在国外,ChatGPT已经成为AI模型行业的大佬,但是国内如果需要使用,会有各种限制,本文介绍如何使用国内的模型。
在国内,讯飞星火大模型是一个非常优秀的中文预训练模型。本文将介绍如何使用Python调用讯飞星火大模型接口,实现文本生成等功能。
讯飞星火官网:讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞
1、获取api接口的ID和key
可以获取星火免费赠送的200万个token使用和测试,个人学习使用完全够了
1.1 创建应用
点击购买首次应该会让创建一个应用, 如下图,按要求内容随意填写,然后提交
1.2 购买token
创建完成应用,回去购买,我这里选择个人的(这些都是在完成认证及设置了支付密码的基础),我们选择免费的包
1.3 获取 ID和key
在工单中心这个大模型3.5,页面就是,appid这三个我们会用到

1.4 接口文档的选择
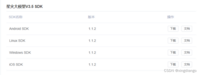
官方提供很多版本的SDK开发包及文档,这里需要我们选择web,官方有介绍

1.5 获取python API接口文档
点击上图的WebAPI链接跳转到如下链接:
星火认知大模型Web API文档 | 讯飞开放平台文档中心

下拉文档到最后,下面会有一些不同语言的调用接口示例,我们选择python的:
点击后会自动下载示例程序包:
![]()
解压后如下:
![]()
打开查看如下内容所示:
# coding: utf-8import _thread as threadimport osimport timeimport base64import base64import datetimeimport hashlibimport hmacimport jsonfrom urllib.parse import urlparseimport sslfrom datetime import datetimefrom time import mktimefrom urllib.parse import urlencodefrom wsgiref.handlers import format_date_timeimport websocketimport openpyxlfrom concurrent.futures import ThreadPoolExecutor, as_completedimport osclass Ws_Param(object): # 初始化 def __init__(self, APPID, APIKey, APISecret, gpt_url): self.APPID = APPID self.APIKey = APIKey self.APISecret = APISecret self.host = urlparse(gpt_url).netloc self.path = urlparse(gpt_url).path self.gpt_url = gpt_url # 生成url def create_url(self): # 生成RFC1123格式的时间戳 now = datetime.now() date = format_date_time(mktime(now.timetuple())) # 拼接字符串 signature_origin = "host: " + self.host + "\n" signature_origin += "date: " + date + "\n" signature_origin += "GET " + self.path + " HTTP/1.1" # 进行hmac-sha256进行加密 signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"' authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') # 将请求的鉴权参数组合为字典 v = { "authorization": authorization, "date": date, "host": self.host } # 拼接鉴权参数,生成url url = self.gpt_url + '?' + urlencode(v) # 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致 return url# 收到websocket错误的处理def on_error(ws, error): print("### error:", error)# 收到websocket关闭的处理def on_close(ws): print("### closed ###")# 收到websocket连接建立的处理def on_open(ws): thread.start_new_thread(run, (ws,))def run(ws, *args): data = json.dumps(gen_params(appid=ws.appid, query=ws.query, domain=ws.domain)) ws.send(data)# 收到websocket消息的处理def on_message(ws, message): # print(message) data = json.loads(message) code = data['header']['code'] if code != 0: print(f'请求错误: {code}, {data}') ws.close() else: choices = data["payload"]["choices"] status = choices["status"] content = choices["text"][0]["content"] print(content,end='') if status == 2: print("#### 关闭会话") ws.close()def gen_params(appid, query, domain): """ 通过appid和用户的提问来生成请参数 """ data = { "header": { "app_id": appid, "uid": "1234", # "patch_id": [] #接入微调模型,对应服务发布后的resourceid }, "parameter": { "chat": { "domain": domain, "temperature": 0.5, "max_tokens": 4096, "auditing": "default", } }, "payload": { "message": { "text": [{"role": "user", "content": query}] } } } return datadef main(appid, api_secret, api_key, gpt_url, domain, query): wsParam = Ws_Param(appid, api_key, api_secret, gpt_url) websocket.enableTrace(False) wsUrl = wsParam.create_url() ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open) ws.appid = appid ws.query = query ws.domain = domain ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})if __name__ == "__main__": main( appid="", api_secret="", api_key="", #appid、api_secret、api_key三个服务认证信息请前往开放平台控制台查看(https://console.xfyun.cn/services/bm35) gpt_url="wss://spark-api.xf-yun.com/v3.5/chat", # Spark_url = "ws://spark-api.xf-yun.com/v3.1/chat" # v3.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址 domain="generalv3.5", # domain = "generalv3" # v3.0版本 # domain = "generalv2" # v2.0版本 # domain = "general" # v2.0版本 query="给我写一篇100字的作文" )代码解释
这段代码定义了一个名为Ws_Param的类,用于处理WebSocket请求。以下是代码中各个方法的解释:
__init__(self, APPID, APIKey, APISecret, gpt_url):初始化方法,用于设置类的实例变量。其中,APPID、APIKey、APISecret分别表示讯飞开放平台的应用ID、API Key和API Secret;gpt_url表示讯飞语音合成服务的URL。create_url(self):生成请求的URL。根据当前时间生成RFC1123格式的时间戳;然后,拼接签名字符串,包括host、date和GET请求行;接着,使用hmac-sha256算法对签名字符串进行加密;将加密后的签名字符串进行Base64编码,并将其添加到鉴权参数中,生成完整的URL。on_error(ws, error):收到WebSocket错误的处理方法。当WebSocket连接发生错误时,会调用此方法。on_close(ws):收到WebSocket关闭的处理方法。当WebSocket连接关闭时,会调用此方法。on_open(ws):收到WebSocket连接建立的处理方法。当WebSocket连接建立时,会调用此方法。在此处,会启动一个新的线程来运行run函数。run(ws, *args):运行函数,用于向讯飞语音合成服务发送请求。根据WebSocket实例的appid和question属性生成请求参数;然后,将请求参数转换为JSON字符串并通过WebSocket发送。on_message(ws, message):收到WebSocket消息的处理方法。当从讯飞语音合成服务接收到消息时,会调用此方法。解析接收到的消息;然后,根据消息中的code判断请求是否成功;如果成功,则将返回的内容累加到全局变量result中,并打印出来;如果code不为0,表示请求失败,此时关闭WebSocket连接。官方的代码有个坑,就是answer = ""是个全局变量,这个会将所有的提问拼接在一起,不过这个影响不大,就是打印answer的结果不好看,只要我们输入时text列表清除历史输入,token还是不带历史。
2、代码调试
直接运行发现报错

