随着大数据、云计算、人工智能等技术日新月异,大模型作为人工智能领域的重要成果,正逐步改变着我们的生产与生活。在算力成本、工作效率与安全性等需求的不断增长下,大模型的应用逐渐从云端延伸至边缘端,为各行各业带来前所未有的变革机遇。
2月29日,阿加犀CEO孙晓刚受邀做客广和通“智连接”线上研讨会,分享了阿加犀边缘端大模型部署技术最新进展,并聚焦智能边缘计算赋能AI,与来自高通与广和通的资深行业专家共同探讨相关技术的发展、应用场景以及未来趋势。
近半个月来,视频生成模型Sora全网刷屏,它能够通过文本提示生成逼真且富有想象力的视频,一时间成为业界具有颠覆性功能的现象级产品。
而在Sora出现并占据大众视野之前,国内外早已有不少公司在多模态大模型方面展开研究和布局。
去年上半年,阿加犀顺利攻破大模型边缘端部署推理技术难关,成为国内首批支持LLaMA-2、通义千问Qwen等主流开源大模型在边缘端推理的人工智能公司。
随后,阿加犀携手启朔科技、美格智能等合作伙伴,将多个参数达70亿的语言大模型流畅、高效运行在AI阵列服务器、高算力AI模组等边缘计算设备上。
阿加犀打造的大模型边缘端部署解决方案也先后在世界机器人大会、云栖大会、第五届中国工业互联网大赛以及CES 2024上惊艳亮相,为机器人、工业、消费电子等行业接入AI大模型提供了更优技术路径。
近日,阿加犀大模型边缘端部署技术再进化:通过模型转换优化、芯片性能调度等AI工具链能力,不仅让AI大模型边缘端运行速度进一步提升,而且突破性地支持了其在中低端芯片平台上的部署落地。
经过测试,开源多模态对话模型Vicuna在基于高通芯片的边缘端设备上运行速度提升高达72.6%,Llama2、通义千问以及百川大模型等主流开源大模型的边缘端运行速度提升均超过30%。
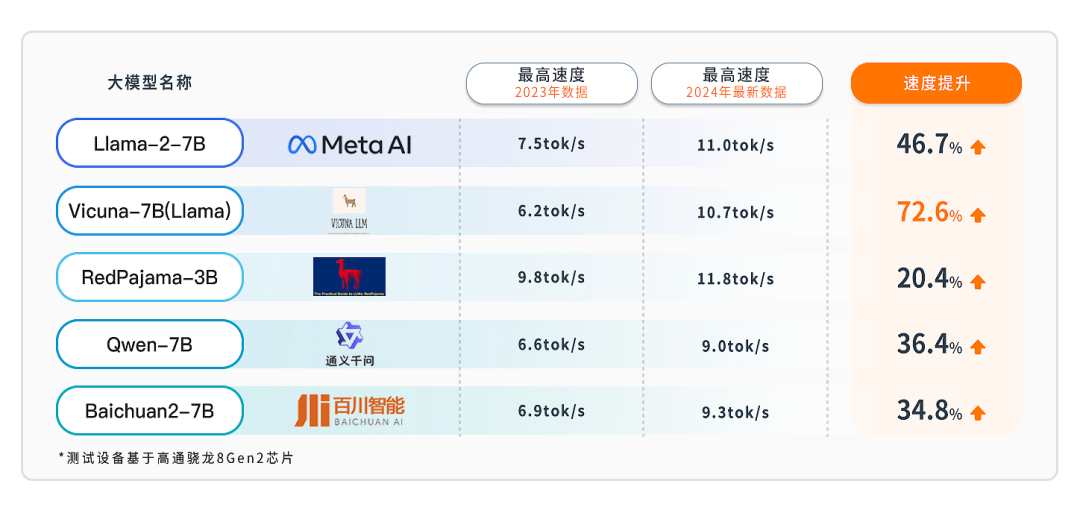
