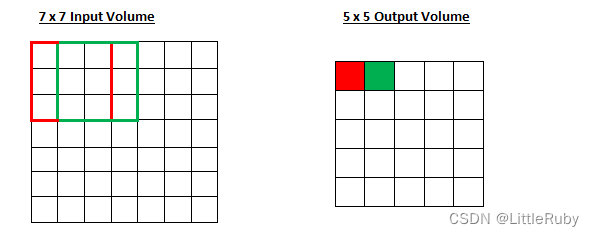
7∗7 的 input,3∗3 的 kernel,无填充(padding=0),步长为2,则 o= (7−3) /2+1也即 output size 为 3∗3
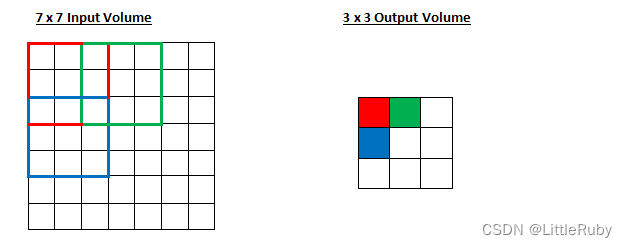
2.池化层
在图像处理中,由于图像中存在较多冗余信息,可用某一区域子块的统计信息(如最大值或均值等)来刻画该区域中所有像素点呈现的空间分布模式,以替代区域子块中所有像素点取值,这就是卷积神经网络中池化(pooling)操作。
池化层可对提取到的特征信息进行降维,实现下采样,同时保留了特征图中主要信息,一方面使特征图变小,简化网络计算复杂度;另一方面进行特征压缩,提取主要特征,增加平移不变性,减少过拟合风险。但其实池化更多程度上是一种计算性能的一个妥协,强硬地压缩特征的同时也损失了一部分信息。
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行降维压缩,以加快运算速度。
池化的几种常见方法包括:平均池化 与 最大池化。其中平均池化和最大池化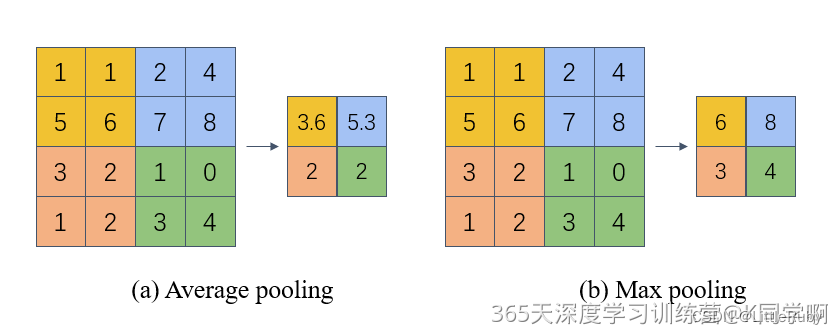
● 平均池化: 计算区域子块所包含所有像素点的均值,将均值作为平均池化结果。如 图(a),这里使用大小为 2 × 2 2\times2 2×2的池化窗口,每次移动的步长为2,对池化窗口覆盖区域内的像素取平均值,得到相应的输出特征图的像素值。池化窗口的大小也称为池化大小,用 k h × k w k_h \times k_w kh×kw表示。在卷积神经网络中用的比较多的是窗口大小为 2 × 2 2 \times 2 2×2,步长为2的池化。
● 最大池化: 从输入特征图的某个区域子块中选择值最大的像素点作为最大池化结果。如 图(b),对池化窗口覆盖区域内的像素取最大值,得到输出特征图的像素值。当池化窗口在图片上滑动时,会得到整张输出特征图。
采用较多的一种池化过程叫最大池化(Max Pooling),max pooling常用的 s=2,f=2的效果:特征图高度、宽度减半,通道数不变。
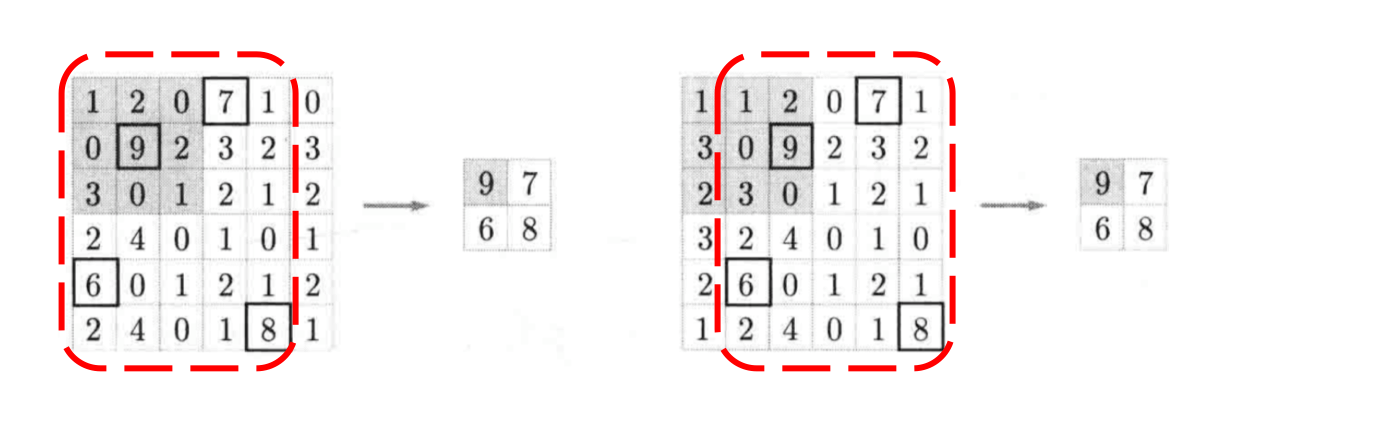
当输入数据做出少量平移时,经过池化后的大多数输出还能保持不变,因此,池化对微小的位置变化具有鲁棒性。例如下图
中,输入矩阵向右平移一个像素值,使用最大池化后,结果与平移前依旧能保持不变。
由于池化之后特征图会变小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
池化层计算公式:
● Input:(N, C, Hin, Win) or (C, Hin, Win)
● Output:(N, C, Hout, Wout) or (C, Hout, Wout)

3.全连接层
全连接层就是将最后一层卷积得到的特征图(矩阵)展开成一维向量,并为分类器提供输入。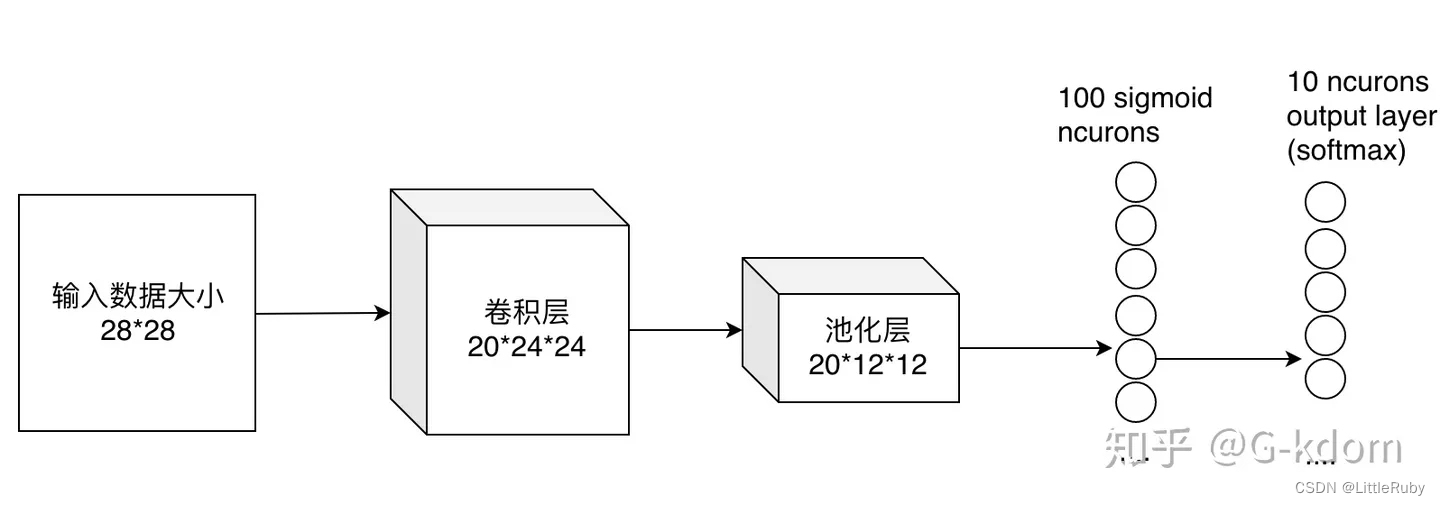
以上图为例输入一个 2828 的灰度图像,经过卷积层输出20个2424 的图像,再经过池化层输出201212的图像,然后通过了一个全连接层用一个12x12x20x100的卷积层去卷积激活函数的输出,最终得到1*100 的向量。 全连接层将学到的特征表示映射到样本的标记空间的作用。就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
全连接层中一层的一个神经元就可以看成一个多项式,我们用许多神经元去拟合数据分布,但是只用一层fully connected layer 有时候没法解决非线性问题,而如果有两层或以上fully connected layer就可以很好地解决非线性问题了。
全连接层对模型影响参数有三个:全接解层的总层数(长度)、单个全连接层的神经元数(宽度)、激活函数
激活函数的作用是增加模型的非线性表达能力
如果全连接层宽度不变,增加长度:
优点:神经元个数增加,模型复杂度提升;全连接层数加深,模型非线性表达能力提高。理论上都可以提高模型的学习能力。
如果全连接层长度不变,增加宽度:
优点:神经元个数增加,模型复杂度提升。理论上可以提高模型的学习能力。
长度和宽度增加并不是越多越好
(1)缺点:学习能力太好容易造成过拟合。
(2)缺点:运算时间增加,效率变低。
那么怎么判断模型学习能力如何?
看Training Curve 以及 Validation Curve,在其他条件理想的情况下,如果Training Accuracy 高, Validation Accuracy 低,也就是过拟合 了,可以尝试去减少层数或者参数。如果Training Accuracy 低,说明模型学的不好,可以尝试增加参数或者层数。
4.参数量计算
先搭建一个简单的cnn网络便于讲解参数计算过程
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2Dfrom keras.layers import Dropout, Flatten, Densefrom keras.models import Sequentialmodel = Sequential()model.add(Conv2D(16,(2,2),input_shape=(224,224,3)))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Dense(133))model.summary()运行结果