发现是on_close()方法少传两个参数,实际在传参时是有三个参数,这里我们给它随便补两个参数,然后调试发现不报错了

运行结果:

3、代码调整
虽然上面的代码可以直接运行了,但是没有交互,只能运行一次,并且不能获取用户输入,如果想实现这样的功能,需要调整代码:
参考官方请求参数:
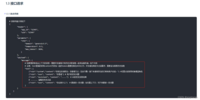
这里我需要给原来的代码添加一个text的列表,将我们要问的问题全部写入到text列表中,然后传递给query参数

封装函数,添加如下代码:
text = []# length = 0def getText(role, content): jsoncon = {} history_put = """['工程','货物',]\n请从上面选项中选择一个属于下面文本的分类\n左侧边坡宣传标语 ,结果只输出1,2 ,如果都不属于输出0 """ text.append({'role': 'user', 'content': history_put}) text.append({'role': 'assistant', 'content': '0'}) # # 设置对话背景或者模型角色 # text.append({"role": "system", "content": "你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"}) jsoncon["role"] = role jsoncon["content"] = content text.append(jsoncon) return text发现接口调用示例对text长度有要求:
注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息需要添加对text长度的检测和判断代码:
#获取长度def getlength(text): length = 0 for content in text: temp = content["content"] leng = len(temp) length += leng return length#检测长度def checklen(text): while getlength(text) > 8000: del text[0] return text接下来对主函数main进行修改,实现交互式及循环请求:
if __name__ == "__main__": text.clear() while 1: Input = input("\n" + "我:") query = checklen(getText("user", Input)) answer = "" print("星火:", end="") main( appid="83e846c5", # 填写控制台中获取的 APPID 信息 api_secret="YTNkNzRiMDRkODBkMjFjOTBiNDM0ZDdl", # 填写控制台中获取的 APISecret 信息 api_key="678b91e71b311082d7bb915f50f44284", # 填写控制台中获取的 APIKey 信息 # appid、api_secret、api_key三个服务认证信息请前往开放平台控制台查看(https://console.xfyun.cn/services/bm35) gpt_url="wss://spark-api.xf-yun.com/v3.5/chat", # Spark_url = "ws://spark-api.xf-yun.com/v3.1/chat" # v3.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址 domain="generalv3.5", # domain = "generalv3" # v3.0版本 # domain = "generalv2" # v2.0版本 # domain = "general" # v2.0版本 query=query ) # 这里是获取星火AI模型助手的回答 getText("assistant", answer)
在使用接口函数调用是加上text.clear(),清除历史对话,否则在一个长的连接调用时历史的token会加越来越长,十分消耗token,不需要历史的建议clear
请求参数这里需要调整,将之前的"text": [{"role": "user", "content": query}]改为如下,否则会报
json: cannot unmarshal array into Go struct field message.payload.message.text.content of type string'
调整后的代码如下:
def gen_params(appid, query, domain): """ 通过appid和用户的提问来生成请参数 """ data = { "header": { "app_id": appid, "uid": "1234", # "patch_id": [] #接入微调模型,对应服务发布后的resourceid }, "parameter": { "chat": { "domain": domain, "temperature": 0.5, "max_tokens": 4096, "auditing": "default", } }, "payload": { "message": { "text": query } } } return data4、代码测试