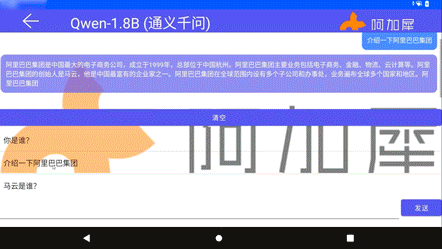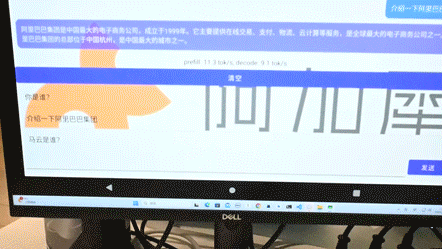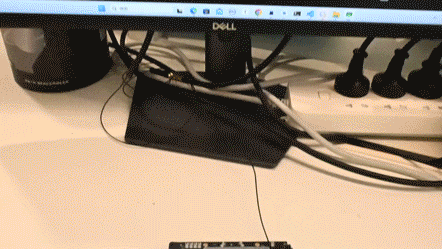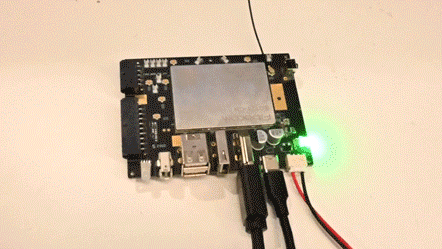
此外,在阿加犀AI工具链的赋能下,百川大模型、RedPajama、通义千问等多个数十亿参数的大模型不仅可以在高通8系列等高端AI芯片平台上落地应用,发挥重要作用,还能够在基于高通7/6/4系列中低端芯片的边缘端设备上稳定运行。
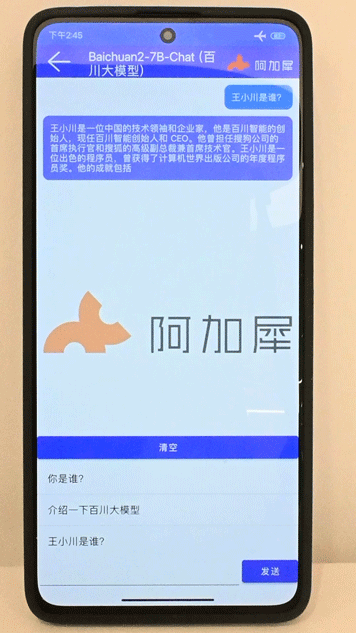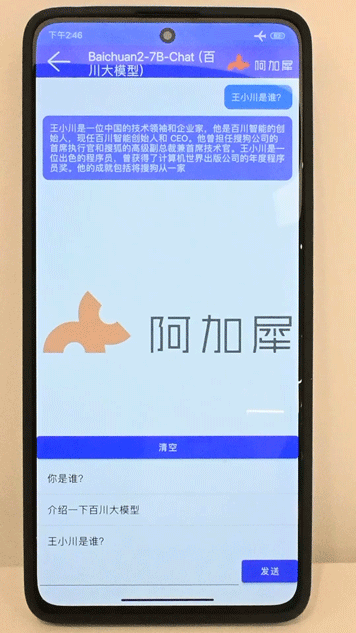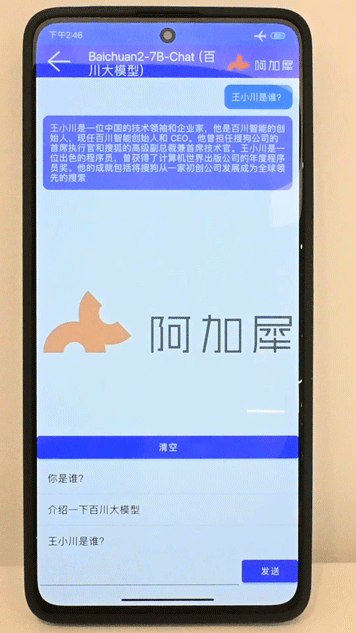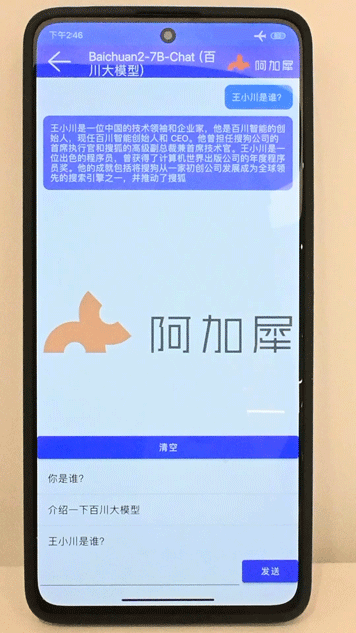