Model: "sequential"_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 223, 223, 16) 208 max_pooling2d (MaxPooling2D (None, 111, 111, 16) 0 ) dense (Dense) (None, 111, 111, 133) 2261 =================================================================Total params: 2,469Trainable params: 2,469Non-trainable params: 0_________________________________________________________________卷积层参数
卷积核大小 k × k k \times k k×k,图像通道数 c c c,卷积核个数 n n n,以公式 w e i g h t × x + b i a s weight \times x + bias weight×x+bias计算总参数 m m m,每个卷积核都有 k × k × c k \times k \times c k×k×c个 w e i g h t weight weight+1个 b i a s bias bias,因此
m = k × k × c × n + n m = k \times k \times c \times n + n m=k×k×c×n+n
一个卷积核的大小为 2 × 2 2\times2 2×2,3通道,则一个卷积核的参数为 2 × 2 × 3 2\times2\times3 2×2×3个,共3个卷积核,总参数为 16 × 12 + 16 = 208 16\times12+16=208 16×12+16=208个
池化层参数
无
全连接层参数
从第一层到第二层,只是图片大小发生了变化,深度没有发生变化,Dense对应的神经元个数 j j j个,图像深度还是卷积层的 n n n个,那么还是根据公式: w e i g h t × x + b i a s weight \times x + bias weight×x+bias,计算总参数 l l l
l = j × n + j l= j \times n + j l=j×n+j
Dense对应的神经元个数133个,图像深度还是卷积层的16个,总参数 133 × 16 + 133 = 2261 133 \times 16 + 133 =2 261 133×16+133=2261个