2023年所暴露的AI生成视频的各种问题,大部分被OpenAI发布的Sora解决了吗?以下为a16z发布的总结,在关键之处,我做了OpenAI Sora的对照备注。
推荐阅读,了解视频生成技术进展。
Why 2023 Was AI Video’s Breakout Year, and What to Expect in 2024
作者:Justine Moore
Posted January 31, 2024
2023年被认为是AI视频的突破年。一年前,几乎没有公开的文本到视频生成模型存在,但在仅仅12个月后,已经有数十种视频生成产品被广泛使用,全球数百万用户可以通过文本或图像提示创建短视频片段。
尽管这些产品仍然相对有限,大多数只能生成3到4秒的视频,输出的质量参差不齐,并且角色的一致性等问题尚未解决。我们离能够通过单个文本提示(甚至多个提示)创作出皮克斯级别的短片还有很长的路要走。
然而,过去一年在视频生成领域取得的进展表明,我们正处于一场巨大变革的早期阶段,类似于图像生成领域所见的情况。我们看到文本到视频模型的持续改进,以及图像到视频和视频到视频等相关领域的兴起。
为了帮助理解这场创新爆发,我们追踪了迄今为止的最重要进展、值得关注的公司以及这一领域中尚未解决的核心问题。
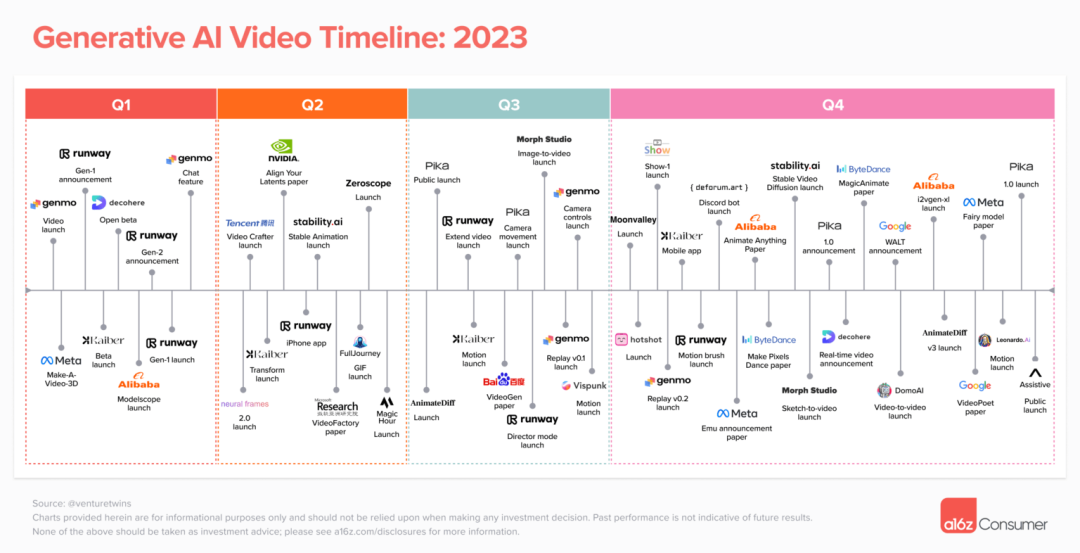
在哪里可以使用AI生成视频的产品?
Products
今年我们追踪了21个公开产品
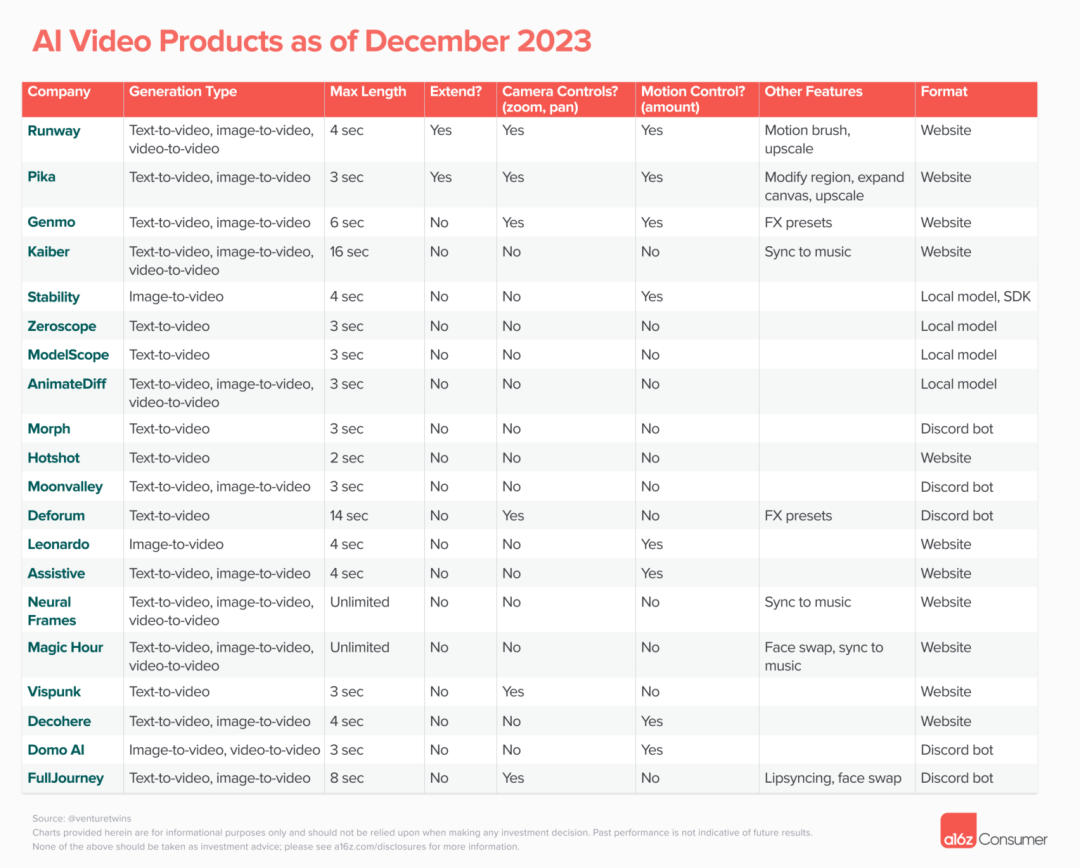
其中大多数产品来自初创公司,其中许多公司最初都是从Discord机器人开始的,这样做有一些优势:
不需要构建自己面向消费者的界面,可以专注于模型质量
利用Discord每月活跃用户达1.5亿的基础进行分发
公共频道为新用户提供了一个方便的方式,可以通过观察其他人生成的内容来获得创作灵感,并为产品提供社交证明
然而,我们开始看到越来越多的视频产品构建自己的网站,甚至推出移动应用程序,尤其是在产品成熟后。虽然Discord提供了一个很好的起点,但其在纯生成之上添加工作流程的能力有限,团队对消费者体验几乎没有控制权。还值得注意的是,有很大一部分人口不使用Discord,可能会对其界面感到困惑,或者不经常使用。
谷歌、Meta和其他公司在哪里?在公开产品的列表中,这些公司明显缺失,尽管你可能已经看到过它们发布的一些响亮的帖子,宣布了Meta的Emu Video、谷歌的VideoPoet和Lumiere,以及字节跳动的MagicVideo等模型。