Baichuan2-7B在7s Gen2手机上运行
↓ ↓ ↓
Qwen-1.8B在QCS6490板卡上运行
↓ ↓ ↓
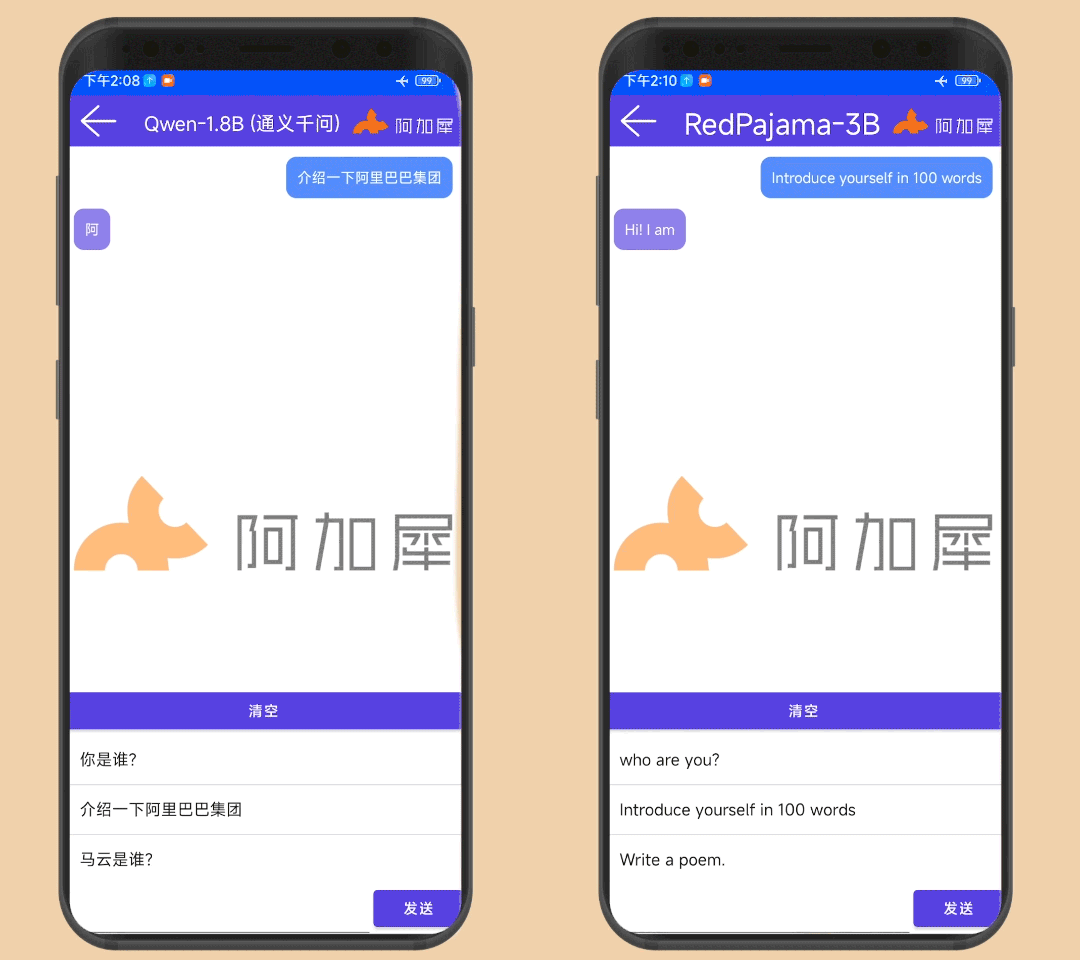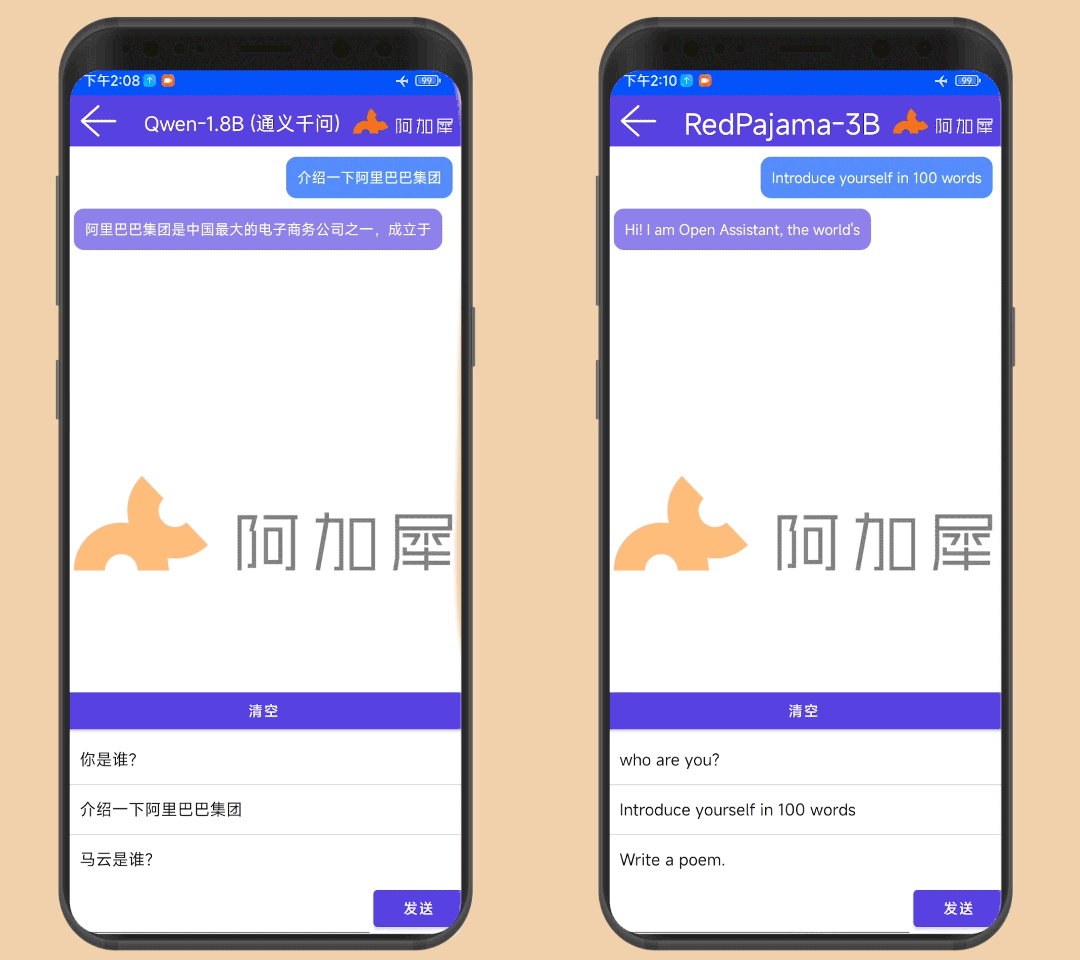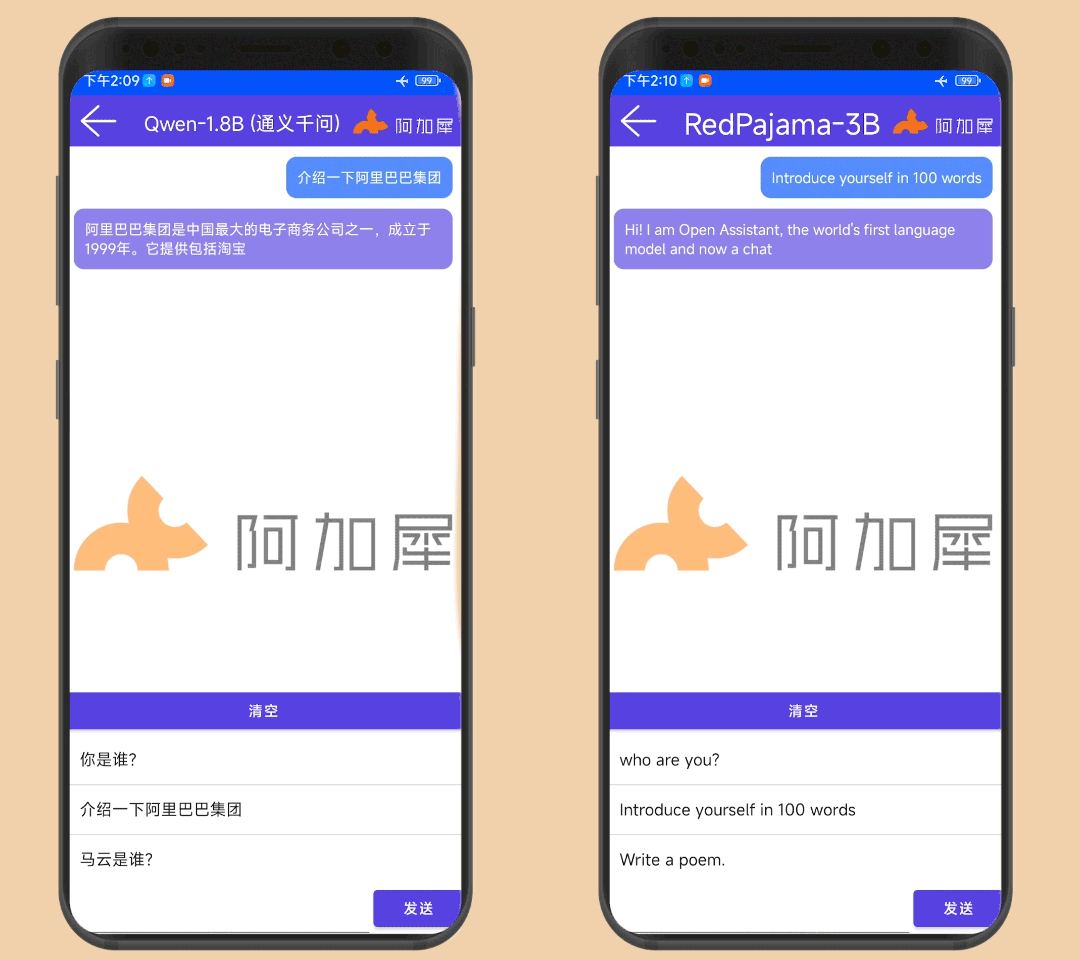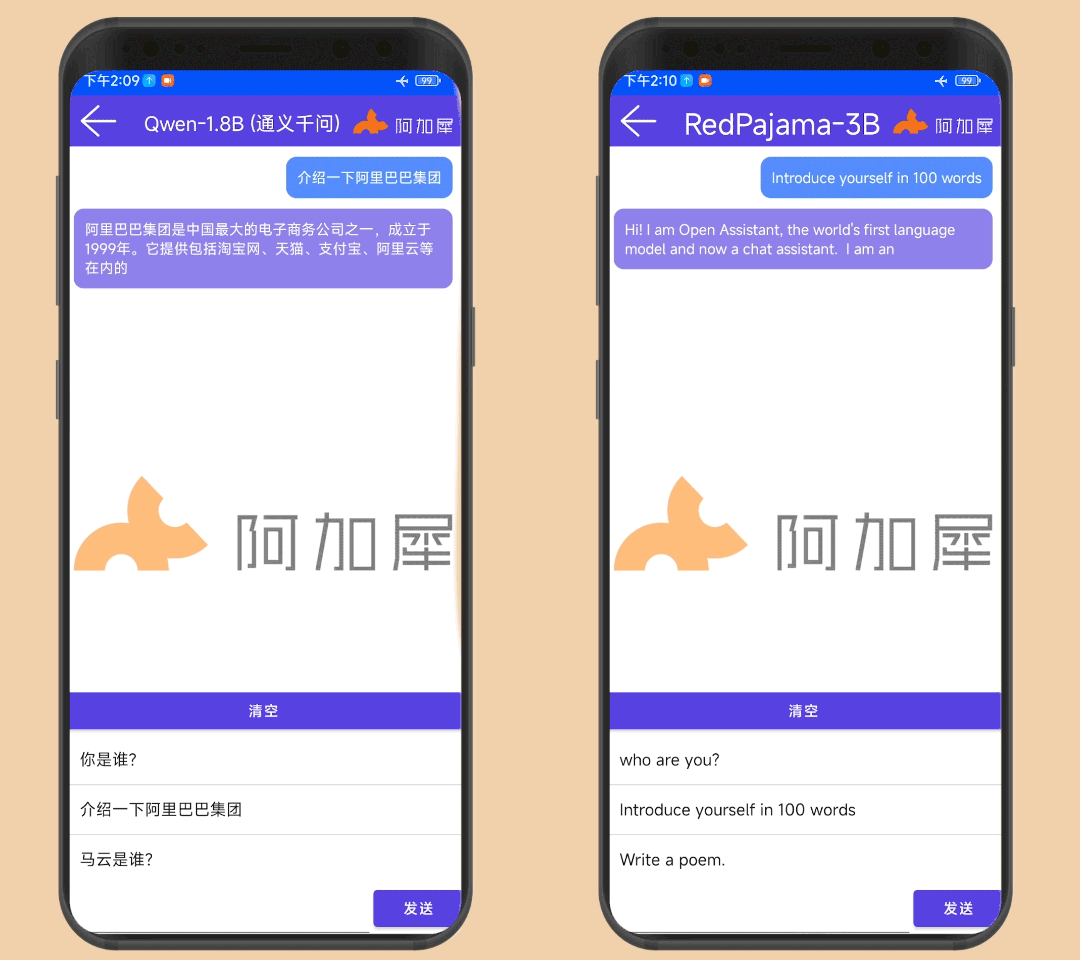
Qwen-1.8B和RedPajama-3B在4gen2手机上运行
↓ ↓ ↓
此次阿加犀的成功实践与验证,为大模型在更广泛、更丰富的边缘端场景高效应用创造了全新可能性。以往,大模型在边缘端的部署落地主要囿于运行效果与硬件设备,而现在,AI大模型在边缘端设备上的运行速度实现了有效提升,算力有限的低端芯片也能够支持较大参数模型的推理了,这将为大模型端侧落地的商业革新带来更多的创新与机遇。