5、最终代码(亲测可用)
# coding: utf-8import _thread as threadimport base64import datetimeimport hashlibimport hmacimport jsonfrom urllib.parse import urlparseimport sslfrom datetime import datetimefrom time import mktimefrom urllib.parse import urlencodefrom wsgiref.handlers import format_date_timeimport websockettext = []# length = 0class Ws_Param(object): # 初始化 def __init__(self, APPID, APIKey, APISecret, gpt_url): self.APPID = APPID self.APIKey = APIKey self.APISecret = APISecret self.host = urlparse(gpt_url).netloc self.path = urlparse(gpt_url).path self.gpt_url = gpt_url # 生成url def create_url(self): # 生成RFC1123格式的时间戳 now = datetime.now() date = format_date_time(mktime(now.timetuple())) # 拼接字符串 signature_origin = "host: " + self.host + "\n" signature_origin += "date: " + date + "\n" signature_origin += "GET " + self.path + " HTTP/1.1" # 进行hmac-sha256进行加密 signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256).digest() signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8') authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"' authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8') # 将请求的鉴权参数组合为字典 v = { "authorization": authorization, "date": date, "host": self.host } # 拼接鉴权参数,生成url url = self.gpt_url + '?' + urlencode(v) # 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致 return url# 收到websocket错误的处理def on_error(ws, error): print("### error:", error)# 收到websocket关闭的处理def on_close(ws, one, two): print("### closed ###")# 收到websocket连接建立的处理def on_open(ws): thread.start_new_thread(run, (ws,))def run(ws, *args): data = json.dumps(gen_params(appid=ws.appid, query=ws.query, domain=ws.domain)) ws.send(data)# 收到websocket消息的处理def on_message(ws, message): # print(message) data = json.loads(message) code = data['header']['code'] if code != 0: print(f'请求错误: {code}, {data}') ws.close() else: choices = data["payload"]["choices"] status = choices["status"] content = choices["text"][0]["content"] print(content, end='') global answer answer += content if status == 2: print() print("#### 关闭会话") ws.close()def gen_params(appid, query, domain): """ 通过appid和用户的提问来生成请参数 """ data = { "header": { "app_id": appid, "uid": "1234", # "patch_id": [] #接入微调模型,对应服务发布后的resourceid }, "parameter": { "chat": { "domain": domain, "temperature": 0.5, "max_tokens": 4096, "auditing": "default", } }, "payload": { "message": { "text": query } } } return datadef getText(role, content): jsoncon = {"role": role, "content": content} # history_put = """['工程','货物',]\n请从上面选项中选择一个属于下面文本的分类\n左侧边坡宣传标语 # ,结果只输出1,2 ,如果都不属于输出0 # """ # text.append({'role': 'user', 'content': history_put}) # text.append({'role': 'assistant', 'content': '0'}) # # 设置对话背景或者模型角色 # text.append({"role": "system", "content": "你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"}) text.append(jsoncon) return textdef getlength(text): length = 0 for content in text: temp = content["content"] leng = len(temp) length += leng return lengthdef checklen(text): while getlength(text) > 8000: del text[0] return textdef main(appid, api_secret, api_key, gpt_url, domain, query): wsParam = Ws_Param(appid, api_key, api_secret, gpt_url) websocket.enableTrace(False) wsUrl = wsParam.create_url() ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open) ws.appid = appid ws.query = query ws.domain = domain ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})if __name__ == "__main__": text.clear() while 1: Input = input("\n" + "我:") query = checklen(getText("user", Input)) answer = "" print("星火:", end="") main( appid="", # 填写控制台中获取的 APPID 信息 api_secret="", # 填写控制台中获取的 APISecret 信息 api_key="", # 填写控制台中获取的 APIKey 信息 # appid、api_secret、api_key三个服务认证信息请前往开放平台控制台查看(https://console.xfyun.cn/services/bm35) gpt_url="wss://spark-api.xf-yun.com/v3.5/chat", # Spark_url = "ws://spark-api.xf-yun.com/v3.1/chat" # v3.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址 domain="generalv3.5", # domain = "generalv3" # v3.0版本 # domain = "generalv2" # v2.0版本 # domain = "general" # v2.0版本 query=query ) # 这里是获取星火AI模型助手的回答 getText("assistant", answer)6、其他功能参数
system:设置对话背景或者模型角色
使用方法--> 旧版本传入请求数据时列表中只有usr和assistant这两个字典数据,现在要是使用system,只需要在usr前加入提示语字典如下图。
也就是在上文应用分享中 getText函数,text.append( {"role":"system","content":"你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} )后面每次调用接口都是自带system
# 参数构造示例如下{ "header": { "app_id": "12345", "uid": "12345" }, "parameter": { "chat": { "domain": "generalv3.5", "temperature": 0.5, "max_tokens": 1024, } }, "payload": { "message": { # 如果想获取结合上下文的回答,需要开发者每次将历史问答信息一起传给服务端,如下示例 # 注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息 "text": [ {"role":"system","content":"你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} #设置对话背景或者模型角色 {"role": "user", "content": "你是谁"} # 用户的历史问题 {"role": "assistant", "content": "....."} # AI的历史回答结果 # ....... 省略的历史对话 {"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题 ] } }}测试如下:

一股子诗人的味道,哈哈!
7、问题解决
问题现象
在websocket同服务器进行连接时,出现没有enableTrace属性:
module 'websocket' has no attribute 'enableTrace'

问题原因
检查一下当前安装的websocket:
pip show websocket检查这个库的相关发布信息:已经很久没维护了,早已被弃用:
pip_search websocket
解决方法
后续Python中websocket库改为使用websocket-client,需要重新安装:
卸载websocket,这个已弃用,websockets中没有enableTrace模块
推荐安装如下库
pip install websocket-client -i https://pypi.tuna.tsinghua.edu.cn/simple/