迄今为止,除了阿里巴巴之外,大型科技公司选择不公开发布他们的视频生成产品。相反,他们在各种形式的视频生成上发表论文,并在不宣布模型何时会公开的情况下发布演示视频。
这些公司都拥有庞大的用户群体,具有巨大的分发优势。为什么他们不发布视频模型,当他们的演示看起来很强大,并且他们有机会在这个新兴领域占据有意义的市场份额呢?
重要的是要记住,这些公司行动缓慢。大多数公司甚至还没有发布文本到图像的产品,尽管Instagram在去年底推出了一个用于故事的AI背景生成器,而TikTok一直悄悄地推出AI滤镜。法律、安全和版权问题通常使得这些公司将研究转化为产品变得困难,并延迟发布,这给新进入者有机会获得先发优势。
AI视频是什么样子的?
如果你曾经使用过这些产品,你就会知道在AI视频准备就绪之前还有很多需要改进的地方。偶尔会有“魔法时刻”,模型生成了与你的提示相匹配的精美视频片段,但这种情况相对较少。更常见的情况是需要多次重新生成并裁剪或编辑输出,以获得专业级的视频片段。
可控性——你能否控制场景中发生的事情(例如,如果你提示“男人向前走”,动作是否正如描述的那样?)以及“摄像机”的移动方式?在后者方面,许多产品已经添加了功能,允许你缩放或平移摄像机,甚至添加特效。
动作是否如描述的那样?是一个更难解决的问题。这是一个模型质量问题(模型是否理解并能够执行你的提示),尽管一些公司正试图在生成之前给用户更多的控制权。
Runway的运动画笔就是一个很好的例子,它允许你突出显示图像的特定区域并确定它们的移动方式。
时间上的连贯性——如何使角色、物体和背景在帧之间保持一致,而不会变形或扭曲?这是所有公开可用模型中普遍存在的问题。如果你今天看到一个时间上连贯的视频,且超过几秒钟,那很可能是视频到视频的效果,它将一个视频转换为另一个风格,例如使用AnimateDiff提示进行旅行。
### OpenAI的sora具有空间一致性,就像是在3D空间中拍摄的视频一样。
长度——是否能够生成超过几秒钟的视频片段?这与时间上的连贯性密切相关。许多公司限制了你可以生成的视频长度,因为他们无法确保在几秒钟后仍然保持一致。如果你看到一个长形式的AI视频(如下面的视频),你会注意到它由许多短片段组成,可能需要数十个,甚至数百个提示!
### OpenAI的sora解决了长度问题,可以生成60s视频,同时可以为任意两段视频进行插帧,还可以为视频进行补全。
尚未解决的问题
AI视频目前似乎处于GPT-2的水平。在过去一年中,我们取得了很大的进展,但在日常消费者能够每天使用这些产品之前,还有很长的路要走。什么时候会出现类似于“ChatGPT时刻”的视频模型?在该领域的研究人员和创始人中并没有广泛的共识,还有一些问题有待回答:
当前的扩散架构是否适用于视频?目前的视频模型是基于扩散的:它们生成帧并尝试在它们之间创建时间上连贯的动画(有多种策略可以实现这一点)。它们没有对3D空间和物体如何互动的内在理解,这解释了扭曲/变形现象的原因。例如,一个视频片段的前半部分可能是一个人沿着街道走动,然后在后半部分融化到地面上——模型没有“硬”表面的概念。由于缺乏对场景的3D概念化,从不同的角度生成相同的视频片段也很困难(甚至不可能)。
### 如前所述,OpenAI已经解决了这个问题。
有些人认为视频模型基本上不需要对3D空间有所了解。如果它们在足够质量的数据上进行了训练,它们将能够学习对象之间的关系,以及如何从不同角度表示场景。
### OpenAI的Sora再次展示了“暴力美学”,在大规模视频模型的基础上,模型涌现了新的能力:对空间的理解能力。
而其他人则坚信,这些模型需要一个3D引擎来生成时间上连贯的内容,特别是超过几秒钟的内容。
高质量训练数据将从何而来?训练视频模型比其他内容模态更困难,主要是因为这些模型可以从中学习的高质量标记训练数据相对较少。语言模型通常在像Common Crawl这样的公共数据集上进行训练,而图像模型则在像LAION和ImageNet这样的带标签数据集(文本-图像对)上进行训练。
### 目前,可以猜测OpenAI的Sora模型训练数据是由3D引擎来制作的。
视频数据更难获取。虽然在YouTube和TikTok等平台上有大量公开可访问的视频,但它们没有标记,并且可能不够多样化。理想情况下,理想的视频数据可能来自于电影工作室或制片公司,它们拥有从多个角度拍摄的长片,并附有剧本和指导。然而,是否愿意授权这些数据进行训练还有待确定。
这些应用场景将如何在平台/模型之间划分?我们几乎在每个内容模态中都看到一个模型不能胜任所有应用场景的情况。例如,Midjourney、Ideogram和DALL-E都具有独特的风格,并擅长生成不同类型的图像。
我们预计视频也会有类似的动态。如果你测试今天的文本到视频和图像到视频模型,你会注意到它们在不同的风格、运动类型和场景构图方面表现出色(我们将在下面展示两个例子)。围绕这些模型构建的产品在工作流程方面可能会进一步分化,并服务于不同的终端市场。这甚至还不包括那些不仅仅进行纯文本到视频生成,而是处理诸如动画人类化身(例如HeyGen)、视觉特效(例如Wonder Dynamics)和视频到视频(例如DomoAI)等内容的相关产品。
Prompt: “Snow falling on a city street, photorealistic”