运行速度大幅提升,端侧体验更高效
边缘AI大模型运行速度提升意味着其在单位时间内处理的数据量更大、速度更快、延迟更低,这对于需要实时或快速响应的边缘端应用场景而言尤为关键,例如智能机器人、智能家居、自动驾驶等。
通过阿加犀自研AI工具链对大模型进行优化后,多个主流开源大模型在边缘端计算设备上的推理运行速度显著提升。
这不仅意味着响应速度更快、服务质量更有保障,而且能在一定程度上减少计算资源的占用,降低能源消耗和成本。无论是语音识别、图像处理,还是自然语言处理等智能应用,都将受益于这一突破。
中低端芯片支持,让AI无处不在
很多嵌入式系统、物联网设备或移动端应用对于设备的计算能力和功耗都有特殊要求。相较于高端芯片而言,中低端芯片在性能和功耗之间取得了较好的平衡,且成本较低,设备价格亲民。
例如在极端温度、湿度或者缺乏稳定电源等特定场景中,中低端芯片更加稳定、可靠、耐用,支持大模型的中低端芯片则能为这些场景中的各类AI应用提供智能、高效的边缘计算支持。搭上中低端芯片的场景“直通车”,大模型也将有望大规模应用于更丰富的边缘计算场景中。
因此阿加犀AI大模型部署技术支持以高通7/6/4系列芯片为代表的中低端芯片,对于端侧AI普及而言具有重要意义。
囿于云端方案在成本、延迟、安全性等方面的短板,能在本地进行数据处理与决策的边缘端AI发展逐渐成为大势所趋。阿加犀基于行业领先AI工具链打造的大模型边缘端部署解决方案,让推理以更高的效率和更好的效果集中在离数据产生距离更近的端侧进行,能够弥补云端方案的短板,且有效缓解AI算力不足的需求和缺口。
随着阿加犀边缘端大模型部署技术的不断提升与成熟,以及各行业智能化转型和升级的持续推进,AI大模型应用将加速落地于智能机器人、智能驾驶、智能家居、工业自动化等场景,成为人类智慧生活的重要支撑工具。