Genmo

Runway

Stable Video Diffusion

Pika Labs
Prompt: “Young boy playing with tiger, anime style”

Genmo

Runway

Stable Video Diffusion

Pika Labs
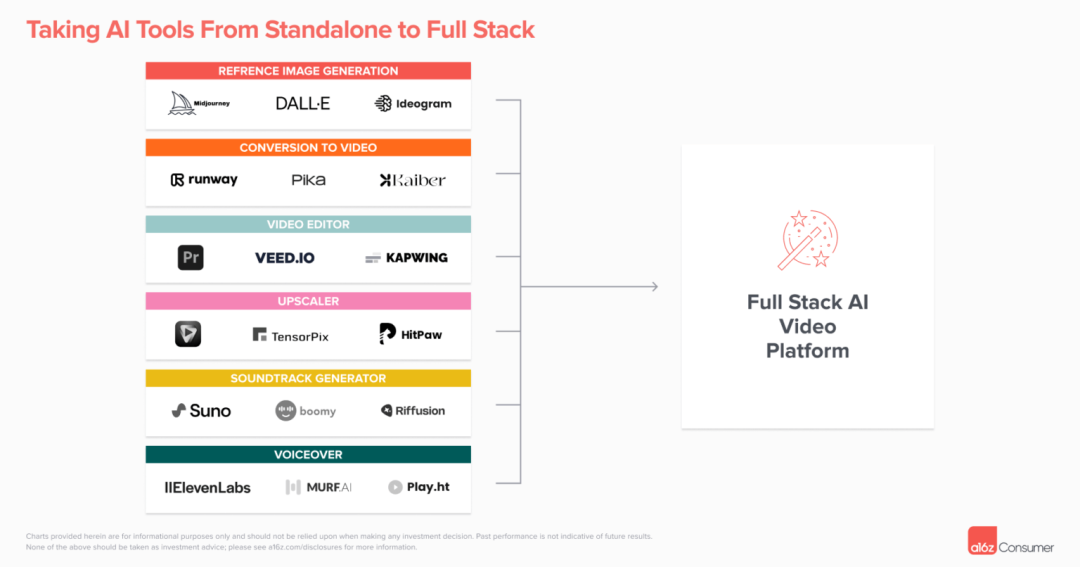
谁将拥有这个工作流程?在纯视频生成之外,制作一个好的片段或电影通常需要编辑,尤其是在当前范式下,许多创作者使用视频模型来为在其他平台上创建的照片添加动画效果。在Capcut或Kapwing等编辑平台上添加配乐和配音(通常是在其他产品上生成的,如Suno和ElevenLabs)是很常见的。
在这么多产品之间来回切换是没有意义的。我们预计视频生成平台将开始添加一些这些功能。例如,Pika现在允许你在他们的网站上提升视频质量。然而,我们对于一个AI原生的编辑平台也抱有乐观态度,它可以方便地在一个地方从不同的模型生成跨模态的内容,并将这些内容组合在一起。
a16z.com/why-2023-was-ai-videos-breakout-year-and-what-to-expect-in-2024
原文中文注解已经更新至AIGC知识库
